Exploring Kubernetes API using Wireshark part 1: Creating, Listing and Deleting Pods
Related Articles: Exploring Kubernetes API using Wireshark part 2: Namespaces Exploring Kubernetes API using Wireshark part 3: Python Client API Quick Intro This article answers the following question: What happens when we create, list and delete pods under the hood? More specifically on the wire. I used these 3 commands: I'll show you on Wireshark the communication between kubectl client and master node (API) for each of the above commands. I used a proxy so we don't have to worry about TLS layer and focus on HTTP only. Creating NGINX pod pcap:creating_pod.pcap (use http filter on Wireshark) Here's our YAML file: Here's how we create this pod: Here's what we see on Wireshark: Behind the scenes, kubectl command sent an HTTP POST with our YAML file converted to JSON but notice the same thing was sent (kind, apiVersion, metadata, spec): You can even expand it if you want to but I didn't to keep it short. Then, Kubernetes master (API) responds with HTTP 201 Created to confirm our pod has been created: Notice that master node replies with similar data with the additional status column because after pod is created it's supposed to have a status too. Listing Pods pcap:listing_pods.pcap (use http filter on Wireshark) When we list pods, kubectl just sends a HTTP GET request instead of POST because we don't need to submit any data apart from headers: This is the full GET request: And here's the HTTP 200 OK with JSON file that contains all information about all pods from default's namespace: I just wanted to emphasise that when you list a pod the resource type that comes back isPodListand when we created our pod it was justPod. Remember? The other thing I'd like to point out is that all of your pods' information should be listed underitems. Allkubectldoes is to display some of the API's info in a humanly readable way. Deleting NGINX pod pcap:deleting_pod.pcap (use http filter on Wireshark) Behind the scenes, we're just sending an HTTP DELETE to Kubernetes master: Also notice that the pod's name is also included in the URI: /api/v1/namespaces/default/pods/nginx← this is pods' name HTTP DELETEjust likeHTTP GETis pretty straightforward: Our master node replies with HTTP 200 OK as well as some json file with all the info about the pod, including about it's termination: It's also good to emphasise here that when our pod is deleted, master node returns JSON file with all information available about the pod. I highlighted some interesting info. For example, resource type is now just Pod (not PodList when we're just listing our pods).4.5KViews3likes0CommentsCreating a Credential in F5 Distributed Cloud for GCP
Configuring a cloud account credential for F5 Distributed Cloud to use with Google Cloud Platform (GCP), while a straightforward process, requires some nuance to get just right. This article illustrates each step of the way. Log in to GCP at console.cloud.google.com. Navigate to IAM & Admin > Service Accounts, then click “Create Service Account”. Enter the service account name, then click “Create and Continue”, then click “Done". Click the “Keys” tab, then “Add Key”, then “Create new key”. To download the key file, select key type “JSON”, click “Create”, then click “Done”. Open and navigate to the F5 Distributed Cloud Console, Cloud and Edge Sites > Site Management > Cloud Credentials, then click “Add Cloud Credentials”. Enter cloud credential Name, Cloud Credential Type: GCP Credential, then click “Configure”. Locate the file download in Step 4 above on your local computer, and copy and paste this into the window, then click “Blindfold”. Although not required, it is recommended confirm the following additional fields: Secret Info: Blindfold Secret Policy: Built-in Build-in policies: shared/ves-io-allow-volterra Type: Text Click “Apply” to complete creating the Cloud Credential. You can now use this when deploying your GCP Cloud Site using F5 Distributed Cloud. You've now configured a Cloud Credential for deploying services in GCP using the F5 Distributed Cloud Console.848Views1like0CommentsReady to Go! Deploying F5 Infrastructure Using Terraform
This article describes how using Terraform enables you to rapidly deploy F5 infrastructure. Having something that is "ready to go" is what building infrastructure with Terraform is all about! The article also describes how you can customize your Terraform code to meet your particular needs. Once you have your specific design pattern, you have an automated way of rapidly creating, modifying, or destroying the network/application infrastructure over and over again in minutes, rather than hours or days. My Chosen Environment I will be using: Google Cloud Platform Terraform Github for source control VS Code for Editing Terraform There are also templates in the same repository that will work just as easily in AWS and Azure. What Is Terraform? Terraform is a tool that is produced by Hashicorp. Terraformis a solution for building, changing, and versioning infrastructure safely and efficiently.Terraformcan manage existing and popular service providers as well as custom in-house solutions. Configuration files describe toTerraformthe components needed to run a single application or your entire datacenter. How Can You Deploy F5 Using Terraform? There are many articles about how to install Terraform. This article assumes you have already installed Terraform and are ready to start deploying F5 infrastructure. In this article we will show you how easy it is to: Deploy an Example F5 Terraform Template Modify the Vanilla Terraform Template to Add a Jump-Box Why Would You Want to Modify the Generic Template to Add a Jump-Box? Well, don’t put your management interface on the internet. That is not a good idea. The Terraform example that I will use sets the management interface up with direct access to the internet. There are ACLs that you can configure to only allow connections from specific source IP addresses, which you should definitely employ even if you don’t use a jump-box. An additional layer of security is to add a jump-box so that you have to connect to the jump-box prior to accessing the management interface. From there you could also go ahead and smart card enable your jump-box or provide other two-factor authentication in order to further increase the security of the environment. Using a jump-box is a good best practice, period. For example, CVE-2020-5902 is a critical vulnerability that allowed attackers to actively exploit F5 management