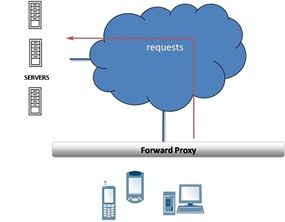
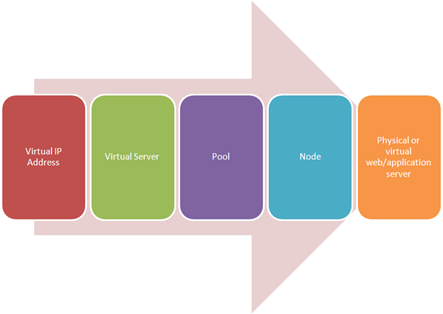
"}},"componentScriptGroups({\"componentId\":\"custom.widget.Beta_Footer\"})":{"__typename":"ComponentScriptGroups","scriptGroups":{"__typename":"ComponentScriptGroupsDefinition","afterInteractive":{"__typename":"PageScriptGroupDefinition","group":"AFTER_INTERACTIVE","scriptIds":[]},"lazyOnLoad":{"__typename":"PageScriptGroupDefinition","group":"LAZY_ON_LOAD","scriptIds":[]}},"componentScripts":[]},"component({\"componentId\":\"custom.widget.Tag_Manager_Helper\"})":{"__typename":"Component","render({\"context\":{\"component\":{\"entities\":[],\"props\":{}},\"page\":{\"entities\":[],\"name\":\"TagPage\",\"props\":{},\"url\":\"https://community.f5.com/tag/adc\"}}})":{"__typename":"ComponentRenderResult","html":" "}},"componentScriptGroups({\"componentId\":\"custom.widget.Tag_Manager_Helper\"})":{"__typename":"ComponentScriptGroups","scriptGroups":{"__typename":"ComponentScriptGroupsDefinition","afterInteractive":{"__typename":"PageScriptGroupDefinition","group":"AFTER_INTERACTIVE","scriptIds":[]},"lazyOnLoad":{"__typename":"PageScriptGroupDefinition","group":"LAZY_ON_LOAD","scriptIds":[]}},"componentScripts":[]},"component({\"componentId\":\"custom.widget.Consent_Blackbar\"})":{"__typename":"Component","render({\"context\":{\"component\":{\"entities\":[],\"props\":{}},\"page\":{\"entities\":[],\"name\":\"TagPage\",\"props\":{},\"url\":\"https://community.f5.com/tag/adc\"}}})":{"__typename":"ComponentRenderResult","html":""}},"componentScriptGroups({\"componentId\":\"custom.widget.Consent_Blackbar\"})":{"__typename":"ComponentScriptGroups","scriptGroups":{"__typename":"ComponentScriptGroupsDefinition","afterInteractive":{"__typename":"PageScriptGroupDefinition","group":"AFTER_INTERACTIVE","scriptIds":[]},"lazyOnLoad":{"__typename":"PageScriptGroupDefinition","group":"LAZY_ON_LOAD","scriptIds":[]}},"componentScripts":[]},"cachedText({\"lastModified\":\"1753121700619\",\"locale\":\"en-US\",\"namespaces\":[\"components/community/NavbarDropdownToggle\"]})":[{"__ref":"CachedAsset:text:en_US-components/community/NavbarDropdownToggle-1753121700619"}],"cachedText({\"lastModified\":\"1753121700619\",\"locale\":\"en-US\",\"namespaces\":[\"components/messages/MessageListTabs\"]})":[{"__ref":"CachedAsset:text:en_US-components/messages/MessageListTabs-1753121700619"}],"cachedText({\"lastModified\":\"1753121700619\",\"locale\":\"en-US\",\"namespaces\":[\"components/messages/MessageView/MessageViewInline\"]})":[{"__ref":"CachedAsset:text:en_US-components/messages/MessageView/MessageViewInline-1753121700619"}],"cachedText({\"lastModified\":\"1753121700619\",\"locale\":\"en-US\",\"namespaces\":[\"components/customComponent/CustomComponent\"]})":[{"__ref":"CachedAsset:text:en_US-components/customComponent/CustomComponent-1753121700619"}],"cachedText({\"lastModified\":\"1753121700619\",\"locale\":\"en-US\",\"namespaces\":[\"shared/client/components/common/OverflowNav\"]})":[{"__ref":"CachedAsset:text:en_US-shared/client/components/common/OverflowNav-1753121700619"}],"cachedText({\"lastModified\":\"1753121700619\",\"locale\":\"en-US\",\"namespaces\":[\"components/users/UserLink\"]})":[{"__ref":"CachedAsset:text:en_US-components/users/UserLink-1753121700619"}],"cachedText({\"lastModified\":\"1753121700619\",\"locale\":\"en-US\",\"namespaces\":[\"components/messages/MessageSubject\"]})":[{"__ref":"CachedAsset:text:en_US-components/messages/MessageSubject-1753121700619"}],"cachedText({\"lastModified\":\"1753121700619\",\"locale\":\"en-US\",\"namespaces\":[\"components/messages/MessageBody\"]})":[{"__ref":"CachedAsset:text:en_US-components/messages/MessageBody-1753121700619"}],"cachedText({\"lastModified\":\"1753121700619\",\"locale\":\"en-US\",\"namespaces\":[\"components/messages/MessageTime\"]})":[{"__ref":"CachedAsset:text:en_US-components/messages/MessageTime-1753121700619"}],"cachedText({\"lastModified\":\"1753121700619\",\"locale\":\"en-US\",\"namespaces\":[\"shared/client/components/nodes/NodeIcon\"]})":[{"__ref":"CachedAsset:text:en_US-shared/client/components/nodes/NodeIcon-1753121700619"}],"cachedText({\"lastModified\":\"1753121700619\",\"locale\":\"en-US\",\"namespaces\":[\"components/messages/MessageUnreadCount\"]})":[{"__ref":"CachedAsset:text:en_US-components/messages/MessageUnreadCount-1753121700619"}],"cachedText({\"lastModified\":\"1753121700619\",\"locale\":\"en-US\",\"namespaces\":[\"components/messages/MessageViewCount\"]})":[{"__ref":"CachedAsset:text:en_US-components/messages/MessageViewCount-1753121700619"}],"cachedText({\"lastModified\":\"1753121700619\",\"locale\":\"en-US\",\"namespaces\":[\"components/kudos/KudosCount\"]})":[{"__ref":"CachedAsset:text:en_US-components/kudos/KudosCount-1753121700619"}],"cachedText({\"lastModified\":\"1753121700619\",\"locale\":\"en-US\",\"namespaces\":[\"components/messages/MessageRepliesCount\"]})":[{"__ref":"CachedAsset:text:en_US-components/messages/MessageRepliesCount-1753121700619"}],"cachedText({\"lastModified\":\"1753121700619\",\"locale\":\"en-US\",\"namespaces\":[\"shared/client/components/users/UserAvatar\"]})":[{"__ref":"CachedAsset:text:en_US-shared/client/components/users/UserAvatar-1753121700619"}]},"Theme:customTheme1":{"__typename":"Theme","id":"customTheme1"},"User:user:-1":{"__typename":"User","id":"user:-1","entityType":"USER","eventPath":"community:zihoc95639/user:-1","uid":-1,"login":"Former Member","email":"","avatar":null,"rank":null,"kudosWeight":1,"registrationData":{"__typename":"RegistrationData","status":"ANONYMOUS","registrationTime":null,"confirmEmailStatus":false,"registrationAccessLevel":"VIEW","ssoRegistrationFields":[]},"ssoId":null,"profileSettings":{"__typename":"ProfileSettings","dateDisplayStyle":{"__typename":"InheritableStringSettingWithPossibleValues","key":"layout.friendly_dates_enabled","value":"false","localValue":"true","possibleValues":["true","false"]},"dateDisplayFormat":{"__typename":"InheritableStringSetting","key":"layout.format_pattern_date","value":"dd-MMM-yyyy","localValue":"MM-dd-yyyy"},"language":{"__typename":"InheritableStringSettingWithPossibleValues","key":"profile.language","value":"en-US","localValue":null,"possibleValues":["en-US","en-GB","fr-FR","de-DE","ja-JP","pt-PT","pt-BR","es-ES"]},"repliesSortOrder":{"__typename":"InheritableStringSettingWithPossibleValues","key":"config.user_replies_sort_order","value":"DEFAULT","localValue":"DEFAULT","possibleValues":["DEFAULT","LIKES","PUBLISH_TIME","REVERSE_PUBLISH_TIME"]}},"deleted":false},"CachedAsset:pages-1753121694584":{"__typename":"CachedAsset","id":"pages-1753121694584","value":[{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"BlogViewAllPostsPage","type":"BLOG","urlPath":"/category/:categoryId/blog/:boardId/all-posts/(/:after|/:before)?","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"CasePortalPage","type":"CASE_PORTAL","urlPath":"/caseportal","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"CreateGroupHubPage","type":"GROUP_HUB","urlPath":"/groups/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"CaseViewPage","type":"CASE_DETAILS","urlPath":"/case/:caseId/:caseNumber","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"InboxPage","type":"COMMUNITY","urlPath":"/inbox","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"HelpFAQPage","type":"COMMUNITY","urlPath":"/help","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"IdeaMessagePage","type":"IDEA_POST","urlPath":"/idea/:boardId/:messageSubject/:messageId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"IdeaViewAllIdeasPage","type":"IDEA","urlPath":"/category/:categoryId/ideas/:boardId/all-ideas/(/:after|/:before)?","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"LoginPage","type":"USER","urlPath":"/signin","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"WorkstreamsPage","type":"COMMUNITY","urlPath":"/workstreams","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"BlogPostPage","type":"BLOG","urlPath":"/category/:categoryId/blogs/:boardId/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1739501733000,"localOverride":null,"page":{"id":"Test","type":"CUSTOM","urlPath":"/custom-test-2","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"ThemeEditorPage","type":"COMMUNITY","urlPath":"/designer/themes","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"TkbViewAllArticlesPage","type":"TKB","urlPath":"/category/:categoryId/kb/:boardId/all-articles/(/:after|/:before)?","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"OccasionEditPage","type":"EVENT","urlPath":"/event/:boardId/:messageSubject/:messageId/edit","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"OAuthAuthorizationAllowPage","type":"USER","urlPath":"/auth/authorize/allow","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"PageEditorPage","type":"COMMUNITY","urlPath":"/designer/pages","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"PostPage","type":"COMMUNITY","urlPath":"/category/:categoryId/:boardId/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"ForumBoardPage","type":"FORUM","urlPath":"/category/:categoryId/discussions/:boardId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"TkbBoardPage","type":"TKB","urlPath":"/category/:categoryId/kb/:boardId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"EventPostPage","type":"EVENT","urlPath":"/category/:categoryId/events/:boardId/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"UserBadgesPage","type":"COMMUNITY","urlPath":"/users/:login/:userId/badges","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"GroupHubMembershipAction","type":"GROUP_HUB","urlPath":"/membership/join/:nodeId/:membershipType","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"MaintenancePage","type":"COMMUNITY","urlPath":"/maintenance","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"IdeaReplyPage","type":"IDEA_REPLY","urlPath":"/idea/:boardId/:messageSubject/:messageId/comments/:replyId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"UserSettingsPage","type":"USER","urlPath":"/mysettings/:userSettingsTab","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"GroupHubsPage","type":"GROUP_HUB","urlPath":"/groups","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"ForumPostPage","type":"FORUM","urlPath":"/category/:categoryId/discussions/:boardId/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"OccasionRsvpActionPage","type":"OCCASION","urlPath":"/event/:boardId/:messageSubject/:messageId/rsvp/:responseType","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"VerifyUserEmailPage","type":"USER","urlPath":"/verifyemail/:userId/:verifyEmailToken","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"AllOccasionsPage","type":"OCCASION","urlPath":"/category/:categoryId/events/:boardId/all-events/(/:after|/:before)?","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"EventBoardPage","type":"EVENT","urlPath":"/category/:categoryId/events/:boardId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"TkbReplyPage","type":"TKB_REPLY","urlPath":"/kb/:boardId/:messageSubject/:messageId/comments/:replyId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"IdeaBoardPage","type":"IDEA","urlPath":"/category/:categoryId/ideas/:boardId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"CommunityGuideLinesPage","type":"COMMUNITY","urlPath":"/communityguidelines","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"CaseCreatePage","type":"SALESFORCE_CASE_CREATION","urlPath":"/caseportal/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"TkbEditPage","type":"TKB","urlPath":"/kb/:boardId/:messageSubject/:messageId/edit","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"ForgotPasswordPage","type":"USER","urlPath":"/forgotpassword","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"IdeaEditPage","type":"IDEA","urlPath":"/idea/:boardId/:messageSubject/:messageId/edit","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"TagPage","type":"COMMUNITY","urlPath":"/tag/:tagName","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"BlogBoardPage","type":"BLOG","urlPath":"/category/:categoryId/blog/:boardId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"OccasionMessagePage","type":"OCCASION_TOPIC","urlPath":"/event/:boardId/:messageSubject/:messageId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"ManageContentPage","type":"COMMUNITY","urlPath":"/managecontent","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"ClosedMembershipNodeNonMembersPage","type":"GROUP_HUB","urlPath":"/closedgroup/:groupHubId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"CommunityPage","type":"COMMUNITY","urlPath":"/","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"ForumMessagePage","type":"FORUM_TOPIC","urlPath":"/discussions/:boardId/:messageSubject/:messageId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"IdeaPostPage","type":"IDEA","urlPath":"/category/:categoryId/ideas/:boardId/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"BlogMessagePage","type":"BLOG_ARTICLE","urlPath":"/blog/:boardId/:messageSubject/:messageId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"RegistrationPage","type":"USER","urlPath":"/register","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"EditGroupHubPage","type":"GROUP_HUB","urlPath":"/group/:groupHubId/edit","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"ForumEditPage","type":"FORUM","urlPath":"/discussions/:boardId/:messageSubject/:messageId/edit","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"ResetPasswordPage","type":"USER","urlPath":"/resetpassword/:userId/:resetPasswordToken","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"TkbMessagePage","type":"TKB_ARTICLE","urlPath":"/kb/:boardId/:messageSubject/:messageId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"BlogEditPage","type":"BLOG","urlPath":"/blog/:boardId/:messageSubject/:messageId/edit","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"ManageUsersPage","type":"USER","urlPath":"/users/manage/:tab?