Taking Comfort In Understanding File Virtualization Terminology
Have you ever began boarding an airplane and thought to yourself, "Wow, this plane is huge… and it's about to fly through the air? How crazy is that?" To make myself feel better I like to see the man or women behind the "wheel" of such a large flying steel tube. Just to look them in the eye, give them a nod and take my seat. It makes me feel better knowing just a little about who is controlling my destiny and feel comfortable that this person will get me to my destination. Understanding a little bit about your situation, from something as simple as seeing your pilot, gives you comfort in knowing things will be okay. The same situation can be said about technology and its impact on your life. Technology can be confusing and riddled with technical specifications and terminology that leaves you feeling very uncomfortable. File Virtualization is a technology that is designed to bring understanding and order in an environment of chaos and confusion. Yet, very few people take the time to understand File Virtualization so they can feel a bit more comfortable with what they're about to install, in-line, into a network environment. While the F5 ARX may not be a human you can glance at and tip your hat, it still requires you to seek out a little bit of "comfort" to know your ride is going to be okay. I firmly believe that comfort in a solution is more important than full feature set. Maybe I'm alone in that concept but, just like my airplane analogy, I take more comfort in seeing the pilot eye to eye if for only a glance than knowing how many exits the plane has or what inflatable device I have under my seat to potentially save my life. I don't take 100% comfort in knowing I have a little inflatable raft to save me incase a ton of steel screams headfirst into the ocean--maybe that's just me. Taking Comfort In Understanding File Virtualization and Metadata. Understanding some of the basic terminology sure as heck wouldn't hurt! This doesn't mean knowing the processor speeds or the inner workings to how a file migrates from one share to another, that's pretty "in the weeds" with the technology and, at the end of the day, as long as the files get to their destination without error and on time, you probably don't care about the nitty gritty details (and if you do, we have plenty of technical tips). We're talking metadata access, modify and data plane operations. Much like a highway, your data is traveling as fast as they're allowed to travel and continue taking the correct exits as needed. Not all roads are created equal, sometimes congestion occurs, tolls are passed and you move from your origin to a known destination--file system operations do all the same things. By understanding what metadata access and modify does, at a high level, and the idea behind a data plane you can walk away feeling that you "understand" what this F5 ARX is doing in the environment and, perhaps, a little bit about how its bringing order to the chaos. Today, I'd like to define four terms I use day-to-day when working with potential customer installations. These terms go hand in hand with "sizing" and "understanding" of a customers environment. Of course, the only way to do this is to compare metadata operations to that of a police officer pulling you over for speeding, right? Data Plane Operations: These file operations are the fastest and the F5 ARX hardware is optimized to handle them as quickly and efficiently as possible. The best-case scenario, in a storage environment, would be to have an extremely high proportion of data plane operations and a minimal amount of metadata and control plane operations. The file system operations that get to stay on the data plane are the Porsche's and Ferrari's of the data storage world. Examples:Flush, Read, Write, Access, etc. Metadata: Information about information! When we're talking about metadata, in our File Virtualization examples, we're talking about small descriptions of data that the F5 ARX finds important, from object names to object attributes. Imagine your drivers license as metadata, when an officer pulls you over for speeding they use this information to find out more about you and what you're all about; this may include the class of vehicle you're licensed to drive, expiration dates and state/town you inhabit. If the officer needs to know more detailed information about, you such as how many children you have, or what home town you grew up in, that goes beyond metadata and would require additional questioning. Metadata Access Operations: These operations are slightly slower than data plane operations because it requires the operation to move from the data plane to the control plane to better analyze and assistance on the in-flight operation. This often leads to a metadata read operation (one that does not modify metadata) but is often subject to optimization techniques. A police officer can read your license "metadata" as they walk back to their car and know your name and the city you live in right away; it's more efficient than waiting to sit in their car before glancing at your license. Examples:LOOKUP, Query File Information, Find First, Find Next, FSSTAT, Lookup, etc. Metadata Modifying Operations: These file system operations will pass through the data plane to the control plane and update the ARX metadata with changes. This may be due to attribute changes, filename changes and other such operations. While metadata modifying operations are usually less frequent than other operations, it’s important to watch their frequency for environments with intense metadata modifying operations. If a police officer has to write you a ticket, it will take more time than simply walking back to your car and saying "okay, you can go" while handing back your license. Examples: Create, Delete, Rename, Make Directory, etc. As with many things, understanding the knowledge and terms require more time than understanding how it can be implemented to help you. Each ARX platform is designed to handle a specific size network environment, the more beefy ARX platforms are designed to handle massive scale, file counts and can juggle more metadata access and modify operations than its smaller counterparts. If you first understand how to speak the language of File Virtualization you'll begin to understand more about what solutions may work better for you.324Views0likes1Comment
SSDs, Velocity and the Rate of Change.
