F5 in AWS Part 1 - AWS Networking Basics
Updated for Current Versions and Documentation Part 1 : AWS Networking Basics Part 2: Running BIG-IP in an EC2 Virtual Private Cloud Part 3: Advanced Topologies and More on Highly-Available Services Part 4: Orchestrating BIG-IP Application Services with Open-Source Tools Part 5: Cloud-init, Single-NIC, and Auto Scale Out of BIG-IP in v12 If you work in IT, and you haven’t been living under a rock, then you have likely heard of Amazon Web Services (AWS). There has been a substantial increase in the maturity and stability of the AWS Elastic Compute Cloud (EC2), but you are wondering – can I continue to leverage F5 services in AWS? In this series of blog posts, we will discuss the how and why of running F5 BIG-IP in EC2. In this specific article, we’ll start with the basics of the AWS EC2 and Virtual Private Cloud (VPC). Later in the series, we will discuss some of the considerations associated with running BIG-IP as compute instance in this environment, we’ll outline the best deployment models for your application in EC2, and how these deployment models can be automated using open-source tools. Note: AWS uses the terms "public" and "private" to refer to what F5 Networks has typically referred to as "external" and "internal" respectively. We will use this terms interchangeably. First, what is AWS? If you have read the story, you will know that the EC2 project began with an internal interest at Amazon to move away from messy, multi-tenant networks using VLANs for segregation. Instead, network engineers at Amazon wanted to build an entirely IP-based architecture. This vision morphed into the universe of application services available today. Of course, building multi-tenant, purely L3 networks at massive scale had implications for both security and redundancy (we’ll get to this later). Today, EC2 enables users to run applications and services on top of virtualized network, storage, and compute infrastructure, where hosts are deployed in the form of Amazon Machine Images (AMIs). These AMIs can either be private to the user or launched from the public AWS marketplace. Hosts can be added to elastic load balancing (ELB) groups and associated with publicly accessible IPs to implement a simple horizontal model for availability. AWS became truly relevant for the enterprise with the introduction of the Virtual Private Cloud service. VPCs enabled users to build virtual private networks at the IP layer. These private networks can be connected to on-premise configurations by way of a VPN Gateway, or connected to the internet via an Internet Gateway. When deploying hosts within a VPC, the user has a significant amount of control over how each host is attached to the network. For example, a host can be attached to multiple networks and given several public or private IPs on one or multiple interfaces. Further, users can control many of the security aspects they are used to configuring in an on-premise environment (albeit in a slightly different way), including network ACLs, routing, simple firewalling, DHCP options, etc. Lets talk about these and other important EC2 aspects and try to understand how they affect our application deployment strategy. L2 Restrictions As we mentioned above, one of the design goals of AWS was to remove layer 2 networking. This is a worthy accomplishment but we lose access to certain useful protocols, including ARP (and gratuitious ARP), broadcast and multi-cast groups, 802.1Q tagging. We can no longer use VLANs for some availability models, for quality of service management, or for tenant isolation. Network Interfaces For larger topologies, one of the largest impacts given the removal of 802.1Q protocol support is the number of subnets we can attach to a node in the network. Because in AWS each interface is attached as a layer 3 endpoint, we must add an interface for each subnet. This contrasts with traditional networks, where you can add VLANs to your trunk for each subnet via tagging. Even though we're in a virtual world, the number of virtual network interfaces (or Elastic Network Interfaces (ENIs) in AWS terminology) is also limited according to the EC2 instance size. Together, the limits on number of interfaces and mapping between interface and subnet effectively limit the number of directly connected networks we can attach to a device (like BIG-IP, for example). IP Addressing AWS offers two kinds of globally routable IP address; these are “Public IP Addresses” and “Elastic IP Address”. In the table below, we outlined some of the differences between these two types of IP addresses. You can probably figure out for yourself why we will want to use Elastic IPs with BIG-IP. Like interfaces, AWS limits the number of IPs in several ways, including the number of IPs that can be attached to an interface and the number of elastic IPs per AWS account. Table 1: Differences between Public and