/:manageUsersTab?","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"ForumReplyPage","type":"FORUM_REPLY","urlPath":"/discussions/:boardId/:messageSubject/:messageId/replies/:replyId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"PrivacyPolicyPage","type":"COMMUNITY","urlPath":"/privacypolicy","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"NotificationPage","type":"COMMUNITY","urlPath":"/notifications","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"UserPage","type":"USER","urlPath":"/users/:login/:userId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"HealthCheckPage","type":"COMMUNITY","urlPath":"/health","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"OccasionReplyPage","type":"OCCASION_REPLY","urlPath":"/event/:boardId/:messageSubject/:messageId/comments/:replyId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"ManageMembersPage","type":"GROUP_HUB","urlPath":"/group/:groupHubId/manage/:tab?","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"SearchResultsPage","type":"COMMUNITY","urlPath":"/search","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"BlogReplyPage","type":"BLOG_REPLY","urlPath":"/blog/:boardId/:messageSubject/:messageId/replies/:replyId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"GroupHubPage","type":"GROUP_HUB","urlPath":"/group/:groupHubId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"TermsOfServicePage","type":"COMMUNITY","urlPath":"/termsofservice","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"CategoryPage","type":"CATEGORY","urlPath":"/category/:categoryId","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"ForumViewAllTopicsPage","type":"FORUM","urlPath":"/category/:categoryId/discussions/:boardId/all-topics/(/:after|/:before)?","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"TkbPostPage","type":"TKB","urlPath":"/category/:categoryId/kbs/:boardId/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"GroupHubPostPage","type":"GROUP_HUB","urlPath":"/group/:groupHubId/:boardId/create","__typename":"PageDescriptor"},"__typename":"PageResource"},{"lastUpdatedTime":1753121694584,"localOverride":null,"page":{"id":"HowDoI","type":"COMMUNITY","urlPath":"/c/how-do-i","__typename":"PageDescriptor"},"__typename":"PageResource"}],"localOverride":false},"CachedAsset:text:en_US-components/context/AppContext/AppContextProvider-0":{"__typename":"CachedAsset","id":"text:en_US-components/context/AppContext/AppContextProvider-0","value":{"noCommunity":"Cannot find community","noUser":"Cannot find current user","noNode":"Cannot find node with id {nodeId}","noMessage":"Cannot find message with id {messageId}","userBanned":"We're sorry, but you have been banned from using this site.","userBannedReason":"You have been banned for the following reason: {reason}"},"localOverride":false},"CachedAsset:text:en_US-shared/client/components/common/Loading/LoadingDot-0":{"__typename":"CachedAsset","id":"text:en_US-shared/client/components/common/Loading/LoadingDot-0","value":{"title":"Loading..."},"localOverride":false},"CachedAsset:theme:customTheme1-1753121679135":{"__typename":"CachedAsset","id":"theme:customTheme1-1753121679135","value":{"id":"customTheme1","animation":{"fast":"150ms","normal":"250ms","slow":"500ms","slowest":"750ms","function":"cubic-bezier(0.07, 0.91, 0.51, 1)","__typename":"AnimationThemeSettings"},"avatar":{"borderRadius":"50%","collections":["custom"],"__typename":"AvatarThemeSettings"},"basics":{"browserIcon":{"imageAssetName":"android-chrome-512x512-1748534255255.png","imageLastModified":"1748534256856","__typename":"ThemeAsset"},"customerLogo":{"imageAssetName":"F5-devCentral-HR-color-reverse-1750868999153.png","imageLastModified":"1750869001512","__typename":"ThemeAsset"},"maximumWidthOfPageContent":"fluid","oneColumnNarrowWidth":"800px","gridGutterWidthMd":"30px","gridGutterWidthXs":"10px","pageWidthStyle":"WIDTH_OF_PAGE_CONTENT","__typename":"BasicsThemeSettings"},"buttons":{"borderRadiusSm":"5px","borderRadius":"5px","borderRadiusLg":"5px","paddingY":"5px","paddingYLg":"7px","paddingYHero":"var(--lia-bs-btn-padding-y-lg)","paddingX":"12px","paddingXLg":"14px","paddingXHero":"42px","fontStyle":"NORMAL","fontWeight":"500","textTransform":"NONE","disabledOpacity":0.5,"primaryTextColor":"var(--lia-bs-white)","primaryTextHoverColor":"var(--lia-bs-white)","primaryTextActiveColor":"var(--lia-bs-white)","primaryBgColor":"#0072B0","primaryBgHoverColor":"hsl(201.10000000000002, 100%, 29.3%)","primaryBgActiveColor":"hsl(201.10000000000002, 100%, 24.2%)","primaryBorder":"1px solid transparent","primaryBorderHover":"1px solid transparent","primaryBorderActive":"1px solid transparent","primaryBorderFocus":"1px solid var(--lia-bs-white)","primaryBoxShadowFocus":"0 0 0 1px #0072B0, 0 0 0 4px rgba(0, 114, 176, 0.2)","secondaryTextColor":"var(--lia-bs-white)","secondaryTextHoverColor":"var(--lia-bs-white)","secondaryTextActiveColor":"var(--lia-bs-white)","secondaryBgColor":"#0072B0","secondaryBgHoverColor":"hsl(201.10000000000002, 100%, 29.3%)","secondaryBgActiveColor":"hsl(201.10000000000002, 100%, 24.2%)","secondaryBorder":"1px solid transparent","secondaryBorderHover":"1px solid transparent","secondaryBorderActive":"1px solid transparent","secondaryBorderFocus":"1px solid transparent","secondaryBoxShadowFocus":"0 0 0 1px #0072B0, 0 0 0 4px rgba(0, 114, 176, 0.2)","tertiaryTextColor":"#0072B0","tertiaryTextHoverColor":"hsl(201.10000000000002, 100%, 32.8%)","tertiaryTextActiveColor":"hsl(201.10000000000002, 100%, 31.1%)","tertiaryBgColor":"transparent","tertiaryBgHoverColor":"transparent","tertiaryBgActiveColor":"rgba(0, 114, 176, 0.04)","tertiaryBorder":"1px solid transparent","tertiaryBorderHover":"1px solid rgba(0, 114, 176, 0.08)","tertiaryBorderActive":"1px solid transparent","tertiaryBorderFocus":"1px solid transparent","tertiaryBoxShadowFocus":"0 0 0 1px #0072B0, 0 0 0 4px rgba(0, 114, 176, 0.2)","destructiveTextColor":"var(--lia-bs-danger)","destructiveTextHoverColor":"hsl(var(--lia-bs-danger-h), var(--lia-bs-danger-s), calc(var(--lia-bs-danger-l) * 0.95))","destructiveTextActiveColor":"hsl(var(--lia-bs-danger-h), var(--lia-bs-danger-s), calc(var(--lia-bs-danger-l) * 0.9))","destructiveBgColor":"var(--lia-bs-gray-300)","destructiveBgHoverColor":"hsl(var(--lia-bs-gray-300-h), var(--lia-bs-gray-300-s), calc(var(--lia-bs-gray-300-l) * 0.96))","destructiveBgActiveColor":"hsl(var(--lia-bs-gray-300-h), var(--lia-bs-gray-300-s), calc(var(--lia-bs-gray-300-l) * 0.92))","destructiveBorder":"1px solid transparent","destructiveBorderHover":"1px solid transparent","destructiveBorderActive":"1px solid transparent","destructiveBorderFocus":"1px solid transparent","destructiveBoxShadowFocus":"0 0 0 1px #0072B0, 0 0 0 4px rgba(0, 114, 176, 0.2)","__typename":"ButtonsThemeSettings"},"border":{"color":"hsla(var(--lia-bs-black-h), var(--lia-bs-black-s), var(--lia-bs-black-l), 0.08)","mainContent":"DARK","sideContent":"DARK","radiusSm":"3px","radius":"5px","radiusLg":"9px","radius50":"100vw","__typename":"BorderThemeSettings"},"boxShadow":{"xs":"0 0 0 1px hsla(var(--lia-bs-gray-900-h), var(--lia-bs-gray-900-s), var(--lia-bs-gray-900-l), 0.08), 0 3px 0 -1px hsla(var(--lia-bs-gray-900-h), var(--lia-bs-gray-900-s), var(--lia-bs-gray-900-l), 0.16)","sm":"0 2px 4px hsla(var(--lia-bs-gray-900-h), var(--lia-bs-gray-900-s), var(--lia-bs-gray-900-l), 0.12)","md":"0 5px 15px hsla(var(--lia-bs-gray-900-h), var(--lia-bs-gray-900-s), var(--lia-bs-gray-900-l), 0.3)","lg":"0 10px 30px hsla(var(--lia-bs-gray-900-h), var(--lia-bs-gray-900-s), var(--lia-bs-gray-900-l), 0.3)","__typename":"BoxShadowThemeSettings"},"cards":{"bgColor":"var(--lia-panel-bg-color)","borderRadius":"var(--lia-panel-border-radius)","boxShadow":"var(--lia-box-shadow-xs)","__typename":"CardsThemeSettings"},"chip":{"maxWidth":"300px","height":"30px","__typename":"ChipThemeSettings"},"coreTypes":{"defaultMessageLinkColor":"var(--lia-bs-primary)","defaultMessageLinkDecoration":"none","defaultMessageLinkFontStyle":"NORMAL","defaultMessageLinkFontWeight":"500","defaultMessageFontStyle":"NORMAL","defaultMessageFontWeight":"400","defaultMessageFontFamily":"var(--lia-bs-font-family-base)","forumColor":"#0C5C8D","forumFontFamily":"var(--lia-bs-font-family-base)","forumFontWeight":"var(--lia-default-message-font-weight)","forumLineHeight":"var(--lia-bs-line-height-base)","forumFontStyle":"var(--lia-default-message-font-style)","forumMessageLinkColor":"var(--lia-default-message-link-color)","forumMessageLinkDecoration":"var(--lia-default-message-link-decoration)","forumMessageLinkFontStyle":"var(--lia-default-message-link-font-style)","forumMessageLinkFontWeight":"var(--lia-default-message-link-font-weight)","forumSolvedColor":"#62C026","blogColor":"#730015","blogFontFamily":"var(--lia-bs-font-family-base)","blogFontWeight":"var(--lia-default-message-font-weight)","blogLineHeight":"1.75","blogFontStyle":"var(--lia-default-message-font-style)","blogMessageLinkColor":"var(--lia-default-message-link-color)","blogMessageLinkDecoration":"var(--lia-default-message-link-decoration)","blogMessageLinkFontStyle":"var(--lia-default-message-link-font-style)","blogMessageLinkFontWeight":"var(--lia-default-message-link-font-weight)","tkbColor":"#C20025","tkbFontFamily":"var(--lia-bs-font-family-base)","tkbFontWeight":"var(--lia-default-message-font-weight)","tkbLineHeight":"1.75","tkbFontStyle":"var(--lia-default-message-font-style)","tkbMessageLinkColor":"var(--lia-default-message-link-color)","tkbMessageLinkDecoration":"var(--lia-default-message-link-decoration)","tkbMessageLinkFontStyle":"var(--lia-default-message-link-font-style)","tkbMessageLinkFontWeight":"var(--lia-default-message-link-font-weight)","qandaColor":"#4099E2","qandaFontFamily":"var(--lia-bs-font-family-base)","qandaFontWeight":"var(--lia-default-message-font-weight)","qandaLineHeight":"var(--lia-bs-line-height-base)","qandaFontStyle":"var(--lia-default-message-link-font-style)","qandaMessageLinkColor":"var(--lia-default-message-link-color)","qandaMessageLinkDecoration":"var(--lia-default-message-link-decoration)","qandaMessageLinkFontStyle":"var(--lia-default-message-link-font-style)","qandaMessageLinkFontWeight":"var(--lia-default-message-link-font-weight)","qandaSolvedColor":"#3FA023","ideaColor":"#F3704B","ideaFontFamily":"var(--lia-bs-font-family-base)","ideaFontWeight":"var(--lia-default-message-font-weight)","ideaLineHeight":"var(--lia-bs-line-height-base)","ideaFontStyle":"var(--lia-default-message-font-style)","ideaMessageLinkColor":"var(--lia-default-message-link-color)","ideaMessageLinkDecoration":"var(--lia-default-message-link-decoration)","ideaMessageLinkFontStyle":"var(--lia-default-message-link-font-style)","ideaMessageLinkFontWeight":"var(--lia-default-message-link-font-weight)","contestColor":"#FCC845","contestFontFamily":"var(--lia-bs-font-family-base)","contestFontWeight":"var(--lia-default-message-font-weight)","contestLineHeight":"var(--lia-bs-line-height-base)","contestFontStyle":"var(--lia-default-message-link-font-style)","contestMessageLinkColor":"var(--lia-default-message-link-color)","contestMessageLinkDecoration":"var(--lia-default-message-link-decoration