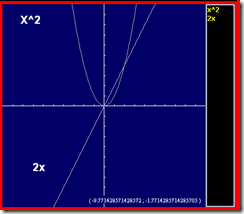
The rate of change in a mathematical equation can vary immensely based upon the equation and the inputs to the equation. Certainly the rate of change for f(x) = x^2 is a far different picture than the rate of change for f(x)=2x, for example. The old adage “the only constant is change” is absolutely true in high tech. The definition of “high” in tech changes every time something becomes mainstream. You’re working with tools and systems that even ten years ago were hardly imaginable. You’re carrying a phone that Alexander Graham Bell would not recognize – or know how to use. You have tablets with the power that was not so long ago only held by mainframes. But that change did not occur overnight. Apologies to iPhone fans, but all the bits Apple put together to produce the iPhone had existed before, Apple merely had the foresight to see how they could be put together in a way customers would love. The changes happen over time, and we’re in the midst of them, sometimes that’s difficult to remember. Sometimes that’s really easy to remember, as our brand-new system or piece of architecture gives us headaches. Depends upon the day. Image generated at Cool Math So what is coming of age right now? Well, SSDs for one. They’re being deployed in the numbers that were expected long ago, largely because prices have come down far enough to make them affordable. We offer an SSD option for some of our systems these days, and since the stability of our products is of tantamount to our customers’ interests, we certainly aren’t out there on the cutting edge with this development. They’re stable enough for mission critical use, and the uptick in sales reflects that fact. If you have a high-performance application that relies upon speedy database access, you might look into them. There are a lot of other valid places to deploy SSDs – Tier one for example – but a database is an easy win. If access times are impacting application performance, it is relatively easy to drop in an SSD drive and point the DB (cache or the whole DB) at them, speeding performance of every application that relies on that DBMS. That’s an equation that is pretty simple to figure out, even if the precise numbers are elusive. Faster disk access = faster database response times = faster applications. That is the same type of equation that led us to offer SSDs for some of our products. They sit in the network between data and the applications that need the data. Faster is better, assuming reliability, which after years of tweaking and incremental development, SSDs offer. Another place to consider SSDs is in your virtual environment. If you have twenty VMs on a server, and two of them have high disk access requirements, putting SSDs into place will lighten the load on the overall system simply by reducing the blocking time waiting for disk responses. While there are some starting to call for SSDs everywhere, remember that there were some who said cloud computing meant no one should ever build out a datacenter again also. The price of HDs has gone down with the price of SSDs pushing them from the top, so there is still a significant cost differential, and frankly, a lot of applications just don’t need the level of performance that SSDs offer. The final place I’ll offer up for SSDs is if you are implementing storage tiering such as that available through our ARX product. If you have high-performance NAS needs, placing an SSD array as tier one behind a tiering device can significantly speed access to the files most frequently used. And that acceleration is global to the organization. All clients/apps that access the data receive the performance boost, making it another high-gain solution. Will we eventually end up in a market where old-school HDDs are a thing of the past and we’re all using SSDs for everything? I honestly can’t say. We have plenty of examples in high-tech where as demand went down, the older technology started to cost more because margins plus volume equals profit. Tube monitors versus LCDs, a variety of memory types, and even big old HDDs – the 5.25 inch ones. But the key is whether SDDs can fulfill all the roles of HDDs, and whether you and I believe they can. That has yet to be seen, IMO. The arc of price reduction for both HDDs and SSDs plays in there also – if quality HDDs remain cheaper, they’ll remain heavily used. If they don’t, that market will get eaten by SSDs just because all other things being roughly equal, speed wins. It’s an interesting time. I’m trying to come up with a plausible use for this puppy just so I can buy one and play with it. Suggestions are welcome, our websites don’t have enough volume to warrant it, and this monster for laptop backups would be extreme – though it would shorten my personal backup window ;-). OCZ Technology 1 TB SSD. The Golden Age of Data Mobility? What Do You Really Need? Use the Force Luke. (Zzzaap) Don't Confuse A Rubber Stamp With Validation On Cloud, Integration and Performance Data Center Feng Shui: Architecting for Predictable Performance F5 Friday: Performance, Throughput and DPS F5 Friday: Performance Analytics–More Than Eye-Candy Reports Audio White Paper - High-Performance DNS Services in BIG-IP ... Analyzing Performance Metrics for File Virtualization264Views0likes0CommentsIn The End, You Have to Clean.
Lori and I have a large technical reference library, both in print and electronic. Part of the reason it is large is because we are electronics geeks. We seriously want to know what there is to know about computers, networks, systems, and development tools. Part of the reason is that we don’t often enough sit down and decide to pare the collection down by those books that no longer have a valid reason for sitting on our (many) bookshelves of technical reference. The collection runs the gamut from the outdated to the state of the art, from the old stand-byes to the obscure, and we’ve been at it for 20 years… So many of them just don’t belong any more. One time we went through and cleaned up. The few books we got rid of were not only out of date (mainframe pascal data structures was one of them), but weren’t very good when they were new. And we need to do it again.From where I sit at my desk, I can see an OSF DCE reference, the Turbo Assembler documentation, A Perl 5 reference, a MicroC/OS-II reference, and Mastering Web Server Security. All of which are just not relevant anymore. There’s more, but I’ll save you the pain, you get the point. The thing is, I’m more likely to take a ton of my valuable time and sort through these books, recycling those that no longer make sense unless they have sentimental value - Lori and I wrote an Object Oriented Programming book back in 1996, that’s not going to recycling – than you are to go through your file system and clean the junk out of it. Two of ten… Funny thing happens in highly complex areas of human endeavor, people start avoiding ugly truths by thinking they’re someone else’s problem. In my case (and Lori’s), I worry about recycling a book that she has a future use for. Someone else’s problem syndrome (or an SEP field if you read Douglas Adams) has been the source of tremendous folly throughout mankind’s history, and storage at enterprises is a prime example of just such folly. Now don’t bet me wrong, I’ve been around the block, responsible for an ever-growing pool of storage, know that IT management has to worry that the second they start deleting unused files they’re going to end up in the hotseat because someone thought they needed the picture of the sign in front of the building circa 1995… But if IT (who owns the storage space) isn’t doing it, and business unit leaders (who own the files on the storage) aren’t doing it… Well, you’re going to have a nice big stack of storage building up over the next couple of years. Just like the last couple. I could – and will - tell you that you can use our ARX product to help you solve the problem, particularly with ARX Cloud Extender and a trusted cloud provider, by shuffling out to the cloud. But in the longer term, you’ve got to clean up the bookshelf, so-to-speak. ARX is very good at many things, but not making those extra files disappear. You’re going to pay for more disk, or you’re going to pay a cloud provider until you delete them. I haven’t been in IT management for a while, but if I were right now, I’d get the storage guys to build me a pie-chart showing who owns how much data, then gather a couple of outrageous examples of wasted space (a PowerPoint that is more than five years old is good, better than the football pool for marketing from ten years ago, because PowerPoint uses a ton more disk space), and then talk with business leaders about the savings they can bring the company by cleaning up. While you can’t make it their priority, you can give them the information they need. If marketing is responsible for 30% of the disk usage on NAS boxes (or I suppose unstructured storage in general, though this exercise is more complex with mixed SAN/NAS numbers, not terribly more complex), and you can show that 40% of the files owned by Marketing haven’t been touched in a year… That’s compelling at the C-level. 