Implementing HTTP Strict Transport Security in iRules
Last month I ran across a blog entry by Extreme Geekboy discussing a patch (now in the most recent nightly forthcoming 4.0 builds) for Firefox he submitted that implements the user agent components of HTTP Strict Transport Security. Strict Transport Security, or HSTS (or STS if that extra character is taxing to type) is an internet draft that allows site owners to specify https as the only acceptable means of accessing the site. This is accomplished by the site inserting a header that the browser will evaluate and for x number of seconds (specified in the header) will rewrite all requests, either from the user or returned in a link from the site to https. This first part is good, but is only half of the implementation. If you are under a man-in-the-middle attack, it matters not if your data is encrypted because the attacker has the keys and is quite happy to decrypt your session unbeknownst to you. This is where the second half of the draft comes in. It disallows the use of untrusted certificates (self-signed, untrusted-CA signed, etc). Any link to an untrusted destination should result in an error in the browser. The goals of the draft are to thwart passive and active network attackers as well as imperfect web developers. It does not address phishing or malware. For details on the threat vectors, read section 2.3 of the draft. Implementation of this draft is actually quite trivial. To get there, I’ll walk you configuring your own certificate authority for use in testing, a BIG-IP (Don’t have one? Get the VE trial!), and a server. All this testing for me is completely contained on my laptop, utilizing Joe’s excellent article on laptop load balancing configuration with LTM VE and VMware, though full-disclosure: I deployed Apache instead of IIS. Working with Certificates I’ve worked with certificates on windows and linux, but for this go I’ll create the certificate authority on my linux virtual machine and prepare the certificates. Many have mad cli skills with the openssl command switches, but I do not. So I’m a big fan of the CA.pl script for working with certificates, which hides a lot of the magic. Make a directory a copy a couple tools into it for testing (my Ubuntu system file locations, ymmv) jrahm@jrahm-dev:~$ mkdir catest jrahm@jrahm-dev:~$ cd catest jrahm@jrahm-dev:~/catest$ cp /usr/lib/ssl/misc/CA.pl . jrahm@jrahm-dev:~/catest$ cp /usr/lib/ssl/openssl.cnf . Create the certificate authority. Questions are pretty self explanatory, make sure the common name is the name you want the CA to be referenced as. jrahm@jrahm-dev:~/catest$ ./CA.pl –newca Create the certificate and sign in. Similar questions to the CA process. Common name should be the name of your site. In my case, this is test.testco.com jrahm@jrahm-dev:~/catest$ ./CA.pl -newreq jrahm@jrahm-dev:~/catest$ ./CA.pl –sign Export the root certificate to Windows compatible format (had to use the openssl command for this one) jrahm@jrahm-dev:~/catest$ openssl x509 -in cacert.pem -outform DER -out ca.der Copy the files to the desktop (using pscp) C:\Users\jrahm>pscp jrahm@10.10.20.200:/home/jrahm/catest/*.pem . C:\Users\jrahm>pscp jrahm@10.10.20.200:/home/jrahm/catest/demoCA/ca.der . Install the root certificate in Windows Install the test.testco.com key and certificate to BIG-IP Create the SSL Profile for CA-signed certificate Create a self-signed certificate in BIG-IP for host test.testco.com Create an additional clientssl profile for the self-signed certificate Preparing the BIG-IP Configuration To test this properly we need four virtual servers, a single pool, and a couple iRules. The first two virtuals are for the “good” site and support the standard ports for http and https. The second two virtuals are for the “bad” site and this site will represent our man-in-the-middle attacker. The iRules support a response rewrite on the good site http virtual (as recommended in the draft), and the insert of the HSTS header on the https virtual only (as required by the draft). Not specified in the draft is the appropriate length for the max-age. I’m adding logic to expire the max-age a day in advance of the certificate expiration date, but you can set a static length of time. I read on one blog that a user was setting it for 50 years. It’s not necessary in my example, but I’m setting the includeSubDomains as well, so that will instruct browsers to securely request and link from test.testco.com and any subdomains of this site (ie, my.test.testco.com). 1: ### iRule for HSTS HTTP Virtuals ### 2: # 3: when HTTP_REQUEST { 4: HTTP::respond 301 Location "https://[HTTP::host][HTTP::uri]" 5: } 6: 7: ### iRule for HSTS HTTPS Virtuals ### 8: # 9: when RULE_INIT { 10: set static::expires [clock scan 20110926] 11: } 12: when HTTP_RESPONSE { 13: HTTP::header insert Strict-Transport-Security "max-age=[expr {$static::expires - [clock seconds]}]; includeSubDomains" 14: } HSTS & MITM Virtuals ### "Good" Virtuals ### # virtual testco_http-vip { snat automap pool testco-pool destination 10.10.20.111:http ip protocol tcp rules hsts_redirect profiles { http {} tcp {} } } virtual testco_https-vip { snat automap pool testco-pool destination 10.10.20.111:https ip protocol tcp rules hsts_insert profiles { http {} tcp {} testco_clientssl { clientside } } } ### "Bad" Virtuals ### # virtual testco2_http-vip { snat automap pool testco-pool destination 10.10.20.112:http ip protocol tcp profiles { http {} tcp {} } } virtual testco2_https-vip { snat automap pool testco-pool destination 10.10.20.112:https ip protocol tcp profiles { http {} tcp {} testco-bad_clientssl { clientside } } } The Results I got the expected results on both Firefox 4.0 and Chrome. Once I switched the virtual from the known good site to the bad site, both browsers presented error pages that I could not click through. HSTS TestResults Great! Where is it Supported? Support already exists in the latest releases of Google Chrome, and if you use the NoScript add-on for current Firefox releases you have support as well. As mentioned above in the introductory section, Firefox 4.0 will support it as well when it releases. Conclusion HTTP Strict Transport Security is a promising development in thwarting some attack vectors between client and server, and is a simple yet effective deployment in iRules. One additional thing worth mentioning is the ability on the user agent (browser or browser add-on) to “seed” known HSTS servers. This would provide additional protection against the initial http connection users might make before redirecting to the https site where the STS header is delivered. Section 12.2 of the draft discusses the bootstrap vulnerability without the seeds in place prior to the first connection to the specified site. Technorati Tags: F5 DevCentral,HTTP Strict Transport Security,HSTS,STS,MITM Attack,Jason Rahm Strict+Transport+Security" rel="tag">HTTP Strict Transport Security,HSTS,STS,MITM Attack,Jason Rahm4.8KViews0likes5Comments
Implementing The Exponential Backoff Algorithm To Thwart Dictionary Attacks
Introduction Recently there was a forum post regarding using the exponential backoff algorithm to prevent or at the very least slow down dictionary attacks. A dictionary attack is when a perpetrator attacks a weak system or application by cycling through a common list of username and password combinations. If were to leave a machine connected Internet with SSH open for any length of time, it wouldn’t take long for an attacker to come along and start hammering the machine. He’ll go through his list until he either cracks an account, gets blocked, or hits the bottom of his list. The attacker has a distinct advantage when he can send unabated requests to the system or application he is attacking. The purpose of the exponential backoff algorithm is to increase the time between subsequent login attempts exponentially. Under this scenario, a normal user wouldn’t be able to type or navigate faster than the minimum lockout period and probably has a very low likelihood of ever hitting the limit. In contrast, if someone was to make a number of repetitive requests in a small timeframe, the time he would be locked out would rise exponentially. Exponential Backoff Algorithm The exponential backoff algorithm is mathematically rather simple. The lockout period is calculated by raising 2 to the power of the number of previous attempts made, subtracting 1, then dividing by two. The equation looks like this: The effect of this calculation is that the timeout for the lockout period is small for the first series of attempts, but rise very quickly given a burst of attempts. If we assemble a table and a plot of previous attempts vs. lockout period, the accumulation becomes apparent with each subsequent attempt doubling the lockout period. If an attacker were to hit an application with 20 attempts in a short window, they would be locked out almost indefinitely or at least to the max lockout period, which we’ll discuss shortly. Attempts Lockout (s) Lockout (h, m, s) 1 0 0s 2 2 2s 3 4 4s 4 8 8s 5 16 16s 6 32 32s 7 64 1m 4s 8 128 2m 8s 9 256 4m 16s 10 512 8m 32s 11 1024 17m 4s 12 2048 34m 8s 13 4096 1h 8m 16s 14 8192 2h 16m 32s 15 16384 4h 33m 4s Previous Attempts vs. Lockout Period Calculating Integer Powers of 2 A number of standard TCL math functions are disabled in iRules because of their ability to consume immense CPU resources. While this does protect the average iRule