)","contestMessageLinkFontStyle":"ITALIC","contestMessageLinkFontWeight":"var(--lia-default-message-link-font-weight)","occasionColor":"#EE4B5B","occasionFontFamily":"var(--lia-bs-font-family-base)","occasionFontWeight":"var(--lia-default-message-font-weight)","occasionLineHeight":"var(--lia-bs-line-height-base)","occasionFontStyle":"var(--lia-default-message-font-style)","occasionMessageLinkColor":"var(--lia-default-message-link-color)","occasionMessageLinkDecoration":"var(--lia-default-message-link-decoration)","occasionMessageLinkFontStyle":"var(--lia-default-message-link-font-style)","occasionMessageLinkFontWeight":"var(--lia-default-message-link-font-weight)","grouphubColor":"#491B62","categoryColor":"#949494","communityColor":"#FFFFFF","productColor":"#949494","__typename":"CoreTypesThemeSettings"},"colors":{"black":"#000000","white":"#FFFFFF","gray100":"#F7F7F7","gray200":"#F7F7F7","gray300":"#E8E8E8","gray400":"#D9D9D9","gray500":"#CCCCCC","gray600":"#949494","gray700":"#707070","gray800":"#545454","gray900":"#333333","dark":"#545454","light":"#F7F7F7","primary":"#0072B0","secondary":"#333333","bodyText":"#222222","bodyBg":"#F5F5F5","info":"#1D9CD3","success":"#62C026","warning":"#FFD651","danger":"#C20025","alertSystem":"#FF6600","textMuted":"#707070","highlight":"#FFFCAD","outline":"var(--lia-bs-primary)","custom":["#C20025","#081B85","#009639","#B3C6D7","#7CC0EB","#F29A36","#B2D7EB","#66AFD7","#007ABC","#343434","#0E6EB9","#0072B0"],"__typename":"ColorsThemeSettings"},"divider":{"size":"3px","marginLeft":"4px","marginRight":"4px","borderRadius":"50%","bgColor":"var(--lia-bs-gray-600)","bgColorActive":"var(--lia-bs-gray-600)","__typename":"DividerThemeSettings"},"dropdown":{"fontSize":"var(--lia-bs-font-size-sm)","borderColor":"var(--lia-bs-border-color)","borderRadius":"var(--lia-bs-border-radius-sm)","dividerBg":"var(--lia-bs-gray-300)","itemPaddingY":"5px","itemPaddingX":"20px","headerColor":"var(--lia-bs-gray-700)","__typename":"DropdownThemeSettings"},"email":{"link":{"color":"#0069D4","hoverColor":"#0061c2","decoration":"none","hoverDecoration":"underline","__typename":"EmailLinkSettings"},"border":{"color":"#e4e4e4","__typename":"EmailBorderSettings"},"buttons":{"borderRadiusLg":"5px","paddingXLg":"16px","paddingYLg":"7px","fontWeight":"700","primaryTextColor":"#ffffff","primaryTextHoverColor":"#ffffff","primaryBgColor":"#0069D4","primaryBgHoverColor":"#005cb8","primaryBorder":"1px solid transparent","primaryBorderHover":"1px solid transparent","__typename":"EmailButtonsSettings"},"panel":{"borderRadius":"5px","borderColor":"#e4e4e4","__typename":"EmailPanelSettings"},"__typename":"EmailThemeSettings"},"emoji":{"skinToneDefault":"#ffcd43","skinToneLight":"#fae3c5","skinToneMediumLight":"#e2cfa5","skinToneMedium":"#daa478","skinToneMediumDark":"#a78058","skinToneDark":"#5e4d43","__typename":"EmojiThemeSettings"},"heading":{"color":"var(--lia-bs-body-color)","fontFamily":"Neusa Next Pro Wide Bold","fontStyle":"NORMAL","fontWeight":"700","h1FontSize":"30px","h2FontSize":"25px","h3FontSize":"20px","h4FontSize":"18px","h5FontSize":"16px","h6FontSize":"16px","lineHeight":"1.1","subHeaderFontSize":"11px","subHeaderFontWeight":"500","h1LetterSpacing":"normal","h2LetterSpacing":"normal","h3LetterSpacing":"normal","h4LetterSpacing":"normal","h5LetterSpacing":"normal","h6LetterSpacing":"normal","subHeaderLetterSpacing":"2px","h1FontWeight":"var(--lia-bs-headings-font-weight)","h2FontWeight":"var(--lia-bs-headings-font-weight)","h3FontWeight":"var(--lia-bs-headings-font-weight)","h4FontWeight":"var(--lia-bs-headings-font-weight)","h5FontWeight":"var(--lia-bs-headings-font-weight)","h6FontWeight":"var(--lia-bs-headings-font-weight)","__typename":"HeadingThemeSettings"},"icons":{"size10":"10px","size12":"12px","size14":"14px","size16":"16px","size20":"20px","size24":"24px","size30":"30px","size40":"40px","size50":"50px","size60":"60px","size80":"80px","size120":"120px","size160":"160px","__typename":"IconsThemeSettings"},"imagePreview":{"bgColor":"var(--lia-bs-gray-900)","titleColor":"var(--lia-bs-white)","controlColor":"var(--lia-bs-white)","controlBgColor":"var(--lia-bs-gray-800)","__typename":"ImagePreviewThemeSettings"},"input":{"borderColor":"var(--lia-bs-gray-600)","disabledColor":"var(--lia-bs-gray-600)","focusBorderColor":"var(--lia-bs-primary)","labelMarginBottom":"10px","btnFontSize":"var(--lia-bs-font-size-sm)","focusBoxShadow":"0 0 0 3px hsla(var(--lia-bs-primary-h), var(--lia-bs-primary-s), var(--lia-bs-primary-l), 0.2)","checkLabelMarginBottom":"2px","checkboxBorderRadius":"3px","borderRadiusSm":"var(--lia-bs-border-radius-sm)","borderRadius":"var(--lia-bs-border-radius)","borderRadiusLg":"var(--lia-bs-border-radius-lg)","formTextMarginTop":"4px","textAreaBorderRadius":"var(--lia-bs-border-radius)","activeFillColor":"var(--lia-bs-primary)","__typename":"InputThemeSettings"},"loading":{"dotDarkColor":"hsla(var(--lia-bs-black-h), var(--lia-bs-black-s), var(--lia-bs-black-l), 0.2)","dotLightColor":"hsla(var(--lia-bs-white-h), var(--lia-bs-white-s), var(--lia-bs-white-l), 0.5)","barDarkColor":"hsla(var(--lia-bs-black-h), var(--lia-bs-black-s), var(--lia-bs-black-l), 0.06)","barLightColor":"hsla(var(--lia-bs-white-h), var(--lia-bs-white-s), var(--lia-bs-white-l), 0.4)","__typename":"LoadingThemeSettings"},"link":{"color":"var(--lia-bs-primary)","hoverColor":"hsl(var(--lia-bs-primary-h), var(--lia-bs-primary-s), calc(var(--lia-bs-primary-l) - 10%))","decoration":"none","hoverDecoration":"underline","__typename":"LinkThemeSettings"},"listGroup":{"itemPaddingY":"15px","itemPaddingX":"15px","borderColor":"var(--lia-bs-gray-300)","__typename":"ListGroupThemeSettings"},"modal":{"contentTextColor":"var(--lia-bs-body-color)","contentBg":"var(--lia-bs-white)","backgroundBg":"var(--lia-bs-black)","smSize":"440px","mdSize":"760px","lgSize":"1080px","backdropOpacity":0.3,"contentBoxShadowXs":"var(--lia-bs-box-shadow-sm)","contentBoxShadow":"var(--lia-bs-box-shadow)","headerFontWeight":"700","__typename":"ModalThemeSettings"},"navbar":{"position":"FIXED","background":{"attachment":null,"clip":null,"color":"var(--lia-bs-white)","imageAssetName":null,"imageLastModified":"0","origin":null,"position":"CENTER_CENTER","repeat":"NO_REPEAT","size":"COVER","__typename":"BackgroundProps"},"backgroundOpacity":0.8,"paddingTop":"15px","paddingBottom":"15px","borderBottom":"1px solid var(--lia-bs-border-color)","boxShadow":"var(--lia-bs-box-shadow-sm)","brandMarginRight":"30px","brandMarginRightSm":"10px","brandLogoHeight":"30px","linkGap":"10px","linkJustifyContent":"flex-start","linkPaddingY":"5px","linkPaddingX":"10px","linkDropdownPaddingY":"9px","linkDropdownPaddingX":"var(--lia-nav-link-px)","linkColor":"var(--lia-bs-body-color)","linkHoverColor":"var(--lia-bs-primary)","linkFontSize":"var(--lia-bs-font-size-sm)","linkFontStyle":"NORMAL","linkFontWeight":"400","linkTextTransform":"NONE","linkLetterSpacing":"normal","linkBorderRadius":"var(--lia-bs-border-radius-sm)","linkBgColor":"transparent","linkBgHoverColor":"transparent","linkBorder":"none","linkBorderHover":"none","linkBoxShadow":"none","linkBoxShadowHover":"none","linkTextBorderBottom":"none","linkTextBorderBottomHover":"none","dropdownPaddingTop":"10px","dropdownPaddingBottom":"15px","dropdownPaddingX":"10px","dropdownMenuOffset":"2px","dropdownDividerMarginTop":"10px","dropdownDividerMarginBottom":"10px","dropdownBorderColor":"hsla(var(--lia-bs-black-h), var(--lia-bs-black-s), var(--lia-bs-black-l), 0.08)","controllerBgHoverColor":"hsla(var(--lia-bs-black-h), var(--lia-bs-black-s), var(--lia-bs-black-l), 0.1)","controllerIconColor":"var(--lia-bs-body-color)","controllerIconHoverColor":"var(--lia-bs-body-color)","controllerTextColor":"var(--lia-nav-controller-icon-color)","controllerTextHoverColor":"var(--lia-nav-controller-icon-hover-color)","controllerHighlightColor":"hsla(30, 100%, 50%)","controllerHighlightTextColor":"var(--lia-yiq-light)","controllerBorderRadius":"var(--lia-border-radius-50)","hamburgerColor":"var(--lia-nav-controller-icon-color)","hamburgerHoverColor":"var(--lia-nav-controller-icon-color)","hamburgerBgColor":"transparent","hamburgerBgHoverColor":"transparent","hamburgerBorder":"none","hamburgerBorderHover":"none","collapseMenuMarginLeft":"20px","collapseMenuDividerBg":"var(--lia-nav-link-color)","collapseMenuDividerOpacity":0.16,"__typename":"NavbarThemeSettings"},"pager":{"textColor":"var(--lia-bs-link-color)","textFontWeight":"var(--lia-font-weight-md)","textFontSize":"var(--lia-bs-font-size-sm)","__typename":"PagerThemeSettings"},"panel":{"bgColor":"var(--lia-bs-white)","borderRadius":"var(--lia-bs-border-radius)","borderColor":"var(--lia-bs-border-color)","boxShadow":"none","__typename":"PanelThemeSettings"},"popover":{"arrowHeight":"8px","arrowWidth":"16px","maxWidth":"300px","minWidth":"100px","headerBg":"var(--lia-bs-white)","borderColor":"var(--lia-bs-border-color)","borderRadius":"var(--lia-bs-border-radius)","boxShadow":"0 0.5rem 1rem hsla(var(--lia-bs-black-h), var(--lia-bs-black-s), var(--lia-bs-black-l), 0.15)","__typename":"PopoverThemeSettings"},"prism":{"color":"#000000","bgColor":"#f5f2f0","fontFamily":"var(--font-family-monospace)","fontSize":"var(--lia-bs-font-size-base)","fontWeightBold":"var(--lia-bs-font-weight-bold)","fontStyleItalic":"italic","tabSize":2,"highlightColor":"#b3d4fc","commentColor":"#62707e","punctuationColor":"#6f6f6f","namespaceOpacity":"0.7","propColor":"#990055","selectorColor":"#517a00","operatorColor":"#906736","operatorBgColor":"hsla(0, 0%, 100%, 0.5)","keywordColor":"#0076a9","functionColor":"#d3284b","variableColor":"#c14700","__typename":"PrismThemeSettings"},"rte":{"bgColor":"var(--lia-bs-white)","borderRadius":"var(--lia-panel-border-radius)","boxShadow":" var(--lia-panel-box-shadow)","customColor1":"#bfedd2","customColor2":"#fbeeb8","customColor3":"#f8cac6","customColor4":"#eccafa","customColor5":"#c2e0f4","customColor6":"#2dc26b","customColor7":"#f1c40f","customColor8":"#e03e2d","customColor9":"#b96ad9","customColor10":"#3598db","customColor11":"#169179","customColor12":"#e67e23","customColor13":"#ba372a","customColor14":"#843fa1","customColor15":"#236fa1","customColor16":"#ecf0f1","customColor17":"#ced4d9","customColor18":"#95a5a6","customColor19":"#7e8c8d","customColor20":"#34495e","customColor21":"#000000","customColor22":"#ffffff","defaultMessageHeaderMarginTop":"14px","defaultMessageHeaderMarginBottom":"10px","defaultMessageItemMarginTop":"0","defaultMessageItemMarginBottom":"10px","diffAddedColor":"hsla(170, 53%, 51%, 0.4)","diffChangedColor":"hsla(43, 97%, 63%, 0.4)","diffNoneColor":"hsla(0, 0%, 80%, 0.4)","diffRemovedColor":"hsla(9, 74%, 47%, 0.4)","specialMessageHeaderMarginTop":"14px","specialMessageHeaderMarginBottom":"10px","specialMessageItemMarginTop":"0","specialMessageItemMarginBottom":"10px","tableBgColor":"transparent","tableBorderColor":"var(--lia-bs-gray-700)","tableBorderStyle":"solid","tableCellPaddingX":"5px","tableCellPaddingY":"5px","tableTextColor":"var(--lia-bs-body-color)","tableVerticalAlign":"middle","__typename":"RteThemeSettings"},"tags":{"bgColor":"var(--lia-bs-gray-200)","bgHoverColor":"var(--lia-bs-gray-400)","borderRadius":"var(--lia-bs-border-radius-sm)","color":"var(--lia-bs-body-color)","hoverColor":"var(--lia-bs-body-color)","fontWeight":"var(--lia-font-weight-md)","fontSize":"var(--lia-font-size-xxs)","textTransform":"UPPERCASE","letterSpacing":"0.5px","__typename":"TagsThemeSettings"},"toasts":{"borderRadius":"var(--lia-bs-border-radius)","paddingX":"12px","__typename":"ToastsThemeSettings"},"typography":{"fontFamilyBase":"Proxima Nova A Medium","fontStyleBase":"NORMAL","fontWeightBase":"500","fontWeightLight":"300","fontWeightNormal":"400","fontWeightMd":"500","fontWeightBold":"700","letterSpacingSm":"normal","letterSpacingXs":"normal","lineHeightBase":"1.2","fontSizeBase":"15px","fontSizeXxs":"11px","fontSizeXs":"12px","fontSizeSm":"13px","fontSizeLg":"20px","fontSizeXl":"24px","smallFontSize":"14px","customFonts":[{"source":"SERVER","name":"Proxima Nova A Medium","styles":[{"style":"NORMAL","weight":"500","__typename":"FontStyleData"}],"assetNames":["ProximaNovaAMedium-normal-500.woff2"],"__typename":"CustomFont"},{"source":"SERVER","name":"Neusa Next Pro Wide Bold","styles":[{"style":"NORMAL","weight":"700","__typename":"FontStyleData"}],"assetNames":["NeusaNextProWideBold-normal-700.woff2"],"__typename":"CustomFont"}],"__typename":"TypographyThemeSettings"},"unstyledListItem":{"marginBottomSm":"5px","marginBottomMd":"10px","marginBottomLg":"15px","marginBottomXl":"20px","marginBottomXxl":"25px","__typename":"UnstyledListItemThemeSettings"},"yiq":{"light":"#ffffff","dark":"#000000","__typename":"YiqThemeSettings"},"colorLightness":{"primaryDark":0.36,"primaryLight":0.74,"primaryLighter":0.89,"primaryLightest":0.95,"infoDark":0.39,"infoLight":0.72,"infoLighter":0.85,"infoLightest":0.93,"successDark":0.24,"successLight":0.62,"successLighter":0.8,"successLightest":0.91,"warningDark":0.39,"warningLight":0.68,"warningLighter":0.84,"warningLightest":0.93,"dangerDark":0.41,"dangerLight":0.72,"dangerLighter":0.89,"dangerLightest":0.95,"__typename":"ColorLightnessThemeSettings"},"localOverride":false,"__typename":"Theme"},"localOverride":false},"CachedAsset:text:en_US-shared/client/components/common/Loading/LoadingDot-1753121700619":{"__typename":"CachedAsset","id":"text:en_US-shared/client/components/common/Loading/LoadingDot-1753121700619","value":{"title":"Loading..."