12% of your disk is sitting there just from one department with easy to identify unused files on it. Some CIOs I’ve known have laid the smackdown – “delete X percent by Y date or we will remove this list of files” is actually from a CIOs memo – but that’s just bad PR in my opinion. Convincing business leaders that they’re costing the company money – what’s 12% of your NAS investment for example, plus 12% of the time of the storage staff dedicated to NAS – is a much better plan, because you’re not the bad guy, you’re the person trying to save money while not negatively impacting their jobs. So yeah, install ARX, because it has a ton of other benefits, but go to the bookshelf, dust off that copy of the Fedora 2 Admin Guide, and finally put it to rest. That’s what I’ll be doing this weekend, I know that.179Views0likes0CommentsAnalyzing Performance Metrics for File Virtualization
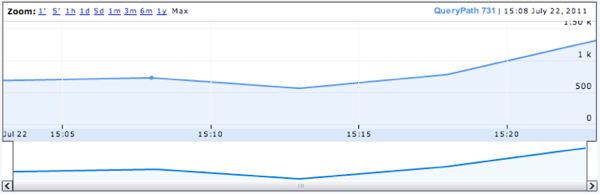
Trying to analyze your file storage from an RPC-level can be a challenge, but the fruits of your labor can be tasty if you put in the work (sorry, went Apple picking last weekend and it’s still on my mind.) It is time to bust out your storage solutions command reference and begin searching for “show screens” for finding statistics counts for the CIFS and NFS RPCs. File Virtualization can be very beneficial for complex environments, but understanding your environment goes beyond simply knowing how big your files are and how many files you have on disks in your data center. Let’s take some time to draw out some theories as to how we can analyze the statistics on our file storage devices using their text-based statistical screens. Our two big examples, as some may expect, are Network Appliance and EMC and, while their statistics are similar, we’re going to focus mainly on Network Appliance storage but the results can be applied to many devices on the market. We’ll capture both NFS and CIFS RPC’s so that we can understand their impact on the environment (including the absence of statistics because no statistics will still be important information). The two commands we’ll focus on are called “cifs stat” and “nfs stat” which, as you may guess, show statistics for CIFS and NFS respectively. While the output is extensive, here is a small example of a the CIFS information from this output: cifs stat ... find_first22044150854 10% find_next261012764 0% query_fs_info378632530% query_path_info709707294335% set_path_info00% query_file_info9840657795% set_file_info1501991131% create_dir200% ... These statistics can, often times, be super-intimidating because they are often extremely large and, alone, extremely limited in use. For instance, what does 7097072943 really mean for the “query_path_info” CIFS RPC? Of course, you can clear the statistics and start watching them closer from here on out, or you can utilize these large numbers as your initial “baseline” and continue to monitor the statistics over a set interval. If you’ve not figured it out already, that’s what we’re going to do, save clearing statistics for the newbies, we’re going hardcore! (okay, some administrators may not want you to do this or not give you access to clear their statistics, rightly so.) The first step I suggest would be to pick a language that is easily accessible to your environment for scripting; you may choose TCL because you are familiar with it and on a Unix/Linux/OSX system, like myself, or Visual Basic Script (VBS) for those that require Microsoft Windows in their environment. One key factor in this scripting language is the ability to utilize tools like RSH, SSH or Telnet in order to access the remote storage device to issue the required commands. For our VBS solutions, we’ve made use of putty/plink with to authenticate into a remote system. With TCL, the expect package has most of the tools to spawn off ssh/rsh and other shell activity. Using TCL as a base example, I’ve designed an interface in which a variable $style represents SSH/TELNET or RSH: switch -- $style { "rsh" { set useRSH true } # Login via TELNET "telnet" { spawn telnet "$host" handleTELNET $user $password $prompt } # Login via SSH "ssh" { spawn ssh "$user@$host" handleSSH $password $prompt } } The above logic breaks out the correct login handler and then “handles” the negotiations of authentication before continuing. In the case of RSH, it’s extremely beautiful in its lack of authentication (don’t tell the security guys, but this is the easiest method of scripting!) While we don’t show the boring handler functions here, these functions do the heavy lifting of awaiting password prompts, supplying the credentials and awaiting an initial prompt. For Network Appliance, I encourage the use of RSH because it doesn’t count as an authenticated user so, in the case in which an administrator is already logged in, it won’t boot you offline when too many sessions have connected. If you’re consistently booted off the system you’ll have a very difficult time getting timed interval statistics. Once you’ve successfully logged in you can poll for statistics. For sanity, I always first poll for the version of the software followed by the statistics and keep a time stamp and counter for the iteration so that we can graph the trends over time. A high level example may look like: set stamp [clock format $seconds -format "%D %H:%M:%S"] puts $fd "INDEX: $index" puts $fd "TIME: $stamp\n" puts $fd [sendCMD $prompt "version"] puts $fd [sendCMD $prompt "cifs stat" ] puts $fd [sendCMD $prompt "nfs stat" ] Here we write to our log file (the file handle $fd, which must be opened before logging) and write an index counter (starting at zero or one and incrementing each iteration) along with the current time stamp and then get the version and statistics information. Our little function “sendCMD” does the send and expect function calls to ship the information to the filer and return the results. These results are stored in our log file and look very much like the command we issued on the filer. Toss this logic around a loop and sleep for some set interval (I like a 5-minute sleep timer) and re-run it again with a new $index and timestamp against the storage filer for a few days or a week and you’ll end up with a great trend of important RPC information fully logged and ready to parse! How Do I Parse This Epic RPC Data!? With the tricky use of regular expressions or your favorite text-extraction mechanism, you’ll want to pull out each RPC and its associated value so you can examine it closer. Let’s use the attribute retrieval RPC again: query_path_info 7097072943 35% This can be stored so that we record “query_path_info” and “7097072943” using your favorite string parsing mechanism, we don’t need the 35% to really get the meat of the RPC. Continue to record that information for every interval in our log output for trending and graphing, as long as you feel it worth, but I suggest you measure that time in days not hours. Let’s pretend this was the only RPC in our output in order to avoid any confusion. Assuming query_path_info was recorded in our little log file six times (only 6-intervals, but it’s just an example), we’d have values of