Elastic IP Addresses Public IP Elastic IP Released on device termination/disassociation YES NO Assignable to secondary interfaces NO YES Can be associated after launch NO YES Amazon provides more information on public and elastic IP addresses here: http://docs.aws.amazon.com/AWSEC2/latest/UserGuide/using-instance-addressing.html#concepts-public-addresses Each interface on an EC2 instance is given a private IP address. This IP address is routable locally through your subnet and assigned from the address range associated with the subnet to which your interface is attached. Multiple private secondary IP addresses can be attached to an interface, and is a useful technique for creating more complex topologies. The number of interfaces and private IPs per interface within an Amazon VPC are listed here: http://docs.aws.amazon.com/AWSEC2/latest/UserGuide/using-eni.html#AvailableIpPerENI NAT Instances, Subnets and Routing When creating a VPC using the wizard available in the AWS VPC web portal, several default configurations are possible. One of these configurations is “VPC with Public and Private subnets”. In this configuration, what if the instances on our private subnet wish to access the outside world? Because we cannot attach public or elastic IP address to instances within the private subnet, we must use NAT provided by AWS. Like BIG-IP and other network devices in EC2, the NAT instance will live as a compute node within your VPC. This is good way to allow outbound traffic from your internal servers, but to prevent those servers from receiving inbound traffic. When you create subnets manually or through the VPC wizard, you’ll note that each subnet has an associated routing table. These route tables may be updated to control traffic flow between instances and subnets in your VPC. Regions and Availability Zones We know quite a few number of people who have been confused by the concept of availabilty zones in EC2. To put it clearly, an availabilty zone is a physically isolated datacenter in a region. Regions may contain mulitple availability zones. Availabilty zones run on different networking and storage infrastructure, and depend on seperate power supplies and internet connections. Striping your application deployments across availability zones is a great way to provide redundancy and, perhaps a hot standby, but please note that these are not the same thing. Amazon does not mirror any data between zones on behalf of the customer. While VPCs can span availability zones, subnets may not. To close this blog post, we are fortunate enough to get a video walk through from Vladimir Bojkovic, Solution Architect at F5 Networks. He shows how to create a VPC with internal and external subnets as a practical demonstration of the concepts we discussed above.4KViews2likes4Comments
Back to Basics: Health Monitors and Load Balancing
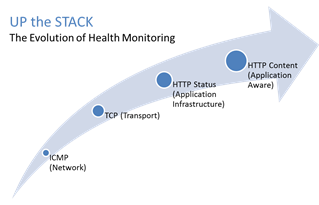
#webperf #ado Because every connection counts One of the truisms of architecting highly available systems is that you never, ever want to load balance a request to a system that is down. Therefore, some sort of health (status) monitoring is required. For applications, that means not just pinging the network interface or opening a TCP connection, it means querying the application and verifying that the response is valid. This, obviously, requires the application to respond. And respond often. Best practices suggest determining availability every 5 seconds or so. That means every X seconds the load balancing service is going to open up a connection to the application and make a request. Just like a user would do. That adds load to the application. It consumes network, transport, application and (possibly) database resources. Resources that cannot be used to service customers. While the impact on a single application may appear trivial, it's not. Remember, as load increases performance decreases. And no matter how trivial it may appear, health monitoring is adding load to what may be an already heavily loaded application. But Lori, you may be thinking, you expound on the importance of monitoring and visibility all the time! Are you saying we shouldn't be monitoring applications? Nope, not at all. Visibility is paramount, providing the actionable data necessary to enable highly dynamic, automated operations such as elasticity. Visibility through health-monitoring is a critical means of ensuring availability at both the local and global level. What we may need to do, however, is move from active to passive monitoring. PASSIVE MONITORING Passive monitoring, as the modifier suggests, is not an active process. The Load balancer does not open up connections nor query an application itself. Instead, it snoops on responses being returned to clients and from that infers the current status of the application. For example, if a request for content results in an HTTP error message, the load balancer can