},"localOverride":false},"CachedAsset:text:en_US-components/common/EmailVerification-1753121700619":{"__typename":"CachedAsset","id":"text:en_US-components/common/EmailVerification-1753121700619","value":{"email.verification.title":"Email Verification Required","email.verification.message.update.email":"To participate in the community, you must first verify your email address. The verification email was sent to {email}. To change your email, visit My Settings.","email.verification.message.resend.email":"To participate in the community, you must first verify your email address. The verification email was sent to {email}. Resend email."},"localOverride":false},"CachedAsset:text:en_US-pages/tags/TagPage-1753121700619":{"__typename":"CachedAsset","id":"text:en_US-pages/tags/TagPage-1753121700619","value":{"tagPageTitle":"Tag:\"{tagName}\" | {communityTitle}","tagPageForNodeTitle":"Tag:\"{tagName}\" in \"{title}\" | {communityTitle}","name":"Tags Page","tag":"Tag: {tagName}"},"localOverride":false},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bi0zNC1SbWNGdVQ?image-coordinates=0%2C0%2C500%2C500\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bi0zNC1SbWNGdVQ?image-coordinates=0%2C0%2C500%2C500","mimeType":"image/png"},"Category:category:Articles":{"__typename":"Category","id":"category:Articles","entityType":"CATEGORY","displayId":"Articles","nodeType":"category","depth":1,"title":"Articles","shortTitle":"Articles","parent":{"__ref":"Category:category:top"},"categoryPolicies":{"__typename":"CategoryPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Category:category:top":{"__typename":"Category","id":"category:top","displayId":"top","nodeType":"category","depth":0,"title":"Top"},"Tkb:board:TechnicalArticles":{"__typename":"Tkb","id":"board:TechnicalArticles","entityType":"TKB","displayId":"TechnicalArticles","nodeType":"board","depth":2,"conversationStyle":"TKB","title":"Technical Articles","description":"F5 SMEs share good practice.","avatar":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bi0zNC1SbWNGdVQ?image-coordinates=0%2C0%2C500%2C500\"}"},"profileSettings":{"__typename":"ProfileSettings","language":null},"parent":{"__ref":"Category:category:Articles"},"ancestors":{"__typename":"CoreNodeConnection","edges":[{"__typename":"CoreNodeEdge","node":{"__ref":"Community:community:zihoc95639"}},{"__typename":"CoreNodeEdge","node":{"__ref":"Category:category:Articles"}}]},"userContext":{"__typename":"NodeUserContext","canAddAttachments":false,"canUpdateNode":false,"canPostMessages":false,"isSubscribed":false},"boardPolicies":{"__typename":"BoardPolicies","canPublishArticleOnCreate":{"__typename":"PolicyResult","failureReason":{"__typename":"FailureReason","message":"error.lithium.policies.forums.policy_can_publish_on_create_workflow_action.accessDenied","key":"error.lithium.policies.forums.policy_can_publish_on_create_workflow_action.accessDenied","args":[]}},"canReadNode":{"__typename":"PolicyResult","failureReason":null}},"theme":{"__ref":"Theme:customTheme1"},"tkbPolicies":{"__typename":"TkbPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"shortTitle":"Technical Articles","tagPolicies":{"__typename":"TagPolicies","canSubscribeTagOnNode":{"__typename":"PolicyResult","failureReason":{"__typename":"FailureReason","message":"error.lithium.policies.labels.action.corenode.subscribe_labels.allow.accessDenied","key":"error.lithium.policies.labels.action.corenode.subscribe_labels.allow.accessDenied","args":[]}},"canManageTagDashboard":{"__typename":"PolicyResult","failureReason":{"__typename":"FailureReason","message":"error.lithium.policies.labels.action.corenode.admin_labels.allow.accessDenied","key":"error.lithium.policies.labels.action.corenode.admin_labels.allow.accessDenied","args":[]}}}},"CachedAsset:quilt:f5.prod:pages/tags/TagPage:board:TechnicalArticles-1753121697447":{"__typename":"CachedAsset","id":"quilt:f5.prod:pages/tags/TagPage:board:TechnicalArticles-1753121697447","value":{"id":"TagPage","container":{"id":"Common","headerProps":{"removeComponents":["community.widget.bannerWidget"],"__typename":"QuiltContainerSectionProps"},"items":[{"id":"tag-header-widget","layout":"ONE_COLUMN","bgColor":"var(--lia-bs-white)","showBorder":"BOTTOM","sectionEditLevel":"LOCKED","columnMap":{"main":[{"id":"tags.widget.TagsHeaderWidget","__typename":"QuiltComponent"}],"__typename":"OneSectionColumns"},"__typename":"OneColumnQuiltSection"},{"id":"messages-list-for-tag-widget","layout":"ONE_COLUMN","columnMap":{"main":[{"id":"messages.widget.messageListForNodeByRecentActivityWidget","props":{"viewVariant":{"type":"inline","props":{"useUnreadCount":true,"useViewCount":true,"useAuthorLogin":true,"clampBodyLines":3,"useAvatar":true,"useBoardIcon":false,"useKudosCount":true,"usePreviewMedia":true,"useTags":false,"useNode":true,"useNodeLink":true,"useTextBody":true,"truncateBodyLength":-1,"useBody":true,"useRepliesCount":true,"useSolvedBadge":true,"timeStampType":"conversation.lastPostingActivityTime","useMessageTimeLink":true,"clampSubjectLines":2}},"panelType":"divider","useTitle":false,"hideIfEmpty":false,"pagerVariant":{"type":"loadMore"},"style":"list","showTabs":true,"tabItemMap":{"default":{"mostRecent":true,"mostRecentUserContent":false,"newest":false},"additional":{"mostKudoed":true,"mostViewed":true,"mostReplies":false,"noReplies":false,"noSolutions":false,"solutions":false}}},"__typename":"QuiltComponent"}],"__typename":"OneSectionColumns"},"__typename":"OneColumnQuiltSection"}],"__typename":"QuiltContainer"},"__typename":"Quilt"},"localOverride":false},"CachedAsset:text:en_US-components/common/ActionFeedback-1753121700619":{"__typename":"CachedAsset","id":"text:en_US-components/common/ActionFeedback-1753121700619","value":{"joinedGroupHub.title":"Welcome","joinedGroupHub.message":"You are now a member of this group and are subscribed to updates.","groupHubInviteNotFound.title":"Invitation Not Found","groupHubInviteNotFound.message":"Sorry, we could not find your invitation to the group. The owner may have canceled the invite.","groupHubNotFound.title":"Group Not Found","groupHubNotFound.message":"The grouphub you tried to join does not exist. It may have been deleted.","existingGroupHubMember.title":"Already Joined","existingGroupHubMember.message":"You are already a member of this group.","accountLocked.title":"Account Locked","accountLocked.message":"Your account has been locked due to multiple failed attempts. Try again in {lockoutTime} minutes.","editedGroupHub.title":"Changes Saved","editedGroupHub.message":"Your group has been updated.","leftGroupHub.title":"Goodbye","leftGroupHub.message":"You are no longer a member of this group and will not receive future updates.","deletedGroupHub.title":"Deleted","deletedGroupHub.message":"The group has been deleted.","groupHubCreated.title":"Group Created","groupHubCreated.message":"{groupHubName} is ready to use","accountClosed.title":"Account Closed","accountClosed.message":"The account has been closed and you will now be redirected to the homepage","resetTokenExpired.title":"Reset Password Link has Expired","resetTokenExpired.message":"Try resetting your password again","invalidUrl.title":"Invalid URL","invalidUrl.message":"The URL you're using is not recognized. Verify your URL and try again.","accountClosedForUser.title":"Account Closed","accountClosedForUser.message":"{userName}'s account is closed","inviteTokenInvalid.title":"Invitation Invalid","inviteTokenInvalid.message":"Your invitation to the community has been canceled or expired.","inviteTokenError.title":"Invitation Verification Failed","inviteTokenError.message":"The url you are utilizing is not recognized. Verify your URL and try again","pageNotFound.title":"Access Denied","pageNotFound.message":"You do not have access to this area of the community or it doesn't exist","eventAttending.title":"Responded as Attending","eventAttending.message":"You'll be notified when there's new activity and reminded as the event approaches","eventInterested.title":"Responded as Interested","eventInterested.message":"You'll be notified when there's new activity and reminded as the event approaches","eventNotFound.title":"Event Not Found","eventNotFound.message":"The event you tried to respond to does not exist.","redirectToRelatedPage.title":"Showing Related Content","redirectToRelatedPageForBaseUsers.title":"Showing Related Content","redirectToRelatedPageForBaseUsers.message":"The content you are trying to access is archived","redirectToRelatedPage.message":"The content you are trying to access is archived","relatedUrl.archivalLink.flyoutMessage":"The content you are trying to access is archived View Archived Content"},"localOverride":false},"CachedAsset:quiltWrapper:f5.prod:Common:1753121676321":{"__typename":"CachedAsset","id":"quiltWrapper:f5.prod:Common:1753121676321","value":{"id":"Common","header":{"backgroundImageProps":{"assetName":null,"backgroundSize":"COVER","backgroundRepeat":"NO_REPEAT","backgroundPosition":"CENTER_CENTER","lastModified":null,"__typename":"BackgroundImageProps"},"backgroundColor":"#343434","items":[{"id":"custom.widget.GainsightShared","props":{"widgetVisibility":"signedInOnly","useTitle":true,"useBackground":false,"title":"","lazyLoad":false},"__typename":"QuiltComponent"},{"id":"custom.widget.Beta_MetaNav","props":{"widgetVisibility":"signedInOrAnonymous","useTitle":true,"useBackground":false,"title":"","lazyLoad":false},"__typename":"QuiltComponent"},{"id":"community.widget.navbarWidget","props":{"showUserName":false,"showRegisterLink":true,"useIconLanguagePicker":true,"useLabelLanguagePicker":true,"style":{"boxShadow":"var(--lia-bs-box-shadow-sm)","linkFontWeight":"700","controllerHighlightColor":"#F29A36","dropdownDividerMarginBottom":"10px","hamburgerBorderHover":"none","linkFontSize":"15px","linkBoxShadowHover":"none","backgroundOpacity":1,"controllerBorderRadius":"var(--lia-border-radius-50)","hamburgerBgColor":"transparent","linkTextBorderBottom":"none","hamburgerColor":"var(--lia-nav-controller-icon-color)","brandLogoHeight":"48px","linkLetterSpacing":"normal","linkBgHoverColor":"transparent","collapseMenuDividerOpacity":0.16,"paddingBottom":"10px","dropdownPaddingBottom":"15px","dropdownMenuOffset":"2px","hamburgerBgHoverColor":"transparent","borderBottom":"unset","hamburgerBorder":"none","dropdownPaddingX":"10px","brandMarginRightSm":"10px","linkBoxShadow":"none","linkJustifyContent":"center","linkColor":"var(--lia-bs-white)","collapseMenuDividerBg":"var(--lia-nav-link-color)","dropdownPaddingTop":"10px","controllerHighlightTextColor":"var(--lia-yiq-dark)","controllerTextColor":"var(--lia-nav-controller-icon-color)","background":{"imageAssetName":"","color":"var(--lia-bs-body-color)","size":"COVER","repeat":"NO_REPEAT","position":"CENTER_CENTER","imageLastModified":""},"linkBorderRadius":"var(--lia-bs-border-radius-sm)","linkHoverColor":"var(--lia-bs-white)","position":"FIXED","linkBorder":"none","linkTextBorderBottomHover":"2px solid var(--lia-bs-white)","brandMarginRight":"30px","hamburgerHoverColor":"var(--lia-nav-controller-icon-color)","linkBorderHover":"none","collapseMenuMarginLeft":"20px","linkFontStyle":"NORMAL","linkPaddingX":"10px","controllerTextHoverColor":"var(--lia-nav-controller-icon-hover-color)","paddingTop":"10px","linkPaddingY":"5px","linkTextTransform":"NONE","dropdownBorderColor":"hsla(var(--lia-bs-white-h), var(--lia-bs-white-s), var(--lia-bs-white-l), 0.08)","controllerBgHoverColor":"hsla(var(--lia-bs-white-h), var(--lia-bs-white-s), var(--lia-bs-white-l), 