Anonymous DDOS Tools 2016
In February 2016, the hacktivist group Anonymous published a hacktivist message in avideo posted on YouTube. The video contains detailed examples of uses for various DDoS tools, andthe video description contains a link to a zip file containing these tools. Screenshot from the Anonymous DDOS Tools 2016 video on YouTube. 2016 Tools Bundle A substantial number of DDoS tools (20, in fact) are included in this bundle. All of them are easy to use and have nice GUI menus. It’s not necessary to have any understanding of how the attacks actually work in order to operate the tools. This makes them very appealing to lay persons with little understanding of computer networking. Screenshot from the video of multiple attack tools in use at once. Most of the tools offer similar DDoS attack types—mostly HTTP, TCP, and UDP floods—but there is some interesting differentiation. For example, some tools offer more Layer 7 attack granularity, while providing the attacker control of the attacked URL path and parameters and also supporting POST floods. Other tools are focused on a single attack type, such as "Anonymous Ping Attack" and "Pringle DDOS", which only have ICMP flood capability. Screenshot of Pringle DDoS - a simple ICMP flooder If an attacker wants to launch a powerful Low and Slow DDoS attack, surprisingly he or she will find only a single tool in this bundle, the well-known Slowloris.pl perl tool, which is not authored by Anonymous at all. R.U.D.Y and other slow POST tools are noticeably missing from this bundle. Another group of tools provide some evasions, such as support for sending requests with different user agent and referer headers. For example, theUnKnown DoSer, a Layer 7 flooder, even supports randomization ofURL, User-Agent , and the Content-Length values in order to bypass hard-coded attack signatures. Screenshot of UnKnown DoSer - a Layer 7 flooder, with request randomization capability Screenshot of UnKnown DoSer attack traffic, demonstrating fields randomization Can't get enough of LOIC Low Orbit Ion Cannon-based (LOIC-based) tools are prominent in this bundle of DDoS tools: LOIC, JavaLOIC, LOIC-IFC, LOIC-SD and NewLOIC. LOIC was notoriously known as the main attack delivery tool used in several Anonymous operations such as Operation Payback, Operation Chanology and more.Being JAVA based, JavaLOIC is across-platform tool witha built-in proxy feature that enables an attacker to hide his or her own IP address. Some Anonymous sub-groups localize and re-brand the LOIC tool. LOIC-SD was first published by a Brazilian hacker group called Script Defenders and is mainly designed to overcome a language barrier by translating LOIC's user interface into Portuguese. Script Defenders’ variant of LOIC The "Indonesia Fighter Cyber" hacking group created LOIC-IFC, which differs only in thedefault TCP/UDP flood message saying, "Merdeka atau Mati", which means "Freedom or Death" in Malay. From a technical perspective, it provides additionalability to append random characters to the attacked URL in case of HTTP flood, and to the packet payload in case of TCP/UDP. Another LOIC-modified tool included in this bundle is NewLOIC, which, despite its name, offers no new functionality, only a new GUI design. Anonymous still consider LOIC and its various versions to be meaningful tools in its DDoS arsenal. In fact, a quarter of the tools included in this bundle are LOIC-based tools, despite the risk of exposing the attacker’s IP address by using these tools. DDoS Tools Features Comparison Some of the DDoS tools known to be used by Anonymous aren’t included in the published bundle.R.U.D.Y,keep-dead.php,TORsHammer,THC-SSL-DOS,#Refref, andAnonStress are just some of the known tools that don't appear here. Attack tools that use proxies in order to protect the identity of their users also seem to be missing in this bundle, which makes potential Anonymous newrecruits vulnerable to detection andprosecution. Even so, Anonymous continues to strengthen its presence.By regularly publishing a variety of simple-to-use tools, the group makes DDoS attacks more accessible and easy to perpetrate, with the obvious goal of recruiting more users to support its hacktivist operations. Although not a single tool in the bundle is new, the group continues to terrorize the world with every successful DDoS operation. Mitigating The Threat F5 mitigates a wide range of DDoS attacks, including those generated by Anonymous tools, using it's unique combination of innovative security products and services. F5’s DDoS Protection solution protects the fundamental elements of an application (network, DNS, SSL, and HTTP) against distributed denial-of-service attacks. Leveraging the intrinsic security capabilities of intelligent traffic management and application delivery, F5 protects and ensures availability of an organization's network and application infrastructure under the most demanding conditions.17KViews0likes0Comments
Explanation of F5 DDoS threshold modes
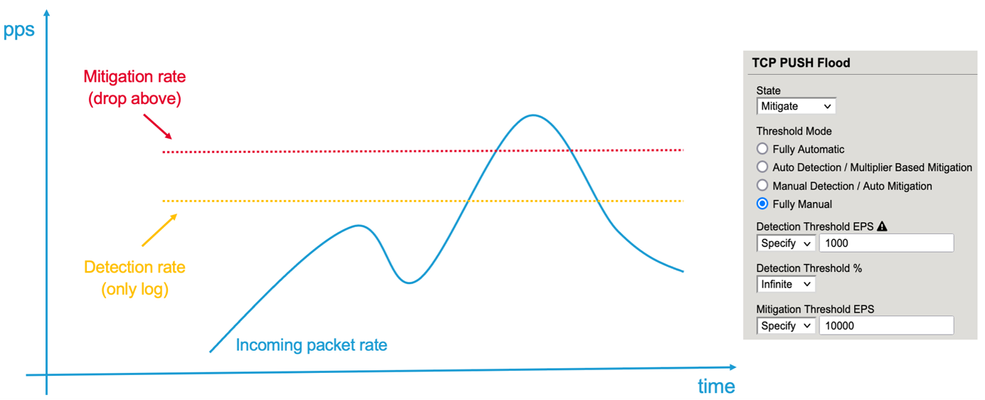
Der Reader, In my article “Concept of Device DOS and DOS profile”, I recommended to use the “Fully Automatic” or “Multiplier” based configuration option for some DOS vectors. In this article I would like to explain how these threshold modes work and what is happening behind the scene. When you configure a DOS vector you have the option to choose between different threshold modes: “Fully Automatic”, “Auto Detection / Multiplier Based”, “Manual Detection / Auto Mitigation” and “Fully Manual”. Figure 1: Threshold Modes The two options I normally use on many vectors are “Fully Automatic” and “Auto Detection / Multiplier Based”. But what are these two options do for me? To manually set thresholds is for some vectors not an easy task. I mean who really knows how many PUSH/ACK packets/sec for example are usually hitting the device or a specific service? And when I have an idea about a value, should this be a static value? Or should I better take the maximum value I have seen so far? And how many packets per second should I put on top to make sure the system is not kicking in too early? When should I adjust it? Do I have increasing traffic? Fully Automatic In reality, the rate changes constantly and most likely during the day I will have more PUSH/ACK packets/sec then during the night. What happens when there is a campaign or an event like “Black Friday” and way more users are visiting the webpage then usually? During these high traffic events, my suggested thresholds might be no longer correct which could lead to “good” traffic getting dropped. All this should be taken into consideration when setting a threshold and it ends up being very difficult to do manually. It´s better to make the machine doing it for you and this is what “Fully Automatic” is about. Figure 2: Expected EPS As soon as you use this option, it leverages from the learning it has done since traffic is passing through the BIG-IP, or since you have enforced the relearning, which resets everything learned so far and starts from new. The system continuously calculates the expected rates for all the vectors based on the historic rates of traffic. It takes the information up to one year and calculates them with different weights in order to know which packets rate should be expected at that time and day for that specific vector in the specific context (Device, Virtual Server/Protected Object). The system then calculates a padding on top of this expected rate. This rate is called Detection Rate and is dependent on the “threshold sensitivity” you have configured: Low Sensitivity means 66% padding Medium Sensitivity means 40% padding High Sensitivity means 0% padding Figure 3: Detection EPS As soon as the current rate is above the detection value, the BIG-IP will show the message “Attack detected”, which actually means anomaly detected, because it sees more packets of that specific vector then expected + the padding (detection_rate). But DoS mitigation will not start at that point! Figure 4: Current EPS Keep in mind, when you run the BIG-IP in stateful mode it will drop 'out of state' packets anyway. This has nothing to do with DoS functionalities. But what happens when there is a serious flood and the BIG-IP CPU gets high because of the massive number of packets it has to deal with? This is when the second part of the “Fully Automatic” approach comes into the game. Again, depending on your threshold sensitivity the DOS mitigation starts as soon as a certain level of stress is detected on the CPU of the BIG-IP. Figure 5: Mitigation Threshold Low Sensitivity means 78,3% TMM load Medium Sensitivity means 68,3% TMM load High Sensitivity means 51,6% TMM load Note, that the mitigation is per TMM and therefore the stress and rate per TMM is relevant. When the traffic rate for that vector is above the detection rate and the CPU of the BIG-IP (Device DOS) is “too” busy, the mitigation kicks in and will rate limit on that specific vector. When a DOS vector is hardware supported, FPGAs drop the packets at the switch level of the BIG-IP. If that DOS vector is not hardware supported, then the packet is dropped at a very early stage of the life cycle of a packet inside a BIG-IP. The rate at which are packets dropped is dynamic (mitigation rate), depending on the incoming number of packets for that vector and the CPU (TMM) stress of the BIG-IP. This allows the stress of the CPU to go down as it has to deal with less packets. Once the incoming rate is again below the detection rate, the system declares the attack as ended. Note: When an attack is detected, the packet rate during that time will not go into the calculation of expected rates for the future. This ensures that the BIG-IP will not learn from attack traffic skewing the automatic thresholds. All traffic rates below the detection (or below the floor value, when configured) rate modify the expected rate for the future and the BIG-IP will adjust the detection rate automatically. For most of the vectors you can configure a floor and ceiling value. Floor means that as long as the traffic value is below that threshold, the mitigation for that vector will never kick in. Even when the CPU is at 100%. Ceiling means that mitigation always kicks in at that rate, even when the CPU is idle. With these two values the dynamic and automatic process is done between floor and ceiling. Mitigation only gets executed when the rate is above the rate of the Floor EPS and Detection EPS AND stress on the particular context is measured. Figure 6: Floor and Ceiling EPS What is the difference when you use “Fully Automatic” on Device level compared to VS/PO (DOS profile) level? Everything is the same, except that on VS or Protected Object (PO) level the relevant stress is NOT the BIG-IP device stress, it is the stress of the service you are protecting (web-, DNS, IMAP-server, network, ...). BIG-IP can measure the stress of the service by measuring TCP attributes like retransmission, window size, congestion, etc. This gives a good indication on how busy a service is. This works very well for request/response protocols like TCP, HTTP, DNS. I recommend using this, when the Protected Object is a single service and not a “wildcard” Protected Object covering for example a network or service range. When the Protected Object is a “wildcard” service and/or a UDP service (except DNS), I recommend using “Auto Detection / Multiplier Option”. It works in the same way as the “Fully Automatic” from the learning perspective, but the mitigation condition is not stress, it is the multiplication of the detection rate. For example, the detection rate for a specific vector is calculated to be 100k packets/sec. By default, the multiplication rate is “500”, which means 5x. Therefore, the mitigation rate is calculated to 500k packets/sec. If that particular vector has more than 500k packets/sec those packets would be dropped. The multiplication rate can also be individually configured. Like in the screenshot, where it is set to 8x (800). Figure 7: Auto Detection / Multiplier Based Mitigation The benefit of this mode is that the BIG-IP will automatically learn the baseline for that vector and will only start to mitigate based on a large spike. The mitigation rate is always a multiplication of the detection rate, which is 5x by default but is configurable. When should I use “Fully Manual”? When you want to rate-limit a specific vector to a certain number of packets/sec, then “Fully Manual” is the right choice. Very good examples for that type of vector are the “Bad