determine whether or not the application is available and capable of processing subsequent requests. If the load balancer is a BIG-IP, it can mark the service as "down" and invoke an active monitor to probe the application status as well as retrying the request to another available instance – insuring end-users do not see an error. Passive (inband) monitors are not binary. That is, they aren't simple "on" or "off" based on HTTP status codes. Such monitors can be configured to track the number of failures and evaluate failure rates against a configurable failure interval. When such thresholds are exceeded, the application can then be marked as "down". Passive monitors aren't restricted to availability status, either. They can also monitor for performance (response time). Failure to meet response time expectations results in a failure, and the application continues to be watched for subsequent failures. Passive monitors are, like most inline/inband technologies, transparent. They quietly monitor traffic and act upon that traffic without adding overhead to the process. Passive monitoring gives operations the visibility necessary to enable predictable performance and to meet or exceed user expectations with respect to uptime, without negatively impacting performance or capacity of the applications it is monitoring.2.8KViews1like2CommentsThe Limits of Cloud: Gratuitous ARP and Failover
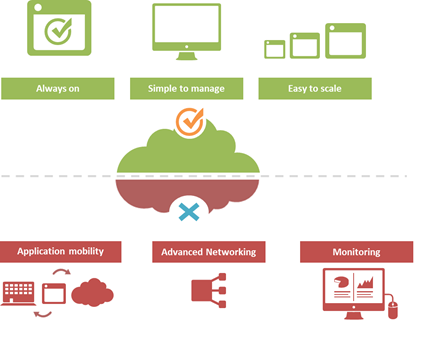
#Cloud is great at many things. At other things, not so much. Understanding the limitations of cloud will better enable a successful migration strategy. One of the truisms of technology is that takes a few years of adoption before folks really start figuring out what it excels at – and conversely what it doesn't. That's generally because early adoption is focused on lab-style experimentation that rarely extends beyond basic needs. It's when adoption reaches critical mass and folks start trying to use the technology to implement more advanced architectures that the "gotchas" start to be discovered. Cloud is no exception. A few of the things we've learned over the past years of adoption is that cloud is always on, it's simple to manage, and it makes applications and infrastructure services easy to scale. Some of the things we're learning now is that cloud isn't so great at supporting application mobility, monitoring of deployed services and at providing advanced networking capabilities. The reason that last part is so important is that a variety of enterprise-class capabilities we've come to rely upon are ultimately enabled by some of the advanced networking techniques cloud simply does not support. Take gratuitous ARP, for example. Most cloud providers do not allow or support this feature which ultimately means an inability to take advantage of higher-level functions traditionally taken for granted in the enterprise – like failover. GRATUITOUS ARP and ITS IMPLICATIONS For those unfamiliar with gratuitous ARP let's get you familiar with it quickly. A gratuitous ARP is an unsolicited ARP request made by a network element (host, switch, device, etc… ) to resolve its own IP address. The source and destination IP address are identical to the source IP address assigned to the network element. The destination MAC is a broadcast address. Gratuitous ARP is used for a variety of reasons. For example, if there is an ARP reply to the request, it means there exists an IP conflict. When a system first boots up, it will often send a gratuitous ARP to indicate it is "up" and available. And finally, it is used as the basis for load balancing failover. To ensure availability of load balancing services, two load balancers will share an IP address (often referred to as a floating IP). Upstream devices recognize the "primary" device by means of a simple ARP entry associating the floating IP with the active device. If the active device fails, the secondary immediately notices (due to heartbeat monitoring between the two) and will send out a gratuitous ARP indicating it is now associated with the IP address and won't the rest of the network please send subsequent traffic to it rather than the failed primary. VRRP and HSRP may also use gratuitous ARP to implement router failover. Most cloud environments do not allow broadcast traffic of this nature. After all, it's practically guaranteed that you are sharing a network segment with other tenants, and thus broadcasting traffic could certainly disrupt other tenant's traffic. Additionally, as security minded folks will be eager to remind us, it is fairly well-established that the default for accepting gratuitous ARPs on the network should be "don't do it". The astute observer will realize the reason for this; there is no security, no ability to verify, no authentication, nothing. A network element configured to accept gratuitous ARPs does so at the risk of being tricked into trusting, explicitly, every