0.1)","linkDropdownPaddingX":"var(--lia-nav-link-px)","linkBgColor":"transparent","linkDropdownPaddingY":"9px","controllerIconColor":"var(--lia-bs-white)","dropdownDividerMarginTop":"10px","linkGap":"10px","controllerIconHoverColor":"var(--lia-bs-white)"},"links":{"sideLinks":[],"logoLinks":[],"mainLinks":[{"children":[{"linkType":"INTERNAL","id":"migrated-link-1","params":{"boardId":"TechnicalForum","categoryId":"Forums"},"routeName":"ForumBoardPage"},{"linkType":"INTERNAL","id":"migrated-link-2","params":{"boardId":"WaterCooler","categoryId":"Forums"},"routeName":"ForumBoardPage"}],"linkType":"INTERNAL","id":"migrated-link-0","params":{"categoryId":"Forums"},"routeName":"CategoryPage"},{"children":[{"linkType":"INTERNAL","id":"migrated-link-4","params":{"boardId":"codeshare","categoryId":"CrowdSRC"},"routeName":"TkbBoardPage"},{"linkType":"INTERNAL","id":"migrated-link-5","params":{"boardId":"communityarticles","categoryId":"CrowdSRC"},"routeName":"TkbBoardPage"}],"linkType":"INTERNAL","id":"migrated-link-3","params":{"categoryId":"CrowdSRC"},"routeName":"CategoryPage"},{"children":[{"linkType":"INTERNAL","id":"migrated-link-7","params":{"boardId":"TechnicalArticles","categoryId":"Articles"},"routeName":"TkbBoardPage"},{"linkType":"INTERNAL","id":"article-series","params":{"boardId":"article-series","categoryId":"Articles"},"routeName":"TkbBoardPage"},{"linkType":"INTERNAL","id":"security-insights","params":{"boardId":"security-insights","categoryId":"Articles"},"routeName":"TkbBoardPage"},{"linkType":"INTERNAL","id":"migrated-link-8","params":{"boardId":"DevCentralNews","categoryId":"Articles"},"routeName":"TkbBoardPage"}],"linkType":"INTERNAL","id":"migrated-link-6","params":{"categoryId":"Articles"},"routeName":"CategoryPage"},{"children":[{"linkType":"INTERNAL","id":"migrated-link-10","params":{"categoryId":"CommunityGroups"},"routeName":"CategoryPage"},{"linkType":"INTERNAL","id":"migrated-link-11","params":{"categoryId":"F5-Groups"},"routeName":"CategoryPage"}],"linkType":"INTERNAL","id":"migrated-link-9","params":{"categoryId":"GroupsCategory"},"routeName":"CategoryPage"},{"children":[],"linkType":"INTERNAL","id":"migrated-link-12","params":{"boardId":"Events","categoryId":"top"},"routeName":"EventBoardPage"},{"children":[],"linkType":"INTERNAL","id":"migrated-link-13","params":{"boardId":"Suggestions","categoryId":"top"},"routeName":"IdeaBoardPage"},{"children":[],"linkType":"EXTERNAL","id":"Common-external-link","url":"https://community.f5.com/c/how-do-i","target":"SELF"}]},"className":"QuiltComponent_lia-component-edit-mode__lQ9Z6","showSearchIcon":false,"languagePickerStyle":"iconAndLabel"},"__typename":"QuiltComponent"},{"id":"community.widget.bannerWidget","props":{"backgroundColor":"#343434","visualEffects":{"showBottomBorder":false},"backgroundImageProps":{"backgroundSize":"COVER","backgroundPosition":"CENTER_CENTER","backgroundRepeat":"NO_REPEAT"},"fontColor":"var(--lia-bs-white)"},"__typename":"QuiltComponent"},{"id":"community.widget.breadcrumbWidget","props":{"backgroundColor":"#343434","linkHighlightColor":"#FFFFFF","visualEffects":{"showBottomBorder":true},"backgroundOpacity":100,"linkTextColor":"#FFFFFF"},"__typename":"QuiltComponent"}],"__typename":"QuiltWrapperSection"},"footer":{"backgroundImageProps":{"assetName":null,"backgroundSize":"COVER","backgroundRepeat":"NO_REPEAT","backgroundPosition":"CENTER_CENTER","lastModified":null,"__typename":"BackgroundImageProps"},"backgroundColor":"var(--lia-bs-body-color)","items":[{"id":"custom.widget.Beta_Footer","props":{"widgetVisibility":"signedInOrAnonymous","useTitle":true,"useBackground":false,"title":"","lazyLoad":false},"__typename":"QuiltComponent"},{"id":"custom.widget.Tag_Manager_Helper","props":{"widgetVisibility":"signedInOrAnonymous","useTitle":true,"useBackground":false,"title":"","lazyLoad":false},"__typename":"QuiltComponent"},{"id":"custom.widget.Consent_Blackbar","props":{"widgetVisibility":"signedInOrAnonymous","useTitle":true,"useBackground":false,"title":"","lazyLoad":false},"__typename":"QuiltComponent"}],"__typename":"QuiltWrapperSection"},"__typename":"QuiltWrapper","localOverride":false},"localOverride":false},"CachedAsset:component:custom.widget.GainsightShared-en-us-1753121706741":{"__typename":"CachedAsset","id":"component:custom.widget.GainsightShared-en-us-1753121706741","value":{"component":{"id":"custom.widget.GainsightShared","template":{"id":"GainsightShared","markupLanguage":"HTML","style":null,"texts":{},"defaults":{"config":{"applicablePages":[],"description":"Shared functions for Gainsight integration","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"components":[{"id":"custom.widget.GainsightShared","form":null,"config":null,"props":[],"__typename":"Component"}],"grouping":"TEXTHTML","__typename":"ComponentTemplate"},"properties":{"config":{"applicablePages":[],"description":"Shared functions for Gainsight integration","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"form":null,"__typename":"Component","localOverride":false},"globalCss":null,"form":null},"localOverride":false},"CachedAsset:component:custom.widget.Beta_MetaNav-en-us-1753121706741":{"__typename":"CachedAsset","id":"component:custom.widget.Beta_MetaNav-en-us-1753121706741","value":{"component":{"id":"custom.widget.Beta_MetaNav","template":{"id":"Beta_MetaNav","markupLanguage":"HANDLEBARS","style":null,"texts":{},"defaults":{"config":{"applicablePages":[],"description":"MetaNav menu at the top of every page.","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"components":[{"id":"custom.widget.Beta_MetaNav","form":null,"config":null,"props":[],"__typename":"Component"}],"grouping":"CUSTOM","__typename":"ComponentTemplate"},"properties":{"config":{"applicablePages":[],"description":"MetaNav menu at the top of every page.","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"form":null,"__typename":"Component","localOverride":false},"globalCss":null,"form":null},"localOverride":false},"CachedAsset:component:custom.widget.Beta_Footer-en-us-1753121706741":{"__typename":"CachedAsset","id":"component:custom.widget.Beta_Footer-en-us-1753121706741","value":{"component":{"id":"custom.widget.Beta_Footer","template":{"id":"Beta_Footer","markupLanguage":"HANDLEBARS","style":null,"texts":{},"defaults":{"config":{"applicablePages":[],"description":"DevCentral´s custom footer.","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"components":[{"id":"custom.widget.Beta_Footer","form":null,"config":null,"props":[],"__typename":"Component"}],"grouping":"CUSTOM","__typename":"ComponentTemplate"},"properties":{"config":{"applicablePages":[],"description":"DevCentral´s custom footer.","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"form":null,"__typename":"Component","localOverride":false},"globalCss":null,"form":null},"localOverride":false},"CachedAsset:component:custom.widget.Tag_Manager_Helper-en-us-1753121706741":{"__typename":"CachedAsset","id":"component:custom.widget.Tag_Manager_Helper-en-us-1753121706741","value":{"component":{"id":"custom.widget.Tag_Manager_Helper","template":{"id":"Tag_Manager_Helper","markupLanguage":"HANDLEBARS","style":null,"texts":{},"defaults":{"config":{"applicablePages":[],"description":"Helper widget to inject Tag Manager scripts into head element","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"components":[{"id":"custom.widget.Tag_Manager_Helper","form":null,"config":null,"props":[],"__typename":"Component"}],"grouping":"CUSTOM","__typename":"ComponentTemplate"},"properties":{"config":{"applicablePages":[],"description":"Helper widget to inject Tag Manager scripts into head element","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"form":null,"__typename":"Component","localOverride":false},"globalCss":null,"form":null},"localOverride":false},"CachedAsset:component:custom.widget.Consent_Blackbar-en-us-1753121706741":{"__typename":"CachedAsset","id":"component:custom.widget.Consent_Blackbar-en-us-1753121706741","value":{"component":{"id":"custom.widget.Consent_Blackbar","template":{"id":"Consent_Blackbar","markupLanguage":"HTML","style":null,"texts":{},"defaults":{"config":{"applicablePages":[],"description":"","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"components":[{"id":"custom.widget.Consent_Blackbar","form":null,"config":null,"props":[],"__typename":"Component"}],"grouping":"TEXTHTML","__typename":"ComponentTemplate"},"properties":{"config":{"applicablePages":[],"description":"","fetchedContent":null,"__typename":"ComponentConfiguration"},"props":[],"__typename":"ComponentProperties"},"form":null,"__typename":"Component","localOverride":false},"globalCss":null,"form":null},"localOverride":false},"CachedAsset:text:en_US-components/community/Breadcrumb-1753121700619":{"__typename":"CachedAsset","id":"text:en_US-components/community/Breadcrumb-1753121700619","value":{"navLabel":"Breadcrumbs","dropdown":"Additional parent page navigation"},"localOverride":false},"CachedAsset:text:en_US-components/tags/TagsHeaderWidget-1753121700619":{"__typename":"CachedAsset","id":"text:en_US-components/tags/TagsHeaderWidget-1753121700619","value":{"tag":"{tagName}","topicsCount":"{count} {count, plural, one {Topic} other {Topics}}"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageListForNodeByRecentActivityWidget-1753121700619":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageListForNodeByRecentActivityWidget-1753121700619","value":{"title@userScope:other":"Recent Content","title@userScope:self":"Contributions","title@board:FORUM@userScope:other":"Recent Discussions","title@board:BLOG@userScope:other":"Recent Blogs","emptyDescription":"No content to show","MessageListForNodeByRecentActivityWidgetEditor.nodeScope.label":"Scope","title@instance:1706288370055":"Content Feed","title@instance:1743095186784":"Most Recent Updates","title@instance:1704317906837":"Content Feed","title@instance:1743095018194":"Most Recent Updates","title@instance:1702668293472":"Community Feed","title@instance:1743095117047":"Most Recent Updates","title@instance:1704319314827":"Blog Feed","title@instance:1743095235555":"Most Recent Updates","title@instance:1704320290851":"My Contributions","title@instance:1703720491809":"Forum Feed","title@instance:1743095311723":"Most Recent Updates","title@instance:1703028709746":"Group Content Feed","title@instance:VTsglH":"Content Feed"},"localOverride":false},"Category:category:Forums":{"__typename":"Category","id":"category:Forums","categoryPolicies":{"__typename":"CategoryPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Forum:board:TechnicalForum":{"__typename":"Forum","id":"board:TechnicalForum","forumPolicies":{"__typename":"ForumPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Forum:board:WaterCooler":{"__typename":"Forum","id":"board:WaterCooler","forumPolicies":{"__typename":"ForumPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Tkb:board:DevCentralNews":{"__typename":"Tkb","id":"board:DevCentralNews","tkbPolicies":{"__typename":"TkbPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Category:category:GroupsCategory":{"__typename":"Category","id":"category:GroupsCategory","categoryPolicies":{"__typename":"CategoryPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Category:category:F5-Groups":{"__typename":"Category","id":"category:F5-Groups","categoryPolicies":{"__typename":"CategoryPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Category:category:CommunityGroups":{"__typename":"Category","id":"category:CommunityGroups","categoryPolicies":{"__typename":"CategoryPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Occasion:board:Events":{"__typename":"Occasion","id":"board:Events","boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"occasionPolicies":{"__typename":"OccasionPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Idea:board:Suggestions":{"__typename":"Idea","id":"board:Suggestions","boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"ideaPolicies":{"__typename":"IdeaPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Category:category:CrowdSRC":{"__typename":"Category","id":"category:CrowdSRC","categoryPolicies":{"__typename":"CategoryPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Tkb:board:codeshare":{"__typename":"Tkb","id":"board:codeshare","tkbPolicies":{"__typename":"TkbPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Tkb:board:communityarticles":{"__typename":"Tkb","id":"board:communityarticles","tkbPolicies":{"__typename":"TkbPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Tkb:board:security-insights":{"__typename":"Tkb","id":"board:security-insights","tkbPolicies":{"__typename":"TkbPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Tkb:board:article-series":{"__typename":"Tkb","id":"board:article-series","tkbPolicies":{"__typename":"TkbPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}},"boardPolicies":{"__typename":"BoardPolicies","canReadNode":{"__typename":"PolicyResult","failureReason":null}}},"Conversation:conversation:303142":{"__typename":"Conversation","id":"conversation:303142","topic":{"__typename":"TkbTopicMessage","uid":303142},"lastPostingActivityTime":"2023-02-07T10:30:03.247-08:00","solved":false},"User:user:418292":{"__typename":"User","uid":418292,"login":"Dave_Potter","registrationData":{"__typename":"RegistrationData","status":null},"deleted":false,"avatar":{"__typename":"UserAvatar","url":"https://community.f5.com/t5/s/zihoc95639/images/dS00MTgyOTItRnlyVUo0?image-coordinates=9%2C9%2C226%2C226"},"id":"user:418292"},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0zMDMxNDItMjAxOTBpMjlDRkVGMDg0MzA4NTIxMg?revision=10\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0zMDMxNDItMjAxOTBpMjlDRkVGMDg0MzA4NTIxMg?revision=10","title":"ruth-paradis-yhPIRUOdHVs-unsplash.jpg","associationType":"COVER","width":4608,"height":3072,"altText":""},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0zMDMxNDItMjAxOTFpMTM2MEFGNjUxQ0UwMjcwMg?revision=10\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0zMDMxNDItMjAxOTFpMTM2MEFGNjUxQ0UwMjcwMg?revision=10","title":"Slide2.jpeg","associationType":"BODY","width":1920,"height":1080,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0zMDMxNDItMjAxOTJpNjM4QzBCQ0I3OUJDNzQ5RQ?revision=10\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0zMDMxNDItMjAxOTJpNjM4QzBCQ0I3OUJDNzQ5RQ?revision=10","title":"Slide4.jpeg","associationType":"BODY","width":1920,"height":1080,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0zMDMxNDItMjAxOTNpMkJGQUEzQzkxRDg0MzkzMQ?revision=10\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0zMDMxNDItMjAxOTNpMkJGQUEzQzkxRDg0MzkzMQ?revision=10","title":"Slide5.jpeg","associationType":"BODY","width":1920,"height":1080,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0zMDMxNDItMjAxOTRpQTNCRTYxOTk5OERFOEE4Rg?revision=10\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0zMDMxNDItMjAxOTRpQTNCRTYxOTk5OERFOEE4Rg?revision=10","title":"CDN-WAAP-Step2 DNS.png","associationType":"BODY","width":1920,"height":1080,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0zMDMxNDItMjAxOTVpQ0VFODE1N0Q2OEZGMTNCOA?revision=10\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0zMDMxNDItMjAxOTVpQ0VFODE1N0Q2OEZGMTNCOA?revision=10","title":"CDN-WAAP-1.jpg","associationType":"BODY","width":1316,"height":314,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0zMDMxNDItMjAxOTZpQzA1RTdDQTI3QjVDMjhDNg?revision=10\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0zMDMxNDItMjAxOTZpQzA1RTdDQTI3QjVDMjhDNg?revision=10","title":"CDN-WAAP-Step4.png","associationType":"BODY","width":1920,"height":1080,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0zMDMxNDItMjAxOTdpOTNBREM0RUM4QjQwMEZCRg?revision=10\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0zMDMxNDItMjAxOTdpOTNBREM0RUM4QjQwMEZCRg?revision=10","title":"CDN-WAAP-Step5.png","associationType":"BODY","width":1920,"height":1080,"altText":null},"TkbTopicMessage:message:303142":{"__typename":"TkbTopicMessage","subject":"Use F5 Distributed Cloud to service chain WAAP and CDN","conversation":{"__ref":"Conversation:conversation:303142"},"id":"message:303142","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:303142","revisionNum":10,"uid":303142,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:418292"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":7860},"postTime":"2022-11-01T09:00:00.015-07:00","lastPublishTime":"2023-02-07T10:30:03.247-08:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" \n The Content Delivery Network (CDN) market has become increasingly commoditized. Many providers have augmented their CDN capabilities with WAFs/WAAPs, DNS, load balancing, edge compute, and networking. Managing all these solutions together creates a web of operational complexity, which can be confusing. \n F5’s synergistic bundling of CDN with Web Application and API Protection (WAAP) benefits those looking for simplicity and ease of use. It provides a way around the complications and silos that many resource-strapped organizations face with their IT systems. \n This bundling also signifies how CDN has become a commodity product often not purchased independently anymore. This trend is encouraging many competitors to evolve their capabilities to include edge computing – a space where F5 has gained considerable experience in recent years. \n F5 is rapidly catching up to other providers’ CDNs. F5’s experience and leadership building the world’s best-of-breed Application Delivery Controller (ADC), the BIG-IP load balancer, put it in a unique position to offer the best application delivery and security services directly at the edge with many of its CDN points of presence. With robust regional edge capabilities and a global network, F5 has entered the CDN space with a complementary offering to an already compelling suite of features. This includes the ability to run microservices and Kubernetes workloads anywhere, with a complete range of services to support app infrastructure deployment, scale, and lifecycle management all within a single management console. \n \n \n With advancements made in the application security space at F5, WAAP capabilities are directly integrated into the Distributed Cloud Platform to protect both web apps and APIs. Features include (yet not limited to): \n \n Web Application Firewall: Signature + Behavioral WAF functionality \n Bot Defense: Detect client signals, determining if clients are human or automated \n DDoS Mitigation: Fully managed by F5 \n API Security: Continuous inspection and detection of shadow APIs \n \n Solution \n Combining the Distributed Cloud WAAP with CDN as a form of service chaining is a straightforward process. This not only gives you the best security protection for web apps and APIs, but also positions apps regionally to deliver them with low latency and minimal compute per request. \n In the following solution, we’ve combined Distributed Cloud WAAP and CDN to globally deliver an app protected by a WAF policy from the closest regional point of presence to the user. Follow along as I demonstrate how to configure the basic elements. \n \n Configuration \n \n Log in to the Distributed Cloud Console and navigate to the DNS Management service. Decide if you want Distributed Cloud to manage the DNS zone as a Primary DNS server or if you’d rather delegate the fully qualified domain name (FQDN) for your app to Distributed Cloud with a CNAME. While using Delegation or Managed DNS is optional, doing so makes it possible for Distributed Cloud to automatically create and manage the SSL certificates needed to securely publish your app. \n \n Next, in Distributed Cloud Console, navigate to the Web App and API Protection service, then go to App Firewall, then Add App Firewall. This is where you’ll create the security policy that we’ll later connect our HTTP LB. Let’s use the following basic WAF policy in YAML format, you can paste it directly in to the Console by changing the configuration view to JSON and then changing the format to YAML. Note: This uses the namespace “waap-cdn”, change this to match your individual tenant’s configuration. \n metadata:\n name: buytime-waf\n namespace: waap-cdn\n labels: {}\n annotations: {}\n disable: false\nspec:\n blocking: {}\n detection_settings:\n signature_selection_setting:\n default_attack_type_settings: {}\n high_medium_low_accuracy_signatures: {}\n enable_suppression: {}\n enable_threat_campaigns: {}\n default_violation_settings: {}\n bot_protection_setting:\n malicious_bot_action: BLOCK\n suspicious_bot_action: REPORT\n good_bot_action: REPORT\n allow_all_response_codes: {}\n default_anonymization: {}\n use_default_blocking_page: {} \n With the WAF policy saved, it’s time to configure the origin server. Navigate to Load Balancers > Origin Pools, then Add Origin Pool. The following YAML uses a FQDN DNS name reach the app server. Using an IP address for the server is possible as well. \n metadata:\n name: buytime-pool\n namespace: waap-cdn\n labels: {}\n annotations: {}\n disable: false\nspec:\n origin_servers:\n - public_name:\n dns_name: webserver.f5-cloud-demo.com\n labels: {}\n no_tls: {}\n port: 80\n same_as_endpoint_port: {}\n healthcheck: []\n loadbalancer_algorithm: LB_OVERRIDE\n endpoint_selection: LOCAL_PREFERRED \n With the supporting WAF and Origin Pool resources configured, it’s time to create the HTTP Load Balancer. Navigate to Load Balancers > HTTP Load Balancers, then create a new one. Use the following YAML to create the LB and use both resources created above. \n metadata:\n name: buytime-online\n namespace: waap-cdn\n labels: {}\n annotations: {}\n disable: false\nspec:\n domains:\n - buytime.waap.f5-cloud-demo.com\n https_auto_cert:\n http_redirect: true\n add_hsts: true\n port: 443\n tls_config:\n default_security: {}\n no_mtls: {}\n default_header: {}\n enable_path_normalize: {}\n non_default_loadbalancer: {}\n header_transformation_type:\n default_header_transformation: {}\n advertise_on_public_default_vip: {}\n default_route_pools:\n - pool:\n tenant: your-tenant-uid\n namespace: waap-cdn\n name: buytime-pool\n kind: origin_pool\n weight: 1\n priority: 1\n endpoint_subsets: {}\n routes: []\n app_firewall:\n tenant: your-tenant-uid\n namespace: waap-cdn\n name: buytime-waf\n kind: app_firewall\n add_location: true\n no_challenge: {}\n user_id_client_ip: {}\n disable_rate_limit: {}\n waf_exclusion_rules: []\n data_guard_rules: []\n blocked_clients: []\n trusted_clients: []\n ddos_mitigation_rules: []\n service_policies_from_namespace: {}\n round_robin: {}\n disable_trust_client_ip_headers: {}\n disable_ddos_detection: {}\n disable_malicious_user_detection: {}\n disable_api_discovery: {}\n disable_bot_defense: {}\n disable_api_definition: {}\n disable_ip_reputation: {}\n disable_client_side_defense: {}\nresource_version: \"517528014\" \n With the HTTP LB successfully deployed, check that its status is ready on the status page. \n \n You can verify the LB is working by sending a basic request using the command line tool, curl. Confirm that the value of the HTTP header “Server” is “volt-adc”. \n da.potter@lab ~ % curl -I https://buytime.waap.f5-cloud-demo.com\nHTTP/2 200 \ndate: Mon, 17 Oct 2022 23:23:55 GMT\ncontent-type: text/html; charset=UTF-8\ncontent-length: 2200\nvary: Origin\naccess-control-allow-credentials: true\naccept-ranges: bytes\ncache-control: public, max-age=0\nlast-modified: Wed, 24 Feb 2021 11:06:36 GMT\netag: W/\"898-177d3b82260\"\nx-envoy-upstream-service-time: 136\nstrict-transport-security: max-age=31536000\nset-cookie: 1f945=1666049035840-557942247; Path=/; Domain=f5-cloud-demo.com; Expires=Sun, 17 Oct 2032 23:23:55 GMT\nset-cookie: 1f9403=viJrSNaAp766P6p6EKZK7nyhofjXCVawnskkzsrMBUZIoNQOEUqXFkyymBAGlYPNQXOUBOOYKFfs0ne+fKAT/ozN5PM4S5hmAIiHQ7JAh48P4AP47wwPqdvC22MSsSejQ0upD9oEhkQEeTG1Iro1N9sLh+w+CtFS7WiXmmJFV9FAl3E2; path=/\nx-volterra-location: wes-sea\nserver: volt-adc \n Now it’s time to configure the CDN Distribution and service chain it to the WAAP HTTP LB. Navigate to Content Delivery Network > Distributions, then Add Distribution. The following YAML creates a basic CDN configuration that uses the WAAP HTTP LB above. \n metadata:\n name: buytime-cdn\n namespace: waap-cdn\n labels: {}\n annotations: {}\n disable: false\nspec:\n domains:\n - buytime.f5-cloud-demo.com\n https_auto_cert:\n http_redirect: true\n add_hsts: true\n tls_config:\n tls_12_plus: {}\n add_location: false\n more_option:\n cache_ttl_options:\n cache_ttl_override: 1m\n origin_pool:\n public_name:\n dns_name: buytime.waap.f5-cloud-demo.com\n use_tls:\n use_host_header_as_sni: {}\n tls_config:\n default_security: {}\n volterra_trusted_ca: {}\n no_mtls: {}\n origin_servers:\n - public_name:\n dns_name: buytime.waap.f5-cloud-demo.com\n follow_origin_redirect: false\nresource_version: \"518473853\" \n After saving the configuration, verify that the status is “Active”. You can confirm the CDN deployment status for each individual region by going to the distribution’s action button “Show Global Status”, and scrolling down to each region to see that each region’s “site_status.status” value is “DEPLOYMENT_STATUS_DEPLOYED”. \n \n Verification \n With the CDN Distribution successfully deployed, it’s possible to confirm with the following basic request using curl. Take note of the two HTTP headers “Server” and “x-cache-status”. The Server value will now be “volt-cdn”, and the x-cache-status will be “MISS” for the first request. \n da.potter@lab ~ % curl -I https://buytime.f5-cloud-demo.com \nHTTP/2 200 \ndate: Mon, 17 Oct 2022 23:24:04 GMT\ncontent-type: text/html; charset=UTF-8\ncontent-length: 2200\nvary: Origin\naccess-control-allow-credentials: true\naccept-ranges: bytes\ncache-control: public, max-age=0\nlast-modified: Wed, 24 Feb 2021 11:06:36 GMT\netag: W/\"898-177d3b82260\"\nx-envoy-upstream-service-time: 63\nstrict-transport-security: max-age=31536000\nset-cookie: 1f945=1666049044863-471593352; Path=/; Domain=f5-cloud-demo.com; Expires=Sun, 17 Oct 2032 23:24:04 GMT\nset-cookie: 1f9403=aCNN1JINHqvWPwkVT5OH3c+OIl6+Ve9Xkjx/zfWxz5AaG24IkeYqZ+y6tQqE9CiFkNk+cnU7NP0EYtgGnxV0dLzuo3yHRi3dzVLT7PEUHpYA2YSXbHY6yTijHbj/rSafchaEEnzegqngS4dBwfe56pBZt52MMWsUU9x3P4yMzeeonxcr; path=/\nx-volterra-location: dal3-dal\nserver: volt-cdn\nx-cache-status: MISS\nstrict-transport-security: max-age=31536000 \n To see a security violation detected by the WAF in real-time, you can simulate a simple XSS exploit with the following curl: \n da.potter@lab ~ % curl -Gv \"https://buytime.f5-cloud-demo.com?