Intro to Load Balancing for Developers – The Algorithms
If you’re new to this series, you can find the complete list of articles in the series on my personal page here If you are writing applications to sit behind a Load Balancer, it behooves you to at least have a clue what the algorithm your load balancer uses is about. We’re taking this week’s installment to just chat about the most common algorithms and give a plain- programmer description of how they work. While historically the algorithm chosen is both beyond the developers’ control, you’re the one that has to deal with performance problems, so you should know what is happening in the application’s ecosystem, not just in the application. Anything that can slow your application down or introduce errors is something worth having reviewed. For algorithms supported by the BIG-IP, the text here is paraphrased/modified versions of the help text associated with the Pool Member tab of the BIG-IP UI. If they wrote a good description and all I needed to do was programmer-ize it, then I used it. For algorithms not supported by the BIG-IP I wrote from scratch. Note that there are many, many more algorithms out there, but as you read through here you’ll see why these (or minor variants of them) are the ones you’ll see the most. Plain Programmer Description: Is not intended to say anything about the way any particular dev team at F5 or any other company writes these algorithms, they’re just an attempt to put the process into terms that are easier for someone with a programming background to understand. Hopefully a successful attempt. Interestingly enough, I’ve pared down what BIG-IP supports to a subset. That means that F5 employees and aficionados will be going “But you didn’t mention…!” and non-F5 employees will likely say “But there’s the Chi-Squared Algorithm…!” (no, chi-squared is theoretical distribution method I know of because it was presented as a proof for testing the randomness of a 20 sided die, ages ago in Dragon Magazine). The point being that I tried to stick to a group that builds on each other in some connected fashion. So send me hate mail… I’m good. Unless you can say more than 2-5% of the world’s load balancers are running the algorithm, I won’t consider that I missed something important. The point is to give developers and software architects a familiarity with core algorithms, not to build the worlds most complete lexicon of algorithms. Random: This load balancing method randomly distributes load across the servers available, picking one via random number generation and sending the current connection to it. While it is available on many load balancing products, its usefulness is questionable except where uptime is concerned – and then only if you detect down machines. Plain Programmer Description: The system builds an array of Servers being load balanced, and uses the random number generator to determine who gets the next connection… Far from an elegant solution, and most often found in large software packages that have thrown load balancing in as a feature. Round Robin: Round Robin passes each new connection request to the next server in line, eventually distributing connections evenly across the array of machines being load balanced. Round Robin works well in most configurations, but could be better if the equipment that you are load balancing is not roughly equal in processing speed, connection speed, and/or memory. Plain Programmer Description: The system builds a standard circular queue and walks through it, sending one request to each machine before getting to the start of the queue and doing it again. While I’ve never seen the code (or actual load balancer code for any of these for that matter), we’ve all written this queue with the modulus function before. In school if nowhere else. Weighted Round Robin (called Ratio on the BIG-IP): With this method, the number of connections that each machine receives over time is proportionate to a ratio weight you define for each machine. This is an improvement over Round Robin because you can say “Machine 3 can handle 2x the load of machines 1 and 2”, and the load balancer will send two requests to machine #3 for each request to the others. Plain Programmer Description: The simplest way to explain for this one is that the system makes multiple entries in the Round Robin circular queue for servers with larger ratios. So if you set ratios at 3:2:1:1 for your four servers, that’s what the queue would look like – 3 entries for the first server, two for the second, one each for the third and fourth. In this version, the weights are set when the load balancing is configured for your application and never change, so the system will just keep looping through that circular queue. Different vendors use different weighting systems – whole numbers, decimals that must total 1.0 (100%), etc. but this is an implementation detail, they all end up in a circular queue style layout with more entries for larger ratings. Dynamic Round Robin (Called Dynamic Ratio on the BIG-IP): is similar to Weighted Round Robin, however, weights are based on continuous monitoring of the servers and are therefore continually changing. This is a dynamic load balancing method, distributing connections based on various aspects of real-time server performance analysis, such as the current number of connections per node or the fastest node response time. This Application Delivery Controller method is rarely available in a simple load balancer. Plain Programmer Description: If you think of Weighted Round Robin where the circular queue is rebuilt with new (dynamic) weights whenever it has been fully traversed, you’ll be dead-on. Fastest: The Fastest method passes a new connection based on the fastest response time of all servers. This method may be particularly useful in environments where servers are distributed across different logical networks. On the BIG-IP, only servers that are active will be selected. Plain Programmer Description: The load balancer looks at the response time of each attached server and chooses the one with the best response time. This is pretty straight-forward, but can lead to congestion because response time right now won’t necessarily be response time in 1 second or two seconds. Since connections are generally going through the load balancer, this algorithm is a lot easier to implement than you might think, as long as the numbers are kept up to date whenever a response comes through. These next three I use the BIG-IP name for. They are variants of a generalized algorithm sometimes called Long Term Resource Monitoring. Least Connections: With this method, the system passes a new connection to the server that has the least number of current connections. Least Connections methods work best in environments where the servers or other equipment you are load balancing have similar capabilities. This is a dynamic load balancing method, distributing connections based on various aspects of real-time server performance analysis, such as the current number of connections per node or the fastest node response time. This Application Delivery Controller method is rarely available in a simple load balancer. Plain Programmer Description: This algorithm just keeps track of the number of connections attached to each server, and selects the one with the smallest number to receive the connection. Like fastest, this can cause congestion when the connections are all of different durations – like if one is loading a plain HTML page and another is running a JSP with a ton of database lookups. Connection counting just doesn’t account for that scenario very well. Observed: The Observed method uses a combination of the logic used in the Least Connections and Fastest algorithms to load balance connections to servers being load-balanced. With this method, servers are ranked based on a combination of the number of current connections and the response time. Servers that have a better balance of fewest connections and fastest response time receive a greater proportion of the connections. This Application Delivery Controller method is rarely available in a simple load balancer. Plain Programmer Description: This algorithm tries to merge Fastest and Least Connections, which does make it more appealing than either one of the above than alone. In this case, an array is built with the information indicated (how weighting is done will vary, and I don’t know even for F5, let alone our competitors), and the element with the highest value is chosen to receive the connection. This somewhat counters the weaknesses of both of the original algorithms, but does not account for