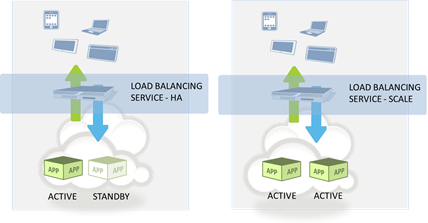
Load Balancing 101: Scale versus Fail
#cloud Elasticity is a design pattern for scalability, not necessarily failability. One of the phrases you hear associated with cloud computing is "architecting for failure." Rather than build in a lot of hardware-level redundancy – power, disk, network, etc… – the idea is that you expect it to fail and can simply replace the application (which is what you care about anyway, right?) with a clone running on the same cheap hardware somewhere else in the data center. Awesome idea, right? But when it comes down to it, cloud computing environments are architected for scale, not fail. SCALE versus FAIL Most enterprise-class data centers have been architected with failure in mind; we call these high-availability (HA) architectures. The goal is to ensure that if any element in the data path fails that another can almost immediately take its place. Within a hardware platform, this implies dual power supplies, a high RAID level, and lights-out management. At the network and higher level, this requires redundant network elements – from load balancers to switches to routers to firewalls to servers, all elements must be duplicated to ensure a (near) immediate failover in the event of a failure. This generally requires configurations and support for floating (shared) IP addresses across redundant elements, allowing for immediate redirection upon detection of a failure upstream. At the application/server tier, the shared address concept is still applied but it is done so at the load balancing layer, where VIP (virtual IP addresses) act as a virtual instance of the application. A primary node (server) is designated that is active with a secondary being designated as the "backup" instance which remains idle in "standby" mode*. If the primary instance fails – whether due to hardware or software or network failure – the secondary immediately becomes active, and continuity of service is assured by virtue of the fact that existing sessions are managed by the load balancing service, not the server. In the event a network element fails, continuity (high-availability) is achieved due to the mirroring (replication) of those same sessions between the active (primary) and standby (secondary) elements. Is it perfect? No, but it does provide sub-second response to failure, which means very high levels of availability (or as I like to call it, failability). That's architected for "FAIL". Now, most cloud computing environments are architected not with failure in mind but with scale in mind – that is, they are designed to enable elasticity (scale out, scale in) that is, in part, based on the ability to rapidly provision the resources required. A load balancing instance is required and it works in much the same way as a high-availability architecture (minus the redundancy). The load balancing service acts as the virtual application, with at least one instance behind it. As demand increases, new instances are provisioned and added to the service to ensure that performance and availability are not adversely impacted. When this process is also capable of scaling back in by automatically eliminating instances when demand contracts it's called "elasticity". If the only instance available fails, this architecture is not going to provide high availability of the application because it takes time to launch an instance to replace it. Even if there are ten active instances and one fails, performance and/or availability for some clients may be impacted because, as noted already, it takes time to launch an instance to replace it. Similarly, if an upstream element fails, such as the load balancing service, availability may be adversely impacted – because it takes time to replace it. But when considering how well the system responds to changes in demand for resources, it works well. That's scalability. That's architected for "SCALE". SCALE and FAIL are NOT INTERCHANGEABLE These two are not interchangeable, they cannot be conflated with the expectation that either architecture is able to meet both goals equally well. They are designed to resolve two different problems. The two can be combined to achieve a scalable, high-availability architecture where redundancy is used to assure availability while elasticity is leveraged to realize scale while reducing the time to provision and investment costs by implementing a virtual, flexible resource model. It's important to understand the difference in these architectures especially when looking to public cloud as an option because they are primarily designed to enable scalability, not failability. If you absolutely need failability, you'll need to do some legwork of your own (scripts or manual intervention – perhaps both) to ensure a more seamless failover in the event of failure or specifically seek out cloud providers that recognize the inherent differences between the two architectures and support either the one you need, or both. Relying on an elastic architecture to provide high-availability – or vice-versa – is likely to end poorly. Downtime cost source: IT Downtime Costs $26.5 Billion In Lost Revenue The Colonial Data Center and Virtualization Back to Basics: Load balancing Virtualized Applications Cloud Bursting: Gateway Drug for Hybrid Cloud The HTTP 2.0 War has Just Begun Why Layer 7 Load Balancing Doesn’t Suck Network versus Application Layer Prioritization224Views0likes0CommentsThe Colonial Data Center and Virtualization