ever incrementing counts like: query_path_info7097072943 query_path_info7097278634 query_path_info7097497868 query_path_info7097667437 query_path_info7097902576 query_path_info7098298014 Assuming we’ve logged this information every 5-minutes and we have a total of six iterations of the statistic in our log file, we can start building some trending. First, lets normalize this data and assume the first entry is our “baseline” value as we said above, that means we set this to zero and find the incremental differences in the data, we also drop off the very last statistical value because it doesn’t have any more statistics to build a difference from (you can’t subtract from nothing!) So, let’s do some 2nd grade math here with some 4rd grade numbers: RPCValue(This RPC - Last RPC) query_path_info0 query_path_info 205691(7097278634 - 7097072943) query_path_info 219234(7097497868 – 7097278634) query_path_info 169569(7097667437 – 7097497868) query_path_info 235139(7097902576 – 7097667437) query_path_info 395438(7098298014 – 7097902576) query_path_info 7098298014 (no future RPC’s) This example reduces the big intimidating numbers down to something more manageable; this represents the total number of query_path_info RPC calls that have occurred between the 5-minutes our script sat sleeping at the wheel—the difference from the first interval to the second interval. To build these, we took the differences of the RPC that occurred at time n from the RPC that occurred at time n+5-minutes to figure out how many RPC’s occurred between the two intervals. You can run your subtraction in the opposite order if you use absolute values or, in other means, drop that negative sign (e.g. 7097072943 - 7097278634 = abs( -205691 ) ). Let’s reduce them even further by calculating the query_path_info RPC’s “per second” over that five minute interval. Given the constant that 5-minutes comes down to 300-seconds (5 x 60) we can break those out with the following mathematical results: RPCPer/Second# (Value / 5-minutes) query_path_info686/second(205691 / 300) query_path_info731/second(219234 / 300) query_path_info565/second(169569 / 300) query_path_info784/second(235139 / 300) query_path_info1,318/second(395438 / 300) Of course, nothing is perfect; we’ve given up some statistical value by rounding up a bit. For example, we report 686 query_path_info RPC’s a second in our first result even though the true result is 685.63667 for simplicity—yes we’re lying. We round up because an environment being sized for File Virtualization might as well take into consideration the worst case so that the correct hardware can be implemented with room for growth. If we design these simple mathematical equations into a little web user-interface using PHP or Python, you can build off some free tools like Google Charts to lay out your RPC counts into some pretty neat graphs. Using an Annotated Timeline chart, assuming you’re also recording that timestamp we talked about above, you can generate an HTML chart similar to (but abridge, we left out some wordy code just for the example): function drawChart() { var data = new google.visualization.DataTable(); data.addColumn('datetime', 'Date'); data.addColumn('number', 'QueryPath'); data.addRows(5); data.setValue( 0, 0, new Date( 2011, 06, 22, 15, 03 ) ); data.setValue( 0, 1, 686); data.setValue( 1, 0, new Date( 2011, 06, 22, 15, 08 ) ); data.setValue( 1, 1, 731); data.setValue( 2, 0, new Date( 2011, 06, 22, 15, 13 ) ); data.setValue( 2, 1, 565); data.setValue( 3, 0, new Date( 2011, 06, 22, 15, 18 ) ); data.setValue( 3, 1, 784); data.setValue( 4, 0, new Date( 2011, 06, 22, 15, 23 ) ); data.setValue( 4, 1, 1318); var chart = new google.visualization.AnnotatedTimeLine( document.getElementById('chart_cifs_qpi') ); chart.draw(data, {displayAnnotations: true} ); } The google API will then render the text to look super awesome, much like their financial graphs in timeline form like: This chart took the information we generated, simplified and reduced to a “per second” interval and develops a timeline trend for the given RPC. This is a simple example, but when implemented with all RPC’s you want to track, you can build a diagram more like: This timeline takes into account (using the same mathematical equations) a mapping of the CIFS FindFirst, FindNext, QueryPath and QueryFile from the statistics within the ‘cifs stat’ calls, over a 5-minute interval for five days worth of time. With this data, we can start to develop trends and understand what the clients within an environment are doing. In this larger example we can theorize a number of active file operations occurring on Saturday with the increase in QueryFile RPC’s, which a Microsoft Windows client typically does before opening a file for create/read/write activity. The weekend also shows a large amount of file system activity with QueryPath information and directory listings (indicated by the FindFirst calls). Lower FindNext RPC calls suggests that most CIFS directory listings can be returned in a single RPC request without needing to ‘next’ through for additional information. I also call into question the ethics of such a scenario having their folks work on Saturdays! In all reality, however, these are probably automated systems or system backups executing during off-peak hours to prevent heavy load during the workday. Next time you have a chance to sit down, think about your poor storage devices and consider all the work they have to do throughout the day. Consider designing some tools to really understand how your data is being used. Understanding your data will better prepare you for the realization that you might need a file virtualization solution like the ARX to most effectively use your storage. --- Once you’ve discovered just how your data looks on the network, you may also want to consider how your data looks on your file system and how to best virtualize your environment. Checkout our Data Manager tool for a completely different look at what you’re platters and solid state are doing throughout the day.216Views0likes0CommentsToll Booths and Dams. And Strategic Points of Control
An interesting thing about toll booths, they provide a point at which all sorts of things can happen. When you are stopped to pay a toll, it smooths the flow of traffic by letting a finite number of vehicles through per minute, reducing congestion by naturally spacing things out. Dams are much the same, holding water back on a river and letting it flow through at a rate determined by the operators of the dam. The really interesting bit is the other things that these two points introduce. When necessary, toll booths have been used to find and stop suspected criminals. They have also been used as advertising and information transmission points. None of the above are things toll booths were created for. They were created to collect tolls. And yet by nature of where they sit in the highway system, can be utilized for much more. The same is true of a dam. Dams today almost always generate electricity. Often they function as bridges over the very water they’re controlling. They control the migration of fish, and operate as a check on predatory invasive species. Again, none of these things is the primary reason dams were originally invented, but the nature of their location allows them to be utilized effectively in all of these roles. Toll booths - Wikipedia We’ve talked a bit about strategic points of control. They’re much like toll booths and dams in the sense that their location makes them key to controlling a whole lot of traffic on your LAN. In the case of F5’s defined strategic points of control, they all tie in to the history of F5’s product lineup much like a toll booth was originally to collect tolls. F5BIG-IPLTM sits at the network strategic point of control. Initially LTM was a load balancer, but by virtue of its location and the needs of customers has grown into one of the most comprehensive Application Delivery Controllers on the market – everything from security to uptime monitoring is facilitated by LTM. F5 ARX is much the same, being the file-based storage strategic point of control allows such things as directing some requests