interfaces to do things like install coin-miners and malware or to gain administrative access to the hacked device. If your management interface had been internet facing, then it is safe to assume that you would have been breached. Also there were reports from the FBI that state-sponsored organizations were also trying to exploit this flaw. https://www.securityweek.com/iranian-hackers-target-critical-vulnerability-f5s-big-ip By using a jump-box you would not be placing your F5 management interfaces directly on the internet; you would have to access the F5 management interfaces via an RDP connection. Note that you should also harden your jump-box and implement ACLs and two-factor authentication in order to improve the security of the jump-box itself, as it presents a means of access. In this article we build the jump-box, but further hardening (which could also be implemented in Terraform) should be a best practice to make access to your management infrastructure more secure. Deploy a Terraform Example That Deploys F5 Infrastructure 1)Fork template In this example, my starting point is to fork templates published by a fellow F5er Jeff Giroux. This way I can keep my own copy and also make changes as appropriate for my environment. 2) Use git pull to make a local copy of the Terraform code. git clone https://github.com/dudesweet/f5_terraform.git This will pull a local copy of the template using the "git" command that will pull your forked version from github. 3) Explore the code with VS code. I am using VS code as my local editor. You can see that the template has directories for Azure, AWS, and GCP, and has different implementations of high availability; plus there are also auto-scale use cases. Your design pattern of choice will depend upon your requirements. In my case I am going to choose HA via load balancing. 4) Build your network infrastructure, as per the readme. This solution uses a Terraform template to launch a new networking stack. It will create three VPC networks with one subnet each: mgmt, external, internal. Use this terraform template to create your Google VPC infrastructure, and then head back to the [BIG-IP GCP Terraform folder](../) to get started! So navigate to the below directory. ~/f5_terraform/GCP/Infrastructure-only And you are going to want to customize the terraform.tfvars.example file and then re-name that file to terraform.tfvars So fill this out according to you specific environment. These are self explanatory, but: The prefix is used to prefix the infrastructure naming. adminsrcAddr - this is is your friend. This is how you restrict management access from the internet. gcp_project_id - this is your Google project Identifier. Region - your region where you would like the infrastructure to be built. Zone - your zone where you would like the infrastructure to be built. # Google Environment prefix = "mydemo123" adminSrcAddr = "0.0.0.0/0" gcp_project_id = "xxxxx" gcp_region = "us-west1" gcp_zone = "us-west1-b" Also, in the variables.tf you can customize the subnets to your own requirements, but in this case you need three VPCs with subnets (this is GCP so we have one 3 VPCs and a Subnet Per VPC). And then build out the network infrastructure. In the infrastructure directory: ~/f5_terraform/GCP/Infrastructure-only Run the following command: terraform plan "terraform plan" will show you the changes that are going to be made. And then run the command: terraform apply "terraform apply" will build the network infrastructure. "terraform apply" will prompt you with a yes/no to confirm if you want to go ahead and make the changes. Once you have built out your network infrastructure, you should be able to see the infrastructure that you have created inside of Google. Once you have built your networks and firewall rules etc., you can go ahead and build out your F5 infrastructure. 6) Build your F5 infrastructure. As mentioned before, the Terraform template that we are using allows access to the management interfaces from the internet - and you can limit access to the management interface via source IP. In my case, I want to add an additional layer of security by adding a jump-box. So I need to add a separate file with a few lines of Terraform code to instantiate the jump-box in the following directory: ~/f5_terraform/GCP/HA_via_lb After creating a file called jumpbox.tf, in my case I then added the following code to create a jump-box instance and associate it with the management subnet. #creates an ipV4 address to associate with the interface resource "google_compute_address" "static" { name = "ipv4-address" } #Define the type of instance tht you want. I am choosing a windows server. resource "google_compute_instance" "jumphost" { count = 1 name = "myjumphost1" project = var.gcp_project_id machine_type = "n1-standard-8" zone = var.gcp_zone allow_stopping_for_update = true boot_disk { initialize_params { image = "windows-server-2016-dc-v20200714" } } #Define the network interface and then associate the IP with the network interface. network_interface { network = "${var.prefix}-net-mgmt" subnetwork = "${var.prefix}-subnet-mgmt" subnetwork_project = var.gcp_project_id network_ip = var.jumphost_private_ip access_config { nat_ip = google_compute_address.static.address } } #Service account and permissions (how much access the service account has to the Google Meta data service). service_account { scopes = ["cloud-platform", "compute-rw", "storage-ro", "service-management", "service-control", "logging-write", "monitoring"] } } Then I will need to modify the terraform.tfvars.example file to suit my environment, and re-name to terraform.tfvars. # BIG-IP Environment uname= "admin" usecret= "my-secret" gceSshPubKey = "ssh-rsa xxxxx" prefix= "mydemo123" adminSrcAddr = "0.0.0.0/0" mgmtVpc= "xxxxx-net-mgmt" extVpc= "xxxxx-net-ext" intVpc= "xxxxx-net-int" mgmtSubnet= "xxxxx-subnet-mgmt" extSubnet= "xxxxx-subnet-ext" intSubnet= "xxxxx-subnet-int" dns_suffix= "example.com" # BIG-IQ Environment bigIqUsername = "admin" # Google Environment gcp_project_id = "xxxxx" gcp_region= "us-west1" gcp_zone= "us-west1-b" svc_acct= "xxxxx@xxxxx.iam.gserviceaccount.com" privateKeyId= "abcdcba123321" ksecret= "svc-acct-secret" I also added a line into the file called outputs.tf. output "JumpBoxIP" { value = google_compute_instance.jumphost.0.network_interface.0.access_config.0.nat_ip} This line will print out the jump-box IP address that I will use to RDP to the jump-box after a "terraform apply". Note that these templates rely upon the use of Google's secret