developer from shooting himself in the leg with them, it limits the ability to perform more complex operations. One function in particular would make implementing the exponential backoff algorithm much easier: pow(). The pow() provides the ability to perform exponentiation or raising a number (the base) to the power of another (the exponent). While we would have needed to write code to perform this functionality for bases larger than 2, it is actually a rather easy operation using an arithmetic shift (left in this case). In TCL (like many other modern languages) uses the << operator to perform a left shift (multiplication by 2) and the >> operator to employ right shift (division by 2). This works because all of the potential lockout periods will be a geometric sequence of integer powers of 2. Take a look at the effect of a left shift on integer powers of two when represented as a binary number (padding added to represent an 8-bit integer): Binary number Decimal number TCL left shift (tclsh) 0 0 0 0 0 0 0 1 1 % expr {1 << 0} => 1 0 0 0 0 0 0 1 0 2 % expr {1 << 1} => 2 0 0 0 0 0 1 0 0 4 % expr {1 << 2} => 4 0 0 0 0 1 0 0 0 8 % expr {1 << 3} => 8 0 0 0 1 0 0 0 0 16 % expr {1 << 4} => 16 0 0 1 0 0 0 0 0 32 % expr {1 << 5} => 32 0 1 0 0 0 0 0 0 64 % expr {1 << 6} => 64 1 0 0 0 0 0 0 0 128 % expr {1 << 7} => 128 Even if the power function were available, a bitwise operation is almost certainly the most efficient way to perform this calculation. Sometimes the most obvious answer is not necessarily the most efficient. Had we not ran into this small barrier, this solution probably would not have emerged. Check out the link below for a complete list of available math functions, operators, and expressions in iRules. List of TCL math function available in iRules Implementing the Algorithm in iRules Now that we know how to calculate integer powers of 2 using an arithmetic shift, the rest of the equation implementation should be straightforward. Once we replace pow() function with a left shift, we get an equation that looks as such: set new_lockout [expr (((1 << $prev_attempts)-1)/2)] Now when we run through a geometric series in TCL we’ll get “almost” the number in the tables above, but they’ll all have a value of one less than expected because we always divide an odd numerator resulting in a float that is truncated when converted to an integer. When this process takes place, the digits after the decimal place are truncated and only the integer portion remains. Given a random distribution of floats truncated to integers there would normally be an even distribution of those rounded “correctly” and “incorrectly.” However in this series all of the solutions end with a decimal value of .500000 and are therefore rounded “incorrectly”. Previous attempts Calculated (float) Calculated (integer) 0 0 0 1 0.5 0 2 1.5 1 3 3.5 3 4 7.5 7 5 15.5 15 We could use the equation listed above, but our numbers would not line up with our projections. In order to get more accurate numbers and save additional CPU cycles, we can further reduce the equations to this: Or as TCL like this: set new_lockout [expr (1 << ($prev_attempts-1))] Now we’ve got something that is super fast and serves our purposes. It would be virtually impossible to overload a box with this simple operation. This is a far more efficient and elegant solution than the originally proposed power function. Maximums, Minimums, and State The benefit of the exponential backoff algorithm is that it increased exponentially when probed repeatedly, but this is also the downside. As the timeout grows exponentially you can potentially lock out the user permanently and quickly fill the memory allocated for a 32-bit integer. The maximum value of a 32-bit integer that can be stored in iRules is 2,147,483,647, which equates to 68 years, 1 month, and change (far longer than a BIG-IP will be in service). For this reason, we’ll want to set a maximum lockout period for a user so that we don’t exceed the memory allocation or lock a user out permanently. We recommend a maximum lockout period of anything from an hour (3600s) to a day (86,400s) for most use cases. The maximum lockout period is defined by the static max_lockout variable in the RULE_INIT event. On the flipside, you’ll notice that there is a case where we get a lockout period of zero for the first request, which will cause a timing issue for the iRule. Therefore we need to establish some minimum for the lockout period. During our tests we found that 2 seconds works well for normal browsing behaviors. You may however decide that you never want anyone submitting faster than every 10 seconds and you’d like the added benefit of the exponential backup, therefore you would change the static min_lockout value in RULE_INIT to 10 (seconds). Lastly, we use the session table to record the number of previous attempts and the lockout period. We define the state table name as a static variable in the CLIENT_ACCEPTED event and use a unique session identifier consisting of the client’s IP and source port to track each session’s behavior. Once we receive a POST request, we’ll increment the previous attempts counter and the calculate a new timeout (lockout period) for the table entry. Once enough time has passed, the entry will timeout in the session table and the client may submit another POST request without restriction. The Exponential Backoff iRule Once we bring all those concepts together, we arrive at something like the iRule listed below. When applied to an HTTP virtual server, the exponential backoff iRule will count the POST requests and prevent users from firing them off two quickly. If a user or bot issues two tightly coupled POST requests they will be locked out temporarily and receive an HTTP response advising them to slow down. If they continue to probe the virtual server, they will be locked out for the next 24 hours on their 18th attempt. 1: when RULE_INIT { 2: set static::min_lockout 2 3: set static::max_lockout 86400 4: set static::debug 1 5: } 6: 7: when CLIENT_ACCEPTED { 8: set static::session_id "[IP::remote_addr]:[TCP::remote_port]" 9: set static::state_table "[virtual name]-exp-backoff-state" 10: } 11: 12: when HTTP_REQUEST { 13: if { [HTTP::method] eq "POST" } { 14: set prev_attempts [table lookup -subtable $static::state_table $static::session_id] 15: 16: if { $prev_attempts eq "" } { set prev_attempts 0 } 17: 18: # exponential backoff - http://en.wikipedia.org/wiki/Exponential_backoff 19: set new_lockout [expr (1 << ($prev_attempts-1))] 20: 21: if { $new_lockout > $static::max_lockout } { 22: set new_lockout $static::max_lockout 23: } elseif { $new_lockout < $static::min_lockout } { 24: set new_lockout $static::min_lockout 25: } 26: 27: table incr -subtable $static::state_table $static::session_id 28: table timeout -subtable $static::state_table $static::session_id $new_lockout 29: 30: if { $static::debug > 0 } { 31: log local0. "POST request (#[expr ($prev_attempts+1)]) from $static::session_id received during lockout period, updating lockout to ${new_lockout}s" 32: } 33: 34: if { $prev_attempts > 1 } { 35: # alternatively respond with content - http://devcentral.f5.com/s/wiki/iRules.HTTP__respond.ashx 36: set response "<html><head><title>Hold up there!</title></head><body><center><h1>Hold up there!</h1><p>You're" 37: append response " posting too quickly. Wait a few moments are try again.</p></body></html>" 38: 39: HTTP::respond 200 content $response 40: } 41: } 42: } CodeShare: Exponential Backoff iRule Conclusion The exponential backoff algorithm provides a great method for thwarting attacks that rely on heavy volume of traffic directed at a system or application. Even if an attacker were to discover the minimum lockout period, they would still be greatly slowed in their attack and would likely move on to easier targets. Protecting an application or system is similar to locking up a bike in many ways. Complete impenetrable security is a difficult (and some would say impossible) endeavor. We can however implement a heavy gauge U-lock accompanied by a thick cable to protect the frame and other various expensive components. A perpetrator would have to expend an inordinate amount of energy to compromise our bike (or system) relative to other targets. The greater the difference in effort (given a similar reward), the more likely it will be that the attacker will move on to easier targets. Until next time, happy coding.4.1KViews0likes2CommentsBIG-IP Interface Stats in Real Time with a TMSH Script
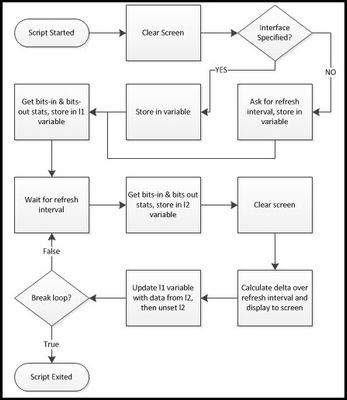