to cloud storage and others to storage by vendor A, while still others go to vendor B, and the remainder go to a Linux or Windows machine with a ton of free disk space on it. The WAN strategic point of control is where you can improve performance over the WAN via WOM, but it is also a place where you can extend LTM functionality to remote locations, including the cloud. Budgets for most organizations are not growing due to the state of the economy. Whether you’re government, public, private, or small business, you’ve been doing more with less for so long that doing more with the same would be a nice change. If you’re lucky, you’ll see growth in IT budgeting due to increasing needs of security and growth of application footprints. Some others will see essentially flat budgets, and many – including most government IT orgs - will see shrinking budgets. While that is generally bad news, it does give you the opportunity to look around and figure out how to make more effective use of existing technology. Yes, I have said that before, because you’re living that reality, so it is worth repeating. Since I work for F5, here are a few examples though, something I’ve not done before. From the network strategic point of control, we can help you with DNSSec, AAA, Application Security, Encryption, performance on several levels (from TCP optimizations to compression), HA, and even WAN optimization issues if needed. From the storage strategic point of control we can help you harness cloud storage, implement tiering, and balance load across existing infrastructure to help stave off expensive new storage purchases. Backups and replication can be massively improved (both in terms of time and data transferred) from this location also. We’re not the only vendor that can help you out without having to build a whole new infrastructure. It might be worthwhile to have a vendor day, where you invite vendors in to give presentations about how they can help – larger companies and the federal government do this regularly, you can do the same in a scaled down manner, and what sales person is going to tell you “no, we don’t want to come tell you how you can help and we can sell you more stuff”? Really? Another option is, as I’ve said in the past, make sure you know not just the functionality you are using, but the capabilities of the IT gear, software, and services that you already have in-house. Chances are there are cost savings by using existing functionality of an existing product, with time being your only expense. That’s not free, but it’s about as close as IT gets. Hoover Dam from the air - Wikipedia So far we in IT have been lucky, the global recession hasn’t hit our industry as hard as it has hit most, but it has constricted our ability to spend big, so little things like those above can make a huge difference. Since I am on a computer or Playbook for the better part of 16 hours a day, hitting websites maintained by people like you, I can happily say that you all rock. A highly complex, difficult to manage set of variables rarely produces a stable ecosystem like we have. No matter how good the technology, in the end it is people who did that, and keep it that way. You all rock. And you never know, but you might just find the AllSpark hidden in the basement ;-).253Views0likes0CommentsFile Virtualization Performance: Understanding CIFS Create ANDX
Once upon a time, files resided on a local disk and file access performance was measured by how fast the disk head accessed the platters, but today those platters may be miles away; creating, accessing and deleting files takes on a new challenge and products like the F5 ARX become the Frodo Baggins of the modern age. File Virtualization devices are burdened with a hefty task (this is where my Lord of the Ring Analogy really beings to play out) of becoming largely responsible for how close your important files are to your finger tips. How fast do you want it to perform? Quite expectedly, “as fast as possible,” will be the typical response. File Virtualization requires you to meet the expectations of an entire office—many of which are working miles away from the data they access and every single user hates to see a waiting cursor. To judge the performance of a storage environment we often ask the question, “How many files do you create and how many files do you open?” Fortunately, Microsoft CIFS allows humans to interact with their files over a network and it does so with many unique Remote Procedure Calls (RPCs). One such procedure call, Create ANDX, was initially intended to create new files on a file system but became the de-facto standard for opening files as well. While you and I can clearly see an obvious distinction between opening a file and creating a file, CIFS liberal use of Create ANDX, gives us pause, as this one tiny procedure has been overloaded to perform both tasks. Why is this a problem? Creating a file and opening a file requires a completely separate amount of work with entirely different results, one of the great challenges of File Virtualization. Imagine if you were given the option between writing a book like The Fellowship of The Ring or simply opening the one already created. Which is easier? Creating a file may require metadata about the file (security information, other identifiers, etc.) and allocating sufficient space on disk takes a little time. Opening a file is a much faster operation compared to “create” and, often, will be followed by one or more read operations. Many storage solutions, EMC and Network Appliance come to mind, have statistics to track just how many CIFS RPC’s have been requested by clients in the office. These statistics are highly valuable when analyzing the performance of a storage environment for File Virtualization with the F5 ARX. Gathering the RPC statistics over a fixed interval of time allow easier understanding of the environment but one key statistic, Create ANDX, leaves room for improvement… this is the “all seeing eye” of RPC’s because of its evil intentions. Are we creating 300 files per second or simply opening them? Perhaps it’s a mix of both and we’ve got to better understand what’s going on in the storage network. When we analyze a storage environment we put additional focus on the Create ANDX RPC and utilize a few other RPC’s to try to guess what the client’s intentions so we can size the environment for the correct hardware. In a network with 300 Create ANDX procedures a second, we would then look into how many read RPC’s we can find compared to the write RPC’s and attempt to judge what the client is intending to perform as an action. For example, a storage system with 300 “creates” that then performs 1200 reads and five writes is probably spending much of its time opening files, not creating them. Logic dictates that a client would open a file to read from it and not create a 0-byte file and read emptiness, which just doesn’t make much sense. Tracking fifteen minute intervals of statistics on your storage device, over a 24-hour period, will give you a bit of understanding as to what RPC’s are heavily used in the environment (a 48-hour sample will yield even more detailed results.) Taking a bit of time to read into the intentions of Create ANDX and try to understand how your clients are using the storage environment, are they opening files or are they creating files? Just as creating files on storage systems is a more intensive process compared to the simple open action, the same can be said for the F5 ARX. The ARX will also track metadata for newly created files for its virtualization layer and the beefier the ARX hardware, the more file creations can be done in a short interval of time. Remember, while it’s interesting and often times impressive to know just how many files are virtualized behind an F5 ARX or sitting on your storage environment, it’s much more interesting when you know how many are actually actively accessed. With a handful of applications, multiple protocols, dozens of RPC’s, hundreds of clients and several petabytes of information, do you know how your files are accessed?235Views0likes0CommentsSometimes, If IT Isn’t Broken, It Still Needs Fixing.