Header” vector types. These type of packets will never get forwarded by the BIG-IP so dropping them by a DoS vector saves the CPU, which is beneficial under DoS conditions. In the screenshot below is a vector configured as “Fully Manual”. Next I’ll describe what each of the options means. Figure 8: Fully Manual Detection Threshold EPS configures the packet rate/sec (pps) when you will get a log messages (NO mitigation!). Detection Threshold % compares the current pps rate for that vector with the multiplication of the configured percentage (in this example 5 for 500%) with the 1-minute average rate. If the current rate is higher, then you will get a log message. Mitigation Threshold EPS rate limits to that configured value (mitigation). I recommend setting the threshold (Mitigation Threshold EPS) to something relatively low like ‘10’ or ‘100’ on ‘Bad Header’ type of vectors. You can also set it also to ‘0’, which means all packets hitting this vector will get dropped by the DoS function which usually is done in hardware (FPGA). With the ‘Detection Threshold EPS’ you set the rate at which you want to get a log messages for that vector. If you do it this way, then you get a warning message like this one to inform you about the logging behavior: Warning generated: DOS attack data (bad-tcp-flags-all-set): Since drop limit is less than detection limit, packets dropped below the detection limit rate will not be logged. Another use-case for “Fully Manual” is when you know the maximum number of these packets the service can handle. But here my recommendation is to still use “Fully Automatic” and set the maximum rate with the Ceiling threshold, because then the protected service will benefit from both threshold options. Important: Please keep in mind, when you set manual thresholds for Device DoS the thresholds are to protect each TMM. Therefore the value you set is per TMM! An exception to this is the Sweep and Flood vector where the threshold is per BIG-IP/service and not per TMM like on DoS profiles. When using manual thresholds for aDOS profileof a Protected Object thethreshold configuration is per service (all packets targeted to the protected service) NOT per TMM like on the Device level. Here the goal is to set how many packets are allowed to pass the BIG-IP and reach the service. The distribution of these thresholds to the TMMs is done in a dynamic way: Every TMM gets a percentage of the configured threshold, based on the EPS (Events Per Second, which is in this context Packets Per Second) for the specific vector the system has seen in the second before on this TMM. This mechanism protects against hash type of attacks. Ok, I hope this article gives you a better understanding on how ‘Fully Manual’, ‘Fully Automatic’ and ‘Auto Detection / Multiplier Based Mitigation’ works. They are important concepts to understand, especially when they work in conjunction with stress measurement. This means the BIG-IP will only kick in with the DoS mitigation when the protected object (BIG-IP or the service behind the BIG-IP) is under stress. -Why risk false positives, when not necessary? With my next article I will demonstrate you how Device DoS and the DoS profiles work together andhow the stateful concept cooperates with the DoS mitigation. I will show you some DoS commands to test it and also commands to get details from the BIG-IP via CLI. Thank you, sVen Mueller8.9KViews20likes10CommentsConcept of F5 Device DoS and DoS profiles
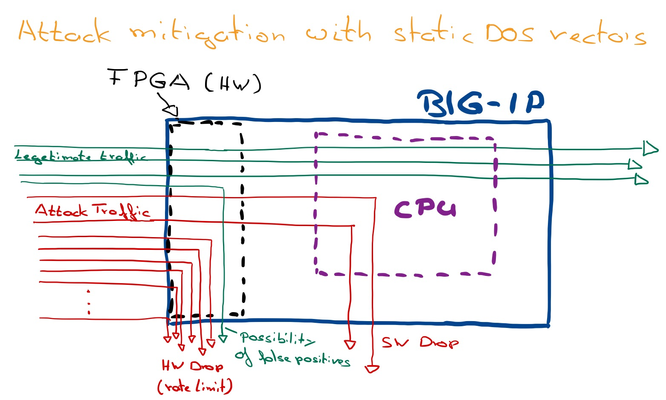
Dear Reader, I´m about to write a series of DDoS articles, which will hopefully help you to better understand how F5 DDoS works and how to configure it. I plan to release them in a more or less regular frequency. Feel free to send me your feedback and let me know which topics are relevant for you and should get covered. This first article is intended to give an explanation of the BIG-IP Device DOS and Per Service-DOS protection (DOS profile). It covers the concepts of both approaches and explains in high level the threshold modes “Fully manual”, “Fully Automatic” and “Multiplier Based Mitigation” including the principles of stress measurement. In later articles I will describe this threshold modes in more detail. In the end of the article you will also find an explanation of the physical and logical data path of the BIG-IP. Device DOS with static DoS vectors The primary goal of “Device DOS” is to protect the BIG-IP itself. BIG-IP has to deal with all packets arriving on the device, regardless of an existing listener (Virtual Server (VS)/ Protected Object (PO)), connection entry, NAT entry or whatever. As soon as a packet hits the BIG-IP it´s CPU has basically to deal with it. Picking up each and every packet consumes CPU cycles, especially under heavy DOS conditions. The more operations each packet needs, depending on configurations, the higher the CPU load gets, because it consumes more CPU cycles. The earlier BIG-IP can drop a packet (if the packet needs to get dropped) the better it is for the CPU load. If the drop process is done in hardware (FPGA), the packet gets dropped before it consumes CPU cycles. Using static DOS vectors helps to lower the number of packets hitting the CPU when under DoS. If the number of packets is above a certain threshold (usually when a flood happens), BIG-IP rate-limits for that specific vector, which keeps the CPU available, because it sees less packets. Figure 1: Principle of Attack mitigation with static DoS vectors The downside with this approach is that the BIG-IP cannot differentiate between "legitimate" and "attacking" packets, when using static DOS rate-limit. BIG-IP (FPGA) just drops on the predicates it gets from the static DOS vector. Predicates are attributes of a packet like protocol “TCP” or “flag” set “ACK”. -Keep in mind, when BIG-IP runs stateful, "bad" packets will get dropped in software anyway by the operating system (TMOS), when it identifies them as not belonging to an existing connection or as invalid/broken (for example bad CRC checksum). This is of course different for SYN packets, because they create connection entries. This is where SYN-Cookies play an important role under DoS conditions and will be explained in a later article. I usually recommend running Behavioral DoS mitigation in conjunction with static DoS vectors. It is way more precise and able to filter out only the attack traffic, but I will discuss this in more detail also in one of the following articles. Manual threshold vs. Fully Automatic Before I start to explain the “per service DoS protection” (DoS profiles), I would like to give you a brief overview of some Threshold modes you can use per DoS vector. There are different ways to set thresholds to activate the detection and rate-limiting on a DOS vector. The operator can do it manual by using the option “Fully Manual” and then fine tune the pre-configured values on the DOS vectors, which can be challenging, because beside doing it all manually it´s mostly difficult to know the thresholds, especially because they are usually related to the day and time of the week. Figure 2: Example of a manual DoS vector configuration That’s why most of the vectors have the option "Fully Automatic" available. It means BIG-IP will learn from the history and “knows” how many packets it usually “sees” at that specific time for the specific vector. This is called the baselining and calculates the detection threshold. Figure 3: Threshold Modes As soon as a flood hits the BIG-IP and crosses the detection threshold for a vector, BIG-IP detects it as an attack for that vector, which basically means it identifies it as an anomaly. However, it does not start to mitigate (drop). This will only happen as soon as a TMM load (CPU load) is also above a certain utilization (Mitigation sensitivity: Low: 78%, Medium 68%, High: 51%). If both conditions (packet rate and TMM/CPU load is too high) are true, the mitigation starts and lowers (rate-limit) the number of packets for this vector going into the BIG-IP for the specific TMM. That means dropping packets by the DOS feature will only happen if necessary, in order to protect the BIG-IP CPU. This is a dynamic process which drops more packets when the attack becomes more aggressive and less when the attack becomes less aggressive. For TCP traffic keep in mind the “invalid” traffic will not get forwarded anyway, which is a strong benefit of running the device stateful. When a DOS vector is hardware supported then FPGAs drop the packets basically at the switch level of the BIG-IP. If it’s not hardware supported, then the packet is dropped at a very early stage of the life cycle of a packet “inside” a BIG-IP. Device DOS counts ALL packets going to the BIG-IP. It doesn´t matter if they have a destination behind the BIG-IP, or when it is the BIG-IP itself. BecauseDevice DOSis to protect the BIG-IP,the thresholdsyou can configure in the “manual configuration” mode on the DOS vectorsare per TMM! This means you configure the maximum number of packets one TMM can handle. Very often operators want to set an overall threshold of let’s say 10k, then they need to divide this limit by the number of TMMs.An Exception is the Sweep and Flood vector. Here the threshold is per BIG-IP and not per TMM. DOS profile for protected Objects Now let’s talk about the “per Service DoS Protection (DoS profile)”. The goal is to protect the service which runs behind the BIG-IP. Important to know, when BIG-IP runs stateful, the service is already protected by the state of BIG-IP (true for TCP traffic). That means a randomized ACK flood for example will never hit the service. On stateless traffic (UDP/ICMP) it is different, here the BIG-IP simply forward packets.Fully Automatic used on a DoS profile discovers thehealth of the service, which works well if its TCP or DNS traffic. (This is done by evaluating the TCP behavior like Window Size, Retransmission, Congestions, or counting DNS requests vs. responses, ....). If the detection rate for that service is crossed (anomaly detected) and stress on the service is identified, the mitigation starts. Again, keep in mind for TCP this will only happen for “legitimate” traffic, because out of the state traffic will never reach the service. It is already protected by the BIG-IP being configured state-full. An example could be a HTTP flood.My recommendation:If you have the option to configureL7 BaDOS(Behavioral DOS running on DHD/A-WAF), then go with that one. It gives much better results and better mitigation options on HTTP floods then just L3/4 DOS, because it does also operate on L7. Please also do thennot configureTCP DOS for “Push Flood”, "bad ACK Flood" and “SYN Flood”, on that DOS profile, except you use a TMOS version newer than 14.1. For other TCP services like POP3, SMTP, LDAP … you can always go with the L3/4 DOS vectors. Since TMOS version 15.0 L7 BaDOS and L3/4 DOS vectors work in conjunction. Stateless traffic (UDP/ICMP) For UDP traffic I would like to separate UDP into DNS traffic and non-DNS-UDP traffic. DNS is a very good example where the health detection mechanism works great. This is done by measuring the ratio of requests vs. responses. For example, if BIG-IP sees 100k queries/sec going to the DNS server and the server sends back 100k answers/sec, the server shows it can handle the load. If it sees 200k queries/sec going to the server and the server sends back only 150k queries/sec, then it is a good indication of that the server cannot handle the load. In that case the BIG-IP would start to rate-limit, when the current rate is also above the detection rate (The rate BIG-IP expects based on the history rates). The 'Device UDP' vector gives you the option to exclude UDP traffic on specific ports from the UDP vector (packet counting). For example, when you exclude port 53 and UDP traffic hits that port, then it will not count into the UDP counter. In that case you would handle the DNS traffic with the DNS vectors. Figure 4 : UDP Port exclusion Here you see an example for port 53 (DNS), 5060 (SIP), 123 (NTP) Auto Detection / Multiplier Based Mitigation If the traffic is non-DNS-UDP traffic or ICMP traffic the stress measurement does not work very accurate, so I recommend going with the“multiplier option” on the DOS profile. Here BIG-IP does the baselining (calculating the detection rate) similar to “fully automatic” mode, except it will kick in (rate-limit) if it sees more than the defined multiplication for the specific vector, regardless of the CPU load. For example, when the calculated detection rate is 250k