manager in order to store the admin password. You will need to create a secret that by default is called "my-secret" (but you can call it anything you want), and this is where the Terraform code will pull the admin password from. Using a vault or a secrets manager to store sensitive values for reference in code is a good security best practice as you are only referencing the secrets vault in code and not the literal values themselves. And then build out the f5 infrastructure that will use the network infrastructure that you created earlier. In the HA_via_lb directory: ~/f5_terraform/GCP/HA_via_lb Run the following command: terraform plan "terraform plan" will show you the changes that are going to be made. And then: terraform apply "terraform apply" will add the F5 infrastructure and the jump-boxes. "terraform apply" will prompt you with a yes/no to confirm that you want to go ahead and make the changes. Remove Access to Port 443 on the Management Plane Because this Terraform template uses F5 declarative on boarding (DO) and AS3 to Place the BIG-IPs in an active standby pair and Create an example application on the BIG-IP... ...the example declarations in the Terraform rely on access to the management interface on port 443 as they POST the declarations to the BIG-IP in order to create the configuration. In your case this may present a too much of a risk, but if you use the source IP-based filtering mechanism properly and you use a very strong admin password for the management interface, then you can mitigate this risk for the brief period of time that the management interface would be exposed on the internet for Infrastructure Creation. Again, I deny port 443 after creating the infrastructure. If you can’t do this, you could build a jump-box first and then run the Terraform code from the jump-box. That being said, in my case I go back into the "Infrastructure Only" section and remove port 443 under allowed ports. You can simply edit the networks.tf file in the "Infrastructure Only" directory and re-run the template again. This is the stanza for the firewall rules on the management VPC: resource "google_compute_firewall" "mgmt" { name = "${var.prefix}-allow-mgmt" network = google_compute_network.vpc_mgmt.name source_ranges = [var.adminSrcAddr] allow { protocol = "icmp" } allow { protocol = "tcp" #remove access to port 443 here an re-apply ports = ["22","3389"] } } When you run this "terraform apply" again you will note that changes will only be made to the infrastructure that are modified. Terraform maintains state. It keeps a copy of what has been deployed and therefore will only make a change to the objects that require changes. Ready to Go! When this is all done, you will have a pair of BIG-IPs clustered in (Active/Standby) in Google GCP configured with three NICS. One for management, one for the "external" traffic interface, and one for the "internal" traffic interface. Traffic will ingress from from the Google Load Balancer to the BIG-IP VE, which will the process traffic to the applications that would reside on the "Internal" traffic side. There is now a jump-box that will be used to access the management interfaces to make changes to the BIG-IP configuration. You could also place further DevOps infrastructure on the jump-box in order to automate your application delivery configuration. From here you should be able to: Navigate to your jump-box. In my case, I set a strong password on the jump-box from the Google console. No doubt this could also be automated in the Terraform. Access your Infrastructure via the jump-box. You will be able to access the management IP on the internal IP address on NIC1. You can view a video based overview below. Links and References https://www.youtube.com/watch?v=o5b2OvN9ReM https://github.com/JeffGiroux/f5_terraform https://clouddocs.f5.com/products/extensions/f5-appsvcs-extension/latest/ https://clouddocs.f5.com/products/extensions/f5-declarative-onboarding/latest/ https://clouddocs.f5.com/products/orchestration/terraform/latest/ https://www.terraform.io/2.7KViews1like1CommentInstalling and running iControl extensions in isolated GCP VPCs
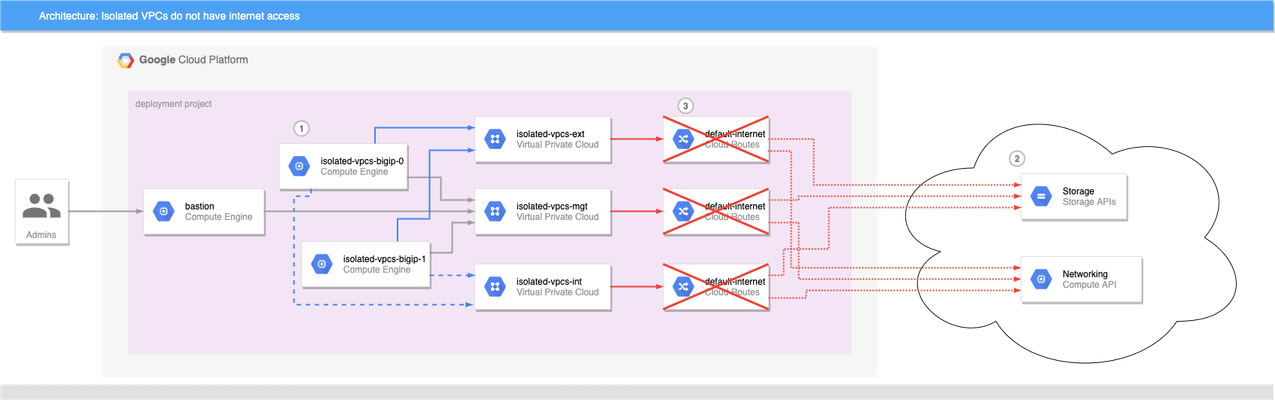
BIG-IP instances launched on Google Cloud Platform usually need access to the internet to retrieve extensions, install DO and AS3 declarations, and get to any other run-time assets pulled from public URLs during boot. This allows decoupling of BIG-IP releases from the library and extensions that enhance GCP deployments, and is generally a good thing. What if the BIG-IP doesn't have access to the Internet? Best practices for Google Cloud recommend that VMs are deployed with the minimal set of access requirements. For some that means that egress to the internet is restricted too: BIG-IP VMs do not have public IP addresses. A NAT Gateway or NATing VM is not present in the VPC. Default VPC network routes to the internet have been removed. If you have a private artifact repository available in the VPC, supporting libraries and onboarding resources could be added to there and retrieved during initialization as needed, or you could also create customized BIG-IP images that have the supporting libraries pre-installed (see BIG-IP image generator for details). Both those methods solve the problem of installing run-time components without internet access, but Cloud Failover Extension, AS3 Service Discovery, and Telemetry Streaming must be able to make calls to GCP APIs, but GCP APIs are presented as endpoints on the public internet. For example, Cloud Failover Extension will not function correctly out of the box when the BIG-IP instances are not able to reach the internet directly or via a NAT because the extension must have access to Storage APIs for shared-state persistence, and to Compute APIs to updates to network resources. If the BIG-IP is deployed without functioning routes to the internet, CFE cannot function as expected. Figure 1: BIG-IP VMs 1 cannot reach public API endpoints 2 because routes to internet 3 are removed Given that constraint, how can we make CFE work in truly isolated VPCs where internet access is prohibited? Private Google Access Enabling Private Google Access on each VPC subnet that may need to access Google Cloud APIs changes the underlying SDN so that the CIDRs for restricted.googleapis.com (or private.googleapis.com † ) will be routed without going through the internet. When combined with a private DNS zone which shadows all googleapis.com lookups to use the chosen protected endpoint range, the VPC networks