when a server is about to be overloaded – like when three requests to that query-heavy JSP have just been submitted, but not yet hit the heavy work. Predictive: The Predictive method uses the ranking method used by the Observed method, however, with the Predictive method, the system analyzes the trend of the ranking over time, determining whether a servers performance is currently improving or declining. The servers in the specified pool with better performance rankings that are currently improving, rather than declining, receive a higher proportion of the connections. The Predictive methods work well in any environment. This Application Delivery Controller method is rarely available in a simple load balancer. Plain Programmer Description: This method attempts to fix the one problem with Observed by watching what is happening with the server. If its response time has started going down, it is less likely to receive the packet. Again, no idea what the weightings are, but an array is built and the most desirable is chosen. You can see with some of these algorithms that persistent connections would cause problems. Like Round Robin, if the connections persist to a server for as long as the user session is working, some servers will build a backlog of persistent connections that slow their response time. The Long Term Resource Monitoring algorithms are the best choice if you have a significant number of persistent connections. Fastest works okay in this scenario also if you don’t have access to any of the dynamic solutions. That’s it for this week, next week we’ll start talking specifically about Application Delivery Controllers and what they offer – which is a whole lot – that can help your application in a variety of ways. Until then! Don.19KViews1like9Comments
The Concise Guide to Proxies
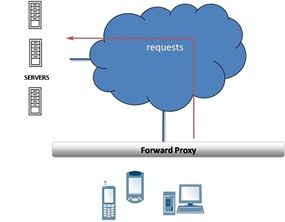
We often mention that the benefits derived from some application delivery controllers are due to the nature of being a full proxy. And in the same breath we might mention reverse, half, and forward proxies, which makes the technology sound more like a description of the positions on a sports team than an application delivery solution. So what does these terms really mean? Here's the lowdown on the different kinds of proxies in one concise guide. PROXIES Proxies (often called intermediaries in the SOA world) are hardware or software solutions that sit between the client and the server and do something to requests and sometimes responses. The most often heard use of the term proxy is in conjunction with anonymizing Web surfing. That's because proxies sit between your browser and your desired destination and proxy the connection; that is you talk to the proxy while the proxy talks to the web server and neither you nor the web server know about each other. Proxies are not all the same. Some are half proxies, some are full proxies; some are forward and some are reverse. Yes, that came excruciatingly close to sounding like a Dr. Seuss book. (Go ahead, you know you want to. You may even remember this from .. .well, when it was first circulated.) FORWARD PROXIES Forward proxies are probably the most well known of all proxies, primarily because most folks have dealt with them either directly or indirectly. Forward proxies are those proxies that sit between two networks, usually a private internal network and the public Internet. Forward proxies have also traditionally been employed by large service providers as a bridge between their isolated network of subscribers and the public Internet, such as CompuServe and AOL in days gone by. These are often referred to as "mega-proxies" because they managed such high volumes of traffic. Forward proxies are generally HTTP (Web) proxies that provide a number of services but primarily focus on web content filtering and caching services. These forward proxies often include authentication and authorization as a part of their product to provide more control over access to public content. If you've ever gotten a web page that says "Your request has been denied by blah blah blah. If you think this is an error please contact the help desk/your administrator" then you've probably used a forward proxy. REVERSE PROXIES A reverse proxy is less well known, generally because we don't use the term anymore to describe products used as such. Load balancers (application delivery controllers) and caches are good examples of reverse proxies. Reverse proxies sit in front of web and application servers and process requests for applications and content coming in from the public Internet to the internal, private network. This is the primary reason for the appellation "reverse" proxy - to differentiate it from a proxy that handles outbound requests. Reverse proxies are also generally focused on HTTP but in recent years have expanded to include a number of other protocols commonly used on the web such as streaming audio (RTSP), file transfers (FTP), and generally any application protocol capable of being delivered via UDP or TCP. HALF PROXIES Half-proxy is a description of the way in which a proxy, reverse or forward, handles connections. There are two uses of the term half-proxy: one describing a deployment configuration that affects the way connections are handled and one that describes simply the difference between a first and subsequent connections. The deployment focused definition of half-proxy is associated with a direct server return (DSR) configuration. Requests are proxied by the device, but the responses do not return through the device, but rather are sent directly to the client. For some types of data - particularly streaming protocols - this configuration results in improved performance. This configuration is known as a half-proxy because only half the connection (incoming) is proxied while the other half, the response, is not. The second use of the term "half-proxy" describes a solution in which the proxy performs what is known as delayed binding in order to provide additional functionality. This allows the proxy to examine the request before determining where to send it. Once the proxy determines where to route the request, the connection between the client and the server are "stitched" together. This is referred to as a half-proxy because the initial TCP handshaking and first requests are proxied by the solution, but subsequently forwarded without interception. Half proxies can look at incoming requests in order to determine where the connection should be sent and can even use techniques to perform layer 7 inspection, but they are rarely capable of examining the responses. Almost all half-proxies fall into the category of reverse proxies. FULL PROXIES Full proxy is also a description of the way in which a proxy, reverse or forward, handles connections. A full proxy maintains two separate connections - one between itself and the client and one between itself and the destination server. A full proxy completely understands the protocols, and is itself an endpoint and an originator for the protocols. Full proxies are named because they completely proxy connections - incoming and outgoing. Because the full proxy is an actual protocol endpoint, it must fully implement the protocols as both a client and a server (a packet-based design does not). This also means the full proxy can have its own TCP connection behavior, such as buffering, retransmits, and TCP options. With a full proxy, each connection is unique; each can have its own TCP connection behavior. This means that a client connecting to the full proxy device would likely have different connection behavior than the full proxy might use for communicating with servers. Full proxies can look at incoming requests and outbound responses and can manipulate both if the solution allows it. Many reverse and forward proxies use a full proxy model today. There is no guarantee that a given solution is a full proxy, so you should always ask your solution provider if it is important to you that the solution is a full proxy.4KViews2likes12Comments6 Reasons You Need an Application Delivery Controller Now