packets/sec and the multiplication is set to 500 (which means 5 times), then the mitigation rate would be 250k x 5 = 1.250.000 packets/sec. The multiplier feature gives the nice option to configure a threshold based on the multiplication of an expected rate. Figure 5 : Multiplier based mitigation On aDOS profilethethreshold configuration is per service (all packets targeted to the protected service), which actually means on that BIG-IP and NOT per TMM like on the Device level. Here the goal is to set how many packets are allowed to pass the BIG-IP and reach the service. The distribution of these thresholds to the TMMs is done in a dynamic way: Every TMM gets a percentage of the configured threshold, based on the EPS (Events Per Second, which is in this context Packets Per Second) for the specific vector the system has seen in the second before on this TMM. This mechanism protects against hash type of attacks. Physical and logical data path There is aphysical and logical traffic pathin BIG-IP. When a packet gets dropped via a DOS profile on a VS/PO, then BIG-IP will not see it on the device level counter anymore. If the threshold on the device level is reached, the packet gets dropped by the device level and will not get to the DOS profile. So, the physical path is device first and then comes the VS/PO, but the logical path is VS/PO first and then device. That means, when a packet arrives on the device level (physical first), that counter gets incremented. If the threshold is not reached, the packet goes to the VS/PO (DOS profile) level. If the threshold is reached here, then the packet gets dropped and the counter for the device DOS vector decremented. If the packet does not get dropped, then the packet counts into both counters (Device/VS). This means that the VS/PO thresholds should always set lower than device thresholds (remember on Device level you set the thresholds per TMM!). The device threshold should be the maximum the BIG-IP (TMM) can handle overall. It is important to note that mitigation in manual mode are “hard” numbers and do not take into account the stress on the service. In “Fully Automatic” mode on the VS/PO level, mitigation kicks in when the detection threshold is reached AND the stress on the service is too high. Now let’s assume a protected TCP service behind the BIG-IP gets attacked by a TCP attack like a randomized Push/ACK food. Because of the high packet rate hitting that vector on the attached DOS profile for that PO, it will go into 'detect mode'. But because it is a TCP flood and BIG-IP is configured to run state-full, the attack packets will never reach the service behind the BIG-IP and therefore the stress on that service will never go high in this case. The flood is then handled by the session state (CPU) of the BIG-IP until this gets too much under pressure and then the Device DOS will kick in “upfront” and mitigate the flood. If you use the “multiplication” option, then the mitigation kicks in when the packet detection rate + multiplication is reached. This can happen on the VS/PO level and/or on the Device level, because it is independent of stress. “Fully automatic” will not work properly with asymmetric traffic for VS/PO, because here BIG-IP cannot identify if the service is under stress due to the fact that BIG-IP will only see half of the traffic. -Either request or response depending on where it is initiated. For deployments with asymmetric traffic I recommend using the manual or “multiplier option”, on VS/PO configurations. The “Multiplier option” keeps it dynamic in regard to the calculated detection and mitigation rate based on the history. “Fully Automatic” works with Asymmetric traffic on Device DOS, because it measures the CPU (TMM) stress of the BIG-IP itself. Of course, when you run asymmetric traffic, BIG-IP can´t be state-full. I recommend to always start first with the Device DOS configuration to protect the BIG-IP itself against DOS floods and then to focus on the DOS protection for the services behind the BIG-IP. On Device DOS you will probably mostly use “Fully Manual” and “Fully Automatic” threshold modes. To protect services, you will mostly go with “Fully Manual” and “Fully Automatic” or “Auto Detection/ Multiplier based mitigation”. In one of the next articles I will describe in more detail when to use what and why. As mentioned before, additional to the static DoS vectors I recommend enabling Behavioral DOS, which is way smarter than the static DOS vectors and can filter out specifically only the attack traffic which tremendously decrease the chance of false positives. You can enable it like the static DoS vectors on Device- an on VS/PO level. But this topic will be covered in another article as well. With that said I would like to finish my first article. Let me know your feedback. Thank you, sVen Mueller6.7KViews32likes7CommentsCookie-based DDoS protection
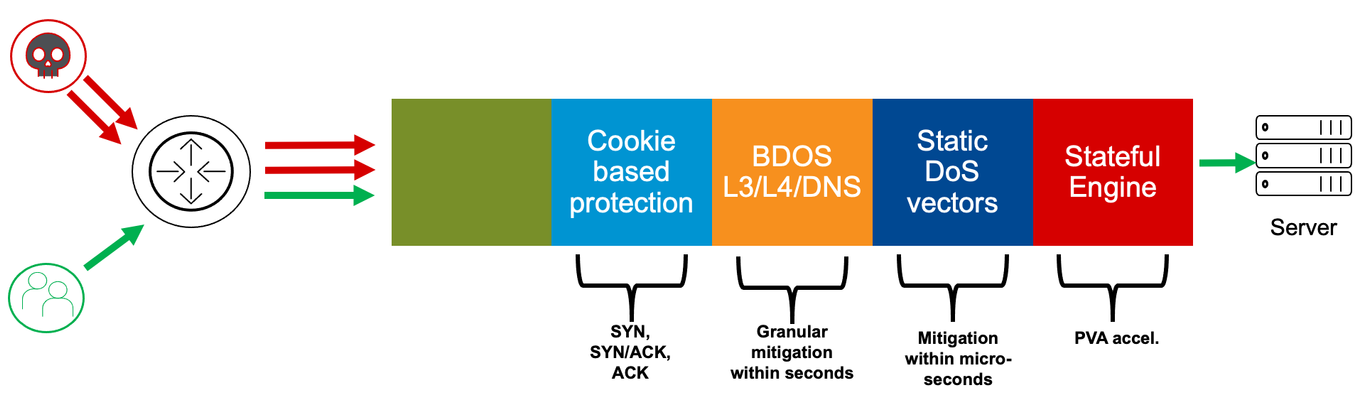
Dear Reader, DDoS protection starts with being able to identify that you are under attack. Next, you will need to be able to differentiate between good and bad traffic. This will be particularly challenging if the attack (bad) traffic looks like your good traffic. So, how can you ideally filter out only the attack traffic without affecting the good traffic? Well, and finally, you need to have the capacity and performance to deal with the high number of flood packets. In this article, I want to explain to you another layer of F5’s network DDoS protection, which perfectly meets these requirements: cookie-based DDoS protection. Figure 1: Multi-layer DDoS mitigation architecture Cookie-based protection No, I´m not talking about HTTP, we are still within the Network protection. Even on the network layer, BIG-IP can deal with cookies and can use it in a very effective way to mitigate without false/positives. The overall idea is to store connection- related information, encrypted within a packet, which is being forwarded. The response packet will have this cookie included as well and can be used to identify that the packet belongs to an existing connection. Therefore the packet is valid and not just a randomized packet to drive up CPU utilization. When the packet is “wrong” it can be dropped at an early stage by a dedicated chip (FPGA) and doesn´t consume CPU resources. But let´s start talking about attack vectors. SYN flood SYN flood is a very old, but still very effective way for DDoS attacks. The idea is to overwhelm stateful devices with too many half-open connections, which mostly results in (too) high CPU usage and/or fully utilized memory consumption. Attackers just send SYN packets towards the target (server, firewall, etc.). The first packet during a 3-way handshake of a connection setup will let the target immediately allocate memory for the TCP socket data structure holding the tuple, sequence number, and “state” of the session. The target then replies to the client (attacker) with an “SYN-ACK” packet. Under normal circumstances, packet loss or slow communication can cause the SYN-ACK packet to be delayed or lost altogether. The server must decide how long to hold the socket in a half-open state before transmitting a reset and releasing the memory for other tasks. This means the higher this timer is, the faster memory can get filled up under SYN flood conditions. But, on the other hand, the lower the value is, the higher the risk that you drop a valid connection request (for example, because of latency). SYN flood attackers usually spoof the source IP, so the SYN-ACK does not hit the initial source (attacker). This way the SYN flood can also result in an SYN-ACK flood done by the target (server, firewall, etc.), which will be especially painful because the spoof involves only one or a small number of IP addresses. This can be easily identified on the mitigation side and can get blocked or rate-limited. Keep in mind, however, that this could also be a strategy of the attacker… Some interesting side effects are also, that depending on the TCP stack, servers send a RST packet when they release a timed-out connection. Some TCP stacks do also send a RST packet when they receive an SYN-ACK packet for which they don´t have a connection entry. Therefore, often SYN floods do also end in SYN-ACK and RST floods as well. Figure 2: SYN flood But, how can you protect against this type of attack? SYN rate-limiting via static DoS vectors is one option, but it can potentially lead to false/positives. This is true in particular when you cannot limit the mitigation to “attacked destination” and/or “bad actors” (source IPs causing the stress). For further information, please read my article “Increasing accuracy using Bad Actor and Attacked Destination detection“. Behavioral DoS (BDoS) is a very effective way but usually takes a few seconds to kick in. Another strong option is to use F5’s SYN-Cookie mitigation. SYN-Cookie mitigation SYN-Cookie mitigation is an effective way to resist SYN floods. It gets activated when the threshold of the configured number of half-open connections is reached. On AFM (Advanced Firewall Manager) or DHD (DDoS Hybrid Defender), the threshold can be configured via the “tcp-half-open” vector on the device level and also on the per VS/PO level via a DoS profile attached to it. Figure 3: TCP Half Open vector configuration Mitigation threshold means, activate the SYN-cookie process after (in this example) 10.000 half-open connections. Keep in mind, on the Device level you configure the threshold per TMM and within a DoS profile it is per PO/VS to which it is attached. SYN-Cookie mitigation gets deployed by choosing initial TCP sequence numbers in the SYN-ACK response according to the properties of the originating TCP SYN. It encrypts connection information within the sequence number of the responding SYN-ACK packet. When the SYN was sent by a valid client, BIG-IP will receive a well-formed ACK response from the client including the cookie stored within the "ack" field and incremented by one. BIG-IP can now decrypt and reconstruct the connection details and establish the connection by performing the necessary SYN establishment handshakes with the server on behalf of the client. The beauty of this technique is that it smartly protects the memory, but the process of “encrypt” and “decrypt” the cookies consumes CPU, which can be potentially dangerous. To enhance the capability of the BIG-IP systems, SYN cookie functionality is extended to the FPGA, which is radically more effective than software mitigation alone. In this way, BIG-IP can differentiate between “valid” and “bad” SYN packets without negatively impacting memory or CPU performance! Here is a useful hint! As mentioned above, you can configure the activation of the SYN cookie process by defining a threshold of the number of half-open connections. This can be done via the “tcp-half-open” vector on the Device level and also via the DoS profile for a VS/PO. This is my recommended approach. Keep the DoS config in one place and therefore disable the second option (via traditional TMOS configuration). This can be done under System/Configuration: Local Traffic: General, by setting the “Default Per Virtual Server SYN Check Threshold” and “Global SYN Check Threshold” to “0”. Also, disable “Hardware VLAN SYN Cookie Protection”. Figure 4: LTM SYN-Cookie configuration Now it’s all controlled by the “tcp-half-open” vector, which makes it less confusing. Please also keep in mind, SYN Cookie does only work in FPGA when “Auto Last Hop” is enabled! What do the stats of "tcp-half open" mean in the context of SYN-Cookie protection? When we take a look into the stats via the script I provided in my article “Demonstration of Device DoS and Per-Service DoS protection” during an SYN flood attack, we see a rate for int_drops. This only appears when the mitigation threshold (number of half-open connections) is reached. Figure 5: TCP Half Open vector shown in dos_stats output The “stats_rate” shows the number of half-open connections in the last second and the “drop_rate” or “int_drop_rate” = (the number of cookies sent) – (number of valid ACKs received). SYN-ACK flood Let’s talk about another attack vector: SYN-ACK flood. Again, this attack can be done in different ways. The attackers simply send a high rate of randomized SYN-ACK packets towards the victim. Or it is a result of an SYN flood with responding SYN-ACK packets towards a spoofed source IP of the SYN packet. Anyhow, every high packet rate can cause massive damage to the performance of Firewalls, Servers, or other devices and this