effectively have access for all GCP APIs. The steps to do so are simple: Enable Private Google Access on each VPC subnet where a GCP API call may be sourced. Create a Cloud DNS private zone for googleapis.com that contains two records: CNAME for *.googleapis.com that responds with restricted.googleapis.com. A record for restricted.googleapis.com that resolves to each host in 199.36.153.4/30. Create a custom route on each VPC network for 199.36.153.4/30 with next-hop set for internet gateway. With this configuration in place, any VMs that are attached to the VPC networks that are associated with this private DNS zone will automatically try to use 199.36.153.4/30 endpoints for all GCP API calls without code changes, and the custom route will allow Private Google Access to function correctly. Automating with Terraform and Google Cloud Foundation Toolkit ‡ While you can perform the steps to enable private API access manually, it is always better to have a repeatable and reusable approach that can be automated as part of your infrastructure provisioning. My tool of choice for infrastructure automation is Hashicorp's Terraform, and Google's Cloud Foundation Toolkit, a set of Terraform modules that can create and configure GCP resources. By combining Google's modules with my own BIG-IP modules, we can build a repeatable solution for isolated VPC deployments; just change the variable definitions to deploy to development, testing/QA, and production. Cloud Failover Example Figure 2: Private Google Access 1 , custom DNS 2 , and custom routes 3 combine to enable API access 4 without public internet access A fully-functional example that builds out the infrastructure shown in figure 2 can be found in my GitHub repo f5-google-bigip-isolated-vpcs. When executed, Terraform will create three network VPCs that lack the default-internet egress route, but have a custom route defined to allow traffic to restricted.googleapis.com CIDR. A Cloud DNS private zone will be created to override wildcard googleapis.com lookups with restricted.googleapis.com, and the private zone will be enabled on all three VPC networks. A pair of BIG-IPs are instantiated with CFE enabled and configured to use a dedicated CFE bucket for state management. An IAP-enabled bastion host with tinyproxy allows for SSH and GUI access to the BIG-IPs (See the repo's README for full details on how to connect). Once logged in to the active BIG-IP, you can verify that the instances do not have access to the internet, and you can verify that CFE is functioning correctly by forcing the active instance to standby. Almost immediately you can see that the other BIG-IP instance has become the active instance. Notes † Private vs Restricted access GCP supports two protected endpoint options; private and restricted. Both allow access to GCP API endpoints without traversing the public internet, but restricted is integrated with VPC Service Controls. If you need access to a GCP API that is unsupported by VPC Service Controls, you can choose private access and change steps 2 and 3 above to use private.googleapis.com and 199.36.153.8/30 instead. ‡ Prefer Google Deployment Manager? My colleague Gert Wolfis has written a similar article that focuses on using GDM templates for BIG-IP deployment. You can find his article at https://devcentral.f5.com/s/articles/Deploy-BIG-IP-on-GCP-with-GDM-without-Internet-access.333Views1like0CommentsService Discovery in Google Cloud with F5 BIG-IP
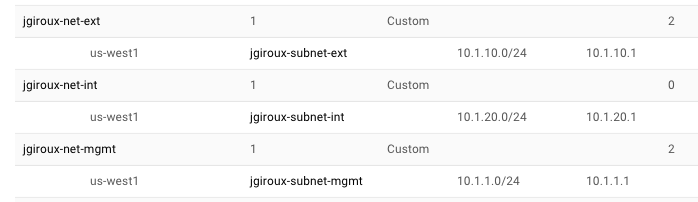
Service discovery allows cool things to happen like dynamic node discovery for your applications. The BIG-IP device can utilize service discovery to automate the scale in/out of pool members. What does this mean? Your BIG-IP configs will get updated without user intervention. Google Cloud uses "Labels" that are assigned to virtual machines (VM). The BIG-IP will use these "Labels" to automate the dynamic nature of pool members coming and going. It periodically scans the cloud provider for VMs matching those labels. Benefit? Yes indeed! No tickets to IT asking for pool member modifications...no waiting on emails...no approvals. I setup a BIG-IP (3nic standalone) with service discovery in Google Cloud using our F5 cloud templates on GitHub, and I am here to share the how-to and results. After reading the Github repo as well as visiting our CloudDocs site, I went to work. This article has the following sections: Prerequisites Download, Customize, and Deploy Template Attach Service Account to BIG-IP VM Login to the BIG-IP via SSH and Set Password Configure Service Discovery with iApp Configure Service Discovery with AS3 Summary Appendix Sections Prerequisites - Google Cloud SDK Must have Google Cloud SDK...easy. Go here https://cloud.google.com/sdk/docs/quickstarts. curl https://sdk.cloud.google.com | bash exec -l $SHELL gcloud init The Google Cloud SDK lets you do "?" and "tab" helpers. Meaning, type gcloud then hit tab a few times to see all the options. When you run "gcloud init", it will authenticate your device to the google network resulting in your laptop having Google Cloud API access. If you are running "gcloud init" for the first time, the SSH shell will pop open a browser window in which you authenticate to Google with your credentials. You'll be given an option to select the project name, and you can also configure default zones and regions. Play around with gcloud on CLI and then hit "tab" to see all the options. You can also the Google Cloud docs here https://cloud.google.com/sdk/docs/initializing. Prerequisites - VPC Networks, Subnets, Firewalls, and Routes A VM in Google Cloud can only have one NIC per VPC network. Therefore, a BIG-IP 3nic deployment requires 3 VPC networks with 1 subnet each. Before deploying the GDM template, you'll need to create the required networks and subnets. Then make sure any necessary ports are open via firewall rules. VPC Networks and Subnets Here are some screenshots of my setup. I have a management, external, and internal network. Here are the network and subnet properties for the management network as an example. Firewalls Modify firewall rules to allow any necessary management ports. These are not setup by the template. Therefore, common management ports like tcp:22 and tcp:443 should be created. Here is my management firewall ruleset as an example. In my example, my BIG-IP has additional interfaces (NICs) and therefore additional networks and firewall rules. Make sure to allow appropriate application access (ex. 80/443) to the NICs on the BIG-IP that are