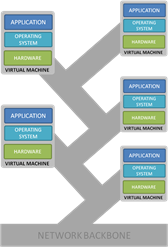
No, not colonial as in Battlestar Gallactica or the British Empire, colonial as in corals and weeds and virtual machines I was out pulling weeds this summer – Canada thistle to be exact – and was struck by how much its root system reminded me of Cnidaria (soft corals to those of you whose experience with aquaria remains relegated to suicidal goldfish). Canada thistle is difficult to control because of its extensive root system. Pulling a larger specimen you often find yourself pulling up its root, only to find it connected to three, four or more other specimens. Cnidaria reproduce in a similar fashion, sharing a “root” system that enables them to share resources. Unlike thistles, however, Cnidaria has several different growth forms. There’s a traditional colonial form that resembles thistles – a single, shared long root with various specimens popping up along the path – and one that may be familiar to folks who’ve seen Finding Nemo: a tree formation in which the root branches not only horizontally but vertically, with individual specimens forming upwards along the branch in what gives it a tree-like appearance. Cnidaria produce a variety of colonial forms, each of which is one organism but consists of polyp-like zooids. The simplest is a connecting tunnel that runs over the substrate (rock or seabed) and from which single zooids sprout. In some cases the tunnels form visible webs, and in others they are enclosed in a fleshy mat. More complex forms are also based on connecting tunnels but produce "tree-like" groups of zooids. The "trees" may be formed either by a central zooid that functions as a "trunk" with later zooids growing to the sides as "branches", or in a zig-zag shape as a succession of zooids, each of which grows to full size and then produces a single bud at an angle to itself. In many cases the connecting tunnels and the "stems" are covered in periderm, a protective layer of chitin. [6] Some colonial forms have other specialized types of zooid, for example, to pump water through their tunnels. [12] -- Wikipedia, Cnidaria Of course, both thistle and Cnidaria and the notion of colonial inter-dependence is one that’s shared by the data center. Virtual machines deployed on the same physical host replicate in many ways the advantages and disadvantages of a Cnidarian tree-formation. The close proximity of the 15.6 average VMs per host (according to Vkernel VMI 2012) allows them to share the “local” (virtual) network, which eliminates many of the physical sources of network latency that occur naturally in the data center. But it also means that a failure in the physical network connecting them to the network backbone is catastrophic for all VMs on a given host. Which is why you want to pay careful attention to placement of VMs in a dynamic data center. The concept of pulling compute resources from anywhere in the data center to support scalability on-demand is a tantalizing one, but doing so can have disastrous results in the event of a catastrophic failure in the network. Architecture and careful planning is necessary to ensure that resources do not end up grouped in such a way that a failure in one negatively impacts the entire application. Proximity must be considered as part of a fault isolation strategy, which is a requirement when resources are loosely – if at all – coupled to specific locations within the data center. Referenced blogs & articles: Wikipedia, Cnidaria Virtualization Management Index: Issues 1 and 2 Back to Basics: Load balancing Virtualized Applications Digital is Different The Cost of Ignoring ‘Non-Human’ Visitors Cloud Bursting: Gateway Drug for Hybrid Cloud The HTTP 2.0 War has Just Begun Why Layer 7 Load Balancing Doesn’t Suck Network versus Application Layer Prioritization Complexity Drives Consolidation Performance in the Cloud: Business Jitter is Bad209Views0likes0CommentsCloud Security: It’s All About (Extreme Elastic) Control