is what DoS attackers usually try to archive with this type of attack. And again, the question is: how to differentiate between “good” and “bad” SYN/ACK packets? Asking the connection table would increase the CPU and is therefore not the best choice. So, ideally, it is done upfront (CPU) within the hardware chip (FPGA) to be high performant. SYN-ACK flood mitigation By enabling “Only Count Suspicious Events” on the “TCP SYN ACK Flood” vector on the Device level you do enable a cookie mechanism that allows the BIG-IP to differentiate if an SYN-ACK packet belongs to an SYN which has passed the BIG-IP before. Figure 6: TCP SYN ACK Flood vector configuration This mechanism is processed within the FPGA and does therefore not consume CPU. This enables the BIG-IP to be extremely resistant against this type of flood. Please keep in mind, this cookie function was added to the product with version 15.1. Before 15.1, you could also enable “Only Count Suspicious Events”, but it puts the vector into software mode. That means it can differentiate between “good” and “bad” SYN-ACK packets, but the mitigation is done within the CPU. How does SYN-ACK cookie mitigation work When the mechanism is enabled and an SYN packet received on a BIG-IP and is being forwarded, then the initial SNI gets replaced by an own SNI which includes properties of the originating TCP SYN in an encrypted format. When BIG-IP now receives SYN-ACK packets, it expects the initial SNI (cookie) with the ACK field to be incremented by 1. BIG-IP can now decrement and decrypt that value to check if the “cookie properties” fit the properties of the initial SYN packet. If that is the case, then the "ack" field gets replaced with the incremented SNI of the initial SYN packet and it will then be returned to the original client. If the cookie check fails, then it will be counted as a bad SYN-ACK and when the mitigation threshold on the vector is reached the rate-limiting for bad SYN-ACK packets gets activates in the hardware (FPGA). Figure 7: TCP SYN ACK cookie mitigation ACK flood and mitigation Let’s get to a third attack vector: ACK flood. This one is also widely used by attackers and can be very damaging. We already know it’s about the differentiation between valid and bad ACK packets plus being able to use the hardware (FPGA) for mitigation. Here again, the overall idea is to encrypt connection properties within a cookie and store them in the TCP packet. Valid response packets do have this cookie included and can be validated. When the number of invalid ACK packets reaches the mitigation threshold, then the rate-limiting will start. This cookie protection mechanism can be enabled per VLAN on the “bad_ack” vector on the Device configuration. Figure 8: TCP BADACK flood vector (cookie) configuration Simply move the VLANs you want to have this feature being enabled to the “Selected” area. Conclusion TCP floods can be easily used to bring down even strong firewalls, servers, or other security devices. Generally, it is not the volume, in terms of bandwidth, that is at issue here. It is the high packet rate, which in particular puts stateful devices under pressure if they don´t have dedicated hardware (FPGA) supported defense mechanism. With the cookie-based detection and mitigation defense technic, F5 delivers another strong layer within the layered network DDoS architecture. Even the whole cookie process is done within FPGAs, these chips can differentiate between valid and bad TCP packets without checking the connection state table. SYN-ACK and ACK cookies, which got introduced into the product with version 15.1, are being processed even before the Behavioral DDoS layer. SYN cookies are done after the static vectors. One of my next articles will provide an overview of best practices and an explanation on how to integrate DHD (DDoS Hybrid Defender) or AFM (Advanced Firewall Manager) into the Network for DDoS protection. But, next, I will explain the latest part of the Network protection layers, which is the first layer from the data path order: IP-Intelligence/ IP shunning and also RTBH (Remote triggered Black Hole Routing) and Flowspec. I hope this article was useful to you and keep in touch! Thank you, Sven Mueller4.2KViews6likes1Comment
Protect your applications using F5’s Distributed Cloud and Fast ACL’s
Introduction In this article I will show you how to easily create Fast ACL’s to protect your applications from DDoS attacks. Layer 3-4 DDoS Mitigation is included with the F5 Distributed Cloud service. When planning your DDoS strategy, you must plan at many layers. This means organizations need multiple tools and capabilities to protect themselves and keep their infrastructure and applications running. This layered approach uses network firewalls for Layer 3-4 DDoS protection, Web Application Firewalls (WAF) for Layer 7 protections, and as I’ll cover here Access Control Lists (ACLs) or as we call them Fast ACLs that can include rate-limiting. These ACL rules are applied at very early stages in datapath ingress processing and form a first line of defense against attack. Typical Use case(s) are: Rate-limiting traffic to destination Accepting traffic from certain source IPs to destination Rate-limiting or dropping traffic from source IPs to destination These rules are evaluated for each packet coming into the system (ingress), unlike session-based ACL’s where action is calculated only on first packet in the session. It is specified in terms of five tuple of the packet {destination ip, destination port, source ip, source port, protocol}. This gives you the ability to fine tune your DDoS strategy based on your network infrastructure and application performance. Getting Started Log in to your F5 Distributed Cloud Service. Select the Cloud and Edge Sites Tile. Navigate to Manage >> Firewall >> Fast ACL’s. We will also be discussing and using Policers and Protocol Policers. They can be added from this screen or as we build out our DDoS protection. We will show how during the build out. Click Add Fast ACL Give your Fast ACL a Name, add a Label and Description to help identify later. Next is what sets F5 XC Services apart. Under Fast ACL Type you have 2 options. This can be at the F5 XC Services regional edge (RE) or your own customer edge (CE) for apps deployed locally with F5 Distributed Cloud Service nodes. For this article I will cover the Customer Edge (CE). Select Configure. Here you have the option to select which network to apply this to at the CE, Inside or Outside, I will use the Outside Network. Next select the Destination IP, where you have three options to protect. I will use All Interface IP(s) as VIP. Finally, under Source, we will configure the Rules we wish to apply. Click Configure Under the Rules Section. Click Add Item Give your Rule a Name and a Description. Under Action you have 3 options, Simple Action, Policer Action and Protocol Policer Action. First, we will cover the Simple Action. You have two options, allow or deny. Under Source Port, click Add Item. You have the option to select All Ports, A User Defined Port or DNS. I will select User defined and add the value of 443. Under Source I'll allow all from 0.0.0.0./0 and click Add Item. Now you can go back in Rules and any additional rules that reflect your architecture. Click Add Item. This time I'll select Deny as the Action and ALL as Source Ports and Source Prefix as 0.0.0.0/0 When complete click Apply, this takes you back a Screen, Click Apply again. Protocol Policer Finally, we will configure a FAST ACL Protocol Policer. Give your Protocol Policer a Name, Labels and Description. Select a pre-configured Protocol Policer if one is already configured or you have system wide one you wish to apply. For this demonstration we will click Create new Protocol Policer. Click Add Item This will give you the option of Packet Type. The options are TCP, ICMP, UDP and DNS. For this we will select TCP. Then you select the appropriate TCP Flags, we will select SYN. Policer Dropping to the Policer section, we either need to select a preconfigured policer that might be used system wide or Create a new one. We will select Create New Policer. Creating a Policer is straightforward. Give it a Name, Labels and Description. Select If the Policer is to be Shared or Not Shared System wide. Here is where creating Fast ACLs helps you fine tune your DDoS protection for your application. You will enter both a Committed Information Rate in pps and a Burst Size in pps. Click Continue Add item and then Continue. Finally Save and Exit. These are all the steps necessary to get started using Fast ACL's. Two additional steps are needed and beyond the scope of this article. Most builds will already have the necessary configurations required. You need to have a Network Firewall designated and what F5 Distributed Cloud calls a Fleet. The Firewall will reference the ACL and the Firewall and Fleet Tag will be asisgned to your Customer Edge (CE). Conclusion In this article you learned how to configure Fast ACLs DDoS protection quickly and easily with the F5's Distributed Cloud. We included Rate Limiting as a viable option to tune your DDoS settings. In a few short minutes you would be able to react to an attack on your network by going into the F5 Distributed Cloud Console and adjusting or adding DDoS protections. "Nature is a mutable cloud, which is always and never the same." - Ralph Waldo Emerson We might not wax that philosophically around here, but our heads are in the cloud nonetheless! Join the F5 Distributed Cloud user group today and learn more with your peers and other F5 experts. For further information or to get started: F5 Distributed Cloud WAAP YouTube series (Link) F5 Distributed Cloud WAAP Services (Link) F5 Distributed Cloud WAAP Get Started (Link)3.5KViews3likes0CommentsDemonstration of Device DoS and Per-Service DoS protection
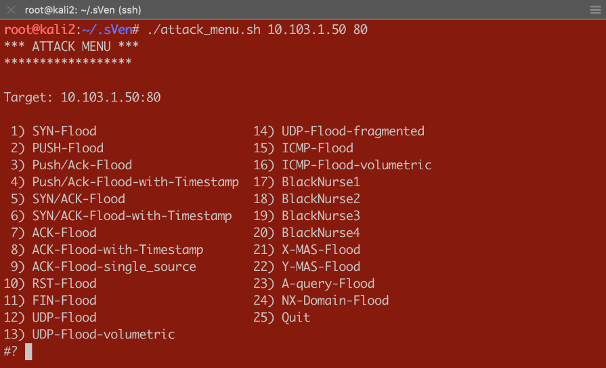
Dear Reader, This article is intended to show what effect the different threshold modes have on the Device and Per-Service (VS/PO) context. I will be using practical examples to demonstrate those effects. You will get to review a couple of scripts which will help you to do DoS flood tests and “visualizing” results on the CLI. In my first article (https://devcentral.f5.com/s/articles/Concept-of-F5-Device-DoS-and-DoS-profiles), I talked about the concept of F5 Device DoS and Per-Service DoS protection (DoS profiles). I also covered the physical and logical data path, which explains the order of Device DoS and Per-Service DoS using the DoS profiles. In the second article (https://devcentral.f5.com/s/articles/Explanation-of-F5-DDoS-threshold-modes), I explained how the different threshold modes are working. In this third article, I would like to show you what it means when the different modes work together. But, before I start doing some tests to show the behavior, I would like to give you a quick introduction into the toolset I´m using for these tests. Toolset First of all, how to do some floods? Different tools that can be found on the Internet are available for use. Whatever tools you might prefer, just download the tool and run it against your Device Under Test (DUT). If you would like to use my script you can get it from GitHub: https://github.com/sv3n-mu3ll3r/DDoS-Scripts With this script - it uses hping - you can run different type of attacks. Simply start it with: $ ./attack_menu.sh <IP> <PORT> A menu of different attacks will be presented which you can launch against the used IP and port as a parameter. Figure 1:Attack Menu To see what L3/4 DoS events are currently ongoing on your BIG-IP, simply go to the DoS Overview page. Figure 2:DoS Overview page I personally prefer to use the CLI to get the details I´m interested in. This way I don´t need to switch between CLI to launch my attacks and GUI to see the results. For that reason, I created a script which shows me what I am most interested in. Figure 3:DoS stats via CLI You can download that script here: https://github.com/sv3n-mu3ll3r/F5_show_DoS_stats_scripts Simply run it with the “watch” command and the parameter “-c” to get a colored output (-c is only available starting with TMOS version 14.0): What is this script showing you? context_name: This is the context, either PO/VS or the Device in which the vector is running vector_name: This is the name of the DoS vector attack_detected:When it shows “1”, then an attack has been detected, which means the ‘stats_rate’ is above the ‘detection-rate'. stats_rate: Shows you the current incoming pps rate for that vector in