In our first house, we had a set of stairs that were horrible. They were unfinished, narrow, and steep. Lori went down them once with a vacuum cleaner, they were just not what we wanted in the house. They came out into the kitchen, so you were looking at these half-finished steps while sitting at the kitchen table. We covered them so they at least weren’t showing bare treads, and then we… Got used to them. Yes, that is what I said. We adapted. They were covered, making them minimally acceptable, they served their purpose, so we enjoyed them. Then we had the house remodeled. Nearly all of it. And the first thing the general contractor did was rip out those stairs and put in a sweeping staircase that turned and came into the living room. The difference was astonishing. We had agreed to him moving the stairs, but hadn’t put much more thought into it beyond his argument that it would save space upstairs and down, and they would no longer come out in the kitchen. This acceptance of something “good enough” is what happens in business units when you deliver an application that doesn’t perfectly suit their needs. They push for changes, and then settle into a restless truce. “That’s the way it is” becomes the watch-word. But do not get confused, they are not happy with it. There is a difference between acceptance and enjoyment. Stairs in question, before on left, after on right. Another issue that we discovered while making changes to that house was “the incredible shrinking door”. The enclosed porch on the back of the house was sitting on rail road ties from about a century ago, and they were starting into accelerated degradation. The part of the porch not attached to the house was shrinking yearly. Twice I sawed off the bottom of the door to the porch so that it would open and close. It really didn’t bother us overly much, because it happened over the course of years, and we adapted to the changes as they occurred. When we finally had that porch ripped off to put an actual addition on the house, we realized how painful dealing with the porch and its outer door had been. This too is what happens in business units when over time the usability of a given application slowly degrades or the system slowly becomes out of date. Users adapt, making it do what they want because, like our door, the changes occur day-to-day, not in one big catastrophic heap. So it is worth your time to occasionally look over your application portfolio and consider the new technologies you’ve brought in since each application was implemented. Decide if there are ways you can improve the experience without a ton of overhead. Your users may not even realize you’re causing them pain anymore, which means you may be able to offer them help they don’t know they’re looking for. Consider, would a given application perform better if placed behind an ADC, would putting a Web Application Firewall in front of an application make it more secure simply because the vendor is updating the Web App Firewall to adapt to new threats and your developers only update the application on occasion? Would shortening the backup window with storage tiering such as F5’s ARX offers improve application performance by reducing network traffic during backups and/or replication? Would changes in development libraries benefit existing applications? Granted, that one can be a bit more involved and has more potential for going wrong, but it is possible that the benefits are worth the investment/risk – that’s what the evaluation is for. Would turning on WAN Optimization between datacenters increase available bandwidth and thus improve application performance of all applications utilizing that connection? Would offloading encryption to an ADC decrease CPU utilization and thus improve performance of a wide swath of applications in the DC – particularly VM-based applications that are already sharing a CPU and could gain substantially from offloading encryption? These are the things that in the day-to-day crush of serving the business units and making certain the organizations’ systems are on-line we don’t generally think of, but some of them are simple to implement and offer a huge return – both in terms of application stability/performance and in terms of inter-department relations. Business units love to hear “we made that better” when they didn’t badger you to do so, and if the time investment is small they won’t ask why you weren’t doing what they did badger you to do. Always a fresh look. Your DC is not green field, but it is also not curing cement. Consider all the ways that something benefitting application X can benefit other applications, and what the costs of doing so will be. It is a powerful way to stay dynamic without rip-and-replace upgrades. If you’re an IT Architect, this is just part of your job, if you’re not, it’s simply good practice. Related Blogs: If I Were in IT Management Today… IT Management is Not Called Change Management for a Reason Challenges of SOA Management Nothing New Cloud Changes Everything IPv6 Does Not Mean The End of IPv4 It Is Not What The Market Is Doing, But What You Are.211Views0likes0CommentsIt Is Not What The Market Is Doing, But What You Are.