gratuitous ARP – even those that may be attempting to fool the network into believing it is a device it is not supposed to be. That, in essence, is ARP poisoning, and it's one of the security risks associated with the use of gratuitous ARP. Granted, someone needs to be physically on the network to pull this off, but in a cloud environment that's not nearly as difficult as it might be on a locked down corporate network. Gratuitous ARP can further be used to execute denial of service, man in the middle and MAC flooding attacks. None of which have particularly pleasant outcomes, especially in a cloud environment where such attacks would be against shared infrastructure, potentially impacting many tenants. Thus cloud providers are understandably leery about allowing network elements to willy-nilly announce their own IP addresses. That said, most enterprise-class network elements have implemented protections against these attacks precisely because of the reliance on gratuitous ARP for various infrastructure services. Most of these protections use a technique that will tentatively accept a gratuitous ARP, but not enter it in its ARP cache unless it has a valid IP-to-MAC mapping, as defined by the device configuration. Validation can take the form of matching against DHCP-assigned addresses or existence in a trusted database. Obviously these techniques would put an undue burden on a cloud provider's network given that any IP address on a network segment might be assigned to a very large set of MAC addresses. Simply put, gratuitous ARP is not cloud-friendly, and thus it is you will be hard pressed to find a cloud provider that supports it. What does that mean? That means, ultimately, that failover mechanisms in the cloud cannot be based on traditional techniques unless a means to replicate gratuitous ARP functionality without its negative implications can be designed. Which means, unfortunately, that traditional failover architectures – even using enterprise-class load balancers in cloud environments – cannot really be implemented today. What that means for IT preparing to migrate business critical applications and services to cloud environments is a careful review of their requirements and of the cloud environment's capabilities to determine whether availability and uptime goals can – or cannot – be met using a combination of cloud and traditional load balancing services.1.1KViews1like0CommentsIP::addr and IPv6
Did you know that all address internal to tmm are kept in IPv6 format? If you’ve written external monitors, I’m guessing you knew this. In the external monitors, for IPv4 networks the IPv6 “header” is removed with the line: IP=`echo $1 | sed 's/::ffff://'` IPv4 address are stored in what’s called “IPv4-mapped” format. An IPv4-mapped address has its first 80 bits set to zero and the next 16 set to one, followed by the 32 bits of the IPv4 address. The prefix looks like this: 0000:0000:0000:0000:0000:ffff: (abbreviated as ::ffff:, which looks strickingly simliar—ok, identical—to the pattern stripped above) Notation of the IPv4 section of the IPv4-formatted address vary in implementations between ::ffff:192.168.1.1 and ::ffff:c0a8:c8c8, but only the latter notation (in hex) is supported. If you need the decimal version, you can extract it like so: % puts $x ::ffff:c0a8:c8c8 % if { [string range $x 0 6] == "::ffff:" } { scan [string range $x 7 end] "%2x%2x:%2x%2x" ip1 ip2 ip3 ip4 set ipv4addr "$ip1.$ip2.$ip3.$ip4" } 192.168.200.200 Address Comparisons The text format is not what controls whether the IP::addr command (nor the class command) does an IPv4 or IPv6 comparison. Whether or not the IP address is IPv4-mapped is what controls the comparison. The text format merely controls how the text is then translated into the internal IPv6 format (ie: whether it becomes a IPv4-mapped address or not). Normally, this is not an issue, however, if you are trying to compare an IPv6 address against an IPv4 address, then you really need to understand this mapping business. Also, it is not recommended to use 0.0.0.0/0.0.0.0 for testing whether something is IPv4 versus IPv6 as that is not really valid a IP address—using the 0.0.0.0 mask (technically the same as /0) is a loophole and ultimately, what you are doing is loading the equivalent form of a IPv4-mapped mask. Rather, you should just use the following to test whether it is an IPv4-mapped address: if { [IP::addr $IP1 equals ::ffff:0000:0000/96] } { log local0. “Yep, that’s an IPv4 address” } These notes are covered in the IP::addr wiki entry. Any updates to the command and/or supporting notes will exist there, so keep the links handy. Related Articles F5 Friday: 'IPv4 and IPv6 Can Coexist' or 'How to eat your cake ... Service Provider Series: Managing the ipv6 Migration IPv6 and the End of the World No More IPv4. You do have your IPv6 plan running now, right ... Question about IPv6 - BIGIP - DevCentral - F5 DevCentral ... Insert IPv6 address into header - DevCentral - F5 DevCentral ... Business Case for IPv6 - DevCentral - F5 DevCentral > Community ... We're sorry. The IPv4 address you are trying to reach has been ... Don MacVittie - F5 BIG-IP IPv6 Gateway Module1.1KViews1like1CommentBIG-IP Configuration Conversion Scripts