this context drops_rate: Shows you the number dropped pps rate in software (not FPGA) for that vector in this context int_drops_rate: Shows you the number dropped pps rate in hardware (FPGA) for that vector in this context ba_stats_rate: Shows you the pps rate for bad actors ba_drops_rate: Shows you the pps rate of dropped ‘bad actors’ in HW and SW bd_stats_rate:Shows you the pps rate for attacked destination bd_drop_rate: Shows you the pps rate for dropped ‘attacked destination’ mitigation_curr: Shows the current mitigation rate (per tmm) for that vector in that context detection: Shows you the current detection rate (per tmm) for that vector in that context wl_count: Shows you the number of whitelist hits for that vector in that context hw_offload: When it shows ‘1’ it means that FPGAs are involved in the mitigation int_dropped_bytes_rate: Gives you the rate of in HW dropped bytes for that vector in that context dropped_bytes_rate: Gives you the rate of in SW dropped bytes for that vector in that context When a line is displayed in green, it means packets hitting that vector. However, no anomaly is detected or anything is mitigated (dropped) via DoS. If a line turns yellow, then an attack - anomaly – has been detected but no packets are dropped via DoS functionalities. When the color turns red, then the system is actually mitigating and dropping packets via DoS functionalities on that vector in that context. Start Testing Before we start doing some tests, let me provide you with a quick overview of my own lab setup. I´m using a DHD (DDoS Hybrid Defender) running on a i5800 box with TMOS version 15.1 My traffic generator sends around 5-6 Gbps legitimate (HTTP and DNS) traffic through the box which is connected in L2 mode (v-wire) to my network. On the “client” side, where my clean traffic generator is located, my attacking clients are located as well by use of my DoS script. On the “server” side, I run a web service and DNS service, which I´m going to attack. Ok, now let’s do some test so see the behavior of the box and double check that we really understand the DDoS mitigation concept of BIG-IP. Y-MAS flood against a protected server Let’s start with a simple Y-MAS (all TCP flags cleared) flood. You can only configure this vector on the device context and only in manual mode. Which is ok, because this TCP packet is not valid and would get drop by the operating system (TMOS) anyway. But, because I want this type of packet get dropped in hardware (FPGA) very early, when they hit the box, mostly without touching the CPU, I set the thresholds to ‘10’ on the Mitigation Threshold EPS and to ‘10’ on Detection Threshold EPS. That means as soon as a TMM sees more then 10 pps for that vector it will give me a log message and also rate-limit this type of packets per TMM to 10 packets per second. That means that everything below that threshold will get to the operating system (TMOS) and get dropped there. Figure 4:Bad TCP Flags vector As soon as I start the attack, which targets the web service (10.103.1.50, port 80) behind the DHD with randomized source IPs. $ /usr/sbin/hping3 --ymas -p 80 10.103.1.50 --flood --rand-source I do get a log messages in /var/log/ltm: Feb5 10:57:52 lon-i5800-1 err tmm3[15367]: 01010252:3: A Enforced Device DOS attack start was detected for vector Bad TCP flags (all cleared), Attack ID 546994598. And, my script shows me the details on that attack in real time (the line is in ‘red’, indicating we are mitigating): Currently 437569 pps are hitting the device. 382 pps are blocked by DDoS in SW (CPU) and 437187 are blocked in HW (FPGA). Figure 5:Mitigating Y-Flood Great, that was easy. :-) Now, let’s do another TCP flood against my web server. RST-flood against a protected server with Fully manual Threshold mode: For this test I´m using the “Fully Manual” mode, which configures the thresholds for the whole service we are protecting with the DoS profile, which is attached to my VS/PO. Figure 6:RST flood with manual configuration My Detection Threshold and my Mitigation Threshold EPS is set to ‘100’. That means as soon as we see more then 100 RST packets hitting the configured VS/PO on my BIG-IP for this web server, the system will start to rate-limit and send a log message. Figure 7:Mitigating RST flood on PO level Perfect. We see the vector in the context of my web server (/Common/PO_10.103.1.50_HTTP) is blocking (rate-limiting) as expected from the configuration. Please ignore the 'IP bad src' which is in detected mode. This is because 'hping' creates randomized IPs and not all of them are valid. RST-flood against a protected server with Fully Automatic Threshold mode: In this test I set the Threshold Mode for the RST vector on the DoS profile which is attached to my web server to ‘Fully Automatic’ and this is what you would most likely do in the real world as well. Figure 8:RST vector configuration with Fully Automatic But, what does this mean for the test now? I run the same flood against the same destination and my script shows me the anomaly on the VS/PO (and on the device context), but it does not mitigate! Why would this happen? Figure 9:RST flood with Fully Automatic configuration When we take a closer look at the screenshot we see that the ‘stats_rate’ shows 730969 pps. The detection rate shows 25. From where is this 25 coming? As we know, when ‘Fully Automatic’ is enabled then the system learns from history. In this case, the history was even lower than 25, but because I set the floor value to 100, the detection rate per TMM is 25 (floor_value / number of TMMs), which in my case is 100/4 = 25 So, we need to recognize, that the ‘stats_rate’ value represents all packets for that vector in that context and the detection value is showing the per TMM value. This value explains us why the system has detected an attack, but why is it not dropping via DoS functionalities? To understand this, we need to remember that the mitigation in ‘Fully Automatic’ mode will ONLY kick in if the incoming rate for that vector is above the detection rate (condition is here now true) AND the stress on the service is too high. But, because BIG-IP is configures as a stateful device, this randomized RST packets will never reach the web service, because they get all dropped latest by the state engine of the BIG-IP. Therefor the service will never have stress caused by this flood.This is one of the nice benefits of having a stateful DoS device. So, the vector on the web server context will not mitigate here, because the web server will not be stressed by this type of TCP attack. This does also explains the Server Stress visualization in the GUI, which didn´t change before and during the attack. Figure 10:DoS Overview in the GUI But, what happens if the attack gets stronger and stronger or the BIG-IP is too busy dealing with all this RST packets? This is when the Device DOS kicks in but only if you have configured it in ‘Fully Automatic’ mode as well. As soon as the BIG-IP receives more RST packets then usually (detection rate) AND the stress (CPU load) on the BIG-IP gets too high, it starts to mitigate on the device context. This is what you can see here: Figure 11:'massive' RST flood with Fully Automatic configuration The flood still goes against the same web server, but the mitigation is done on the device context, because the CPU utilization on the BIG-IP is too high. In the screenshot below you can see that the value for the mitigation (mitigation_curr) is set to 5000 on the device context, which is the same as the detection value. This value resultsfrom the 'floor' value as well. It is the smallest possible value, because the detection and mitigation rate will never be below the 'floor' value. The mitigation rate is calculated dynamically based on the stress of the BIG-IP. In this test I artificially increased the stress on the BIG-IP and therefor the mitigation rate was calculated to the lowest possible number, which is the same as the detection rate. I will provide an explanation of how I did that later. Figure 13:Device context configuration for RST Flood Because this is the device config, the value you enter in the GUI is per TMM and this is reflected on the script output as well. What does this mean for the false-positive rate? First of all, all RST packets not belonging to an existing flow will kicked out by the state engine. At this point we don´t have any false positives. If the attack increases and the CPU can´t handle the number of packets anymore, then the DOS protection on the device context kicks in. With the configuration we have done so far, it will do the rate-limiting on all RST packets hitting the BIG-IP. There is no differentiation anymore between good and bad RST, or if the RST has the destination of server 1 or server 2, and so on. This means that at this point we can face false positives with this configuration. Is this bad? Well, false-positives are always bad, but at this point you can say it´s better to have few false-positives then a service going down or, even more critical, when your DoS device goes down. What can you do to only have false positives on the destination which is under attack? You probably have recognized that you can also enable “Attacked Destination Detection” on the DoS vector, which makes sense on the device context and on a DoS profile which is used on protected object (VS), that covers a whole network. Figure 14:Device context configuration for RST Flood with 'Attacked Destination Detection' enabled If the attack now hits one or multiple IPs in that network, BIG-IP will identify them and will do the rate-limiting only on the destination(s) under attack. Which still means that you could face false positives, but they will be at least only on the IPs under attack. This is what we see here: Figure 15:Device context mitigation on attacked destination(s) The majority of the RST packet drops are done on the “bad destination” (bd_drops_rate), which is the IP under attack. The other option you can also set is “Bad Actor Detection”. When this is enabled the system identifies the source(s) which causes the load and will do the rate limiting for that IP address(es). This usually works very well for amplification attacks, where the attack packets coming from ‘specific’ hosts and are not randomized sources. Figure 16:Device context mitigation on attacked destination(s) and bad actor(s) Here you can see the majority of the mitigation is done on ‘bad actors’. This reduces the chance of false positives massively. Figure 17:Device context configuration for RST Flood with 'Attacked Destination Detection' and 'Bad Actor Detection' enabled You also have multiple additional options to deal with ‘attacked destination’ and ‘bad actors’, but this is something I will cover in another article. Artificial increase BIG-IPs CPU load Before I finish this article, I would like to give you an idea on how you could increase the CPU load of the BIG-IP for your own testing. Because, as we know, with “Fully Automatic” on the device context, the mitigation kicks only in if the packet rate is above the detection rate AND the CPU utilization on the BIG-IP is “too” high. This is sometimes difficult to archive in a lab because you may not be able to send enough packets to stress the CPUs of a HW BIG-IP. In this use-case I use a simple iRule, which I attach to the VS/PO that is under attack. Figure 18:Stress iRule When I start my attack, I send the traffic with a specific TTL for identification. This TTL is configured in my iRule in order to get a CPU intensive string compare function to work on every attack packet. Here is an example for 'hping': $ /usr/sbin/hping3 --rst -p 80 10.103.1.50 --ttl 5 --flood --rand-source This can easily drive the CPU very high and the DDoS rate-limiting kicks in very aggressive. Summary I hope that this article provides you with an even better understanding on what effect the different threshold modes have on the attack mitigation. Of course, keep in mind this are just the ‘static DoS’ vectors. In later articles I will explain also the 'Behavioral DoS' and the Cookie based mitigation, which helps to massively reduce the chance of a false positives. But, also keep in mind, the DoS vectors start to act in microseconds and are very effective for protecting. Thank you, sVen Mueller3.3KViews11likes3CommentsIP-Intelligence and IP-Shunning