Application delivery controllers, and load balancing in general, are often seen as solutions waiting for a problem to solve. We know what those problems are, but until we experience them we often don't feel a sense of urgency in acquiring and deploying an application delivery controller. While it's certainly true that an application delivery controller can solve many problems that arise, it's also true that there are benefits to acquiring and deploying an application delivery controller before it becomes absolutely necessary in order to save your application, your site, or your job. So here are six good reasons to consider deploying an application delivery controller now rather than waiting until the next emergency. 6. Efficiency An application delivery controller (ADC) can improve the efficiency of the servers for which it manages application requests. By offloading compute intensive processing like SSL or TCP/IP connection management an ADC reduces the overhead associated with assembling and serving responses to application requests and makes better use of the resources (RAM, CPU, I/O) on each server. Making your infrastructure more efficient is also a great way to "go green". 5. Performance The performance of your applications can be improved dramatically through the deployment of an ADC. Whether it's because of compression, caching, protocol optimizations, connection management or intelligent load balancing algorithms, an ADC improves the overall performance of your applications. 4. Reliability If you rely on applications for business processes or as a revenue stream, the last thing you want is for those application to be unavailable. An ADC provides reliability by ensuring that requests are sent only to available servers, redirecting requests when a server is down for maintenance or finally hit the wall and died. If you're large enough to have two data centers, an ADC with global load balancing capabilities furthers assurance of reliability by redirecting requests from the primary data center to a secondary in the event of a disaster - whether that's a natural disaster (earthquake, fire, flood) or man-made (oops - was that our DS3 I just ripped out?). 3. Security We're not talking about advanced security options like web application firewalls or secure remote access products such as an SSL VPN, we're just talking basic security here. DDoS protection, rate limiting, blacklisting, whitelisting, authentication, resource obfuscation, SSL, content encryption - the bare minimum security you need to protect your applications and the servers on which they're deployed. An ADC provides the core security functions you need to ensure your site is safe. 2. Capacity Capacity is about how much throughput, how many requests, how many users you can support. It's nearly impossible to support thousands of concurrent users with a single server, unless it's one really really really big server. You need more than one server, and in order to architect a solution that uses a pool of servers you need something to mediate and direct those requests - to balance the load across those servers. That means you need an ADC, because the core purpose of an ADC is to perform load balancing and ensure that you can serve everyone who wants to be served. 1. Scalability Scaling up to meet demand is difficult, doing so without re-architecting your infrastructure or scheduling down-time is even more difficult. By including an ADC in your architecture from the very beginning, the process becomes a simple one. Add a new server, add it to the ADC and voila! You've just scaled up and can instantly support more users and more requests without requiring downtime or moving around network cables. Imbibing: Mountain Dew791Views0likes0CommentsIs it time for a new Enterprise Architect?
After a short break to get some major dental rework done, I return to you with my new, sore mouth for a round of “Maybe we should have…” discussions. In the nineties and early 21st century, positions were created in may organizations with titles like “chief architect” and often there was a group whose title were something like “IT Architect”. These people made decisions that impacted one or all subsidiaries of an organization, trying to bring standardization to systems that had grown organically and were terribly complex. They ushered in standards, shared code between disparate groups, made sure that AppDev and Network Ops and Systems Admins were all involved in projects that touched their areas. The work they did was important to the organization, and truly different than what had come before. Just like in the 20th century the concept of a “Commander of Army Group” became necessary because the armies being fielded were so large that you needed an overall commander to make sure the pieces were working together, the architect was there (albeit with far less power than an Army Group commander) to make sure all the pieces fit together. Through virtualization, they managed to keep the ball rolling, and direct things such that a commitment to virtualization was applied everywhere it made sense. Organizations without this role did much the same, but those with this role had a person responsible for making sure things moved along as smoothly as a major architecture change that impacts users, systems, apps, and networks can. Steve Martin in Little Shop of Horrors I worked on an enterprise architecture team for several years in the late 90s, and the work was definitely challenging, and often frustrating, but was a role (at least at the insurer I worked for) that had an impact on cutting waste out of IT and building a robust architecture in apps, systems, and networks. The problem was that network and security staff were always a bit distanced from architecture. A couple of companies whose architects I hung out with (Southwestern Bell comes to mind) had managed to drive deep into the decision making process for all facets of IT, but most of us were left with systems and applications being primary and having to go schmooze and beg to get influence in the network or security groups. Often we were seen as outsiders telling them what to do, which wasn’t the case at all. For the team we were on, if one subsidiary had a rocking security bit, we wanted it shared across the other subsidiaries so they would all benefit from this work the organization had already paid for. It was tough work, and some days you went home feeling as if you’d accomplished nothing. But when it all came together, it was a great job to have. You saw almost every project the organization was working on, you got to influence their decisions, and you got to see the project implemented. It was a fun time. Now, we face a scenario in networking and network architecture that is very similar to that faced by applications back then. We have to make increasingly complex networking decisions about storage, app deployment, load distribution, and availability. And security plays a critical role in all of these choices because if your platform is not secure, none of the applications running on it are. We use the term “Network architecture” a lot, and some of us even use it to describe all the possibilities – Internal, SaaS providers, cross-datacenter WAN, the various cloud application/platform providers, and cloud storage… But maybe it is time to create a position that can juggle all of these balls and get applications to the right place. This person could work with business units to determine needs, provide them with options about deployment that stress strengths and weaknesses in terms of their application, and make sure that each application lives in a “happy place” where all of its needs are met, and the organization is served by the locality. We here at F5, along with many other infrastructure vendors, are increasingly offering virtual versions of our products, in our case the goal is to allow you to extend the impact of our market leading ADC and File Virtualization appliances to virtualized and cloud environments. I won’t speak for other vendors about why they’re doing it, each has a tale to tell that I wouldn’t do justice to. But the point of this blog is that all of these options… In the cloud, or reserve capacity in the cloud? What impact does putting this application in the cloud have on WAN bandwidth? Can we extend our application firewall security functionality to protect this application if it is sent out to the cloud? Would an internal virtualized deployment be a better fit for the volume of in-datacenter database accesses that this particular application makes? Can we run this application from multiple datacenters and share the backend systems somehow, and if so what is the cost? These are the exact types of questions that a dedicated architect, specialized in deployment models, could ask and dig to find the answers to. It would be just like the other architecture team members, but more focused on getting the most out of where an application is deployed and minimizing the impacts of choices one application team makes upon everyone else. I think it’s time. A network architect worries mostly about the internal network, and perhaps some of the items above, we should use a