#iam #infosec #cloud #mobile Whether controlling access by users or flows of data, control is common theme to securing “the cloud” The proliferation of mobile devices along with the adoption of hybrid cloud architectures that integrate black-box services from external providers is bringing back to the fore issues of control. Control over access to resources, control over flow of data into and out of resources, and the ability to exert that control consistently whether the infrastructure is “owned” or “rented”. What mobile and BYOD illustrates is the extreme nature of computing today; of the challenges of managing the elasticity inherent in cloud computing . It is from the elasticity that the server side poses its greatest challenges – with mobile IP addresses and locations that can prevent security policies from being efficiently codified, let alone applied consistently. With end-points (clients) we see similar impacts; the elasticity of users lies in their device mobility, in the reality that users move from smart phone to laptop to tablet with equal ease, expecting the same level of access to corporate applications – both on and off-premise. This is extreme elasticity – disrupting both client and server variables. Given the focus on mobile today it should be no surprise to see the declaration that “cloud security” is all about securing “mobile devices.” "If you want to secure the cloud, you need to secure your mobile devices," he explained. "They are the access points to the cloud -- and from an end-user perspective, the difference between the cloud and the mobile phone is lost." -- BYOD: if you can't beat 'em, secure 'em If this were to be taken literally, it would be impossible. Without standardization – which runs contrary to a BYOD policy – it is simply not feasible for IT to secure each and every mobile device, let alone all the possible combinations of operating systems and versions of operating systems. To do so is futile, and IT already knows this, having experienced the pain of trying to support just varying versions of one operating system on corporate-owned desktops and laptops. It knows the futility in attempting to do the same with mobile devices, and yet they are told that this is what they must do, if they are to secure the cloud. Which brings us to solutions posited by experts and pundits alike: IAM (Identity and Access Management) automation and integration. IAM + “Single Control Point” = Strategic Point of (Federated Access) Control IAM is not a new solution, nor is the federation of such services to provide a single control point through which access can be managed. In fact, combining the two beliefs – that control over access to cloud applications with the importance of a “single control point” – is exactly what is necessary to address the “great challenge” for the security industry described by Wendy Nather of the 451 Group. It is the elasticity that exists on both sides of the equation – the client and the server – that poses the greatest challenge for IT security (and operations in general, if truth be told). Such challenges can be effectively met through the implementation of a flexible intermediation tier, residing in the data center and taking advantage of infrastructure and application integration techniques through APIs and process orchestration. Intermediation via the application delivery tier, residing in the data center to ensure the control demanded and required (as a strategic point of control), when combined with context-awareness offer the means by which organizations can meet head on the security challenge of internal and external elasticity.211Views0likes0CommentsHybrid Architectures Do Not Require Private Cloud
Oh, it certainly helps, but it’s not a requirement Taking advantage of cloud-hosted resources does not require forklift re-architecture of the data center. That may sound nearly heretical but that’s the truth, and I’m not talking about just SaaS which, of course, has never required anything more than an Internet connection to “integrate” into the data center. I’m talking about IaaS and integrating compute and storage resources into the data center, whether it’s cloud-based or traditional or simply highly virtualized. Extending the traditional data center using hybrid model means being able to incorporate (integrate) cloud-hosted resources as part of the data center. For most organizations this means elasticity – expanding and contracting capacity by adding and removing remote resources to a data center deployed application. Flexibility and cost savings drive this model, and the right model can realize the benefits of cloud without requiring wholesale re-architecture of the data center. That’s something that ought to please the 50% of organizations that, according to a 2011 CIO survey, are interested in cloud specifically to increase capacity and availability. Bonus: it also serves to address other top drivers identified in the same survey of reducing IT management and maintenance as well as IT infrastructure investment. Really Big Bonus? Most organizations probably have the means by which they can achieve this today. LEVERAGING CLOUD RESOURCES FROM A TRADITIONAL DATA CENTER Scalability requires two things: resources and a means to distribute load across them. In the world of application delivery we call the resources “pools” and the means to distribute them an application delivery controller (load balancing service, if you prefer). The application delivery tier, where the load balancing service resides topologically in the data center, is responsible for not only distributing load across resources but for being able to mitigate failure without disrupting the application service. That goes for elasticity, too. It should be possible to add and