<script>('alert:XSS')</script>\"\n* Trying x.x.x.x:443...\n* Connected to buytime.f5-cloud-demo.com (x.x.x.x) port 443 (#0)\n* ALPN, offering h2\n* ALPN, offering http/1.1\n* successfully set certificate verify locations:\n* CAfile: /etc/ssl/cert.pem\n* CApath: none\n* (304) (OUT), TLS handshake, Client hello (1):\n* (304) (IN), TLS handshake, Server hello (2):\n* TLSv1.2 (IN), TLS handshake, Certificate (11):\n* TLSv1.2 (IN), TLS handshake, Server key exchange (12):\n* TLSv1.2 (IN), TLS handshake, Server finished (14):\n* TLSv1.2 (OUT), TLS handshake, Client key exchange (16):\n* TLSv1.2 (OUT), TLS change cipher, Change cipher spec (1):\n* TLSv1.2 (OUT), TLS handshake, Finished (20):\n* TLSv1.2 (IN), TLS change cipher, Change cipher spec (1):\n* TLSv1.2 (IN), TLS handshake, Finished (20):\n* SSL connection using TLSv1.2 / ECDHE-ECDSA-AES256-GCM-SHA384\n* ALPN, server accepted to use h2\n* Server certificate:\n* subject: CN=buytime.f5-cloud-demo.com\n* start date: Oct 14 23:51:02 2022 GMT\n* expire date: Jan 12 23:51:01 2023 GMT\n* subjectAltName: host \"buytime.f5-cloud-demo.com\" matched cert's \"buytime.f5-cloud-demo.com\"\n* issuer: C=US; O=Let's Encrypt; CN=R3\n* SSL certificate verify ok.\n* Using HTTP2, server supports multiplexing\n* Connection state changed (HTTP/2 confirmed)\n* Copying HTTP/2 data in stream buffer to connection buffer after upgrade: len=0\n* Using Stream ID: 1 (easy handle 0x14f010000)\n> GET /?<script>('alert:XSS')</script> HTTP/2\n> Host: buytime.f5-cloud-demo.com\n> user-agent: curl/7.79.1\n> accept: */*\n> \n* Connection state changed (MAX_CONCURRENT_STREAMS == 128)!\n< HTTP/2 200 \n< date: Sat, 22 Oct 2022 01:04:39 GMT\n< content-type: text/html; charset=UTF-8\n< content-length: 269\n< cache-control: no-cache\n< pragma: no-cache\n< set-cookie: 1f945=1666400679155-452898837; Path=/; Domain=f5-cloud-demo.com; Expires=Fri, 22 Oct 2032 01:04:39 GMT\n< set-cookie: 1f9403=/1b+W13c7xNShbbe6zE3KKUDNPCGbxRMVhI64uZny+HFXxpkJMsCKmDWaihBD4KWm82reTlVsS8MumTYQW6ktFQqXeFvrMDFMSKdNSAbVT+IqQfSuVfVRfrtgRkvgzbDEX9TUIhp3xJV3R1jdbUuAAaj9Dhgdsven8FlCaADENYuIlBE; path=/\n< x-volterra-location: dal3-dal\n< server: volt-cdn\n< x-cache-status: MISS\n< strict-transport-security: max-age=31536000\n< \n<html><head><title>Request Rejected</title></head>\n<body>The requested URL was rejected. Please consult with your administrator.<br/><br/>\nYour support ID is 85281693-eb72-4891-9099-928ffe00869c<br/><br/><a href='javascript:history.back();'>[Go Back]</a></body></html>\n* Connection #0 to host buytime.f5-cloud-demo.com left intact \n Notice that the above request intentionally by-passes the CDN cache and is sent to the HTTP LB for the WAF policy to inspect. With this request rejected, you can confirm the attack by navigating to the WAAP HTTP LB Security page under the WAAP Security section within Apps & APIs. After refreshing the page, you’ll see the security violation under the “Top Attacked” panel. \n \n Demo \n To see all of this in action, watch my video below. This uses all of the configuration details above to make a WAAP + CDN service chain in Distributed Cloud. \n \n Additional Guides \n Virtually deploy this solution in our product simulator, or hands-on with step-by-step comprehensive demo guide. The demo guide includes all the steps, including those that are needed prior to deployment, so that once deployed, the solution works end-to-end without any tweaks to local DNS. The demo guide steps can also be automated with Ansible, in case you'd either like to replicate it or simply want to jump to the end and work your way back. \n Conclusion \n This shows just how simple it can be to use the Distributed Cloud CDN to frontend your web app protected by a WAF, all natively within the F5 Distributed Cloud’s regional edge POPs. The advantage of this solution should now be clear – the Distributed Cloud CDN is cloud-agnostic, flexible, agile, and you can enforce security policies anywhere, regardless of whether your web app lives on-prem, in and across clouds, or even at the edge. \n For more information about Distributed Cloud WAAP and Distributed Cloud CDN, visit the following resources: Product website: https://www.f5.com/cloud/products/cdn Distributed Cloud CDN & WAAP Demo Guide: https://github.com/f5devcentral/xcwaapcdnguide Video: https://youtu.be/OUD8R6j5Q8o Simulator: https://simulator.f5.com/s/waap-cdn Demo Guide: https://github.com/f5devcentral/xcwaapcdnguide \n ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"14788","kudosSumWeight":10,"repliesCount":0,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0zMDMxNDItMjAxOTBpMjlDRkVGMDg0MzA4NTIxMg?revision=10\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDI","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0zMDMxNDItMjAxOTFpMTM2MEFGNjUxQ0UwMjcwMg?revision=10\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDM","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0zMDMxNDItMjAxOTJpNjM4QzBCQ0I3OUJDNzQ5RQ?revision=10\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDQ","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0zMDMxNDItMjAxOTNpMkJGQUEzQzkxRDg0MzkzMQ?revision=10\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDU","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0zMDMxNDItMjAxOTRpQTNCRTYxOTk5OERFOEE4Rg?revision=10\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDY","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0zMDMxNDItMjAxOTVpQ0VFODE1N0Q2OEZGMTNCOA?revision=10\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDc","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0zMDMxNDItMjAxOTZpQzA1RTdDQTI3QjVDMjhDNg?revision=10\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDg","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0zMDMxNDItMjAxOTdpOTNBREM0RUM4QjQwMEZCRg?revision=10\"}"}}],"totalCount":8,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[{"__typename":"VideoEdge","cursor":"MHxodHRwczovL3lvdXR1LmJlL09VRDhSNmo1UThvfDB8MjU7MjV8fA","node":{"__typename":"AssociatedVideo","videoTag":{"__typename":"VideoTag","vid":"https://youtu.be/OUD8R6j5Q8o","thumbnail":"https://i.ytimg.com/vi/OUD8R6j5Q8o/hqdefault.jpg","uploading":false,"height":338,"width":600,"title":null},"videoAssociationType":"INLINE_BODY"}}],"totalCount":1,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"Conversation:conversation:308092":{"__typename":"Conversation","id":"conversation:308092","topic":{"__typename":"TkbTopicMessage","uid":308092},"lastPostingActivityTime":"2023-06-09T09:46:50.369-07:00","solved":false},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0zMDgwOTItMjE3MThpQTZEQTcwNTQxRkE3MTAwRQ?revision=10\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0zMDgwOTItMjE3MThpQTZEQTcwNTQxRkE3MTAwRQ?revision=10","title":"bryson-hammer-JZ8AHFr2aEg-unsplash.jpg","associationType":"COVER","width":1920,"height":1280,"altText":""},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0zMDgwOTItMjE2NDdpODVCRkE3RjlDMjYwQ0IyRg?revision=10\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0zMDgwOTItMjE2NDdpODVCRkE3RjlDMjYwQ0IyRg?revision=10","title":"Slide3.jpeg","associationType":"BODY","width":1920,"height":1080,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0zMDgwOTItMjE2NDlpNTEwQ0ZDQUE4RDlFQkU0MQ?revision=10\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0zMDgwOTItMjE2NDlpNTEwQ0ZDQUE4RDlFQkU0MQ?revision=10","title":"Slide4.jpeg","associationType":"BODY","width":1920,"height":1080,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0zMDgwOTItMjE2NzVpNTI3RDZDOTBDM0RDM0E0NQ?revision=10\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0zMDgwOTItMjE2NzVpNTI3RDZDOTBDM0RDM0E0NQ?revision=10","title":"Slide5.jpeg","associationType":"BODY","width":1128,"height":992,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0zMDgwOTItMjE2ODRpMDBBODJDRkU0MjgzNThCNQ?revision=10\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0zMDgwOTItMjE2ODRpMDBBODJDRkU0MjgzNThCNQ?revision=10","title":"SnagIt_1.jpg","associationType":"BODY","width":622,"height":198,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0zMDgwOTItMjE2ODVpNUUyNEJGQ0RBNDg2NERCQg?revision=10\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0zMDgwOTItMjE2ODVpNUUyNEJGQ0RBNDg2NERCQg?revision=10","title":"SnagIt_2.jpg","associationType":"BODY","width":504,"height":204,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0zMDgwOTItMjE2ODZpNkMwQjRFOEZDNEIyNTg3MA?revision=10\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0zMDgwOTItMjE2ODZpNkMwQjRFOEZDNEIyNTg3MA?revision=10","title":"SnagIt_3.jpg","associationType":"BODY","width":1099,"height":737,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0zMDgwOTItMjE2ODhpQTcxRDg0MzBFRjY0M0UzOA?revision=10\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0zMDgwOTItMjE2ODhpQTcxRDg0MzBFRjY0M0UzOA?revision=10","title":"SnagIt_4.jpg","associationType":"BODY","width":563,"height":477,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0zMDgwOTItMjE3MTJpNDkwRTA1Qzc0RjIyQThDMQ?revision=10\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0zMDgwOTItMjE3MTJpNDkwRTA1Qzc0RjIyQThDMQ?revision=10","title":"Slide8.jpeg","associationType":"BODY","width":1920,"height":1080,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0zMDgwOTItMjE3MTNpRDgwODhGNTg4RUQwRDQ2OQ?revision=10\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0zMDgwOTItMjE3MTNpRDgwODhGNTg4RUQwRDQ2OQ?revision=10","title":"SnagIt_5.jpg","associationType":"BODY","width":1131,"height":773,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0zMDgwOTItMjE3MTFpODE2RDQyRjlFQTI2Qzg5Rg?revision=10\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0zMDgwOTItMjE3MTFpODE2RDQyRjlFQTI2Qzg5Rg?revision=10","title":"SnagIt.jpg","associationType":"BODY","width":834,"height":455,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0zMDgwOTItMjE3MTZpOTY4Njk5Rjk0NDYzNkVBNg?revision=10\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0zMDgwOTItMjE3MTZpOTY4Njk5Rjk0NDYzNkVBNg?revision=10","title":"SnagIt2.jpg","associationType":"BODY","width":960,"height":475,"altText":null},"TkbTopicMessage:message:308092":{"__typename":"TkbTopicMessage","subject":"Using F5 Distributed Cloud private connectivity orchestration for secure multi-cloud infrastructure","conversation":{"__ref":"Conversation:conversation:308092"},"id":"message:308092","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:308092","revisionNum":10,"uid":308092,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:418292"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":2944},"postTime":"2023-01-15T19:07:54.805-08:00","lastPublishTime":"2023-06-09T09:46:50.369-07:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" \n Introduction \n Enterprise businesses use modern apps that access services in many locations. Users running productivity apps, like Office365, must connect to services in the cloud from on-prem locations. To keep this running well, enterprises must provide connectivity that’s fast, reliable, and private. \n \n Traditionally, it has taken many steps to create private connections to a public cloud subscription and route application specific traffic to it. F5 Distributed Cloud Platform orchestrates ExpressRoutes in Azure and Direct Connect services in AWS, eliminating many of the steps needed for routing end-to-end. Distributed Cloud private connectivity orchestration makes it easier than ever