For the savants among us, calculating bits in and bits out over a delta from two snapshots of the interface counters is a walk in the park. For the rest of us, it's nice to have a tool to look at the current traffic load on an interface while working in the command line interface. This article will walk you through creating a TMSH script to do just that. Source Data You can get at interface data via snmp and icontrol, but is also available with the tmsh show net interface command. --------------------------------------------------------- Net::Interface Name Status Bits Bits Pkts Pkts Drops Errs Media In Out In Out --------------------------------------------------------- 1.1 up 59.4T 5.0T 6.2G 2.4G 0 0 none Yep, that's data. But when you get to terabits, the dial doesn't move quite so quickly, so taking a diff every few seconds won't amount to much. Specifying the raw option on the show net interface command helps out in that regard. (raw) ----------------------------------------------------------------------------------------- Net::Interface Name Status Bits Bits Pkts Pkts Drops Errs Media In Out In Out ----------------------------------------------------------------------------------------- 1.1 up 59485486972968 5080727699544 6291600606 2488751052 0 0 none That's better, but a little more challenging to parse than adding the field-fmt option, which puts it in a nice key value pair list. The bits-in and bits-out counters are the focus of this script. net interface 1.1 { counters.bits-in 59486479580896 counters.bits-out 5080875828888 counters.drops-all 0 counters.errors-all 0 counters.pkts-in 6291722759 counters.pkts-out 2488812198 media-active none name 1.1 status up } Now that we have key value pairs, and already separated by whitespace, this is a simple extraction once we split the entire string by newline. % split $x "\n" net\ interface\ 1.1\ \{ \ { counters.bits-in 59500356294368} \ { counters.bits-out 5082163022832} \ { counters.drops-all 0} \ { counters.errors-all 0} \ { counters.pkts-in 6293231170} \ { counters.pkts-out 2489470246} \ { media-active none} \ { name 1.1} \ { status up} \} \ {} % lindex [split $x "\n"] 1 counters.bits-in 59500356294368 % lindex [split $x "\n"] 2 counters.bits-out 5082163022832 % lindex [lindex [split $x "\n"] 1] 1 59500356294368 % lindex [lindex [split $x "\n"] 2] 1 5082163022832 Now that the data is extracted in proper form, we can move on to the script! Goals & Workflow The goals for this script are simple: take the values from counters.bits-in and counters.bits-out from a specified interface and display them at a specified refresh interval. We'll get from goals to a script by first working through some workflow: The Script Since we need to get data from the user (interface and interval specifications), let's start with the standard input. We'll use the getFeedback proc below. proc getFeedback { question } { puts -nonewline $question flush stdout return [gets stdin] } This proc pulls is then used in the initial script setup as shown next. tmsh::clear_screen if { $tmsh::argc == 1 } { set int [getFeedback "Please enter the interface number (ie, 1.1): "] } else { set int [lindex $tmsh::argv 1] } set l1 [] set l2 [] set interval [getFeedback "Please enter refresh rate for the stats (in seconds): "] set delay [expr $interval * 1000] Here we see the screen has been cleared, and then if the only argument in the script initialization is the script itself, then we ask for the interface name. Otherwise, we take the second argument value and set it as the interface name. Then, we initialize the l1 and l2 variables as lists. Finally, we ask for the desired refresh interval and set that delay for the after command use as it's argument is in milliseconds, not seconds. Next, we need to go ahead and take the data and dump it into the l1 variable we initialized: lappend l1 [lindex [lindex [split [tmsh::show net interface $int raw field-fmt] "\n"] 1] 1] lappend l1 [lindex [lindex [split [tmsh::show net interface $int raw field-fmt] "\n"] 2] 1] It looks a little scary, but this is an exact copy of the structure shown above in the Tcl shell except that we're using the TMSH command output instead of the static "x" variable we used to get the syntax necessary to extract the data. This results in l1 having a list with the bits-in and bits-out values in indexes 0 and 1 respectively. Now, the loop that allows this script to display the bit rate real time. while { true } { after $delay lappend l2 [lindex [lindex [split [tmsh::show net interface $int raw field-fmt] "\n"] 1] 1] lappend l2 [lindex [lindex [split [tmsh::show net interface $int raw field-fmt] "\n"] 2] 1] tmsh::clear_screen set statsIn [expr ([lindex $l2 0] - [lindex $l1 0]) / $interval] set statsOut [expr ([lindex $l2 1] - [lindex $l1 1]) / $interval] puts "Interface\t\tInbound (bps)\t\tOutbound (bps)" puts "$int\t\t\t$statsIn\t\t\t$statsOut" set l1 $l2 unset l2 } This loop will continue until you break it with a ctrl-c. We start the loop condition with our specified delay, then do with the l2 variable what we did with the l1 variable: take a snapshot of the bits-in and bits-out of the interface. After again clearing the screen, now we take the delta of the new snapshot and the old snapshot, and divide by the interval to get the bits transferred in and out on that interface, per second. Next, we display that to the screen with the puts command. Finally, in order to maintain the latest snapshot for the next interval, we set the l2 data to the l1 variable and unset the l2 variable. And that's it. Not that complicated, right? Going Forward This is a very simple throwaway script that needs a lot of work to have "arrived." Error checking, extensibility, etc, are missing, and are all left to the reader to develop for those purposes. This met a very specific troubleshooting need in my environment, and I would be remiss if I didn't share. I'd love to see someone take on error checking, or maybe displaying the bitrates for all interfaces if none is specified, or going a step further, summarizing all interfaces per vlan and showing vlan bitrates. Any takers? The script in its entirety is here in the TMSH codeshare.3.6KViews0likes2Comments
Multiple Certs, One VIP: TLS Server Name Indication via iRules
An age old question that we’ve seen time and time again in the iRules forums here on DevCentral is “How can I use iRules to manage multiple SSL certs on one VIP"?”. The answer has always historically been “I’m sorry, you can’t.”. The reasoning is sound. One VIP, one cert, that’s how it’s always been. You can’t do anything with the connection until the handshake is established and decryption is done on the LTM. We’d like to help, but we just really can’t. That is…until now. The TLS protocol has somewhat recently provided the ability to pass a “desired servername” as a value in the originating SSL handshake. Finally we have what we’ve been looking for, a way to add contextual server info during the handshake, thereby allowing us to say “cert x is for domain x” and “cert y is for domain y”. Known to us mortals as "Server Name Indication" or SNI (hence the title), this functionality is paramount for a device like the LTM that can regularly benefit from hosting multiple certs on a single IP. We should be able to pull out this information and choose an appropriate SSL profile now, with a cert that corresponds to the servername value that was sent. Now all we need is some logic to make this happen. Lucky for us, one of the many bright minds in the DevCentral community has whipped up an iRule to show how you can finally tackle this challenge head on. Because Joel Moses, the shrewd mind and DevCentral MVP behind this example has already done a solid write up I’ll quote liberally from his fine work and add some additional context where fitting. Now on to the geekery: First things first, you’ll need to create a mapping of which servernames correlate to which certs (client SSL profiles in LTM’s case). This could be done in any manner, really, but the most efficient both from a resource and management perspective is to use a class. Classes, also known as DataGroups, are name->value pairs that will allow you to easily retrieve the data later in the iRule. Quoting Joel: Create a string-type datagroup to be called "tls_servername". Each hostname that needs to be supported on the VIP must be input along with its matching clientssl profile. For example, for the site "testsite.site.com" with a ClientSSL profile named "clientssl_testsite", you should add the following values to the datagroup. String: testsite.site.com Value: clientssl_testsite Once you’ve finished inputting the different server->profile pairs, you’re ready to move on to pools. It’s very likely that since you’re now managing multiple domains on this VIP you'll also want to be able to handle multiple pools to match those domains. To do that you'll need a second mapping that ties each servername to the desired pool. This could again be done in any format you like, but since it's the most efficient option and we're already using it, classes make the most sense here. Quoting from Joel: If you wish to switch pool context at the time the servername is detected in TLS, then you need to create a string-type datagroup called "tls_servername_pool". You will input each hostname to be supported by the VIP and the pool to direct the traffic towards. For the site "testsite.site.com" to be directed to the pool "testsite_pool_80", add the following to the datagroup: String: testsite.site.com Value: testsite_pool_80 If you don't, that's fine, but realize all traffic from each of these hosts will be routed to the default pool, which is very likely not what you want. Now then, we have two classes set up to manage the mappings of servername->SSLprofile and servername->pool, all we need is some app logic in line to do the management and provide each inbound request with the appropriate profile & cert. This is done, of course, via iRules. Joel has written up one heck of an iRule which is available in the codeshare (here) in it's entirety along with his solid write-up, but I'll also include it here in-line, as is my habit. Effectively what's happening is the iRule is parsing through the data sent throughout the SSL handshake process and searching for the specific TLS servername extension, which are the bits that will allow us to do the profile switching magic. He's written it up to fall back to the default client SSL profile and pool, so it's very important that both of these things exist on your VIP, or you may likely find yourself with unhappy users. One last caveat before the code: Not all browsers support Server Name Indication, so be careful not to implement this unless you are very confident that most, if not all, users connecting to this VIP will support SNI. For more info on testing for SNI compatibility and a list of browsers that do and don't support it, click through to Joel's awesome CodeShare entry, I've already plagiarized enough. So finally, the code. Again, my hat is off to Joel Moses for this outstanding example of the power of iRules. Keep at it Joel, and thanks for sharing! 