remove (intentionally through provisioning processes or unintentionally through failure) resources from a given pool without disruption the overall application service. This is the primary business and operational value brought to an organization by load balancing services: non-disruptive (or seamless or transparent if you prefer more positive marketing terminology) elasticity. Yes, the foundations of cloud have always existed and they’re in most organizations’ data centers today. Now, it isn’t that hard to imagine how this elasticity can extend to integrate cloud-hosted resources. Such resources are either non-disruptively added to/removed from the load balancing service’s “pool” of resources. The application delivery controller does not care whether the resources in the pool are local or remote, traditional or cloud, physical or virtual. Resources are resources. So whether the data center is still very traditional (physical-based), has moved into a highly virtualized state, or has gone all the way to cloud is really not relevant to the application delivery service. All resources can be operationally managed consistently by the application delivery controller. To integrate cloud-based resources into the architecture requires only one thing: connectivity. The connectivity between a data center and the “cloud” is generally referred to as a cloud bridge (or some variation thereof). This cloud bridge has the responsibility of connecting the two worlds securely and providing a network compatibility layer that “bridges” the two networks, implying a transparency that allows resources in either environment to communicate without concern for the underlying network topology. How this is accomplished varies from solution to solution, and there are emerging “virtual network encapsulation” technologies (think VXLAN and GRE) that are designed to make this process even smoother. Once a connection is established, and assuming network bridging capabilities, resources provisioned in “the cloud” can be non-disruptively added to the data center-hosted “pools” and from there, load is distributed as per the load balancing service’s configuration for the resource (application, etc… ). THE ROAD to CLOUD There seems to be a perception in the market that you aren’t going to get to hybrid cloud until you have private cloud, which may explain the preponderance of survey respondents who are focused on private cloud with must less focus on public cloud. The road to “cloud” doesn’t require that you completely revamp the data center to be cloud-based before you can begin taking advantage of public cloud resources. In fact, a hybrid approach that integrates public cloud into your existing data center provides an opportunity to move steadily in the direction of cloud without being overwhelmed by the transformation that must ultimately occur. A hybrid traditional-cloud based approach allows the organization to build the skill sets necessary, define the appropriate roles that will be needed, and understand the fundamental differences in operational models required to implement the automation and orchestration that ultimately brings to the table all the benefits of cloud (as opposed to just the cheaper resources). Cloud is a transformational journey – for both IT and the business – but it’s not one that can be taken overnight. The pressure to “go cloud” is immense, today, but IT still needs the opportunity to evaluate both the data center and cloud environments for appropriateness and to put into place the proper policies and governance structure around the use of cloud resources. A strategy that allows IT to begin taking advantage of cloud resources now without wholesale rip-and-replace of existing technology provides the breathing room IT needs to ensure that the journey to cloud will be a smooth one, where the benefits will be realized without compromising on the operational governance required to assure availability and security of network, data, and application resources. Related blogs & articles: F5 Friday: Addressing the Unintended Consequences of Cloud Getting at the Heart of Security in the Cloud Cloud Bursting: Gateway Drug for Hybrid Cloud Identity Gone Wild! Cloud Edition At the Intersection of Cloud and Control… The Conspecific Hybrid Cloud231Views0likes0CommentsF5 Friday: Enhancing FlexPod with F5