Dear Reader, With this article we have arrived at the “last” layer of protection, which is actually the first one from the hud-chain point of view: Blocking on the IP layer. The idea is rather simple: When you know that an IP address (or multiple IP addresses) is doing bad things, you block them as early as possible at the speed of line. IP-Intelligence Policy You can create IP-Intelligence (IPI) policies, which describe what should happen (Drop or Allow) with IPs (source or destination) belonging to a specific category. BIG-IP already has a bunch of pre-defined categories, but you can also add your own. Figure 1: Example on an IPI-Policy Important: A great benefit of using this, is that the “Drop” action is done on the FPGA level, which means in hardware. Basically, as soon as a packet hits the BIG-IP. But this is only possible when you set the logging to “No” (no logging, only dropping) or “Limited”. “Limited” means that some packets get leaked into software (CPU) for dropping them there and then they can be logged here as well. By default, every 256th packet goes into software when logging is set to “limited”. This is controlled by the sys db variable “dos.blleaklimit”. You can modify it to values like 1, 3, 7, 15, 31, 63, 127, 255, 511, 1023, and so on. The default value is 255. When you set the logging to “Yes”, then all packets will get logged, because the action (Drop) is done always in software. My recommendation is to use “Limited” logging to enable FPGA support for this feature. This is also what we call “shunning” when we drop on FPGA level. You can create multiple policies and assign them to different contexts: VS/PO or Route Domains to have individual configurations for your protected objects (services, networks, etc.) and you can also assign an IPI policy to the global level of BIG-IP, which means this will be executed first and for the whole box. Even when you want to block via IPI only on VS/PO level, my recommendation is to have a global IPI policy attached. It can be empty. Figure 2: Global Policy assignment Figure 3: Per VS/PO Policy assignment Figure 4: Per Route Domain Policy assignment Order of Mitigation Mitigation using the hardware (FPGA) is always done first. Next, traffic goes into software and can be dropped here as well. For IPI the following order takes place. Note that IPI mitigation done on Route Domain level is always in software. Figure 5: Mitigation Order How to get information about “bad” IPs? There are multiple options available. One is to use an external service (3 rd party), which does the categorization of IPs based on their reputation. If you have the IP Intelligence feature licensed, the information is being updated every 5 minutes. Another one is to use BIG-IP to automatically identify “bad actors” via DoS vectors. In my article Increasing accuracy using Bad Actor and Attacked Destination detection, I described how that works and for what it is useful for. But when BIG-IP identifies “bad actors” and this source IP(s) are behaving aggressive for a configurable amount of time, then it may make sense to drop everything coming from this IP(s) for a specific time interval. Figure 6: Bad Actor Detection In this example, the IP(s) which are identified as bad actors and behaving “bad” for 30 seconds get added to the category “denial_of_service” for 600 seconds. Once the “duration time” is over, they get released from the category and the process starts from the beginning, if they are still “bad”. Drop Attacked Destination Another use case to carefully consider is to drop based on attacked destination. Here you can drop all traffic going to a specific destination which is under attack. True, you stop the attack hitting the target, but you also drop all legitimate traffic going there, which would be a great success for the attacker. But, of course, if for whatever reason the attack would potential bring the BIG-IP to its knees this is an option you can choose. You would loose the destination that is under brutal attack but at least you safe all other services on the BIG-IP from being impacted. Figure 7: Attacked Destination Detection Use your up-stream router Think of the following scenario: An attack is about to saturate your Internet-pipe. You mitigate the bad actors on BIG-IP, but your pipe is still full. Why not “signal” the information of bad actors to your upstream router and drop the attackers already there, even before your pipe gets saturated? This is what you can do with using Remote Triggered Black Hole routing (RTBH) or Flowspec. By enabling “Allow External Advertisement” within your “Bad Actor Detection” or “Attacked Destination Detection” you can enable that functionality. Figure 8: External Advertisement I will cover the topic on how to use the Blacklist Publisher to “signal” bad actors including an action (Drop, Rate-limit, DSCP) to an upstream router via RTBH or Flowspec in a dedicated article. I will also explain in the same article how to use the “Scrubbing profile” to execute an action (redirect, rate-limit, DSCP, drop) on networks, PO/VS when these objects reach a certain bandwidth utilization. More options to add bad actors into categories Returning to how you can add IP(s) into categories. In addition to the already discussed options of using F5 subscription service and DoS vectors you can also add manually IPs. You may have your own sources and want to add this information into the categories. Here you have multiple options again. GUI On the Blacklist Categories page, you can manually add/delete IPs for a selected category. Figure 9: Add IP/Geo/FQDN to categories Feed List You can create your own Feed List using HTTP(s) or FTP to regularly download a file and update your categories. Figure 10: External Feed List Don´t forget to then enable your Feed List within your IPI-Policy! Figure 11: Enable Feed Lists TMSH Using tmsh you can also add IPs to categories. Here is an example: $ tmsh run security ip-intelligence category name denial_of_service ip-ttl add { 123.123.123.123,300 } Rest-API Another way is to use Rest-API. Here is an example: $ curl -sk -u sVen:mySecrectPW -H "Content-Type: application/json" -X POST -d '{"command":"run","utilCmdArgs":"name denial_of_service ip-ttl add {123.123.123.123,300}"}' https://mgmnt-address-big-ip/mgmt/tm/security/ip-intelligence/category/ | python -m json.tool Whitelist IPs for IPI/shunning If you want to whitelist IP(s) from not being shunned on IPI level, you need to add this IP(s) to the “whitelist” category. Please we aware that this only works when you use an external feed to add the IP(s). Figure 12: Feed List Properties More useful CLI commands To get an idea on hits per category, you can use a “tmctl” command: # tmctl -w 180 ip_intelligence_stat It gives you an overview of hits per context, category and drop list type. Figure 13: Stats for categories Here you can also see that you can not only drop based on IP. You can also use GEO information and FQDN. If you want to verify the status of an IP, you can use this command: # tmsh show security ip-intelligence info address <ip-address> Figure 13: Example of status of a GEOIP Conclusion IPI/shunning is a very effective and hardware driven way of blocking traffic based on IP information. Especially on amplification and reflection attacks it is a very useful because you are mostly able to identify IP addresses causing the high load. Often operators do also block traffic from countries on which they are sure they do not communicate with for specific services. After finishing the explanation of this last (first) mitigation layer, you hopefully have a better understanding on how F5 L3/4/DNS DDoS mitigation works. Hardware (FPGA) support is an essential element of successful blocking high packet rates. These high-performance chips get dynamically programmed via the “smart” component, the software which runs on CPU, and which also needs to be protected. Therefore, you can configure the DoS mitigation mechanism for protecting your services (server, network, …) behind the BIG-IP, but also BIG-IP itself! Figure 14: Multi-layer DDoS mitigation architecture F5 also provides the ability to protect with hardware (FPGA) support in virtualized environments. Since more and more data center go virtual, the requirement of running DDoS mitigation in virtualized environments has increased. But, because FPGA support is needed for this type of DDoS mitigation, since CPU alone is usually not powerful enough, it can present a problem. Together with Intel F5 provides a strong solution. This solution uses SmartNICs (network card with FPGA on board) within your Hypervisor. DHD (DDoS Hybrid Defender) and AFM (Advanced Firewall Manager) can program these FPGAs in basically the same way as it can be done on dedicated Hardware appliances. This again gives you the power needed for DDoS mitigation, plus the flexibility of virtualized environments. If you are interested in learning more about this, I would like to recommend the article of my colleague Ryan Howard: https://devcentral.f5.com/s/articles/Mitigating-40Gbps-DDoS-Attacks-with-the-new-BIG-IP-VE-for-SmartNICs-Solution My next article will focus on logging and reporting DDoS events. Together, my colleague Mohamed Shaath and I created a DDoS Dashboard including DDoS statistics visibility on all vectors based on an ELK stack. We will share in that article how to install and use it. Thank you, Sven Mueller3.2KViews6likes4CommentsL3/4/DNS DDoS Reporting with Elastic Search and Kibana
Dear Reader, In this article, I would like to, in collaboration with my colleague Mohamed Shaath, show you how to use DDoS reporting and visibility dashboards that we have created based on an ELK (Elastic Search Logstash and Kibana) stack. The goal is to give you templates based on Open-Source software to address typical questions DDoS operators have and need to answer when an incident happens. Another component we added is the visualization of incoming packets, dropped packets, detection, and mitigation thresholds per attack vector. The idea here is to give you insights into auto-calculated thresholds compared to incoming rates. It will also give you the possibility to see anomalies in traffic behavior. Hopefully, the visualization will also help you with fine-tuning the DoS vector configuration (a typical example of this is the floor value of a vector). This article will give you an introduction to some of the graphs we provide together with the templates. Feel free to arrange or modify them in the way you need when you use the solution. We are also very happy to get your feedback, so we can optimize the dashboards and graphs in a way that is most useful for DDoS operators. Fundamental understanding of log events All DDoS configuration relay basically on two thresholds, regardless of the chosen threshold (manual, fully automatic, multiplier, …): Detection and Mitigation Figure 1: Detection and Mitigation rate “Detection” means, inform the DDoS operator that the incoming rate is above the configured (or auto-calculated rate based on the history) rate. Do not block traffic, just send out specific log information. The “detection” value is usually set or calculated to a rate that is just within the expected “normal” rate. That also means, everything above that value is not “normal” and therefore suspicious, but not necessarily an attack. But the DDoS operator should be aware of that event. Exactly this is happening when a packet rate crosses the detection rate: BIG-IP will send out log messages to the log server (when configured). Within the ELK solution we are introducing, we use the “Splunk” logging format, which sends the information in key/value format. That makes the understanding of the fields much easier. Here is an example of a log message, which is sent out when the packet rate has crossed the detection threshold. Jun 17 23:08:46 172.30.107.11 action="Allow",hostname="lon-i5800-1.pme.itc.f5net.com",bigip_mgmt_ip="172.30.107.11",context_name="/Common/www_10_103_2_80_80",date_time="Jun 17 2021 22:58:12",dest_ip="10.103.2.80",dest_port="80",device_product="DDoS Hybrid Defender",device_vendor="F5",device_version="15.1.2.1.0.317.10",dos_attack_event="Attack Sampled",dos_attack_id="550542726",dos_attack_name="TCP Push Flood",dos_packets_dropped="0",dos_packets_received="117",errdefs_msgno="23003138",errdefs_msg_name="Network DoS Event",flow_id="0000000000000000",severity="4",dos_mode="Enforced",dos_src="Volumetric, Per-SrcIP, VS-specific attack, metric:PPS",partition_name="Common",route_domain="0",source_ip="10.103.6.10",source_port="39219",vlan="/Common/vlan3006_client" Explanation of the message content: Action = “Allow” indicates that BIG-IP is not dropping packets (from the DoS point of view), it’s just giving the operator the information