different title. I know it’s been abused in the past, but extranet architect might be a good title. Since they would need to increasingly be able to interface with business units and explain choices and impacts, I think I prefer application locality architect… But that makes light of some of the more technical aspects of the job, like setting up load balancing in a cloud – or at least seeing to it that someone is. Like other architecture jobs, it would be a job of influence, not command. The role is to find the best solution given the parameters of the problem, and then sell the decision makers on why they are the right choice. But that role works well for all the other enterprise architect jobs, just takes a certain type of personality to get it done. Nothing new there, so knowledge of all of the options available would become the largest requirement… How costs of a cloud deployment at vendor X compare to costs of virtual deployment, what the impact of cloud-based applications are on the WAN (given application parameters of course), etc. There are a ton of really smart people in IT, so finding someone capable of digesting and utilizing all of that information may be easier than finding someone who can put up with “You may have the right solution, but for political reasons, we’re going to do this really dumb thing instead” with equanimity. And for those of you who already have a virtualization or cloud architect… Well that’s just a bit limiting if you have multiple platform choices and multiple deployment avenues. Just like there were application architects and enterprise architecture used their services, so would it be with this role and those specialized architects.286Views0likes1CommentCloud Computing and Infrastructure 2.0
Not every infrastructure vendor needs new capabilities to support cloud computing and infrastructure 2.0. Greg Ness of Infoblox has an excellent article on "The Next Tech Boom: Infrastructure 2.0" that is showing up everywhere. That's because it raises some interesting questions and points out some real problems that will be need to be addressed as we move further into cloud computing and virtualized environments. What is really interesting, however, is the fact that some infrastructure vendors are already there and have been for quite some time. One thing Greg mentions that's not quite accurate (at least in the case of F5) is regarding the ability of "appliances" to "look inside servers (for other servers) or dynamically keep up with fluid meshes of hypervisors". From Greg's article: The appliances that have been deployed across the last thirty years simply were not architected to look inside servers (for other servers) or dynamically keep up with fluid meshes of hypervisors powering servers on and off on demand and moving them around with mouse clicks. Enterprises already incurring dis-economies of scale today will face sheer terror when trying to manage and secure the dynamic environments of tomorrow. Rising management costs will further compromise the economics of static network infrastructure. I must disagree. Not on the sheer terror statement, that's almost certainly true, but on the capabilities of infrastructure devices to handle a virtualized environment. Some appliances and network devices have long been able to look inside servers and dynamically keep up with the rapid changes occurring in a hypervisor-driven application infrastructure. We call one of those capabilities "intelligent health monitoring", for example, and others certainly have their own special name for a similar capability. On the dynamic front, when you combine an intelligent application delivery controller with the ability to be orchestrated from within applications or within the OS, you get the ability to dynamically modify configuration of application delivery in real-time based on current conditions within the data center. And if you're monitoring is intelligent enough, you can sense within seconds when an application - whether virtualized or not - has disappeared or conversely, when it's come back on line. F5 has been supporting this kind of dynamic, flexible application infrastructure for years. It's not really new except that its importance has suddenly skyrocketed due to exactly the scenario Greg points out using virtualization. WHAT ABOUT THE VIRTSEC PIECE? There has never been a better case for centralized web application security through a web application firewall and an application delivery controller. The application delivery controller - which necessarily sits between clients and those servers - provides security at layers 2 through 7. The full stack. There's nothing really that special about a virtualized environment as far as the architecture goes for delivering applications running on those virtual servers; the protocols are still the same, and the same vulnerabilities that have plagued non-virtualized applications will also plague virtualized ones. That means that existing solutions can address those vulnerabilities in either environment, or a mix. Add in a web application firewall to centralize application security and it really doesn't matter whether applications are going up and down like the stock market over the past week. By deploying the security at the edge, rather than within each application, you can let the application delivery controller manage the availability state of the application and concentrate on cleaning up and scanning requests for malicious content. Centralizing security for those applications - again, whether they are deployed on a "real" or "virtual" server - has a wealth of benefits including improving performance and reducing the very complexity Greg points out that makes information security folks reach for a valium. BUT THEY'RE DYNAMIC! Yes, yes they are. The assumption is that given the opportunity to move virtual images around that organizations will do so - and do so on a frequent basis. I think that assumption is likely a poor one for the enterprise and probably not nearly as willy nilly for cloud computing providers, either. Certainly there will some movement, some changes, but it's not likely to be every few minutes, as is often implied. Even if it was, some infrastructure is already prepared to deal with that dynamism. Dynamism is just another term for agility and makes the case well for loose-coupling of security and delivery with the applications living in the infrastructure. If we just apply the lessons we've learned from SOA to virtualization and cloud computing and 90% of the "Big Hairy Questions" can be answered by existing technology. We just may have to change our architectures a bit to adapt to these new computing models. Network infrastructure, specifically application delivery, has had to deal with applications coming online and going offline since their inception. It's the nature of applications to have outages, and application delivery infrastructure, at least, already deals with those situations. It's merely the frequency of those "outages" that is increasing, not the general concept. But what if they change IP addresses? That would indeed make things more complex. This requires even more intelligence but again, we've got that covered. While the functionality necessary to handle this kind of a scenario is not "out of the box" (yet) it is certainly not that difficult to implement if the infrastructure vendor provides the right kind of integration capability. Which most do already. Greg isn't wrong in his assertions. There are plenty of pieces of network infrastructure that need to take a look at these new environments and adjust how they deal with the dynamic nature of virtualization and cloud computing in general. But it's not all infrastructure that needs to "get up to speed". Some infrastructure has been ready for this scenario for years and it's just now that the application infrastructure and deployment models (SOA, cloud computing, virtualization) has actually caught up and made those features even more important to a successful application deployment. Application delivery in general has stayed ahead of the curve and is already well-suited to cloud computing and virtualized environments. So I guess some devices are already "Infrastructure 2.0" ready. I guess what we really need is a sticker to slap on the product that says so. Related Links Are you (and your infrastructure) ready for virtualization? Server virtualization versus server virtualization Automating scalability and high availability services The Three "Itys" of Cloud Computing 4 things you need in a cloud computing infrastructure267Views0likes3CommentsMaking Chili and Managing Network Resources.