1: when CLIENT_ACCEPTED { 2: if { [PROFILE::exists clientssl] } { 3: 4: # We have a clientssl profile attached to this VIP but we need 5: # to find an SNI record in the client handshake. To do so, we'll 6: # disable SSL processing and collect the initial TCP payload. 7: 8: set default_tls_pool [LB::server pool] 9: set detect_handshake 1 10: SSL::disable 11: TCP::collect 12: 13: } else { 14: 15: # No clientssl profile means we're not going to work. 16: 17: log local0. "This iRule is applied to a VS that has no clientssl profile." 18: set detect_handshake 0 19: 20: } 21: 22: } 23: 24: when CLIENT_DATA { 25: 26: if { ($detect_handshake) } { 27: 28: # If we're in a handshake detection, look for an SSL/TLS header. 29: 30: binary scan [TCP::payload] cSS tls_xacttype tls_version tls_recordlen 31: 32: # TLS is the only thing we want to process because it's the only 33: # version that allows the servername extension to be present. When we 34: # find a supported TLS version, we'll check to make sure we're getting 35: # only a Client Hello transaction -- those are the only ones we can pull 36: # the servername from prior to connection establishment. 37: 38: switch $tls_version { 39: "769" - 40: "770" - 41: "771" { 42: if { ($tls_xacttype == 22) } { 43: binary scan [TCP::payload] @5c tls_action 44: if { not (($tls_action == 1) && ([TCP::payload length] > $tls_recordlen)) } { 45: set detect_handshake 0 46: } 47: } 48: } 49: default { 50: set detect_handshake 0 51: } 52: } 53: 54: if { ($detect_handshake) } { 55: 56: # If we made it this far, we're still processing a TLS client hello. 57: # 58: # Skip the TLS header (43 bytes in) and process the record body. For TLS/1.0 we 59: # expect this to contain only the session ID, cipher list, and compression 60: # list. All but the cipher list will be null since we're handling a new transaction 61: # (client hello) here. We have to determine how far out to parse the initial record 62: # so we can find the TLS extensions if they exist. 63: 64: set record_offset 43 65: binary scan [TCP::payload] @${record_offset}c tls_sessidlen 66: set record_offset [expr {$record_offset + 1 + $tls_sessidlen}] 67: binary scan [TCP::payload] @${record_offset}S tls_ciphlen 68: set record_offset [expr {$record_offset + 2 + $tls_ciphlen}] 69: binary scan [TCP::payload] @${record_offset}c tls_complen 70: set record_offset [expr {$record_offset + 1 + $tls_complen}] 71: 72: # If we're in TLS and we've not parsed all the payload in the record 73: # at this point, then we have TLS extensions to process. We will detect 74: # the TLS extension package and parse each record individually. 75: 76: if { ([TCP::payload length] >= $record_offset) } { 77: binary scan [TCP::payload] @${record_offset}S tls_extenlen 78: set record_offset [expr {$record_offset + 2}] 79: binary scan [TCP::payload] @${record_offset}a* tls_extensions 80: 81: # Loop through the TLS extension data looking for a type 00 extension 82: # record. This is the IANA code for server_name in the TLS transaction. 83: 84: for { set x 0 } { $x < $tls_extenlen } { incr x 4 } { 85: set start [expr {$x}] 86: binary scan $tls_extensions @${start}SS etype elen 87: if { ($etype == "00") } { 88: 89: # A servername record is present. Pull this value out of the packet data 90: # and save it for later use. We start 9 bytes into the record to bypass 91: # type, length, and SNI encoding header (which is itself 5 bytes long), and 92: # capture the servername text (minus the header). 93: 94: set grabstart [expr {$start + 9}] 95: set grabend [expr {$elen - 5}] 96: binary scan $tls_extensions @${grabstart}A${grabend} tls_servername 97: set start [expr {$start + $elen}] 98: } else { 99: 100: # Bypass all other TLS extensions. 101: 102: set start [expr {$start + $elen}] 103: } 104: set x $start 105: } 106: 107: # Check to see whether we got a servername indication from TLS. If so, 108: # make the appropriate changes. 109: 110: if { ([info exists tls_servername] ) } { 111: 112: # Look for a matching servername in the Data Group and pool. 113: 114: set ssl_profile [class match -value [string tolower $tls_servername] equals tls_servername] 115: set tls_pool [class match -value [string tolower $tls_servername] equals tls_servername_pool] 116: 117: if { $ssl_profile == "" } { 118: 119: # No match, so we allow this to fall through to the "default" 120: # clientssl profile. 121: 122: SSL::enable 123: } else { 124: 125: # A match was found in the Data Group, so we will change the SSL 126: # profile to the one we found. Hide this activity from the iRules 127: # parser. 128: 129: set ssl_profile_enable "SSL::profile $ssl_profile" 130: catch { eval $ssl_profile_enable } 131: if { not ($tls_pool == "") } { 132: pool $tls_pool 133: } else { 134: pool $default_tls_pool 135: } 136: SSL::enable 137: } 138: } else { 139: 140: # No match because no SNI field was present. Fall through to the 141: # "default" SSL profile. 142: 143: SSL::enable 144: } 145: 146: } else { 147: 148: # We're not in a handshake. Keep on using the currently set SSL profile 149: # for this transaction. 150: 151: SSL::enable 152: } 153: 154: # Hold down any further processing and release the TCP session further 155: # down the event loop. 156: 157: set detect_handshake 0 158: TCP::release 159: } else { 160: 161: # We've not been able to match an SNI field to an SSL profile. We will 162: # fall back to the "default" SSL profile selected (this might lead to 163: # certificate validation errors on non SNI-capable browsers. 164: 165: set detect_handshake 0 166: SSL::enable 167: TCP::release 168: 169: } 170: } 171: }3.6KViews0likes18CommentsiControl REST: Working with Pool Members
Since iControl REST is the new kid on the block, it's bound to start getting some of the same questions we've addressed with traditional iControl. One of these oft-asked and misunderstood questions is about enabling/disabling pool members. The original poster in this case is actually facing a syntax issue with the allowable state issues in the json payload, but I figured I'd kill two birds with one stone here and address both concerns going forward. DevCentral member Rudi posted in Q&A asking for some assistance with disabling a pool member. He was able to change some properties on the pool member, but trying to change the state resulted in this error: {"code":400,"message":"invalid property value \"state\":\"up\"","errorStack":[]} The REST interface is complaining about an invalid property, mainline, the "up" state. If you do a query against an "up" pool member, you can see that the state is "unchecked" instead of up. { "state": "unchecked", "connectionLimit": 0, "address": "192.168.101.11", "selfLink": "https://localhost/mgmt/tm/ltm/pool/testpool/members/~Common~192.168.101.11:8000?ver=11.5.1", "generation": 63, "fullPath": "/Common/192.168.101.11:8000", "partition": "Common", "name": "192.168.101.11:8000", "kind": "tm:ltm:pool:members:membersstate", "dynamicRatio": 1, "inheritProfile": "enabled", "logging": "disabled", "monitor": "default", "priorityGroup": 0, "rateLimit": "disabled", "ratio": 1, "session": "user-enabled" } You might also note the session keyword in the pool member attributes as well. This is the key that controls the forced offline behavior. The mappings for these two values (state and session) to the GUI state of a pool member are as follows GUI: Enabled {"state": "unchecked", "session": "user-enabled"} GUI: Disabled {"state": "unchecked", "session": "user-disabled"} GUI: Forced Offline {"state": "user-down", "session": "user-disabled"} So to change a value on a pool member, you need to use the PUT method, and specify in the URL the pool, pool name, and the pool member: curl -sk -u admin:admin https://192.168.6.5/mgmt/tm/ltm/pool/testpool/members/~Common~192.168.101.11:8000/ \ -H "Content-Type: application/json" -X PUT -d '{"state": "user-down", "session": "user-disabled"}' This results in changed state and session for this pool member: { "state": "user-down", "connectionLimit": 0, "address": "192.168.101.11", "selfLink": "https://localhost/mgmt/tm/ltm/pool/testpool/members/~Common~192.168.101.11:8000?ver=11.5.1", "generation": 63, "fullPath": "/Common/192.168.101.11:8000", "partition": "Common", "name": "192.168.101.11:8000", "kind": "tm:ltm:pool:members:membersstate", "dynamicRatio": 1, "inheritProfile": "enabled", "logging": "disabled", "monitor": "default", "priorityGroup": 0, "rateLimit": "disabled", "ratio": 1, "session": "user-disabled" } Best tip I can give with discovering the nuances of iControl REST is to query existing objects, and change their default values around in the GUI and re-query to see what the values are supposed to be. Happy coding!2.7KViews0likes10CommentsGetting Started with Bigsuds–a New Python Library for iControl