processing application traffic. Here is an example for my external NIC. Routes I didn't touch these. However, it is important to review the VPC network routes and make sure you have a default gateway if required. If the network is meant to be internal/private, then it's best to remove the default route pointing to internet gateway. Here is an example of my management network routes in use. Prerequisites - Service Account To do auto-discovery of pool members (aka Service Discovery), the BIG-IP device requires a role assigned to its VM. When a VM instance has an assigned role in the cloud, it will inherit permissions assigned by the role to do certain tasks like list compute instances, access cloud storage, re-map elastic IPs, and more. This avoids the need to hard-code credentials in application code. In the example of service discovery, we need the service account to have a minimum of "Compute Viewer" or "Compute Engine - Read Only" permissions. Other deployment examples may require more permissions such as storage permissions or pub-sub permissions. Create a new service account in the IAM section, then find "Service accounts". Here's an example of a new service account and role assigned. If done correctly, it will be visible as an IAM user. See below for example. Prerequisites - Pools Members Tagged Correctly Deploy the VM instances that will run your app...the pool members (e.g. http server running port 80) and add a "Label" name with value to each VM instance. For example, my label name = app. My label value = demo. Any VM instance in my project with label name = app, value = demo will be discovered by the BIG-IP and pulled in as new pool member(s). Example... Pre-reqs are done! Download and Customize YAML Template File The Google Cloud templates make use of a YAML file, a PY file, and a schema file (requirements and defaults). The GitHub README contains helpful guidance. Visit the GitHub site to download the necessary files. As a reminder, this demo uses the following 3nic standalone template: https://github.com/F5Networks/f5-google-gdm-templates/tree/master/supported/standalone/3nic/existing-stack/payg Scroll down to the "Deploying the template" section to review the requirements. Download the YAML file to your desktop and ALSO make sure to download the python (PY) and schema files to your desktop. Here's an example of my modified YAML file. Notice some fields are optional and not required by the template as noted in the GitHub README file parameters table. Therefore, 'mgmtSubnetAddress' is commented out and ignored, but I left it in the example for visualization purposes. # Copyright 2019 F5 Networks All rights reserved. # # Version 3.2.0 imports: - path: f5-existing-stack-payg-3nic-bigip.py resources: - name: f5-existing-stack-payg-3nic-bigip type: f5-existing-stack-payg-3nic-bigip.py properties: region: us-west1 availabilityZone1: us-west1-b mgmtNetwork: jgiroux-net-mgmt mgmtSubnet: jgiroux-subnet-mgmt #mgmtSubnetAddress: <DYNAMIC or address> restrictedSrcAddress: 0.0.0.0/0 restrictedSrcAddressApp: 0.0.0.0/0 network1: jgiroux-net-ext subnet1: jgiroux-subnet-ext #subnet1Address: <DYNAMIC or address> network2: jgiroux-net-int subnet2: jgiroux-subnet-int #subnet2Address: <DYNAMIC or address> provisionPublicIP: 'yes' imageName: f5-bigip-15-0-1-0-0-11-payg-best-25mbps-190803012348 instanceType: n1-standard-8 #mgmtGuiPort: <port> #applicationPort: <port port> #ntpServer: <server server> #timezone: <timezone> bigIpModules: ltm:nominal allowUsageAnalytics: 'yes' #logLevel: <level> declarationUrl: default Deploy Template Make sure you point to the correct file location, and you're ready to go! Again, reference the GitHub README for more info. Example syntax... gcloud deployment-manager deployments create <your-deployment-name> --config <your-file-name.yaml> Attach Service Account to BIG-IP VM Once deployed, you will need to attach the service account to the newly created BIG-IP VM instance. You do this by shutting down the BIG-IP VM instance, binding a service account to the VM, and then starting the VM again. It's worth noting that the template can be easily modified to include service account binding during VM instance creation. You can also do this via orchestration tools like Ansible or Terraform. Example... gcloud compute instances stop bigip1-jg-f5-sd gcloud compute instances set-service-account bigip1-jg-f5-sd --service-account svc-jgiroux@xxxxx.iam.gserviceaccount.com gcloud compute instances start bigip1-jg-f5-sd Login to the BIG-IP and Set Password You should have a running BIG-IP at this point with attached service account. In order to access the web UI, you'll need to first access SSH via SSH key authentication and then set the admin password There are orchestrated ways to do this, but let's do the old fashion manual way. First, go to Google Cloud Console, and view properties of the BIG-IP VM instance. Look for the mgmt NIC public IP. Note: In Google Cloud, the BIG-IP mgmt interface is swapped with NIC1 Open your favorite SSH client and access the BIG-IP. Make sure your SSH key already exists in your Google Console. Instructions for uploading SSH keys are found here. Example syntax... ssh admin@x.x.x.x -i /key/location Update the admin password and save config while on the TMOS CLI prompt. Here's an example. admin@(bigip1-jg-f5-sd)(tmos)# modify auth user admin password myNewPassword123! admin@(bigip1-jg-f5-sd)(tmos)# save sys config Now access the web UI using the mgmt public IP via https://x.x.x.x. Login with admin and the newly modified password. Configure Service Discovery with iApp The BIG-IP device is very programmable, and you can apply configurations using various methods like web UI or CLI, iApps, imperative APIs, and declarative APIs. For demo purposes, I will illustrate the iApp method in this section. The F5 cloud templates automatically include the Service Discovery iApp as part of the onboard and build process, but you'll still need to configure an application service. First, the CLI method is a quick TMSH one-liner to configure the app service using the Service Discovery iApp. It does the following: creates new app service called "serviceDiscovery" uses "gce" (Google) as provider chooses a region "default" (causes script to look in same region as BIG-IP VM) chooses intervals and health checks creates new pool, looks for pool tag:value (app=demo, port 80) tmsh create /sys application service serviceDiscovery template f5.service_discovery variables add { basic__advanced { value no } basic__display_help { value hide } cloud__cloud_provider { value gce } cloud__gce_region { value \"/#default#\" } monitor__frequency { value 30 } monitor__http_method { value GET } monitor__http_verison { value http11 } monitor__monitor { value \"/#create_new#\"} monitor__response { value \"\" } monitor__uri { value / } pool__interval { value 60 } pool__member_conn_limit { value 0 } pool__member_port { value 80 } pool__pool_to_use { value \"/#create_new#\" } pool__public_private {value private} pool__tag_key { value 'app'} pool__tag_value { value 'demo'} } If you still love the web UI, then go to the BIG-IP web UI > iApps > Application Services. If you executed the TMSH command above, then you should have an app service called "serviceDiscovery". Select it, then hit "Reconfigure" to review the settings. If no app service exists yet, then create a new app service and set it to match your environmental requirements. Here is my example. Validate Results of Service Discovery with iApp Review the /var/log/ltm file. It will show pool up/down messages for the service discovery pool. It will also indicate if the service discovery script is failing to run or not. tail -f /var/log/ltm Example showing successful member add to pool... Another place to look is the /var/log/cloud/service_discovery/get_nodes.log file. You'll see messages showing the script query and status. tail -f /var/log/cloud/service_discovery/get_nodes.log Example showing getNodes.js call and parameters with successful "finished" message... Last but not least, you can check the UI within the LTM > Pools section. Note: Service Discovery with iApp complete Attach this new pool to a BIG-IP virtual server, and now your app can dynamically scale. I'll leave the virtual server creation up to you! In other words...challenge time! For additional methods to configure service discovery on a BIG-IP, continue reading. Configure Service Discovery with AS3 (declarative option) As mentioned earlier, the BIG-IP device is very programmable. We used the iApp method to automate BIG-IP configs for pool members changes in the previous section. Now let's look at a declarative API approach using AS3 from the F5 Automation Toolchain. You can read more about AS3 - here. At a high level, AS3 enables L4-L7 application services to be managed in a declarative model. This enables teams to place BIG-IP security and traffic management services in orchestration pipelines and greatly eases the configuration of L4-L7 services. This also has the benefit of using consistent patterns to deploy and migrate applications. Similar to the Service Discovery iApp...the AS3 rpm comes bundled with the handy F5 cloud templates. If you deployed via alternative methods, if you do not have AS3 rpm pre-loaded, if you want to upgrade, or if you simply want a place to start learning, review the Quick Start AS3 Docs. Review the Additional Declarations for examples on how to use AS3 with iRules, WAF policies, and more. Note: AS3 is a declarative API and therefore no web UI exists to configure L4-L7 services. Postman will be used in my example to POST the JSON declaration. Open Postman, authenticate to the BIG-IP, and then post the app declaration. Learn how by reviewing the Quick Start AS3 Docs. Here's my example declaration. It does the following: creates new application (aka VIP) with public IP of 10.1.10.34 uses "gce" (Google) as cloud provider defines tenant as "Sample_sd_01" chooses a region "us-west1" in which to query for VMs creates new pool 'web_pool' with members matching tag=app, value=demo on port 80 { "class": "ADC", "schemaVersion": "3.0.0", "id": "urn:uuid:33045210-3ab8-4636-9b2a-c98d22ab425d", "controls": { "class": "Controls", "trace": true, "logLevel": "debug" }, "label": "GCP Service Discovery", "remark": "Simple HTTP application with a pool using GCP service discovery", "Sample_sd_01": { "class": "Tenant", "verifiers": { }, "A1": { "class": "Application", "template": "http", "serviceMain": { "class": "Service_HTTP", "virtualAddresses": [ "10.1.1.34" ], "pool": "web_pool" }, "web_pool": { "class": "Pool", "monitors": [ "http" ], "members": [ { "servicePort": 80, "addressDiscovery": "gce", "updateInterval": 1, "tagKey": "app", "tagValue": "demo", "addressRealm": "private", "region": "us-west1" } ] } } } } Validate Results of Service Discovery with AS3 Similar to the iApp method, review the /var/log/ltm file to validate AS3 pool member discovery. You'll see basic pool member up/down messages. tail -f /var/log/ltm Example showing successful member add to pool... Another place to look is the /var/log/restnoded/restnoded.log file. You'll see messages showing status. tail -f /var/log/restnoded/restnoded.log Example showing restnoded.log sample logs... Last but not least, you can check the UI within the LTM > Pools section. AS3 is multi-tenant and therefore uses partitions (tenants). Make sure to change the partition in upper-right corner of web UI if you don't see your config objects. Change partition... View pool and pool member... As a bonus, you can test the application from a web browser. AS3 deployed full L4-L7 services in my example. Therefore, it also deployed a virtual server listening on the value in declaration parameter 'virtualAddresses' which is IP 10.1.10.34. Here is my virtual server example... This IP of 10.1.10.34 maps to a public IP associated with the BIG-IP VM in Google Cloud of 34.82.79.120 on nic0. See example NIC layout below... Open a web browser and test the app on http://34.82.79.120. Note: Service Discovery with AS3 complete Great job! You're done! Review the Appendix sections for more information. Summary I hope you enjoyed this writeup and gained some new knowledge along the way. I demonstrated a basic Google Cloud network, deployed an F5 BIG-IP instance using F5 cloud templates, and then configured service discovery to dynamically populate pool members. As for other general guidance around BIG-IP and high availability designs in the cloud, I'll leave those details for another article. Appendix: Google Networking and BIG-IP Listeners In my example, I have an external IP mapping to the BIG-IP VM private IP on nic0...no forwarding rules. Therefore Google NATs the incoming traffic from 34.82.79.120 to the VM private IP 10.1.10.34. The BIG-IP virtual server listener will be 10.1.10.34. On the other hand, Google Cloud forwarding rules map public IPs to VM instances and do not NAT. Therefore a forwarding rule of 35.85.85.125 mapping to my BIG-IP VM will result in a virtual server listener of 35.85.85.125. Remember... External public IP > VM private