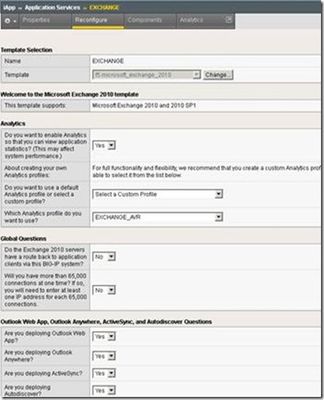
#f5 There’s a new brand of Chili in town. I don’t usually talk a lot about F5 specific solutions, but since we’re the only ones doing this (so far), the contents of this blog are F5 specific. Though this needs to be industry standard. So, you’re yearning for some chili. That’s understandable, this time of year is when those of us from the US midwest think of chili, because it’s good hunting season food, and it both fills you and warms you up. So grab a handful of hamburger and stuff it in your mouth, then grab a handful of dried kidney beans and stuff those in there too, no, don’t worry, we’re about to get to the cayenne pepper… No? Okay, okay, you want it to actually be mixed before it gets to your stomach. I suppose that’s understandable too. So toss a bunch of hamburger into a pot, throw in some dried kidney beans – don’t forget the water – some chili powder, some cayenne pepper, whatever other spices you like, some tomato sauce, that’ll about do it. Got all of that? Okay, so next you cook it. In all that other stuff, it’ll take a good long while for the hamburger to cook, but since we didn’t soak the beans, they’ll need a good long while anyway… What? That’s not it either? Okay then, last try. Brown up some hamburger, drain off the grease (or Juice as one of my best friends complains at this step), pour in some canned (or pre-soaked) kidney beans, some tomato sauce, some spices, and cook it up. What? Still not detailed enough? But I told you what to put into it, weren’t you reading? Oh heck, go to your nearest chili joint and just buy some. In Green Bay we go to Chili Johns. In Cincinnati it’s Skyline chili. But where ever, place the order and get well-made chili. I don’t have to tell you all of the steps, you don’t have to get worked up about grey areas in the directions, you get tasty chili, I can go get some too. Wouldn’t it be nice if that’s how it worked, and you didn’t have to pay for it? Now consider that you’re deploying your application behind an ADC. First you configure the Virtual IP, then you create a pool to service the Virtual IP, then you add nodes to the pool… What? I know. That’s been a problem with ADCs for a good long while. Lots of steps, all necessary, all with room for miscommunication or error. Not anymore. I’ll borrow a picture from coworker Karen Jester’s blog to illustrate the point: There’s more at the link to her blog above (click on her name), but the point is relatively simple. It used to be that you had to configure each of the networking/load balancing/security/app delivery/et cetera. elements of an application deployment separately. Notice in this screenshot that the questions are about the application and your deployment of it, not about nodes and pools. We have some excellent deployment guides, but they run to many pages, and since you’re copying information from a book or PDF, missing steps is possible. With iApps, that is no longer the case. iApps take an application-centric view of network resources. In essence, they’re Skyline Chili, but you don’t have to pay for them. They come free in V.11. And they know your apps. So if you need to deploy Exchange behind a BIG-IP, open the Exchange version X template, and fill in the few questions. Next thing you know, you’re running an ADC configuration with your requirements considered. No more individual items to configure. And you can modify the configuration at a later date to adapt to changes in your environment. Of course, if you’re an expert, you can still configure the individual elements, but if you want to utilize the power of an ADC, but don’t have time to go through each and every step in a deployment guide, now with knowledge of your application, you can get it running – secure, fast, and available – in short order. For those applications we don’t have a template for yet, you can build one, download one developed by a peer from F5 DevCentral, or configure the objects individually using one of our deployment guides. If you don’t already, I’d recommend reading Karen’s blog. She’s wicked smart, and in a location that gives her insight into F5 gear. And yes, I’d love to talk about how other vendors are turning app delivery into an application-focused tool, since in the end it is all about delivery of applications. But until they do, I’ll just keep telling you how cool iApps are. Oh and did I mention they give you an astounding look into overall application performance across the network? Yes, they do that too. It’s like the cheese on top of a bowl of Skyline Chili.247Views0likes0CommentsIs That An ACK In Your Packet, Or Are You Just Glad To See Me?