I imagine the progression for you, the reader, will be something like this in the first six- or seven-hundred milliseconds after reading the title: Oh cool! Wait, what? Don’t we already have like two libraries for python? Really, a third library for python? Yes. An emphatic yes. The first iteration of pycontrol (pc1) was based on the zsi library, which hasn’t been updated in years and was abandoned with the development of the second iteration, pycontrol v2 (pc2), which switched to the active and well-maintained suds library. Bigsuds, like pycontrol v2, is also based on the suds library. So why bigsuds? There are several advantages to using the bigsuds library. No need to specify which WSDLs to download In pycontrol v2, any iControl interface you wish to work with must be specified when you instantiate the BIG-IP, as well as specifying the local directory or loading from URL for the WSDLs. In bigsuds, just specify the host, username, and password (username and password optional if using test box defaults of admin/admin) and you’re good to go. Currently in pycontrol v2: >>> import pycontrol.pycontrol as pc >>> b = pc.BIGIP( ... hostname = '192.168.6.11', ... username = 'admin', ... password = 'admin', ... fromurl = True, ... wsdls = ['LocalLB.Pool']) >>> b.LocalLB.Pool.get_list() [/Common/p1, /Common/p2, /Common/p3, /Common/p5] And here in bigsuds: >>> import bigsuds >>> b = bigsuds.BIGIP(hostname = '192.168.6.11') >>> b.LocalLB.Pool.get_list() ['/Common/p1', '/Common/p2', '/Common/p3', '/Common/p5'] >>> b.GlobalLB.Pool.get_list() ['/Common/p2', '/Common/p1'] No need to define the typefactory for write operations. This was the most challenging aspect of pycontrol v2 for me personally. I would get them correct sometimes. Often I’d bang my head against the wall wondering what little thing I missed to prevent success. The cool thing with bigsuds is you are just passing lists for sequences and lists of dictionaries for structures. No object creation necessary before making the iControl calls. It’s a thing of beauty. Creating a two member pool in pycontrol v2: lbmeth = b.LocalLB.Pool.typefactory.create('LocalLB.LBMethod') # This is basically a stub holder of member items that we need to wrap up. mem_sequence = b.LocalLB.Pool.typefactory.create('Common.IPPortDefinitionSequence') # Now we'll create some pool members. mem1 = b.LocalLB.Pool.typefactory.create('Common.IPPortDefinition') mem2 = b.LocalLB.Pool.typefactory.create('Common.IPPortDefinition') # Note how this is 'pythonic' now. We set attributes agains the objects, then # pass them in. mem1.address = '1.2.3.4' mem1.port = 80 mem2.address = '1.2.3.4' mem2.port = 81 # Create a 'sequence' of pool members. mem_sequence.item = [mem1, mem2] # Let's create our pool. name = 'PC2' + str(int(time.time())) b.LocalLB.Pool.create(pool_names = [name], lb_methods = \ [lbmeth.LB_METHOD_ROUND_ROBIN], members = [mem_sequence]) In contrast, here is a two member pool in bigsuds. >>> b.LocalLB.Pool.create_v2(['/Common/Pool1'],['LB_METHOD_ROUND_ROBIN'],[[{'port':80, 'address':'1.2.3.4'},{'port':81, 'address':'1.2.3.4'}]]) Notice above that I did not use the method parameters. They are not required in bigsuds, though you can certainly include them. This could be written in the long form as: >>> b.LocalLB.Pool.create_v2(pool_names = ['/Common/Pool1'],lb_methods = ['LB_METHOD_ROUND_ROBIN'], members = [[{'port':80, 'address':'1.2.3.4'},{'port':81, 'address':'1.2.3.4'}]]) Standard python data types are returned There’s no more dealing with data returned like this: >>> p2.LocalLB.Pool.get_statistics(pool_names=['/Common/p2']) (LocalLB.Pool.PoolStatistics){ statistics[] = (LocalLB.Pool.PoolStatisticEntry){ pool_name = "/Common/p2" statistics[] = (Common.Statistic){ type = "STATISTIC_SERVER_SIDE_BYTES_IN" value = (Common.ULong64){ high = 0 low = 0 } time_stamp = 0 }, (Common.Statistic){ type = "STATISTIC_SERVER_SIDE_BYTES_OUT" value = (Common.ULong64){ high = 0 low = 0 } time_stamp = 0 }, Data is standard python types: strings, lists, dictionaries. That same data returned by bigsuds: >>> b.LocalLB.Pool.get_statistics(['/Common/p1']) {'statistics': [{'pool_name': '/Common/p1', 'statistics': [{'time_stamp': 0, 'type': 'STATISTIC_SERVER_SIDE_BYTES_IN', 'value': {'high': 0, 'low': 0}}, {'time_stamp': 0, 'type': 'STATISTIC_SERVER_SIDE_BYTES_OUT', 'value': {'high': 0, 'low': 0}} Perhaps not as readable in this form as with pycontrol v2, but far easier to work programmatically. Better session and transaction support George covered the benefits of sessions in his v11 iControl: Sessions article in fine detail, so I’ll leave that to the reader. Regarding implementations, bigsuds handles sessions with a built-in utility called with_session_id. Example code: >>> bigip2 = b.with_session_id() >>> bigip2.System.Session.set_transaction_timeout(99) >>> print b.System.Session.get_transaction_timeout() 5 >>> print bigip2.System.Session.get_transaction_timeout() 99 Also, with transactions, bigsuds has built-in transaction utilities as well. In the below sample code, creating a new pool that is dependent on a non-existent pool being deleted results in an error as expected, but also prevents the pool from the previous step from being created as show in the get_list method call. >>> try: ... with bigsuds.Transaction(bigip2): ... bigip2.LocalLB.Pool.create_v2(['mypool'],['LB_METHOD_ROUND_ROBIN'],[[]]) ... bigip2.LocalLB.Pool.delete_pool(['nonexistent']) ... except bigsuds.OperationFailed, e: ... print e ... Server raised fault: 'Exception caught in System::urn:iControl:System/Session::submit_transaction() Exception: Common::OperationFailed primary_error_code : 16908342 (0x01020036) secondary_error_code : 0 error_string : 01020036:3: The requested pool (/Common/nonexistent) was not found.' >>> bigip2.LocalLB.Pool.get_list() ['/Common/Pool1', '/Common/p1', '/Common/p2', '/Common/p3', '/Common/p5', '/Common/Pool3', '/Common/Pool2'] F5 maintained Community member L4L7, the author of the pycontrol v2 library, is no longer with F5 and just doesn’t have the cycles to maintain the library going forward. Bigsuds author Garron Moore, however, works in house and will fix bugs and enhance as time allows. Note that all iControl libraries are considered experimental and are not officially supported by F5 Networks. Library maintainers for all the languages will do their best to fix bugs and introduce features as time allows. Source is provided though, and bugs can and are encouraged to be fixed by the community! Installing bigsuds Make sure you have suds installed and grab a copy of bigsuds (you’ll need to log in) and extract the contents. You can use the easy setup tools to install it to python’s site-packages library like this: jrahm@jrahm-dev:/var/tmp$ tar xvfz bigsuds-1.0.tar.gz bigsuds-1.0/ bigsuds-1.0/setup.py bigsuds-1.0/bigsuds.egg-info/ bigsuds-1.0/bigsuds.egg-info/top_level.txt bigsuds-1.0/bigsuds.egg-info/requires.txt bigsuds-1.0/bigsuds.egg-info/SOURCES.txt bigsuds-1.0/bigsuds.egg-info/dependency_links.txt bigsuds-1.0/bigsuds.egg-info/PKG-INFO bigsuds-1.0/setup.cfg bigsuds-1.0/bigsuds.py bigsuds-1.0/MANIFEST.in bigsuds-1.0/PKG-INFO jrahm@jrahm-dev:/var/tmp$ cd bigsuds-1.0/ jrahm@jrahm-dev:/var/tmp/bigsuds-1.0$ python setup.py install Doing it that way, you can just enter the python shell (or run your script) with a simple ‘import bigsuds’ command. If you don’t want to install it that way, you can just extract the bigsuds.py from the download and drop it in a directory of your choice and make a path reference in the shell or script: >>> import bigsuds Traceback (most recent call last): File "<stdin>", line 1, in <module> ImportError: No module named bigsuds >>> import sys >>> sys.path.append(r'/home/jrahm/dev/bigsuds-1.0') >>> import bigsuds >>> Conclusion Garron Moore's bigsuds contribution is a great new library for python users. There is work to be done to convert your pycontrol v2 samples, but the flexibility and clarity in the new library makes it worth it in this guy’s humble opinion. A new page in the iControl wiki has been created for bigsuds developments. Please check it out, community! For now, I’ve converted a few scripts to bigsuds, linked in the aforementioned page as well as directly below: Get GTM Pool Status Get LTM Pool Status Get or Set GTM Pool TTL Create or Modify an LTM Pool2.4KViews0likes24CommentsBase32 Encoding and Decoding With iRules