We spend an obsessive amount of time looking at the market and trying to lean toward accepted technologies. Seriously, when I was in IT management, there were an inordinate number of discussions about the state of market X or Y. While these conversations almost always revolved around what we were doing, and thus were put into context, sometimes an enterprise sits around waiting for everyone else to jump on board before joining in the flood. While sometimes this is commendable behavior, it is just as often self-defeating. If you have a project that could use technology X, then find the best implementation of said technology for your needs, and implement it. Using an alternative or inferior technology just because market adoption hasn’t happened will bite you as often as it will save you. Take PDAs, back in the bad old days when cell phones were either non-existent of just plain phones. Those organizations that used them reaped benefits from them, those that did not… Did not. While you could talk forever about the herky-jerky relationship of IT with small personal devices like PDAs, the fact is that they helped management stay better organized and kept salespeople with a device they could manage while on the road going from appointment to appointment. For those who didn’t wait to see what happened or didn’t raise a bunch of barriers and arguments that, retrospectively, appear almost ridiculous. Yeah, data might leak out on them. Of course, that was before USB sticks and in more than one case entire hard disks of information walked away, proving that a PDA wasn’t as unique in that respect as people wanted to claim. There is a whole selection of technologies that seem to have fallen into that same funky bubble – perhaps because, like PDAs, the value proposition was just not quite right. When cell phones became your PDA also, nearly all restrictions on them were lifted in every industry, simply because the cell phone + PDA was a more complete solution. One tool to rule them all and all that. Palm Pilot, image courtesy of wikipedia Like PDAs, there is benefit to be had from going “no, we need this, let’s do it”. Storage tiering was stuck in the valley of wait-and-see for many years, and finally seems to be climbing out of that valley simply because of the ongoing cost of storage combined with the parallel growth of storage. Still, there are many looking to save money on storage that aren’t making the move – almost like there’s some kind of natural resistance. It is rare to hear of an organization that introduced storage tiering and then dumped it to go back to independent NAS boxes/racks/whatever, so the inhibition seems to be strictly one of inexperience. Likewise, cloud suffers from some reluctance that I personally attribute to not only valid security concerns, but to very poor handling of those concerns by industry. If you read me regularly, you know I was appalled when people started making wild claims like “the cloud is more secure than your DC”, because that lack of touch with reality made people more standoffish, not less. But some of it is people not seeing a need in their organization, which is certainly valid if they’ve checked it out and come to that conclusion. Quite a bit of it, I think, is the same resistance that was applied to SaaS early on – if it’s not in your physical network, is it in your control? And that’s a valid fear that often shuts down the discussion before it starts – particularly if you don’t have an application that requires the cloud – lots of spikes in traffic, for example. Application Firewalls are an easier one in my book – having been a developer, I know that they’re going to be suspicious of canned security protecting their custom app. While I would contend that it isn’t “canned security” in the case of an Application Firewall, I can certainly understand their concern, and it is a communications issue on the part of the Application Firewall vendor community that will have to be resolved if uptake is to spike. Regulatory issues are helping, but far better an organization purchase a product because they believe it helps than because someone forced them to purchase. With HP’s exit from the tablet market, this is another field that is in danger of falling into the valley of waiting. While it’s conjecture, I’ll contend that not every organization will be willing to go with iPads as a corporate roll-out for groups that can benefit from tablet PCs – like field sales staff – and RIM is in such a funk organizations are unlikely to rush their money to them. The only major contender that seems to remain is Samsung with the Galaxy Tab (android-based), but I bought one for Lori for her last birthday, and as-delivered it is really a mini gaming platform, not a productivity tool. Since that is configurable within the bounds set in the Android environment, it might not be such a big deal, but someone will have to custom-install them for corporate use. But the point is this. If you’re spending too much on storage and don’t have tiering implemented, contact a vendor that suits your needs and look into it. I of course recommend F5ARX, but since I’m an F5 employee, expecting anything else would be silly. Along the same lines, find a project and send it to the cloud. Doesn’t matter how big or small it is, the point is to build your expertise so you know when the cloud will be most useful to you. And cloud storage doesn’t count, for whatever reason it is seeing a just peachy uptake (see last Thursday’s blog), and uses a different skill set than cloud for application deployment. Application Firewalls can protect your applications in a variety of ways, and those smart organizations that have deployed them have done so as an additive protection to application development security efforts. If for some odd reason you’re against layered protection, then think about this… They can stop most attacks before they ever get to your servers, meaning even fingerprinting becomes a more difficult chore. Of course I think F5 products rule the roost in this market – see my note above about ARX. As to tablet PCs, well, right now you have a few choices, if you can get a benefit from them now, determine what will work for you for the next couple of years and run with it. You can always do a total refresh after the market has matured those couple of years. Right now I see Apple, RIM, and Samsung as your best choices, with RIM being kind of shaky. Lori and I own Playbooks and love them, but RIM has managed to make a debacle of itself right when they hit the market, and doesn’t seem to be climbing out with any speed. Or you could snatch up a whole bunch of those really inexpensive Web-OS pads and save a lot of money until your next refresh :-). But if you need it, don’t wait for the market. The market is like FaceBook… Eventually consistent, but not guaranteed consistent at any given moment. Think more about what’s best for your organization and less about what everyone else is doing, you’ll be happier that way. And yes, there’s slightly more risk, but risk is not the only element in calculating best for the organization, it is one small input that can be largely mitigated by dealing with companies likely to be around for the next few years.210Views0likes0CommentsNow it’s Time for Efficiency Gains in the Network.