Every once in a while, I like to step back a bit and write for those who haven’t been in the field for a zillion years. For starters, it helps refresh the pool of information out there for people trying to research something they haven’t done before. It helps a lot that I enjoy sharing my knowledge, so writing such a blog is like “non-work”. Since I’m gearing up for some holiday time, this seemed like a great time to do just such an article, so I cast about and TCP optimizations came to mind. A lot has been written about TCP optimizations, this take will be for the beginner, and will cover them from the Application Delivery Controller (ADC) perspective. With a background in development, IT management, and storage, I had to learn this stuff the hard way, hopefully this helps some of you skip ahead a few squares in the “IT Learn Something New!” game. My knowledge leans heavily upon F5 gear, specifically BIG-IPLTM, but as usual, I try to stick to features and functionality common to ADCs. At least the big names in ADCs. One of the very cool bits about an ADC is that most act as a full proxy between the LAN and the WAN. This opens possibilities that would not normally exist in a standard network configuration. The ADC can ack to the server at server speed, while spooling to send to the client at client speed. In many cases, this single possibility helps performance by its mere existence. But there is much more going on in a modern ADC. If you’re interested in the deep-delve details along with RFC numbers to research, check out Optimizing WAN and LAN Application Performance With TCP Express on F5.com. It’s getting older (well over three years), and is F5-centric, but by including the RFC numbers, the author has left you room to research. For those who aren’t crazy about reading through RFCs, here are some highlights of what you can hope to get out of an ADC. As always, my knowledge is F5 centric, check with your vendor before assuming they’ve implemented all of these. All of these are turned on or configurable on a BIG-IP. Nagle’s Algorithm. This pools data until the receiver has ACK’d what has already been sent. By doing so, it sends less packets because it’s packing data waiting for ACKs. While this can make it appear that latency has increased, it does generally result in less packets on the wire. Dynamic Window Sizing (Including Slow Start). This adjusts the data window size to suit what’s on the other end. By doing so, the client can have one window size and the server another, each optimized to the network conditions it is seeing and the way its TCP stack is optimized. Normally the two would have to negotiate this to be the minimum. Adaptive Initial Congestion Windows and TCP Slow Start With Congestion Avoidance. These simply change how fast initial Slow Start is handled, so that some connections get to the proper window size quickly. Bandwidth Delay Control. An automatic calculation of how much data can be put into a link without overloading it. TCP Congestion Avoidance. A set of standards to avoid and recover from lost packets due to link congestion. Selective Acknowledgements and Limited and Fast Retransmits. When data is lost, this is a packet-based shorthand for recovery, cutting the time and retransmits required down. Connection pooling to servers. We draw an imaginary line in the sand and don’t call this a TCP optimization, but it really is – it creates less TCP overhead on your server by putting multiple clients into one connection. Normally the server would open one (or more) for each connection, an ADC, sitting in the middle, can “pool” these connections into one, saving your server from setting aside resources for each individual client. What does all of this mean? Well first off, these are not all of the possibilities, TCP has had a long history and lots of improvements have been suggested through the RFC system. Our engineers will likely grind their teeth that I distilled all of their hard work down to a few bullet points that don’t even cover all the possibilities. But the point is to help you understand why the simple act of putting an ADC into your network can improve application performance. If your server is communicating with the BIG-IP at its maximum speed, and the client is communicating with the BIG-IP at its maximum speed, things seem faster to the end user. Add in the ability to recover quickly on lossy networks, and the more remote the user, the more benefits they’ll see. That’s pretty cool. And it’s free with your ADC. How much of it is free with your ADC, and how well it is implemented is going to be vendor dependent, but much of this stuff has been out there for years, so ask your ADC vendor, I’d be surprised if they told you “yeah, we don’t do Nagle’s algorithm” or “Congestion Avoidance? Congestion helps your packets get tougher, why would we want to avoid it?” A modern ADC is a complex system. While implementing TCP and HTTP optimizations is a natural offshoot of what a load balancer does, it is certainly one of the hallmarks of an ADC that this offshoot has been incorporated into the product. I reiterate that this is simply a starting point. There is lots of good information out there about TCP optimizations (starting with that PDF linked to above), and you can get right to it if you need it. This was just a toe-dip into a very complex world. No doubt I have simplified to the point that some experts will think I’ve over-simplified. If it piqued your interest though, then I did not oversimplify at all. The answer to the title? If you have an ADC in your network, the answer is “Both”. That IS an ACK in your server’s packet, and since its workload is reduced, the server IS glad to see the ADC.233Views0likes1CommentAdvanced Load Balancing For Developers. The Network Dev Tool
It has been a while since I wrote an installment of Load Balancing for Developers, and now I think it has been too long, but never fear, this is the grad-daddy of Load Balancing for Developers blogs, covering a useful bit of information about Application Delivery Controllers that you might want to take advantage of. For those who have joined us since my last installment, feel free to check out the entire list of blog entries (along with related blog entries) here, though I assure you that this installment, like most of the others, does not require you to have read those that went before. ZapNGo! Is still a growing enterprise, now with several dozen complex applications and a high availability architecture that spans datacenters and the cloud. While the organization relies upon its web properties to generate revenue, those properties have been going along fine with your Application Delivery Controller (ADC) architecture. Now though, you’re seeing a need to centralize administration of a whole lot of functions. What worked fine separately for one or two applications is no longer working so well now that you have several development teams and several dozen applications, and you need to find a way to bring the growing inter-relationships under control before maintenance and hidden dependencies swamp you in a cascading mess of disruption. With maintenance taking a growing portion of your application development manhours, and a reasonably well positioned test environment configured with a virtual ADC to mimic your production environment, all you need now is a way to cut those maintenance manhours and reduce the amount of repetitive work required to create or update an application. Particularly update an application, because that is a constant problem, where creating is less frequent. With many of the threats that your ZapNGo application will be known as ZapNGone eliminated, now it is efficiencies you are after. And believe it or not, these too are available in an ADC. Not all ADC’s are created equal, but this discussion will stay on topics that most ADCs can handle, and I’ll mention it when I stray from generic into specific – which I will do in one case because only one vendor supports one of the tools you can use, but all of the others should be supported by whatever ADC vendor you have, though as always, check with your vendor directly first, since I’m not an expert in the inner workings of every one. There is a lot that many organizations do for themselves, and the array of possibilities is long – from implementing load balancing in source code to security checks in the application, the boundaries of what is expected of developers are shaped by an organization, its history, and its chosen future direction. At ZapNGo, the team has implemented a virtual test environment that as close as possible mirrors production, so that code can be implemented and tested in the