that within the last second the protected context (here: /Common/www_10_103_80_80) has received 117 (dos_packets_received) push packets (dos_attack_name) from source IP 10.103.6.10 (source_ip) within the last second. Btw., because this is a “Volumetric, Per-SrcIP, VS-specific attack” (dos_src) log message, it also tells you that the source IP has been identified as a bad actor (Also see my article: Increasing accuracy using Bad Actor and Attacked Destination). Therefore, this event was triggered by the Bad Actor configuration of the TCP Push flood vector. Mitigation threshold Once the incoming packet rate has crossed the mitigation threshold of a DoS vector or an attack signature, then BIG-IP starts to drop (rate-limit) traffic above that value. This is when we declare being under an DDoS attack because the protected context (server, service, network, BIG-IP, etc.) will be negatively affected by this high number of packets per second. Now the BIG-IP DoS device (AFM/DHD) needs to lower the number of packets hitting the affected context and that’s why it starts to drop packets on the identified vector. Again, this mitigation threshold can be set manually or auto-calculated based on history or a multiplication of the detection threshold. (Explanation of the F5 DDoS threshold modes) Here is an example of a drop log message: Jun 17 23:05:03 172.30.107.11 action="Drop",hostname="lon-i5800-1.pme.itc.f5net.com",bigip_mgmt_ip="172.30.107.11",context_name="Device",date_time="Jun 17 2021 22:54:29",dest_ip="10.103.2.80",dest_port="0",device_product="DDoS Hybrid Defender",device_vendor="F5",device_version="15.1.2.1.0.317.10",dos_attack_event="Attack Sampled",dos_attack_id="3221546531",dos_attack_name="Bad TCP flags (all cleared)",dos_packets_dropped="152224",dos_packets_received="152224",errdefs_msgno="23003138",errdefs_msg_name="Network DoS Event",flow_id="0000000000000000",severity="4",dos_mode="Enforced",dos_src="Volumetric, Aggregated across all SrcIP's, Device-Wide attack, metric:PPS",partition_name="Common",route_domain="0",source_ip="10.103.6.10",source_port="12826",vlan="/Common/vlan3006_client" In this example, the message is an aggregation of all source IPs (dos_src="Volumetric, Aggregated across all SrcIP's, Device-Wide attack) of the dropped packets (dos_packets_dropped="152224") during the last second. Therefore, the source IP (source_ip="10.103.6.10”) is just a representer for all source IPs with dropped packets within the last second. This is because there was no “bad actor” identified. This is usually the case, when the bad actor functionality is not configured, or when every packet has a different source IP. Structure of the dashboards These two main logging events (allow and drop) are what we have adapted to the visualization of the DDoS dashboard. The DDoS operator needs to know when there is an anomaly in the network and which vectors are triggered by the anomaly. The operator also needs to know what destinations are involved and which sources cause the anomaly. But, it is also important to know when the network is under attack and again what mitigation has taken place on which destinations and sources. How many packets have been dropped etc.? When you open the “DDoS Dashboard” and choose the “Overview Dashboard” you will notice that the dashboard is divided into two halves. On the left side, you get the information when a DDoS device has dropped packets and on the right side, you get the information about “suspicious” packets, which means when traffic was above a detection threshold without being dropped (action “Allow”). Figure 2: Structure of the dashboard Within this dashboard, you will also find graphs or tables which do not split the dashboard into two sides. Here you find combined information from both events/areas (mitigation and suspicious). Explanation of some dashboards In the menu section Home/Analytics/Dashboard you will find all dashboards we created. Figure 3: Dashboard menu Let’s briefly explain what the main Dashboards are for. Figure 4: Dashboard overview DDoS_Dashboard is the board where you can see all events during a chosen timeframe, which you can select in the upper right corner within that dashboard. Figure 5: Period of time selection On the top of the page, you find the Dashboard Explorer. From here you can easily navigate between all the relevant dashboards without going through the Analytics section of the main menu. Figure 6: Dashboard Explorer DDOS STATS Dashboard: shows details of the rates and thresholds (packet rate, detection, and mitigation threshold, drop rate) for all vectors including bad actor and attacked destination thresholds. Here you need to select the relevant vector, and context to see the details. DDOS Network Vectors: show details of the incoming rate and drop rate per network vector on a one-pager. DDOS DNS Vectors: show details of the incoming rate and drop rate per DNS vector on a one-pager. DDOS Bad Header Vectors: show details of the incoming rate and drop rate per bad header vector on one page. DDOS SIP vector: show details of the incoming rate and drop rate per SIP vector on a one pager. Please note that all “stats” dashboards are based on the “dos_stats” table, which you need to you to your server. It is not done via the DoS logs. On the GitHub page, you will find instructions on how to do it. Next, you see the Stats Control Panel Figure 7: Stats Control Panel By default, it will show the events (drop/allow) for all vectors in all contexts (VS/PO, Device) on all DoS devices. But by using the drop-down menu you can filter on specific data. All filters you set can also easily be saved and used again. Kibana gives a lot of flexibility. Next, you get to the Top Attacks Timeline, which shows you the top 10 attack vectors, which have dropped packets. Figure 8: Attack Timeline When you mouseover then you get the number of dropped packets for that vector. To the right of this graph, you see the Attack Event Details. Figure 9: Attack Event Details This simply shows you how many logs you have received per log event. Remember every mechanism (for example per source event, per destination, aggregated, …) has its own logs. The next row shows on the left side how many packets had been dropped during the chosen time frame. Figure 10: Dropped vs. suspicious packets On the right side you see how many packets had been identified as suspicious because the rate was above the detection threshold, but not above the mitigation threshold. This event message has the action “Allow”. In the middle graph, you see the relation of suspicious packets vs. dropped packets vs. incoming packets (incoming packets is the summarization of dropped and suspicious packets). The next graph gives you also an overview of received packets vs. dropped packets. Figure 11: Incoming vs. dropped packets But here the data comes from the dos_stats table, so again it is only visible when you send the information. Keep in mind this is not done via the log messages. This is the part where you send the output of the “tmctl -c dos_stat” command to your log device. If you are not doing it, then you can remove this graph from the dashboard. The main difference to the graph in the middle above is, that you will see data also when there is no event (allow/drop) because depending on the configured frequency you send the “dos_stat” table, you get the data (snapshot). Graphs based on log events of course can only appear when there is an event and logs are sent. This graph shows all incoming packets counted by all enabled vectors, regardless of they are counted on bad actors, attacked destinations, or the global stats per vector. Same for the dropped packets. It gives an overall overview of incoming packets vs. dropped packets. To get more details on which vector or mechanism (BA, AD) did the mitigation, you need to go to the DDOS STATS Dashboard. A piece of important information for a DDoS Operator is to know which services (IPs) are under attack and which contexts or protected objects have been involved. Figure 12: Target information Of course, also which vectors are used by the attacker. This is what is shown in the next row. On the left two graphs you get this information for dropped packets. On the right two graphs you see it for packets above the detection threshold but below the mitigation. Attacked IP and Destination Port, shows you the attacked IPs including the destination ports. Attacked Protected Objects, shows you the Context (VS/PO, Device, Global) in relation to the attack vectors. Context “Global” is used for IPI (IP-Intelligence). In this example packets got dropped because source IPs were configured within the IPI policy “my_IPI” and the category “denial of service”. The mitigation was executed on the global level. IPI activities are shown as attack vectors. Figure 13: IP-Intelligence information When you mouseover you can get the full line. More details on the attack vectors and IPI activity you will see lower on the page. Attacked destination details In the next row, you find a table with information on IP addresses that have been identified as being attacked by “Attacked Destination Detection” configured on a vector. Figure 14: Attacked Destination Details Figure 15: Vector configuration What are the sources of an attack? The next graph gives you the information of the identified attackers. “Top AttackerIPs” shows you the top 10 attacks based on aggregated logs. When you have configured “Bad Actor Detection” then you will also get the information for the top 10 “bad actors” IPs. Identified “bad actor” IPs are certainly important information you want to keep an eye on. Figure 16: Source address information Bad Actor Details To get more information on “bad actors”, you can use the “Bad Actor Details” table, which will show you relevant information. Here is an example: Figure 17: Bad Actor details You can see that the UDF flood vector identified a flood for the bad actor IP “4.4.4.4” at 11:02 on the Device level. Most of the packets had been dropped (PPS vs. Dropped Packets). Within the next multiple 30 second intervals, you get again details for that bad actor IP. But at 11:06 you can see that the IP address got programmed into the “denial of service” category and after that, all traffic coming from that IP got dropped via the IP-Intelligence policy “my_IPI” on the “Global” level/context. BDoS Details The Dashboard will also give you information about BDoS signatures and their events. Figure 18: BDoS details In this example, you can see that the system generated (Signature Add) a BDoS signature at 11:23:30. Then this signature was used (Re-USED) for mitigation (Drop). Keep in mind you will only see the details of a signature when it gets created. If a signature is re-used and you want to see the details of the signatures which may have gotten created days or weeks before, then you need to filter for that signature within the timeframe it got created. Another view on attacked IPs The dashboards give you also another, comprehensive view on attacked and targeted (action allow) IP addresses. Here you probably best start to mouseover from the inner circle going outside and you will get information per attacked context. Figure 19: Combined view on sources, destination and vectors Details about DNS attacks Within the DNS section, you get details about DNS-related attacks. Figure 20: DNS attack overview per vector Figure 21: Detailed DNS attack overview Also, a different view on Bad Actor activities Figure 22: Bad Actor / attack vector / destination overview Since we hope the graphs are mostly self-explaining we don´t want to go through all of them. We also plan to add more or modify them based on your feedback. Now it’s time to talk about another component, which we already touched on multiple times within this article. Attack vector visualization A second component we have created is the visualization of the stats (incoming, detection, mitigation, etc.) per attack vector. This is an optional part and is not related to the DoS logging. It is based on the “dos_stat” table and gives a snapshot of the statistics based on the interval you have configured to send the data from BIG-IP into your ELK stack. In my article “Demonstration of Device DoS and Per-Service DoS protection,” I already introduced you to the “dos_stat” table, when I used it within my “show_DoS_stats_script”. Figure 23: DDoS stat table This script shows you the stats for all vectors and their threshold etc. By sending this data frequently into your ELK stack, you can visualize the data and get graphs for