IP mapping = NAT to VM Forwarding rule public IP > VM instance = no NAT to VM Learn more about Google Cloud forwarding rules in the following links: Forwarding Rule Concepts - how rules interact with Google LBs Using Protocol Forwarding - allowing multiple public IPs to one VM with forwarding rules Appendix: Example Errors This is an example of incorrect permissions. You will find this in /var/log/ltm. The iCall script runs and calls the cloud provider API to get a list of pool members. Jan 24 23:40:00 jg-f5-sd err scriptd[26229]: 014f0013:3: Script (/Common/serviceDiscovery.app/serviceDiscovery_service_discovery_icall_script) generated this Tcl error: (script did not successfully complete: (jq: error: unxpected response from node worker while executing "exec /bin/bash -c "NODE_JSON=\$(curl -sku admin: https://localhost:$mgmt_port/mgmt/shared/cloud/nodes?mgmtPort=$mgmt_port\\&cloud=gce\\&memberTag=app=..." invoked from within "set members [exec /bin/bash -c "NODE_JSON=\$(curl -sku admin: https://localhost:$mgmt_port/mgmt/shared/cloud/nodes?mgmtPort=$mgmt_port\\&cloud=gce\\&m..." line:4)) Review the iCall script to see the curl command running against the cloud provider. Run it manually via CLI for troubleshooting. curl -sku admin: "https://localhost/mgmt/shared/cloud/nodes?mgmtPort=443&cloud=gce&memberTag=app=demo&memberAddressType=private&memberPort=80&providerOptions=region%3d" {"error":{"code":500,"message":"Required 'compute.instances.list' permission for 'projects/xxxxx'","innererror":{"referer":"restnoded","originalRequestBody":"","errorStack":[]}}} From the output, I had the wrong permissions as indicated in the logs (error 500 permissions). Correct the permissions for the service account that is in use by the BIG-IP VM.1.3KViews1like2CommentsJourney to the Multi-Cloud Challenges
Introduction The proliferation of internet-based applications, digital transformations accelerated by the pandemic, an increase in multi-cloud adoption, and the rise of the distributed cloud paradigm allbringnew business opportunitiesas well as new operational challenges. According to Propeller Insights Survey; 75% of all organizations are deploying apps in multiple clouds. 63% of those organizations are usingthree or more clouds. And 56% are findingit difficult to manage workloads across different cloud providers, citing challenges with security, reliability, and connectivity. Below I outline some of the common challenges F5 has seen and illustrate how F5 Distributed Cloud is able to address those challenges.For the purpose of the following examples I am using this demo architecture. Challenge #1: IP Conflict and IP exhaustion As organizations accelerate their digital transformation, they begin to experience significant network growth and changes. As their adoption of multiple public clouds and edge providers expands, they begin to encounter challenges with IP overlap and IP exhaustion. Typically, thesechallenges seldom happen on the Internet as IP addresses are centrally managed. However, this challenge is common for non-Internet traffic becauseorganizations use private/reserved IP ranges (RFC1918) within their networks and any organization is free to use any private ranges they want. This presents a increasingly common problem as networks expand into public clouds, with the ease of infrastructure bootstrapping using automation, the needs of multi-cloud networking, and finally mergers and acquisitions. The F5 Distributed Cloud canhelp organizations overcome IP conflict and IP exhaustion challenges by provisioning multiple apps with a single IP address. How to Provision Multiple Apps with a Single IP Address (~8min) Challenge #2: Easy consumable application services via service catalogue A multi-cloudparadigm causes applications to be very distributed. We often seeapplications running on multiple on-prem data centers, at the edge, and inpublic cloud infrastructure. Making those applicationseasily available ofteninvolves many infrastructureand security control changes - not an easy task. This includes common tasks such as service advertisement, updates to network routing and switching, changing firewall rules, and provisioning DNS.In this demo, wedemonstrate how to seamlessly provision and advertise services, to and from public cloud providers anddata centers. This capability enables an organization to seamlessly provision services and create consumable service catalogues. How to Seamlessly Provision Services to/from the Cloud Edge (~4min) Challenge #3: Operational (Day-2) Complexities Often users have multiple discreet tools managing their infrastructure and each toolprovides their owndashboard for telemetry, visibility, and observability. Users need access to all these tools into a single consistent view so they can tell exactly what is happening in their environments. F5 Distributed Cloud Console provides a 'single pane of glass' for telemetry, visibility and observability providing operational efficiency for Day-2 operations designed to reduce total cost of ownership. Get a Single Pane of Glass on Telemetry, Visibility and Observability (~7min) Challenge #4: Cloud Vendor lock-in impede business agility. Most organizations do not want their cloud workload locked into a particular cloud provider.Cloud vendor lock-in can bea major barrier to the adoption of cloud computing and CIO's show some concern with vendor lock-in perFlexera's2020 CIO Priorities Report,To avoid cloud lock-in, create application resiliency,and get back some of the freedoms of cloud consumption - movingworkload from cloud to cloud - organizations need to be able to dynamically movecloud providers quickly and easilyin the unlikely event that one cloud provider becomes unavailable. Workload Portability - How to Seamlessly Move Workloads from Cloud to Cloud (~4min) Challenge #5: Consistent Security Policiesacross clouds How do you ensure that every security policy you require is applied and enforced consistentlyacross the entire fleet of endpoints? According to F5 2020 State of Application Services Report, 59% of respondents said thatapplying consistent security policies across all company applications was one of their biggestchallenges in multi-cloud security. This demo shows how to apply consistent security policies(WAF) across a fleet of cloud workloads deployed at the edge. This helps reduce risk, increasecompliance, and helps maintaineffective governance. How to Apply Consistent Security Policies Across Clouds (~5min) Challenge #6: Complexities of multiple cloud networking and integration with AWS transit gateway – management of security controls. A multi-cloud strategy introducescomplexities aroundnetworking and security control between clouds and within clouds. Within one cloud (e.g., AWS VPC), an organization may use the AWS transit gateway (TGW) to stitch together the Inter-VPC communication. Managingmultiple VPCs attached to a TGW is, by itself, a challenge in managing security control between VPC. In this demo, we show a simple way to leverage the F5 Distributed Cloud integration with AWS TGW to manage security policy across VPCs(also known as East-West traffic). This demo also demonstrates connecting an AWS VPC with other cloud providers such as Azure, GCP, or an on-prem cloud solution in order to unify theconnectivity and reachability of your workload. Multi-Cloud Integration with AWS Transit Gateway (~19min) 1KViews1like0Comments