Kirk Bauer, John Alam, and Pete White created a handful of perl and/or python scripts aimed at easing your migration from some of the “other guys” to BIG-IP.While they aren’t going to map every nook and cranny of the configurations to a BIG-IP feature, they will get you well along the way, taking out as much of the human error element as possible.Links to the codeshare articles below. Cisco ACE (perl) Cisco ACE via tmsh (perl) Cisco ACE (python) Cisco CSS (perl) Cisco CSS via tmsh (perl) Cisco CSM (perl) Citrix Netscaler (perl) Radware via tmsh (perl) Radware (python)1.6KViews1like13CommentsThe Full-Proxy Data Center Architecture
Why a full-proxy architecture is important to both infrastructure and data centers. In the early days of load balancing and application delivery there was a lot of confusion about proxy-based architectures and in particular the definition of a full-proxy architecture. Understanding what a full-proxy is will be increasingly important as we continue to re-architect the data center to support a more mobile, virtualized infrastructure in the quest to realize IT as a Service. THE FULL-PROXY PLATFORM The reason there is a distinction made between “proxy” and “full-proxy” stems from the handling of connections as they flow through the device. All proxies sit between two entities – in the Internet age almost always “client” and “server” – and mediate connections. While all full-proxies are proxies, the converse is not true. Not all proxies are full-proxies and it is this distinction that needs to be made when making decisions that will impact the data center architecture. A full-proxy maintains two separate session tables – one on the client-side, one on the server-side. There is effectively an “air gap” isolation layer between the two internal to the proxy, one that enables focused profiles to be applied specifically to address issues peculiar to each “side” of the proxy. Clients often experience higher latency because of lower bandwidth connections while the servers are generally low latency because they’re connected via a high-speed LAN. The optimizations and acceleration techniques used on the client side are far different than those on the LAN side because the issues that give rise to performance and availability challenges are vastly different. A full-proxy, with separate connection handling on either side of the “air gap”, can address these challenges. A proxy, which may be a full-proxy but more often than not simply uses a buffer-and-stitch methodology to perform connection management, cannot optimally do so. A typical proxy buffers a connection, often through the TCP handshake process and potentially into the first few packets of application data, but then “stitches” a connection to a given server on the back-end using either layer 4 or layer 7 data, perhaps both. The connection is a single flow from end-to-end and must choose which characteristics of the connection to focus on – client or server – because it cannot simultaneously optimize for both. The second advantage of a full-proxy is its ability to perform more tasks on the data being exchanged over the connection as it is flowing through the component. Because specific action must be taken to “match up” the connection as its flowing through the full-proxy, the component can inspect, manipulate, and otherwise modify the data before sending it on its way on the server-side. This is what enables termination of SSL, enforcement of security policies, and performance-related services to be applied on a per-client, per-application basis. This capability translates to broader usage in data center architecture by enabling the implementation of an application delivery tier in which operational risk can be addressed through the enforcement of various policies. In effect, we’re created a full-proxy data center architecture in which the application delivery tier as a whole serves as the “full proxy” that mediates between the clients and the applications. THE FULL-PROXY DATA CENTER ARCHITECTURE A full-proxy data center architecture installs a digital "air gap” between the client and applications by serving as the aggregation (and conversely disaggregation) point for services. Because all communication is funneled through virtualized applications and services at the application delivery tier, it serves as a strategic point of control at which delivery policies addressing operational risk (performance, availability, security) can be enforced. A full-proxy data center architecture further has the advantage of isolating end-users from the