#VDI #cloud #virtualization Black-box style infrastructure is good, but often fails to include application delivery components. F5 resolves that issue for NetApp FlexPod The best thing about the application delivery tier (load balancing, acceleration, remote access) is that is spans both networking and application demesnes. The worst thing about the application delivery tier (load balancing, acceleration, remote access) is that is spans both networking and application demesnes. The reality of application delivery is that it stands with one foot firmly in the upper layers of the stack and the other firmly in the lower layers of the stack, which means it’s often left out of infrastructure architectures merely because folks don’t know which box it should go in. Thus, when “black-box” style infrastructure architecture solutions like NetApp’s FlexPod arrive, they often fail to include any component that doesn’t firmly fit in one of three neat little boxes: storage, network, server (compute). FlexPod isn’t the only such offering, and I suspect we’ll continue to see more “architecture in a rack” solutions in the future as partnerships are solidified and solution providers continue to expand their understanding of what’s required to support a dynamic data center. FlexPod is a great example of both an “architecture in a rack” supporting the notion of a dynamic data center and of the reality that application delivery components are rarely included. “FlexPod™, jointly developed by NetApp and Cisco, is a flexible infrastructure platform composed of pre-sized storage, networking, and server components. It’s designed to ease your IT transformation from virtualization to cloud computing with maximum efficiency and minimal risk.” -- NetApp FlexPod Data Sheet NetApp has done a great job of focusing on the core infrastructure but it has also gone the distance and tested FlexPod to ensure compatibility with application deployments across a variety of hypervisors, operating systems and applications, including: VMware® View and vSphere™ Citrix XenDesktop Red Hat Enterprise Linux® (RHEL) Oracle® SAP® Microsoft® Exchange, SQL Server® and SharePoint® Microsoft Private Cloud built on FlexPod What I love about this particular list is that it parallels so nicely the tested and fully validated solutions from F5 for delivering all these solutions. Citrix XenDesktop VMWare View and vSphere Oracle SAP Microsoft® Exchange, SQL Server® and SharePoint® That means that providing a variety of application delivery services for these applications - secure remote access, load balancing, acceleration and optimization – should be a breeze for organizations to implement. It should also be a requirement, at least in terms of load balancing and optimization services. If FlexPod makes it easier to dynamically manage resources supporting these applications then adding an F5 application delivery tier to the mix will ensure those resources and the user experience are optimized. SERVERS should SERVE While FlexPod provides the necessary storage, compute, and layer 2 networking components, critical application deployments are enhanced by F5 BIG-IP solutions for several reasons: Increase Capacity Offloads CPU-intensive processes from virtual servers, freeing up resources and increasing VM density and application capacity Improved Performance Accelerates end-user experience using adaptive compression and connection pooling technologies Enables Transparent and Rapid Scalability Deployment of new virtual server instances hosted in FlexPod can be added to and removed from BIG-IP Local Traffic Manager (LTM) virtual pools to ensure seamless elasticity Enables Automated Disaster Recovery F5 BIG-IP Global Traffic Manager (GTM) provides DNS global server load balancing services to automate disaster recovery or dynamic redirection of user requests based on location. Accelerated Replication Traffic BIG-IP WAN Optimization Manager (WOM) can improve the performance of high latency or packet-loss prone WAN links. NetApp replication technology (SnapMirror) will see substantial benefit when customers add BIG-IP WOM to enhance WAN performance. Bonus: Operational Consistency Because BIG-IP is an application delivery platform, it allows the deployment of a variety of application delivery services on a single, unified platform with a consistent operational view of all application delivery services. That extends to other BIG-IP solutions, such as BIG-IP Access Policy Manager (APM) for providing unified authentication to network and application resources across remote, LAN, and wireless access. Operational consistency is one of the benefits a platform-based approach brings to the table and is increasingly essential to ensuring that the cost-saving benefits of cloud and virtualization are not lost when disparate operational and management systems are foisted upon IT. FlexPod only provides certified components for storage, compute and layer 2 networking. Most enterprise application deployments require application delivery services whether for load balancing or security or optimization and ones that do not still realize significant benefits when deploying such services. Marrying F5 application delivery services with a NetApp FlexPod solution will yield significant benefits in terms of resource utilization, cost reductions, and address critical components of operational risk without introducing additional burdens on already overwhelmed IT staff. Operational Risk Comprises More Than Just Security The Future of Cloud: Infrastructure as a Platform At the Intersection of Cloud and Control… The Pythagorean Theorem of Operational Risk The Epic Failure of Stand-Alone WAN Optimization Mature Security Organizations Align Security with Service Delivery F5 Friday: Doing VDI, Only Better204Views0likes0Comments