Introduction Anyone that's done any amount of programming has probably encountered Base64 encoded data. Data that is encoded with Base64 has the advantage of being composed of 64 ASCII characters, which makes it portable and readable with virtually any RFC-compliant decoder. Before Base64 became the de facto encoding standard for content, Base32 was the preferred method. Base32 offers three distinct advantages over Base64: it is case-insensitive, commonly confused characters have been removed (0, 1, and 8 are not included in the Base32 alphabet because they can be mistranscribed as 'O', 'I', and 'B' respectively), and lastly all the characters can be included in a URL without encoding any of them. Here is the full Base32 alphabet: The RFC 4648 Base 32 alphabet* Value Symbol Value Symbol Value Symbol Value Symbol 0 A 9 J 18 S 27 3 1 B 10 K 19 T 28 4 2 C 11 L 20 U 29 5 3 D 12 M 21 V 30 6 4 E 13 N 22 W 31 7 5 F 14 O 23 X 6 G 15 P 24 Y 7 H 16 Q 25 Z 8 I 17 R 26 2 pad = *source Wikipedia’s Base32 article The ability to be able to write down a string of encoded data without worrying about case-sensitivity or mistranscription are advantages, but there are some downsides to Base32 encoding. A few of these reasons include: Base32 is approximately 20% less efficient than Base64 on average and it does not handle UTF-16 (full Unicode) elegantly. With those caveats in place, there is still plenty of code today that uses Base32. Base32 Encoding Base32 encoding works by processing 40-bit chunks, known as quantums, which are composed of five pieces of 8-bit text (UTF-8). During the encoding process, each 8-bit piece of text is read and converted to its UTF-8 integer value. Integer values can range from 0x00 to 0xFF (8-bit) and are concatenated into a string of bits, then read in 5-bit chunks to obtain the corresponding Base32 alphabet symbol. This action is repeated until the final chunk is processed. If the final chunk is exactly 5 bits, it is processed as is, if it is less than 5 bits, zeros are padded (on the right) to bring the chunk to 5-bits, then it is processed. If the final quantum is not an integral multiple of 40, the final quantum is padded with '=' so that the encoded string has a number of characters which are an integral multiple of 8. 1: array set b32_alphabet_inv { 2: 0 A 1 B 2 C 3 D 3: 4 E 5 F 6 G 7 H 4: 8 I 9 J 10 K 11 L 5: 12 M 13 N 14 O 15 P 6: 16 Q 17 R 18 S 19 T 7: 20 U 21 V 22 W 23 X 8: 24 Y 25 Z 26 2 27 3 9: 28 4 29 5 30 6 31 7 10: } 11: 12: set input "Hello World!" 13: set output "" 14: set l [string length $input] 15: set n 0 16: set j 0 17: 18: # encode loop is outlined in RFC 4648 (http://tools.ietf.org/html/rfc4648#page-8) 19: for { set i 0 } { $i < $l } { incr i } { 20: set n [expr $n << 8] 21: set n [expr $n + [scan [string index $input $i] %c]] 22: set j [incr j 8] 23: 24: while { $j >= 5 } { 25: set j [incr j -5] 26: append output $b32_alphabet_inv([expr ($n & (0x1F << $j)) >> $j]) 27: } 28: } 29: 30: # pad final input group with zeros to form an integral number of 5-bit groups, then encode 31: if { $j > 0 } { append output $b32_alphabet_inv([expr $n << (5 - $j) & 0x1F]) } 32: 33: # if the final quantum is not an integral multiple of 40, append "=" padding 34: set pad [expr 8 - [string length $output] % 8] 35: if { ($pad > 0) && ($pad < 8) } { append output [string repeat = $pad] } 36: 37: # $output = JBSWY3DPEBLW64TMMQQQ==== 38: puts $output Base32 DecodingBase32 decoding works in a similar fashion to encoding, just in reverse. By eliminating the need for padding the final bit or quantum, the code is simpler and cleaner. The decoding process begins by removing any '=' padding from the final quantum. Next, the string is looped through character by character extracting the Base32 integer value from each 5-bit character and concatenating the bits into a string. After 8 bits or more bits have been collected, the chunks are then processed in 8-bit chunks converting their 8-bit integer value to its UTF-8 value (full Unicode support is unavailable as the chunk is 8-bit vs. the 16-bits required for Unicode). This processing continues until the Base32-encoded string has been fully read and converted to its respective UTF-8 characters. 1: array set b32_alphabet { 2: A 0 B 1 C 2 D 3 3: E 4 F 5 G 6 H 7 4: I 8 J 9 K 10 L 11 5: M 12 N 13 O 14 P 15 6: Q 16 R 17 S 18 T 19 7: U 20 V 21 W 22 X 23 8: Y 24 Z 25 2 26 3 27 9: 4 28 5 29 6 30 7 31 10: } 11: 12: set input JBSWY3DPEBLW64TMMQQQ==== 13: 14: set input [string toupper $input] 15: set input [string trim $input =] 16: set l [string length $input] 17: set output "" 18: set n 0 19: set j 0 20: 21: # decode loop is outlined in RFC 4648 (http://tools.ietf.org/html/rfc4648#page-8) 22: for { set i 0 } { $i < $l } { incr i } { 23: set n [expr $n << 5] 24: set n [expr $n + $b32_alphabet([string index $input $i])] 25: set j [incr j 5] 26: 27: if { $j >= 8 } { 28: set j [incr j -8] 29: append output [format %c [expr ($n & (0xFF << $j)) >> $j]] 30: } 31: } 32: 33: # $output = "Hello World!" 34: puts $output Base32 Encoding and Decoding iRule If the encoding and decoding functions are combined into a single iRule, you’ll wind up with something similar to the code below. This code just logs the encoding an decoding process and is of little use until combined with some input or output data, but here it is: 1: when RULE_INIT { 2: set b32_tests { 3: JBSWY3DPEBLW64TMMQQQ==== 4: KRUGS4ZANFZSAYLON52GQZLSEBZXI4TJNZTSC=== 5: KRUGS4ZANFZSAYJAON2HE2LOM4QHO2LUNAQGCIDQMFSCA33GEA2A==== 6: KRUGS4ZANFZSAYJAON2HE2LOM4QHO2LUNBXXK5BAMEQGM2LOMFWCA4LVMFXHI5LN 7: } 8: 9: array set b32_alphabet { 10: A 0 B 1 C 2 D 3 11: E 4 F 5 G 6 H 7 12: I 8 J 9 K 10 L 11 13: M 12 N 13 O 14 P 15 14: Q 16 R 17 S 18 T 19 15: U 20 V 21 W 22 X 23 16: Y 24 Z 25 2 26 3 27 17: 4 28 5 29 6 30 7 31 18: } 19: 20: foreach input $b32_tests { 21: log local0. " input = $input" 22: 23: set input [string toupper $input] 24: set input [string trim $input =] 25: set l [string length $input] 26: set output "" 27: set n 0 28: set j 0 29: 30: # decode loop is outlined in RFC 4648 (http://tools.ietf.org/html/rfc4648#page-8) 31: for { set i 0 } { $i < $l } { incr i } { 32: set n [expr $n << 5] 33: set n [expr $n + $b32_alphabet([string index $input $i])] 34: set j [incr j 5] 35: 36: if { $j >= 8 } { 37: set j [incr j -8] 38: append output [format %c [expr ($n & (0xFF << $j)) >> $j]] 39: } 40: } 41: 42: log local0. "output/input = $output" 43: 44: # flip b32_alphabet so that base32 characters can be indexed by a 8-bit integer 45: foreach { key value } [array get b32_alphabet] { 46: array set b32_alphabet_inv "$value $key" 47: } 48: 49: set input $output 50: set output "" 51: set l [string length $input] 52: set n 0 53: set j 0 54: 55: # encode loop is outlined in RFC 4648 (http://tools.ietf.org/html/rfc4648#page-8) 56: for { set i 0 } { $i < $l } { incr i } { 57: set n [expr $n << 8] 58: set n [expr $n + [scan [string index $input $i] %c]] 59: set j [incr j 8] 60: 61: while { $j >= 5 } { 62: set j [incr j -5] 63: append output $b32_alphabet_inv([expr ($n & (0x1F << $j)) >> $j]) 64: } 65: } 66: 67: # pad final input group with zeros to form an integral number of 5-bit groups, then encode 68: if { $j > 0 } { append output $b32_alphabet_inv([expr $n << (5 - $j) & 0x1F]) } 69: 70: # if the final quantum is not an integral multiple of 40, append "=" padding 71: set pad [expr 8 - [string length $output] % 8] 72: if { ($pad > 0) && ($pad < 8) } { append output [string repeat = $pad] } 73: 74: log local0. " output = $output" 75: log local0. [string repeat - 20] 76: } 77: } Attach the iRule to a virtual server (preferably not in production) and send some traffic to the virtual. Then check ‘/var/log/ltm’ for the encoded and decoded strings. Ours looked like this: Dec 8 15:30:43 tmm info tmm[23157]: Rule /Common/base32 : input = JBSWY3DPEBLW64TMMQQQ==== Dec 8 15:30:43 tmm info tmm[23157]: Rule /Common/base32 : output/input = Hello World! Dec 8 15:30:43 tmm info tmm[23157]: Rule /Common/base32 : output = JBSWY3DPEBLW64TMMQQQ==== Dec 8 15:30:43 tmm info tmm[23157]: Rule /Common/base32 : -------------------- Dec 8 15:30:43 tmm info tmm[23157]: Rule /Common/base32 : input = KRUGS4ZANFZSAYLON52GQZLSEBZXI4TJNZTSC=== Dec 8 15:30:43 tmm info tmm[23157]: Rule /Common/base32 : output/input = This is another string! Dec 8 15:30:43 tmm info tmm[23157]: Rule /Common/base32 : output = KRUGS4ZANFZSAYLON52GQZLSEBZXI4TJNZTSC=== Dec 8 15:30:43 tmm info tmm[23157]: Rule /Common/base32 : -------------------- Dec 8 15:30:43 tmm info tmm[23157]: Rule /Common/base32 : input = KRUGS4ZANFZSAYJAON2HE2LOM4QHO2LUNAQGCIDQMFSCA33GEA2A==== Dec 8 15:30:43 tmm info tmm[23157]: Rule /Common/base32 : output/input = This is a string with a pad of 4 Dec 8 15:30:43 tmm info tmm[23157]: Rule /Common/base32 : output = KRUGS4ZANFZSAYJAON2HE2LOM4QHO2LUNAQGCIDQMFSCA33GEA2A==== Dec 8 15:30:43 tmm info tmm[23157]: Rule /Common/base32 : -------------------- Dec 8 15:30:43 tmm info tmm[23157]: Rule /Common/base32 : input = KRUGS4ZANFZSAYJAON2HE2LOM4QHO2LUNBXXK5BAMEQGM2LOMFWCA4LVMFXHI5LN Dec 8 15:30:43 tmm info tmm[23157]: Rule /Common/base32 : output/input = This is a string without a final quantum Dec 8 15:30:43 tmm info tmm[23157]: Rule /Common/base32 : output = KRUGS4ZANFZSAYJAON2HE2LOM4QHO2LUNBXXK5BAMEQGM2LOMFWCA4LVMFXHI5LN Dec 8 15:30:43 tmm info tmm[23157]: Rule /Common/base32 : -------------------- CodeShare: Base32 Encoder/Decoder iRule Unicode (UTF-16) Handling This code sample will not process UTF-16 character sets correctly as they rely on 16-bit integers for their corresponding characters. Reading 16-bit chunks is not supported in RFC 4648 as Unicode was not supported on any of the operating systems that originally used Base32 encoding. Some high-level languages have context aware handling for other character sets, but it is more commonly the exception, not the rule. If you must encode Unicode, you can encode with Base64 first, then encode the output with Base32. Decode in the reverse order. Conclusion You're probably asking yourself why in the world anyone would ever want to use Base32 encoding. It was used historically in operating systems that did not support case-sensitivity, but those days are long gone. Aside from the reasons listed in the introduction, the main advantage and the reason it is still used today is that it can be transcribed via the phonetic alphabet with less effort and fewer mistakes than Base64. Symmetric keys are often exchanged using this method, which is the use-case that we ran into and spawned this Tech Tip. We don't want to give away too much, but there is another Tech Tip around the corner that specifically uses this encoding. Until then, happy (en)coding...1.6KViews0likes2CommentsiCall Triggers - Invalidating Cache from iRules