them. You then can easily see trends or anomalies within a defined time frame. You can also easily see what thresholds (detection/mitigation) the system has calculated. Figure 24: Activity (detection/mitigation)graph per vector In this example you can see, what the system has done during an attack. The green line shows the incoming packet rate for that vector. The yellow line shows the expected auto-calculated rate (detection rate). The blue line is the auto-calculated mitigation rate, which is at the beginning of this graph very high because the protected context has no stress. Then we can see that the packet rate increases massively and crossed the detection rate. This is when the DDoS operator needs to be informed because this rate is not “normal” (based on history) and therefore suspicious. This high packet rate has an impact on the stress of the protected context and the mitigation rate got adjusted below the incoming rate. At that point, the system started to defend and mitigate. But the incoming packet rate went down again for a short time. Here the mitigation stopped because the rate was below the mitigation threshold, which also got increased again because of no stress on the protected context anymore. Then the flood happened again. The mitigation threshold got adjusted, mitigation started. Later we can see the incoming rate sometimes climbed above the detection threshold but was not strong enough to affect the health of the protected context. Therefore, no mitigation took place. At around 11:53 we can see the flood increased again and enabled the mitigation. Please keep in mind that the granularity of this graph depends of course on the frequency you send the data into the ELK stack and the data is always a snapshot of the current stats. How to configure logging on BIG-IP tmsh create ltm pool pool_log_server members add { 1.1.1.1:5558 } tmsh create sys log-config destination remote-high-speed-log HSL_LOG_DEST { pool-name pool_log_server protocol udp } tmsh create sys log-config destination splunk SPLUNK_LOG_DEST forward-to HSL_LOG_DEST tmsh create sys log-config publisher KIBANA_LOG_PUBLISHER destinations add { SPLUNK_LOG_DEST } tmsh create security log profile LOG_PROFILE dos-network-publisher KIBANA_LOG_PUBLISHER protocol-dns-dos-publisher KIBANA_LOG_PUBLISHER protocol-sip-dos-publisher KIBANA_LOG_PUBLISHER ip-intelligence { log-translation-fields enabled log-publisher KIBANA_LOG_PUBLISHER } traffic-statistics { syncookies enabled log-publisher KIBANA_LOG_PUBLISHER } tmsh modify security log profile global-network dos-network-publisher KIBANA_LOG_PUBLISHER ip-intelligence { log-geo enabled log-rtbh enabled log-scrubber enabled log-shun enabled log-translation-fields enabled log-publisher KIBANA_LOG_PUBLISHER } protocol-dns-dos-publisher KIBANA_LOG_PUBLISHER protocol-sip-dos-publisher KIBANA_LOG_PUBLISHER traffic-statistics { log-publisher KIBANA_LOG_PUBLISHER syncookies enabled } tmsh modify security dos device-config dos-device-config log-publisher KIBANA_LOG_PUBLISHER Figure 25: Overview of logging configuration How to send the dos_stats table data modify (crontab -e) the crontab on BIG-IP and add: * * * * * nb_of_tmms=$(tmsh show sys tmm-info | grep Sys::TMM | wc -l);tmctl -c dos_stat -s context_name,vector_name,attack_detected,stats_rate,drops_rate,int_drops_rate,ba_stats_rate,ba_drops_rate,bd_stats_rate,bd_drops_rate,detection,mitigation_low,mitigation_high,detection_ba,mitigation_ba_low,mitigation_ba_high,detection_bd,mitigation_bd_low,mitigation_bd_high | grep -v "context_name" | sed '/^$/d' | sed "s/$/,$nb_of_tmms/g" | logger -n 1.1.1.1 --udp --port 5558 Modify IP and port appropriate. Better approach then using the crontab is to use an external monitor: https://support.f5.com/csp/article/K71282813 Anyhow, keep in mind more frequently logging generates more data on you logging device! Conclusion The DDoS dashboards based on an ELK stack give the DDoS operators visibility into their DDoS events. The dashboard consumes logs sent by BIG-IP based on L3/4/DNS DDoS events and visualizes them in graphs. These graphs provide relevant information on what kinds of attacks from which sources are going to which destinations. Based on your BIG-IP DoS config you get “bad actor” details or “attacked destinations” details listed. You will also see if IPs that have been blocked by certain IPI categories and more. In addition to other information shown, the ELK stack is also able to consume data from the dos_stats table, which gives you details about your network behaviors on a vector level. Further, you can see how “auto thresholds” calculate detection and mitigation thresholds. We hope that this article gives you an introduction to the DDoS ELK Dashboards. We also plan to publish another article on the explanation of the underlying architecture. Sven Mueller & Mohamed Shaat3.2KViews1like0Comments
F5 BIG-IP MQTT protocol support and use cases in an IoT environment
The Internet-of-Things is a system of physical devices, vehicles, buildings, and any other items each provided with a unique identifier allowing them to communicate with one another without any human intervention. MQTT is a widely-used machine-to-machine connectivity protocol that helps these devices communicate and exchange messages. The wide adoption and popularity of the MQTT protocol led to its support in the BIG-IP version 13.0. MQTT is a publish/subscribe messaging protocol. A device such as a camera, heat sensor, lP-enabled light bulb, etc. can publish data to an intermediary module using the MQTT protocol. An application can then subscribe to this intermediary module and retrieve the published data. Intermediary modules are also known as message brokers. The BIG-IP with MQTT awareness can sit in front of the MQTT message brokers to provide scalability, security, visibility, and availability. Fig. 1 – Basic architecture of using the BIG-IP platform in an IoT environment. In an MQTT configuration, clients publish messages and the BIG-IP system parses those MQTT messages based on which it invokes MQTT specific iRule events if defined and performs connection based load balancing on the MQTT messages to a pool of message brokers. The message brokers then transport and route the messages to subscribing servers A typical BIG-IP MQTT configuration includes: MQTT pool of message brokers Are grouped together to receive and process traffic. After the pool is created, associate the pool with a virtual server. Some common open source message brokers examples are Mosquitto and VerneMQ iRules for MQTT Use iRules to exercise MQTT functionality, for example to log the messages that the BIG-IP system passes, or to pass the client certificate's common name in the CONNECT message Client SSL profile Use a Client SSL profile when you want the BIG-IP ® system to authenticate and decrypt/encrypt client-side application traffic Virtual server configured to use MQTT functionality For more details please refer to: https://support.f5.com/kb/en-us/products/big-ip_ltm/manuals/product/ltm-iot-administration-13-0-0/1.html BIG-IP natively supports the MQTT protocol. BIG-IP has a full proxy architecture which makes BIG-IP itself an endpoint and an originator of the MQTT protocol. iRules take advantage of the deep understanding of the protocol and can be used at different events (specific moments within the session flow of a network connection, such as MQTT_CLIENT_INGRESS, MQTT_SERVER_INGRESS) to intelligently parse the MQTT protocol and make traffic decisions. Let’s explore some of the use cases using iRules such as load balancing and steering traffic based on a unique identified present within the MQTT protocol, preventing attacks based on TOPICS/LENGTH of a PUBLISH message, client authentication based on CN name present in the client certificate. Use Case: prevent MQTT DDoS attacks based on the below parameters Topic validation Validate the ‘TOPIC’ of a PUBLISH message and if it does not fit the validation criteria then drop the connection. This will prevent messages with bogus TOPICS from reaching the message brokers. And help in preventing MQTT DDoS attacks based on TOPIC. when MQTT_CLIENT_INGRESS { log local0. "CLIENT [MQTT::type]" if {[MQTT::type] eq "PUBLISH" } { # Check against a allowed topic. if { [MQTT::topic] eq "bogus/bogus" } { # Invalid topic log local0. " Topic is Invalid. Potential DDoS Attack -> Dropping Topic: [MQTT::topic]" drop } } } The above iRule can be enhanced to use data groups where the data groups will have the entire list of TOPICS and the [MQTT::TOPIC] can be checked against the data group MQTT PUBLISH message length validation An application will typically have knowledge about the size of the data that is being transmitted. Taking advantage of that knowledge the length of a PUBLISH message can be validated and if it does not satisfy the expected length then drop the connection. This will prevent large messages from reaching the message brokers and not overload the broker. when MQTT_CLIENT_INGRESS { log local0. "CLIENT [MQTT::type]" if {[MQTT::type] eq "PUBLISH" } { # Check length of message. if { [MQTT::length] > 100 } { # Invalid length log local0. " Length is Invalid. Potential DDoS Attack -> Dropping message: [MQTT::topic] : [MQTT::length]" drop } } } Use Case: pool selection/load balancing based on username as a unique identifier Use the username as a unique identifier to steer traffic to a message broker. This enables stickiness between an end user and a message broker by mapping a device/end user to a pool in the load balancer. The mapping helps in conditions where in a device needs to reconnect to the message broker on which the active client session lives and can use the state information present on the message broker to make decisions. when MQTT_CLIENT_INGRESS { log local0. "CLIENT [MQTT::type]" if {[MQTT::type] eq "CONNECT" } { # Select pool based on username, example license ID if { [MQTT::username] eq "D1111111" } { log local0. "Load balancing to pool MQTT-BrokerPool1" pool MQTT-BrokerPool1 } if { [MQTT::username] eq "D1111112" } { log local0. "Load balancing to pool MQTT-BrokerPool2" pool MQTT-BrokerPool2 } } } The above iRule can be enhanced to use data groups where the data groups will have the list of unique usernames. Multiple data groups can be defined, each one representing users for multiple Pools. The [MQTT::username] can be checked against the data group and based on that the pool selection can be made. Use Case: client certificate authentication over TLS BIG-IP can terminate MQTT encrypted SSL/TLS messages and then send the un-encrypted traffic to the backend Broker. This allows the Broker to scale as it can offload all SSL/TLS functions and configuration to the BIG-IP. In addition to terminating SSL/TLS the BIG-IP can use iRules to perform Client Certificate Authentication. The BIG-IP can embed the client CN name from the client certificate into the backend connection along with the username for authentication by the back-end Broker. when CLIENT_ACCEPTED { set cn "" } when CLIENTSSL_CLIENTCERT { log local0. " Parsing X509 Info for SSL Client Cert CN Name" set cn [findstr [X509::subject [SSL::cert 0]] "CN=" 3 ","] log local0. "Found Client Cert Common Name (CN) : $cn" } when MQTT_CLIENT_INGRESS { log local0. "MQTT Client MmessageTtype [MQTT::type]" if {[MQTT::type] == "CONNECT"} { log local0. "Connecting to Broker" if {$cn == ""} { # if we didn't see a client cert, return an authentication error MQTT::drop MQTT::respond type CONNACK return_code 5 MQTT::disconnect } else { log local0. "Passing Username and CN to Backend for Authentication" log local0. "MQTT Username: [MQTT::username]" log local0. "Username: [MQTT::username] CN: $cn" set mqttuser [MQTT::username] MQTT::username "$mqttuser $cn" } } } Conclusion Bookmark this page if you are interested in learning more. We will be update this blog with new compelling IoT features developed by F5 for the upcoming BIG-IP releases. Do you have a suggestion for an IoT related topic that you would like for us to cover? Please leave a comment on this post if you do. References https://support.f5.com/kb/en-us/products/big-ip_ltm/manuals/product/ltm-iot-administration-13-0-0/1.print.html https://devcentral.f5.com/s/articles/lightboard-lessons-iot-on-big-ip-24923?tag=lbl https://devcentral.f5.com/s/articles/the-iot-ready-platform https://f5.com/resources/white-papers/tmos-redefining-the-solution https://devcentral.f5.com/s/articles/the101-irules-101-events-amp-priorities https://en.wikipedia.org/wiki/MQTT https://mosquitto.org/3KViews0likes1Comment