volatility inherent in highly virtualized and dynamic environments such as cloud computing . It enables solutions such as those used to overcome limitations with virtualization technology, such as those encountered with pod-architectural constraints in VMware View deployments. Traditional access management technologies, for example, are tightly coupled to host names and IP addresses. In a highly virtualized or cloud computing environment, this constraint may spell disaster for either performance or ability to function, or both. By implementing access management in the application delivery tier – on a full-proxy device – volatility is managed through virtualization of the resources, allowing the application delivery controller to worry about details such as IP address and VLAN segments, freeing the access management solution to concern itself with determining whether this user on this device from that location is allowed to access a given resource. Basically, we’re taking the concept of a full-proxy and expanded it outward to the architecture. Inserting an “application delivery tier” allows for an agile, flexible architecture more supportive of the rapid changes today’s IT organizations must deal with. Such a tier also provides an effective means to combat modern attacks. Because of its ability to isolate applications, services, and even infrastructure resources, an application delivery tier improves an organizations’ capability to withstand the onslaught of a concerted DDoS attack. The magnitude of difference between the connection capacity of an application delivery controller and most infrastructure (and all servers) gives the entire architecture a higher resiliency in the face of overwhelming connections. This ensures better availability and, when coupled with virtual infrastructure that can scale on-demand when necessary, can also maintain performance levels required by business concerns. A full-proxy data center architecture is an invaluable asset to IT organizations in meeting the challenges of volatility both inside and outside the data center. Related blogs & articles: The Concise Guide to Proxies At the Intersection of Cloud and Control… Cloud Computing and the Truth About SLAs IT Services: Creating Commodities out of Complexity What is a Strategic Point of Control Anyway? The Battle of Economy of Scale versus Control and Flexibility F5 Friday: When Firewalls Fail… F5 Friday: Platform versus Product3.9KViews1like1Comment
F5 Cookbooks Serve Up Easy-to-Use Configuration Recipes. Bon Appétit!
Whether you are whipping up a crème brûlée or configuring your BIG-IP system to manage web traffic, a good cookbook won’t let you down. Gourmet chefs know that the best way to help us cook a dinner fit for a queen is to create recipes. Top-notch recipes don’t just give us a list of ingredients or describe the chemical composition of an emulsifier; they give us simple, step-by-step instructions on how to cook a meal so delectable our guests will be tweeting about it before they leave the dinner table. Fortunately, recipes aren’t just for cooking. They can also help you configure your BIG-IP system, quickly and easily. Just for fun, here’s a potential recipe for web hosting two different customers through an external switch. Ingredients: 1 BIG-IP system interface 2 VLANs 2 load balancing pools 2 virtual servers routes Instructions: 1. Create an internal VLAN, assigning the interface as a tagged interface to the VLAN. 2. Create a load balancing pool, with content servers as its pool members. 3. Create a virtual server that references the pool. 4. Add routes, to taste. 5. Wash, rinse, repeat. (O.K., a tad over-simplified maybe, but you get the idea.) In this same spirit, the F5 product documentation team regularly publishes a special category of “cookbooks” known as implementations guides. Derived in part from real customer use cases, these guides give you detailed step-by-step instructions for how to quickly combine ingredients (aka product features) to reach your goals, without dropping too many eggs on the floor in the process. For example, the guide BIG-IP Local Traffic Manager: Implementations offers a slew of instructions ranging from how to set up HTTP data compression to how to segment application traffic into route domains. Another guide, BIG-IP Global Traffic Manager: Implementations, gives instructions such as how to set up wide IP load balancing and how to manage bandwidth based on link thresholds. Currently, F5 offers implementations guides for BIG-IP Local Traffic Manager, BIG-IP Global Traffic Manager, and BIG-IP Application Security Manager, and you can find all of these guides on our Ask F5 web site, https://support.f5.com. When you crack open our BIG-IP implementations guides, it’s a sure bet that your dinner guests won’t give a hoot, but your IT staff (and ultimately your application users) will be delighted.413Views1like0Comments