One of the things that F5 has been trying to do since before I came to the company is reach out to developers. Some of the devices in your network could be effective AppDev tools if utilized to their full extent, and indeed, I’ve helped companies develop tools utilizing iControl that give application managers control over their entire environment – from VMs to ADCs. While it is a struggle for any network device company to communicate with developers, I think it is cool that F5 continues to do so. But increasingly, the Network is the place you need to go when attempting to address performance issues and facilitate development efforts. Even if you are not pursuing rapid development methodologies, the timeline for delivering applications is still shrinking. Indeed, the joy of virtualization has sped up the provisioning process by a huge amount, and that increases pressure on AppDev even more. Image courtesy of IBMdeveloperWorks The thing is, IT’s responsiveness is about a lot more than just Application Development. Since virtualization allows us to stand up new servers in what just a few years ago would be considered an insanely short timeframe, the flexibility of the network is also at issue. It’s great that you can get a new VM running in minutes, but storage allocation, network allocation, load balancing policies, security, and a handful of other less obvious issues are still slowing down the process. What we need is a solution that allows developers to leave things to the network. Some things – particularly in a load-balanced environment – the network knows far better than the application. The same is true for security. While security has made some inroads into the “this should be done at the network level”, there’s still a ways to go. The ability to spin up a VM, add it to a load balancing pool, allocate storage, and insure that the correct security policies are applied – be the application internal or external – is the next step in reducing business wait times by improving IT responsiveness. Just like a super-class has the base attributes a developer needs, and and the subclass implements specific functionality, we need the same capability for security, load balancing, and a host of other network-layer items. F5 implements these items through profiles, templates, and increasingly iApp instances. While I think it’s stellar that we have taken steps to increase the viability of network adaptability, this is something that the industry as a whole needs to take on. The life of IT staff would be much simpler if you could package an application with information about what network services it needs, and have it automatically add the VM to a pool or create a new pool if the correct one doesn’t exist, storage could be allocated and mount points set in the OS so as to be unique when needed, the correct security policy is applied, all of the services the application requires are just set up. At the direction of the application when it is spun up, not the administrator. We’re not quite there yet, but we’re headed that way. Automation of network services will be one of the next steps we take to what could accurately be called utility computing, if that term hadn’t already been used and abused. Which is another – albeit less likely - “wouldn’t it be nice” scenario. Wouldn’t it be nice if the buzzword generation capability was somehow tied to actual functionality? Yeah, I know, I’ll be happy with the very cool IT changes and not worry so much about the market-speak. Related Blogs: Don't Let Automation Water Down Your Data Center Virtualization, Cloud, Automation. But Where Are We Going? WILS: Automation versus Orchestration Repetition is the Key to Network Automation Success Extreme Automation. Dynamic Control with or without the Cloud. F5 Friday: Would You Like Some Transaction Integrity with Your ...169Views0likes0CommentsWhat Is Your Reason for Virtualization and Cloud, Anyway?
Gear shifting in a modern car is a highly virtualized application nowadays. Whether you’re driving a stick or an automatic, it is certainly not the same as your great grandaddy’s shifting (assuming he owned a car). The huge difference between a stick and an automatic is how much work the operator has to perform to get the job done. In the case of an automatic, the driver sets the car up correctly (putting it into drive as opposed to one of the other gears), and then forgets about it other than depressing and releasing the gas and brake pedals. A small amount of up-front effort followed by blissful ignorance – until the transmission starts slipping anyway. In a stick, the driver has much more granular control of the shifting mechanism, but is required to pay attention to dials and the feel of the car, while operating both pedals and the shifting mechanism. Two different solutions with two different strengths and weaknesses. Manual transmissions are much more heavily influenced by the driver, both in terms of operating efficiency (gas mileage, responsiveness, etc) and longevity (a careful driver can keep the clutch from going bad for a very long time, a clutch-popping driver can destroy those pads in near-zero time). Automatic transmissions are less overhead day-to-day, but don’t offer the advantages of a stick. This is the same type of trade-off you have to ask about the goals of your next generation architecture. I’ve touched on this before, and no doubt others have too, but it is worth calling out as its own blog. Are you implementing virtualization and/or cloud technologies to make IT more responsive to the needs of the user, or are you implementing them to give users “put it in drive and don’t worry about it” control over their own application infrastructure? The difference is huge, and the two may have some synergies, but they’re certainly not perfectly complimentary. In the case of making IT more responsive, you want to give your operators a ton of dials and whistles to control the day-to-day operations of applications and make certain that load is distributed well and all applications are responsive in a manner keeping with business requirements. In the case of push-button business provisioning, you want to make the process bullet-proof and not require user interaction. It is a different world to say “It is easy for businesses to provision new applications.” (yes, I do know the questions that statement spawns, but there are people doing it anyway – more in a moment) than it is to say “Our monitoring and virtual environment give us the ability to guarantee uptime and shift load to the servers/locales/geographies that make sense.” While you can do the second as a part of the first, they do not require each other, and unless you know where you’re going, you won’t ever get there. Some of you have been laughing since I first mentioned giving business the ability to provision their own applications. Don’t. There are some very valid cases where this is actually the answer that makes the most sense. Anyone reading this that works at a University knows that this is the emerging standard model for the student virtualization efforts. Let students provision a gazillion servers, because they know what they need, and University IT could never service all of the requests. Then between semesters, wipe the virtual arrays clean and start over. The early results show that for the university model, this is a near-perfect solution. For everyone not at a university, there are groups within your organization capable of putting up applications - a content management server for example - without IT involvement… Except that IT controls the hardware. If you gave them single-button ability to provision a standard image, they may well be willing to throw up their own application. There are still a ton of issues, security and DB access come to mind, but I’m pointing out that there are groups with the desire who believe they have the ability, if IT gets out of their way. Are you aiming to serve them? If so, what do you do for less savvy groups within the organization or those with complex application requirements that don’t know how much disk space or how many instances they’ll need? For increasing IT agility, we’re ready to start that move today. Indeed, virtualization was the start of increasing IT’s responsiveness to business needs, and we’re getting more and more technology on-board to cover the missing pieces of agile infrastructure. By making your infrastructure as adaptable as your VM environment, you can leverage the strategic points of control built into your network to handle ADC functionality, security, storage virtualization, and WAN Optimization to make sure that traffic keeps flowing and your network doesn’t become the bottleneck. You can also leverage the advanced reporting that comes from sitting in one of those strategic points of control to foresee problem areas or catch them as they occur, rather than waiting for user complaints. Most of us are going for IT agility in the short term, but it is worth considering if, for some users, one-click provisioning wouldn’t reduce IT overhead and let you focus on new strategic projects. Giving user groups access to application templates and raw VM images configured for some common applications they might need is not a 100% terrible idea if they can use them with less involvement from IT than is currently the case. Meanwhile, watch this space, F5 is one of the vendors driving the next generation of network automation, and I’ll mention it when cool things are going on here. Or if I see something cool someone else is doing, I occasionally plug it here, like I did for Cirtas when they first came out, or Oracle Goldengate. Make a plan. Execute on it. Stand ready to serve the business in the way that makes the most sense with the least time investment from your already busy staff. And listen to a lot of loud music, it lightens the stress level. I was listening to ZZ Top and Buckcherry writing this. Maybe that says something, I don’t quite know.242Views0likes0Comments