way it will be used. They use an ADC for load balancing, so that they don’t have to rewrite the same code over and over, and they have a policy of utilizing a familiar subset of ADC functionality on all applications that face the public. The company is successful and growing, but as always happens in companies in that situation, the pressures upon them are changing just by virtue of their growth. There are more new people who don’t yet have intimate knowledge of the code base, network topology, security policies, whatever their area of expertise is. There are more lines of code to maintain, while new projects are being brought up at a more rapid pace and with higher priorities (I’ve twice lived through the “Everything is high priority? Well this is highest priority!” syndrome while working in IT. Thankfully, most companies grow out of that fast when it’s pointed out that if everything is priority #1, nothing is). Timelines to complete projects – be they new development, bug fixes, or enhancements are stretching longer and longer as the percentage of gurus in the company is down and the complexity of the code and the architecture it runs on is up. So what is a development manager to do to increase productivity? Teaming newer developers with people who’ve been around since the beginning is helping, but those seasoned developers are a smaller and smaller percentage of the workforce, while the volume of work has slowly removed them from some of the many products now under management. Adopting coding standards and standardized libraries helps increase experience portability between projects, but doesn’t do enough. Enter offloading to the ADC. Some things just don’t have to be done in code, and if they don’t have to be, at this stage in the company’s growth, IT management at ZapNGo (that’s you!) decides they won’t be. There just isn’t time for non-essential development anymore. Utilizing a policy management tool and/or an Application Firewall on the ADC can improve security without increasing the code base, for example. And that shaves hours off of maintenance projects, while standardizing on one or a few implementations that are simply selected on the ADC. Implementing Web Application Acceleration protocols on the ADC means that less in-code optimization has to occur. Performance is no longer purely the role of developers (but of course it is still a concern. No Web Application Acceleration tool can make a loop that runs for five minutes run faster), they can allow the Web Application Acceleration tool to shrink the amount of data being sent to the users’ browser for you. Utilizing a WAN Optimization ADC tool to improve the performance of bulk copies or backups to a remote datacenter or cloud storage… The list goes on and on. The key is that the ADC enables a lot of opportunities for App Dev to be more responsive to the needs of the organization by moving repetitive tasks to the ADC and standardizing them. And a heaping bonus is that it also does that for operations with a different subset of functionality, meaning one toolset gives both App Dev and Operations a bit more time out of their day for servicing important organizational needs. Some would say this is all part of DevOps, some would say it is not. I leave those discussions to others, all I care is that it can make your apps more secure, fast, and available, while cutting down on workload. And if your ADC supports an SSL VPN, your developers can work from home when necessary. Or more likely, if your code is your IP, a subset of your developers can. Making ZapNGo more responsive, easier to maintain, and more adaptable to the changes coming next week/month/year. That’s what ADCs do. And they’re pretty darned good at it. That brings us to the one bit that I have to caveat with F5 only, and that is iApps. An iApp is a constructed configuration tool that asks a few questions and then deploys all the bits necessary to set up an ADC for a particular application. Why do I mention it here? Well if you have dozens of applications with similar characteristics, you can create an iApp Template and use it to rapidly bring new applications or new instances of applications online. And since it is abstracted, these iApp templates can be designed such that AppDev, or even the business owner, is able to operate them Meaning less time worrying about what network resources will be available, how they’re configured, and waiting for operations to have time to implement them (in an advanced ADC that is being utilized to its maximum in a complex application environment, this can be hundreds of networking objects to configure – all encapsulated into a form). Less time on the project timeline, more time for the next project. Or for the post deployment party. One of the two. That’s it for the F5 only bit. And knowing that all of these items are standardized means less things to get mis-configured, more surety that it will all work right the first time. As with all of these articles, that offers you the most important benefit… A good night’s sleep.231Views0likes0CommentsGotta Catch Em All. Multiple bottlenecks are a part of the IT lifestyle
My older children, like most kids in their age group, all played with or collected Pokemon cards. Just like I and all of my friends had GI Joes and discussed the strengths and weaknesses of Kung-fu grip versus hard hands, they and all of their friends sat around talking about how much cooler their current favorite Pokemon card was compared to all of the others. We let them play and kept an eye on how cards were being passed about the group (they’re small and tend to walk off, so we patrolled a bit, but otherwise stayed out of the way). And the interesting thing about Pokemon – or any other Collectible Card Game – is that as soon as you’ve settled your discussion about which card is “best”, someone picks a new favorite so you can rehash all the same issues with this new card in the mix. People – mostly but not exclusively children - honestly spend hours at this pass-time, and every time they resolve the differences, it starts all over again. The point of Pokemon is to catch and train little creatures (build a deck of cards) that will, on your command, battle other little creatures (the other players’ card deck) for supremacy. But that’s often lost in the discussions of which individual card or small combinations of cards is “best”. Everyone has their favorites and a focused direction, so these conversations can grow quite heated. It is no mistake that I’m discussing Pokemon in an IT blog. Our role is to support the business with applications that will allow them to do their job, or do their job better, or do things the competition can’t do. That’s why we’re here. But everyone in IT has a focus and direction – Developer, Architect, Network Admin, Systems Admin, Storage Admin, Business Analyst… The list goes on – and sometimes our conversations about how to best serve the business get quite heated. More importantly, sometimes the point of IT – to support the business – gets lost in examining the minutiae, just like comparing two Pokemon cards when there are hundreds of cards to build decks from. There are a few – like Charizard pictured here – that are special until they’re superseded by even cooler cards. But a lot of what we do is written in stone, and is easily lost in the shuffle. Just as no one champions the basic “energy” cards in Pokemon – because they don’t DO anything by themselves – we often don’t discuss some of the basic issues IT always has and always will struggle with, because they’re known, set in stone, and should be self-evident. Or at least we think they should. So I’ll remind you of one of the basics, and perhaps that will spur you to keep the simple stuff in mind whilst arguing over the coolest new toy in the datacenter. Image courtesy of Pokebeach.com The item I’ve chosen? There is never one bottleneck. It is a truth. If you find and eliminate the performance bottleneck of your application, you have not resolved all problems, you have simply removed a roadblock on the way to the next bottleneck. A system that ran fine last week may not be running fine this week because a new bottleneck threshold has been hit. And the bottlenecks are always – always inter-related. (Warning – of course I reference F5 products in this list, if you have other vendors, insert their names) Consider this, your web app is having performance problems, and you track it down to your network card utilization. So you upgrade the server or throw it behind your BIG-IP (or other ADC or a load balancer), and the problem is resolved. So now your CPU utilization is fine, but the application’s performance degrades