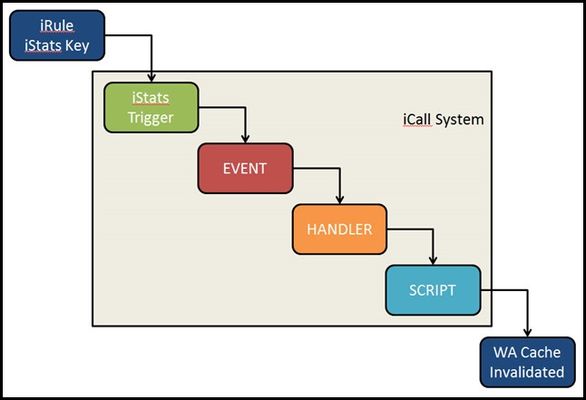
iCall is BIG-IP's all new (as of BIG-IP version 11.4) event-based automation system for the control plane. Previously, I wrote up the iCall system overview, as well as an article on the use of a periodic handler for automating backups. This article will feature the use of the triggered iCall handler to allow a user to submit a http request to invalidate the cache served up for an application managed by the Application Acceleration Manager. Starting at the End Before we get to the solution, I'd like to address the use case for invalidating cache. In many cases, the team responsible for an application's health is not the network services team which is the typical point of access to the BIG-IP. For large organizations with process overhead in generating tickets, invalidating cache can take time. A lot of time. So the request has come in quite frequently..."How can I invalidate cache remotely?" Or even more often, "Can I invalidate cache from an iRule?" Others have approached this via script, and it has been absolutely possible previously with iRules, albeit through very ugly and very-not-recommended ways. In the end, you just need to issue one TMSH command to invalidate the cache for a particular application: tmsh::modify wam application content-expiration-time now So how do we get signal from iRules to instruct BIG-IP to run a TMSH command? This is where iCall trigger handlers come in. Before we hope back to the beginning and discuss the iRule, the process looks like this: Back to the Beginning The iStats interface was introduced in BIG-IP version 11 as a way to make data accessible to both the control and data planes. I'll use this to pass the data to the control plane. In this case, the only data I need to pass is to set a key. To set an iStats key, you need to specify : Class Object Measure type (counter, gauge, or string) Measure name I'm not measuring anything, so I'll use a string starting with "WA policy string" and followed by the name of the policy. You can be explicit or allow the users to pass it in a query parameter as I'm doing in this iRule below: when HTTP_REQUEST { if { [HTTP::path] eq "/invalidate" } { set wa_policy [URI::query [HTTP::uri] policy] if { $wa_policy ne "" } { ISTATS::set "WA policy string $wa_policy" 1 HTTP::respond 200 content "App $wa_policy cache invalidated." } else { HTTP::respond 200 content "Please specify a policy /invalidate?policy=policy_name" } } } Setting the key this way will allow you to create as many triggers as you have policies. I'll leave it as an exercise for the reader to make that step more dynamic. Setting the Trigger With iStats-based triggers, you need linkage to bind the iStats key to an event-name, wacache in my case. You can also set thresholds and durations, but again since I am not measuring anything, that isn't necessary. sys icall istats-trigger wacache_trigger_istats { event-name wacache istats-key "WA policy string wa_policy_name" } Creating the Script The script is very simple. Clear the cache with the TMSH command, then remove the iStats key. sys icall script wacache_script { app-service none definition { tmsh::modify wam application dc.wa_hero content-expiration-time now exec istats remove "WA policy string wa_policy_name" } description none events none } Creating the Handler The handler is the glue that binds the event I created in the iStats trigger. When the handler sees an event named wacache, it'll execute the wacache_script iCall script. sys icall handler triggered wacache_trigger_handler { script wacache_script subscriptions { messages { event-name wacache } } } Notes on Testing Add this command to your arsenal - tmsh generate sys icall event <event-name> context none</event-name> where event-name in my case is wacache. This allows you to troubleshoot the handler and script without worrying about the trigger. And this one - tmsh modify sys db log.evrouted.level value Debug. Just note that the default is Notice when you're all done troubleshooting.1.5KViews0likes6CommentsClient Cert Fingerprint Matching via iRules
Client cert authentication is not a new concept on DevCentral, it’s something that has been covered before in the forums, wikis and Tech Tips. Generally speaking it means that you’re receiving a request from a client, and want to authenticate them, as is often the case. Rather than asking for a userID and password, though, you’re requesting a certificate that only authorized clients should have access to. In this way you’re able to allow seamless access to a resource without forcing a challenge response for the user or application, but still ensuring security is enforced. That’s the short version. So that’s cert authentication, but what is a cert fingerprint? A cert fingerprint is exactly what it sounds like, a unique identifier for a particular certificate. In essence it’s a shorter way to identify a given certificate without having the entirety of the cert. A fingerprint is created by taking a digest of the entire DER encoded certificate and hashing it in MD5 or SHA-1 format. Fingerprints are often represented as hex strings to be more human readable. The process looks something like this: Command: openssl x509 -in cert.pem -noout –fingerprint Output: 3D:95:34:51:24:66:33:B9:D2:40:99:C0:C1:17:0B:D1 This can be useful in many cases, especially when wanting to store a list of viable certificates without storing the entirety of the certs themselves. Say, for instance, you want to enable client cert authentication wherein a user connects to your application and both client and server present certificates. The authentication process would happen normally and assuming all checked out access would be granted to the connecting user. What if, however, you only wanted to allow clients with a certain list of certs access? Sure you could store the entire client certificate in a database somewhere and do a full comparison each time a request is made, but that’s both a bit of a security issue by having the individual client certificates stored in the auth DB itself, and a hassle. A simpler method for limiting which certs to allow would be to store the fingerprints instead. Since the fingerprints are unique to the certificate they represent, you can use them to enforce a limitation on which client certificates to allow access to given portions of your application. Why do I bring this up? Obviously there’s an iRule for that. Credit for this example goes to one of our outstanding Field Engineers out of Australia, Cameron Jenkins. Cameron ended up whipping together an iRule to solve this exact problem for a customer and was kind enough to share the info with us here at DevCentral. Below is a sanitized version of said iRule: 1: when CLIENTSSL_HANDSHAKE { 2: set subject_dn [X509::subject [SSL::cert 0]] 3: set cert_hash [X509::hash [SSL::cert 0]] 4: set cSSLSubject [findstr $subject_dn "CN=" 0 ","] 5: 6: log local0. "Subject = $subject_dn, Hash = $cert_hash and $cSSLSubject" 7: 8: #Check if the client certificate contains the correct CN and Thumbprint from the list 9: set Expected_hash [class lookup $cSSLSubject mythumbprints] 10: 11: if { $Expected_hash != $cert_hash } { 12: log local0. "Thumbprint presented doesn't match mythumbprints. Expected Hash = $Expected_hash, Hash received = $cert_hash" 13: reject 14: } 15: } As you can see the iRule is quite reasonable for performing such a complex task. Effectively what’s happening here is we’re storing the relevent data, the Cert’s subject and fingerprint, or hash, as it’s referred to in our X509 commands, in local variables. Then we’re performing a class lookup against a data group that’s filled with all of the valid fingerprints that we want to have access to our application. We’re using the subject to perform the lookup, and the result will be what we expect the fingerprint of that certificate to be, based on the subject supplied. Then, if that expected hash doesn’t match the actual hash presented by the client, we reject the connection, thereby enforcing access as desired. Related Articles Clientless FirePass Login via the command line using client ... 26 Short Topics about Security: Stats, Stories and Suggestions Configuring SSL Communcations with Apache SOAP > DevCentral > F5 ... Manipulating Header or Content Data > DevCentral > F5 DevCentral ... Add root CA to ca-bundle? - DevCentral - F5 DevCentral > Forums ...1.2KViews0likes1CommentAutomating Web App Deployments with Opscode Chef and iControl