1KViews1like0Comments
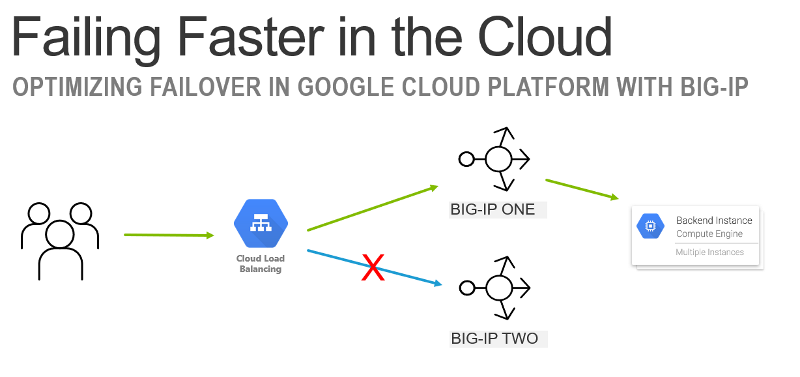
Failing Faster in the Cloud
In this article we look at how to to minimize dropped connections during a planned failover in an Active/Stand-by setup using the GoogleCloudLoad Balancer (GCLB) in front of BIG-IP.This is a companion article to the video demo onDevCentralYouTube (linked below). Failing Faster You are doing your job when you fail. You are successful at your job when you failfastand recover. On Premises versus Cloud BIG-IP can use gratuitous ARP to trigger a very fast device failover in an active/stand-by (A/S) configurationin an on-premises environment.In a cloud environment there is no Layer 2 environment to supportARP.Insteadthe BIG-IP must rely on DNS, API calls, or a “native” load balancer to trigger failover.This can vary failover time from seconds to minutes depending on the failover mechanism. Load Balancing Load Balancers It may seem odd but load balancing load balancers is not uncommon.Two-tierscan provide an easier architecture to maintain and provide greater flexibility.In this scenario the Google Cloud LoadBalancerwillbe acting as a L4 TCP proxy that brings traffic to the BIG-IP to apply L7 HTTP policies (I.e. WAF protection). Google Deployment Manager Template Getting started in the cloud can be challenging.F5 provides Google Deployment Manager (GDM) Templates to expedite your launch into the cloud.We will focus on the “via-lb” template that takes care of setting up a pair of BIG-IP in an A/S configuration and using GCLB in front.It can also be used for an A/A configuration,this is described later in the article.There is also a “via-api” method that does not use GCLB that can be useful in scenarios where it is desired to have direct access to the packet and/or a non-TCP based service.For more information about deploying in GCP with BIG-IP please visit: https://clouddocs.f5.com/cloud/public/v1/google_index.html Failover Out of the Box After deploying the“via-lb”GDM template you will have a scenario where the GCLB is sending traffic to the active BIG-IP. The template also creates two virtual servers.One for data-plane traffic (port 80) and one for monitoring (port 40000). Bad Failover When a failover is triggered the BIG-IP that was previously active begins to drop connections immediately.This is due to both the data-plane and monitoring service will default to dropping connections when a BIG-IP goes into stand-by mode.Since the GCLB considers the device that was previously “stand-by” as down (health checks were failing while in stand-by mode) it has to wait until it detects the second device as “healthy” before sending traffic to that device. Depending on the threshold of how GCLB is configured this could take 10-15 seconds to occur.This isn’t terrible(acceptable for most basic use cases), butbadif you have an application that is sensitive todropped connections. Good Failover To make failover occur faster we can modify the settingsofthe BIG-IPto improve the failover time.The two changes are: Use Traffic Group “NONE” for data-plane This enables the BIG-IP to still accept traffic when the device is in “stand-by” mode Use separate health monitor for Google Load Balancer Allow health monitor to reject traffic while data-plane still accepts traffic Traffic Group “NONE” Changingthetraffic groupto NONEofthevirtual-address of thevirtual serverwill cause the BIG-IP to always respond to traffic.This is not safe to do in an on-premises environment (will create IP address conflicts), butis OK to perform in a cloud environment where the networking is “owned” by the cloud provider.This allows the BIG-IP to still accept connections when it is in stand-by mode. When you change the virtual-address to traffic group NONE this creates an Active/Active (A/A) configuration.Both the data-plane and health monitor will always respond to traffic.In order to make it act as an A/S configuration you need to make an additional change. Separate Health Monitor for GCLB The second change is to create a separate health monitor that will track the state of the BIG-IP.This will allowGCLB to detect when a device has gone into stand-by mode and stop sending traffic to that device. One method of configuring the health monitor is to create a new health monitor on a “bogus” virtual server (I.e. 255.255.255.254) that is on the default “traffic-group-1".The existing monitor can be replaced with a new monitor that uses aniRuleto target the “bogus” virtual.The result of this is the health monitor will go “down” when the BIG-IP is in stand-by, but the “real” virtual server will still accept traffic. The Demo This failover can be seen in the demo video where you can see both the “Bad” and the “Good” failover occurringsimultaneously,and you can comparethe results (spoileralert: Good is better). To help visualize the failover I created a Python script that displays “All Good” while the service is up.When a failure is detected it displays “Trouble!”.In the video you can see that the “Bad” failover drops connections for ~20 seconds.The “Good” failover does not drop any connections.The script tests for failures by establishing a new connection once a second and timing out if the connection takes longer than 1 second to be created. Bad Failover: 20 seconds of dropped connections Good Failover: No dropped connections Also works in the “other” clouds This article featured Google Cloud Platform, but the same methodology can be applied in other cloud environments as well.It is not always necessary to use A/Sor it may be OK to drop connections for a brief period of time; but in case it isn’t, you now know how to fail faster in the cloud.1.4KViews1like0Comments