again relatively quickly. You go researching and discover that your new bottleneck is storage. Too many high-access files on a single NAS device is slowing down simple file reads and writes. So you move your web servers to use a different NAS device (downright simple if you have ARX in-house, not too terribly difficult if you don’t), and a couple of weeks later users are complaining again. You dig and research, and all seems well to you, but there are enough complaints that you are pretty certain there’s a problem. So you call up a coworker in a remote office and have them check. They say performance stinks. So you go home that night and try it from home, and sure enough, outside the building performance stinks. Inside, it’s fine. Now your problem is your Internet connection. So you check the statistics, and back-end services like replication are burying your Internet connection. So you do some research and decide that your problems are best addressed by reducing the bandwidth required for those back-end processes and setting guaranteed bandwidth numbers for HTTP traffic. Enter WAN Optimization. If you’re an F5 customer, you just add WOM to your BIG-IP and configure it. Other vendors have a few more steps, but not terribly more than if you were not an F5 customer and bought BIG-IP with WOM to solve this problem. And once all of that clears up, guess what? We’re back to Pikachu. Your two servers, now completely cleared of other bottlenecks, are servicing so many requests that their CPU utilization is spiking. Time for a third server. Now this whole story sounds simple, but it isn’t. Network, Storage, Systems, all fall under the bailiwick of different groups within IT. It is never so easy as the above paragraph makes it sound… I’ve glossed over the long nights, the endless status meetings, the frustration of not finding the bottleneck right away – mine are obvious only because I list them, I skip the part where you check fifty other things first. And inevitable, there is the discussion of what’s the right solution to a given problem that starts to sound like people who discuss the “best” Pokemon card. Someone wants to cut back on the amount of bandwidth back-office applications use by turning off services, someone wants to buy a bigger pipe, someone suggests WAN optimization, and we go a few rounds until we settle on a plan that’s best for the organization in question. But in the end, keeping the business going and customers happy is the key to IT. Sure, clearing up one bottleneck will create another and spawn another round of “right solution” discussions, but that’s the point. It’s why you’re there. You have the skills and the expertise the company needs to keep moving forward, and this is how they’re applied. And along the way you’ll get to find the new hot toy in the datacenter and propose it as the right solution to everything, because it is your Charizard – until the next round of discussion anyway. And admit it, this stuff is fun, just like the game. Choosing the right solution, getting it implemented, that’s what drives all good IT people. Figuring out problems that are complex enough to be called rocket science under pressure that is sometimes oppressive. But the rush is there when the solution is in and is right. And it’s often a team effort by all of the different groups in IT. I personally think IT should throw itself more parties, but I guess we’ll just have to settle for more dinner-at-the-desk moments for the time being.216Views0likes0CommentsSometimes, If IT Isn’t Broken, It Still Needs Fixing.
In our first house, we had a set of stairs that were horrible. They were unfinished, narrow, and steep. Lori went down them once with a vacuum cleaner, they were just not what we wanted in the house. They came out into the kitchen, so you were looking at these half-finished steps while sitting at the kitchen table. We covered them so they at least weren’t showing bare treads, and then we… Got used to them. Yes, that is what I said. We adapted. They were covered, making them minimally acceptable, they served their purpose, so we enjoyed them. Then we had the house remodeled. Nearly all of it. And the first thing the general contractor did was rip out those stairs and put in a sweeping staircase that turned and came into the living room. The difference was astonishing. We had agreed to him moving the stairs, but hadn’t put much more thought into it beyond his argument that it would save space upstairs and down, and they would no longer come out in the kitchen. This acceptance of something “good enough” is what happens in business units when you deliver an application that doesn’t perfectly suit their needs. They push for changes, and then settle into a restless truce. “That’s the way it is” becomes the watch-word. But do not get confused, they are not happy with it. There is a difference between acceptance and enjoyment. Stairs in question, before on left, after on right. Another issue that we discovered while making changes to that house was “the incredible shrinking door”. The enclosed porch on the back of the house was sitting on rail road ties from about a century ago, and they were starting into accelerated degradation. The part of the porch not attached to the house was shrinking yearly. Twice I sawed off the bottom of the door to the porch so that it would open and close. It really didn’t bother us overly much, because it happened over the course of years, and we adapted to the changes as they occurred. When we finally had that porch ripped off to put an actual addition on the house, we realized how painful dealing with the porch and its outer door had been. This too is what happens in business units when over time the usability of a given application slowly degrades or the system slowly becomes out of date. Users adapt, making it do what they want because, like our door, the changes occur day-to-day, not in one big catastrophic heap. So it is worth your time to occasionally look over your application portfolio and consider the new technologies you’ve brought in since each application was implemented. Decide if there are ways you can improve the experience without a ton of overhead. Your users may not even realize you’re causing them pain anymore, which means you may be able to offer them help they don’t know they’re looking for. Consider, would a given application perform better if placed behind an ADC, would putting a Web Application Firewall in front of an application make it more secure simply because the vendor is updating the Web App Firewall to adapt to new threats and your developers only update the application on occasion? Would shortening the backup window with storage tiering such as F5’s ARX offers improve application performance by reducing network traffic during backups and/or replication? Would changes in development libraries benefit existing applications? Granted, that one can be a bit more involved and has more potential for going wrong, but it is possible that the benefits are worth the investment/risk – that’s what the evaluation is for. Would turning on WAN Optimization between datacenters increase available bandwidth and thus improve application performance of all applications utilizing that connection? Would offloading encryption to an ADC decrease CPU utilization and thus improve performance of a wide swath of applications in the DC – particularly VM-based applications that are already sharing a CPU and could gain substantially from offloading encryption? These are the things that in the day-to-day crush of serving the business units and making certain the organizations’ systems are on-line we don’t generally think of, but some of them are simple to implement and offer a huge return – both in terms of application stability/performance and in terms of inter-department relations. Business units love to hear “we made that better” when they didn’t badger you to do so, and if the time investment is small they won’t ask why you weren’t doing what they did badger you to do. Always a fresh look. Your DC is not green field, but it is also not curing cement. Consider all the ways that something benefitting application X can benefit other applications, and what the costs of doing so will be. It is a powerful way to stay dynamic without rip-and-replace upgrades. If you’re an IT Architect, this is just part of your job, if you’re not, it’s simply good practice. Related Blogs: If I Were in IT Management Today… IT Management is Not Called Change Management for a Reason Challenges of SOA Management Nothing New Cloud Changes Everything IPv6 Does Not Mean The End of IPv4 It Is Not What The Market Is Doing, But What You Are.211Views0likes0Comments