Chef is a systems integration framework developed here in Seattle by Opscode. It provides a number of configuration management facilities for deploying systems rapidly and consistently. For instance, if you want 150 web servers configured identically (or even with variances), Chef can make that happen. It also curtails the urge to make “one-off” changes to individual hosts or to skip over checking those configuration changes into revision control. Chef will revert any changes made out-of-band upon its next convergence. As a former systems administrator with “OCD-like” tendencies, these features make me happy. We were introduced to the folks at Opscode through a mutual friend and we got to chatting about their products and ours. Eventually the topic of Ruby emerged (Chef is built on Ruby). We started tossing around ideas about how to use Ruby to make Chef and BIG-IP a big happy family. What if we could use Chef to automatically add our web servers to an LTM pool as they are built? Well, that’s exactly what we did. We wrote a Chef recipe to automatically add our nodes to our pool. We were able to combine this functionality with the Apache cookbook provided by the Opscode Community and create a role that handles all these actions simultaneously. Combine this with your PXE installation and you’ve got a highly efficient system for building loads of web servers in a hurry. Chef Basics Chef consists of a number of different components, but we will deduce them collectively to the Chef server, Chef client, and knife, the command-line tool. Chef also provides access to configurations via a management console (web interface) that provides all the functionality of knife in a GUI, but I prefer the command-line, so that’s what we’ll be covering. Chef uses cookbooks of recipes to perform automated actions against its nodes (clients). The recipe houses the logic for how resources (pre-defined and user-defined) should perform actions against the nodes. A few of the more common resources are file, package, cron, execute, and Ruby block. We could define a resource for anything though and that is what makes Chef so powerful: its extensibility. Using recipes and resources we can perform sweeping changes to system, but they aren’t very “personal” at this point. That is where attributes come into play. Attributes define the node specific settings that are “personalize” the recipe for that node or class of nodes. Once we have cookbooks to support our node configurations, we can group those recipes into roles. For instance we might want to build a “base_server” role that should be applied to all of my servers regardless of their specialized purpose. This “base_server” role might include recipes for installing and configuring OpenSSH, NTP, and VIM. We would then create a “web_server” role that installs and configure Apache and Tomcat. Our “database_server” role would install MySQL and load my default database. If we wanted to take this a step further, we could organize these roles into environments, so that we could rapidly deploy development, staging, and production servers. This makes building up and tearing down environments very efficient. That was a very short introduction to Chef and its features. For more information on the basics of Chef, check out this Opscode wiki entry. Chef meets F5’s Ruby iControl Library Now that we’ve got a fair number of web servers built with our “web_server” role, we need them to start serving traffic. We could go to our LTM and add them all manually, but that wouldn’t be any fun would it? Wouldn’t it be cool if we could somehow auto-populate our LTM pool with our new web servers? This is where things get cool. We created a Chef cookbook called “f5-node-initiator” that we can add to our server roles. Whenever the node receives this recipe, it will automatically install our f5-icontrol gem, copy an “f5-node-initiator” script to /usr/local/bin/, and add the node to the LTM defined in attributes section of the server’s role. Chef Installation The installation of Chef server and it constituents is a topic beyond the scope of this article. The Opscode folks have assembled a great quick start guide, which they update regularly. We followed this guide and had no trouble getting things up and running. Using Ubuntu 10.04 LTS, the install was exceptionally easy using Aptitude (apt-get) to install the chef-server and chef packages on the Chef server and client(s), respectively. After installing the packages, we cloned the Chef sample repository, copied our user keys to the ~/.chef/ directory (covered in the quick start guide), created a knife.rb configuration file in .chef (also in quick start), finally we filled in the values in ~/chef-repo/config/rake.rb. I would encourage everyone to read the quick start guide as well as a few others here and here. Note: Our environment was Ubuntu 10.04 LTS server installs running on a VMWare ESXi box (Intel Core i7 with 8GB of RAM). This was more than enough to run a Chef server, 10 nodes, an F5 LTM VE instance, as well a few other virtual machines. The f5-node-initiator Cookbook The “f5-node-initiator” cookbook (recipe can be used interchangeably here as the cookbook only contains one recipe) is relatively simple compared to some of the examples I encountered while demoing Chef. Let’s look at the directory structure: f5-node-initiator (dir) |--> attributes (dir) |--> default.rb – contains default attribute values |--> files (dir) |--> default (dir) |--> f5-icontrol-10.2.0.2.gem – F5 Ruby iControl Library |--> f5-node-initiator – script to add nodes to BIG-IP pool; source in Codeshare |--> recipes (dir) |--> default.rb – core logic of recipe |--> metadata.rb – information about author, recipe version, recipe license, etc. |--> README.rdoc – README document with description, requirements, usage, etc. That’s it. Our recipe contains 4 directories and 6 files. If we did our job in creating this cookbook, you shouldn’t need to modify anything within it. We should be able to change the default attributes in our role or our node definition to enact any changes to the defaults. Installing the Cookbook Download the f5-node-initiator cookbook: f5-node-initiator.tgz Untar it into your chef-repo/cookbooks/ directory tar -C ~/chef-repo/cookbooks/. -zxvf f5-node-initiator.tgz Add the new cookbook to your Git repository git commit -a -m "Adding f5-node-initiator cookbook" Install the cookbook on the Chef server rake install Ensure that the cookbook is installed and available on the Chef server knife cookbook list The “web_server” Role Once we have our cookbook uploaded to our server, we need to assign it to our “web_server” role in order to get it to do anything. In this example, we are going to install and configure Apache, mod_php for Apache, and the f5-node-initiator. Here are the steps to create this role: Create a file called “web_server.rb” in ~/chef-repo/roles/ vi ~/chef-repo/roles/web_server.rb Add the following contents to the “web_server.rb” role file name "web_server" description "Common web server configuration" run_list( "recipe[apache2]", "recipe[f5-node-initiator]" ) default_attributes( "bigip" => { "address" => "10.0.0.245", "user" => "admin", "pass" => "admin", "pool_name" => "chef_test_http_pool" } ) Note: Don't forget to create the targret HTTP pool on the LTM. If there isn't a pool to add the nodes to, the f5-node-initiator recipe will fail. Add the role to your Git and commit it to the repository git add web_server.rb git commit -m "Adding web_server role" Install the "web_server" role rake install Applying the “web_server” role to a node The f5-node-initiator cookbook is now in place and the recipe has been added to our “web_server” role. We will now take the role and apply it to our new node, which we’ll call “web-001”. At the conclusion of this section, if everything goes as planned, we should have a web server running Apache and serving traffic as a pool member of our LTM. Let’s walk through the steps of adding the role to our node: Add the “web_server” role to the node’s run_list knife node run_list add web-001 "role[webserver]" Manually kick-off convergence on the node ssh root@web-001 root@web-001:~# chef-client Note: Convergence happens by default automatically every 30 minutes, but it is best to test at least one node to ensure things are working as expected. Watch the output to ensure that everything runs successfully [Fri, 08 Jul 2011 11:17:21 -0700] INFO: Starting Chef Run (Version 0.9.16) [Fri, 08 Jul 2011 11:17:24 -0700] INFO: Installing package[apache2] version 2.2.14-5ubuntu8.4 [Fri, 08 Jul 2011 11:17:29 -0700] INFO: Installing gem_package[f5-icontrol] version 10.2.0.2 [Fri, 08 Jul 2011 11:17:38 -0700] INFO: gem_package[f5-icontrol] sending run action to execute[f5-node-initiator] (immediate) [Fri, 08 Jul 2011 11:17:40 -0700] INFO: Ran execute[f5-node-initiator] successfully [Fri, 08 Jul 2011 11:17:40 -0700] INFO: Chef Run complete in 18.90055 seconds [Fri, 08 Jul 2011 11:17:40 -0700] INFO: cleaning the checksum cache [Fri, 08 Jul 2011 11:17:40 -0700] INFO: Running report handlers [Fri, 08 Jul 2011 11:17:40 -0700] INFO: Report handlers complete Verify that the node was added to the “chef_test_http_pool” on our LTM Conclusion This example used a web server as the example, but the role and attributes could be easily modified to support any number of systems and protocols. If you can pass traffic through a BIG-IP and create a pool for it, then you should be able to use the f5-node-initiator cookbook to automate additions of those nodes to the LTM pool. Give it a shot with SMTP, SIP, etc. and let us know how it goes. Chef and iControl are both incredibly powerful and versatile tools. When combined, they can perform a number of labor-intensive tasks almost effortlessly. The initial configuration of Chef may seem like a lot of work, but it will save you work in the long run. Starting with a good foundation can make large projects later on seem much more approachable. Trust us, it is worth it. Until next time, keep automating!1.2KViews0likes8Comments