to connect and configure routing over existing private and dedicated circuits from on-prem locations to cloud services running in AWS and in Azure. \n The illustration below outlines the basic components to an ExpressRoute service in Azure but there’s a lot more you’ll need to know about just under the cover. \n Without orchestration, many steps are needed to enable routing between on-prem sites and Azure. This requires expert knowledge of Azure Networking, numerous dependent resources to be built, and advanced routing protocols knowledge -- specifically the Border Gateway Protocol (BGP). \n \n Extend on-prem network to a colo provider \n Create and provision the ExpressRoute Circuit \n Create a Virtual Network Gateway \n Create a connection between ExpressRoute Circuit & Virtual Network Gateway (VNG) \n Configure a Route Server to propagate routes between VNG and on-prem \n Configure user-defined routes on each subnet on each VNet in Azure \n \n Using Distributed Cloud to orchestrate ExpressRoutes in Azure and Direct Connect in AWS, the total number of steps is effectively reduced to just an essential few. Additional benefits include no longer needing to be an expert in Azure Networking or in BGP routing, and you get the ability to control connectivity with intent-based policies natively built into the Distributed Cloud Platform. An example of an intent-based policy is to configure VNet tagging in Azure to use with a firewall policy that just allow access to specific apps or by select users. Additional policies that support tagging include Distributed Cloud WAAP and Distributed Cloud App Infrastructure Protection. \n The following details cover the key components needed to support direct connectivity and show how to create the services and deploy a privately routed app in Distributed Cloud. \n Building ExpressRoute to Azure \n \n \n Extend on-prem network to a colo provider \n Create and provision the ExpressRoute Circuit \n Enable the ExpressRoute orchestration feature on an Azure VNet Site configured in Distributed Cloud \n \n \n To create an ExpressRoute orchestrated configuration in Distributed Cloud, navigate to Multi-Cloud Network Connect > Site Management > Azure VNET Sites > Add Azure VNET Site or Manage Configuration for an existing Site. Enter the required parameters, and when you reach the “Ingress Gateway or Ingress/Egress Gateway”, select “Ingress/Egress Gateway (Two Interface) …””. Here you have the option to deploy on a Recommended Region or an Alternate Region. This selection depends entirely on your business’ cloud deployment model. \n \n After choosing the model that best fits your environment, configure the number of Availability Zones for the Gateway and subnets (new/existing) that it will join and Apply the settings. Now scroll down to Advanced Options (enabling Advanced Fields) and Select VNet type: Hub VNet. Click “View Configuration”, and any existing VNet’s from your Azure Subscription that should inherit orchestrated routing. Next, change the “Express Route Configuration” to Enabled to expand the dropdown to access the ExpressRoute Circuit and Virtual Network Gateway settings. \n \n Under “* Connections”, add the ExpressRoute Circuit configuration for your Azure subscription(s). The required fields are the Name and the Express Route Circuit, this is the Resource ID for the circuit in Azure. \n \nNote: When configuring more than one circuit, you may want to also configure the Routing Weight for circuit preference. When configuring an express route circuit from another subscription (not shown below), you’ll also need an Authorization Key.\n For ease of deployment, it’s recommended to use the default values for the remaining fields, including for the Gateway SKU, Subnet for Azure VNet Gateway, and Subnet for Azure Route Server, including ASN Configuration for BGP between Site and Azure Route Servers. \n \n After the configuration is fully saved and deployed, with site status Applied on the Cloud Sites page, all resources in Azure will now be set to use ExpressRoute Circuit(s) for all designated L3 routed traffic. \n Next, we’ll configured the orchestration of Direct Connect in an AWS VPC connected site. AWS TGW connected sites are also support. \n Building Direct Connect for AWS \n \n To create a Direct Connect orchestrated configuration in Distributed Cloud, navigate to Multi-Cloud Network Connect > Site Management > AWS VPC Sites > Add AWS VPC Site or Manage Configuration for an existing Site. Enter the required parameters, and when you reach the “Ingress Gateway or Ingress/Egress Gateway”, choose the form factor that meets your deployment requirements. Scroll down to Advanced Configuration, enable Advanced Fields, and then Enable Direct Connect. \n \n Configuring the Direct Connect connection feature, choose either Hosted VIF or Standard VIF mode. Use Hosted VIF when you’re already using the Direct Connect connection for other purposes in AWS or when the VIF is in another AWS subscription. Otherwise, choosing Standard VIF allows Distributed Cloud to automatically create the VIF, and dependent services in AWS mentioned below to access the Direct Connect connection. Standard VIF mode creates the following additional resources in AWS: \n \n Virtual Gateway (VGW): associating it to the VPC and enabling route propagation to inside route tables \n Direct Connect Gateway (DCG): associating it to the VGW \n \n Note: In Standard VIF mode, at the end of the deployment admins may copy the direct connect gateway ID and use it to create other VIF’s. Admins may also copy the ASN. This is the AWS side of the ASN that’s needed by network ops teams to configure BGP peering. \n Note: In Hosted VIF mode, independent site deployment is responsible for: \n \n Creating VGW, and associating it to the VPC and enabling route propagation to inside route tables \n Creating DCG and associating it to the VGW \n Accepting the Hosted VIF and linking to the DCGW VIF \n \n Optionally, you may configure the Custom ASN if needed to work with an existing BGP configuration or choose Auto to let Distributed Cloud figure it out. Apply the config, save changes, and exit to the general Sites page. \n \n After the configuration is fully saved and deployed and having site status Applied on the Cloud Sites page, all resources in AWS will now be set to use the Direct Connect Gateway for all designated L3 routed traffic. \n Adding Private Connectivity On-Prem \n The final part to this deployment is routing both the ExpressRoute and Direct Connect circuits to an on-prem site. Both circuits must terminate at a colo space, and then standard IT/NetOps teams handle the routing outside the realm of Distributed Cloud to the destination. \n Building a Distributed App w/ Private Connectivity \n With Distributed Cloud having orchestrated the routing to each site’s workload, and IT/NetOps configured routing on-prem, including propagating the on-prem routes on BGP, an app with components that work independently can now be accessed as one unified interface. \n \n An example of a distributed app that run perfectly in this environment is the demo app, Arcadia Finance. This app has four components: \n \n Main – Frontend Web interface \n API – An App module accessed by Main to support money transfers \n Refer-A-Friend (Not used) – An App module interface accessed by Main to invite friends \n Backend – A DB server that stores money transfer accounts used by the API module, stock portfolio positions used by the Main module, and email addresses saved by the Refer-A-Friend module. \n \n Functionally, the connection flow is as follows: \n \n Users access a VIP advertised by an F5 Global Network Regional Edge to the Internet \n User traffic is connected to the Main (frontend) app running in AWS via the F5 Global Network \n Main App connects to API in Azure to load the money-transfer side frame, and then to the Backend DB on-prem to load the stocks portfolio balances. These connections transit the private connectivity links created in this article. \n API App in Azure connects to the Backend DB on-prem to retrieve money transfer accounts. This connection transits the private connectivity links created in this article. \n \n To support this topology and configuration, the apps are divided and run as follows: \n AWS \n \n Frontend (nginx) \n Main (Web) \n Refer-A-Friend \n \n Azure \n \n API (App) \n \n On-Prem \n \n Backend (DB) \n \n To make the app reachable to users, use the Distributed Cloud console Sites Distributed Apps feature to create one HTTP Load Balancer with the VIP advertised to the Internet, and with the origin pool of the Frontend (nginx) app. Note: This step assumes that you have previously created a fully connected AWS CE Site with connectivity to your VPC’s and a Direct Connect circuit in the section above. \n Navigate to Multi-Cloud App Connect > Manage > Load Balancers > Origin Pools, create a new origin pool. In the pool creation menu, at the top, select “JSON” and change the format to YAML, then paste the following example, changing the specific values, such as the namespace, to match your environment: \n metadata:\n name: mcn-aws-workload-pool\n namespace: mcn-privatelinks\n labels:\n ves.io/app_type: arcadia\n annotations: {}\n disable: false\nspec:\n origin_servers:\n - private_ip:\n ip: 10.100.2.238\n site_locator:\n site:\n tenant: acmecorp-tnxbsial\n namespace: system\n name: soln-eng-aws-dc\n kind: site\n inside_network: {}\n labels: {}\n no_tls: {}\n port: 8000\n same_as_endpoint_port: {}\n loadbalancer_algorithm: LB_OVERRIDE\n endpoint_selection: LOCAL_PREFERRED \n With the origin pool created, navigate to Distributed Apps > Manage > Load Balancers > HTTP Load Balancers, and add a new one with the following YAML provided as an example: \n metadata:\n name: mcn-arcadia-frontend\n namespace: mcn-privatelinks\n labels:\n ves.io/app_type: arcadia\n annotations: {}\n disable: false\nspec:\n domains:\n - mcn-arcadia-frontend.demo.internal\n http:\n dns_volterra_managed: false\n port: 80\n downstream_tls_certificate_expiration_timestamps: []\n advertise_on_public_default_vip: {}\n default_route_pools:\n - pool:\n tenant: acmecorp-tnxbsial\n namespace: mcn-privatelinks\n name: mcn-aws-workload-pool\n kind: origin_pool\n weight: 1\n priority: 1\n endpoint_subsets: {} \n \n Internally verify end-to-end connectivity \n Opening a command line shell to the Frontend Web App, a variation of traceroute with the tool hping3 and using curl, reveals each hop identified as privately connected along with connectivity established directly to the destination working without an intermediary. \n The following IP addresses are used to support a TCP connection from the Frontend (Web) app running in AWS to the API app running in Azure: \n \n 10.100.2.238 (Source): Frontend (Web) \n 172.18.0.1: Container host node \n 192.168.1.6: AWS Direct Connect Gateway \n 192.168.1.5: On-Prem router \n 192.168.1.22: Azure ExpressRoute Circuit endpoint \n 10.101.1.5 (Destination): App (API) \n \n In the CLI output, note each hop and the value in the HTTP Response header “Server”: \n root@1e40062cb314:/etc/nginx# hping3 -ST -p 8080 api\nHPING api (eth2 10.101.1.5): S set, 40 headers + 0 data bytes\nhop=1 TTL 0 during transit from ip=172.18.0.1 name=UNKNOWN \nhop=1 hoprtt=7.7 ms\nhop=2 TTL 0 during transit from ip=192.168.1.6 name=UNKNOWN \nhop=2 hoprtt=31.4 ms\nhop=3 TTL 0 during transit from ip=192.168.1.5 name=UNKNOWN \nhop=3 hoprtt=67.3 ms\nhop=4 TTL 0 during transit from ip=192.168.1.22 name=UNKNOWN \nhop=4 hoprtt=67.2 ms\n^C\n--- api hping statistic ---\n8 packets transmitted, 4 packets received, 50% packet loss\nround-trip min/avg/max = 7.7/43.4/67.3 ms root@1e40062cb314:/etc/nginx# curl -v api:8080\n* Rebuilt URL to: api:8080/\n* Hostname was NOT found in DNS cache\n* Trying 10.101.1.5...\n* Connected to api (10.101.1.5) port 8080 (#0)\n> GET / HTTP/1.1\n> User-Agent: curl/7.35.0\n> Host: api:8080\n> Accept: */*\n>\n< HTTP/1.1 200 OK\n* Server nginx/1.18.0 (Ubuntu) is not blacklisted\n< Server: nginx/1.18.0 (Ubuntu)\n< Date: Thu, 12 Jan 2023 18:59:32 GMT\n< Content-Type: text/html\n< Content-Length: 612\n< Last-Modified: Fri, 11 Nov 2022 03:24:47 GMT\n< Connection: keep-alive\n< ETag: \"636dc07f-264\"\n< Accept-Ranges: bytes \n \n Conclusion \n As more services continue to be deployed to and run in the cloud, dedicated, reliable, and secure private connectivity is increasingly required by Enterprises. Establishing connectivity is not a rudimentary task and requires the assistance of many hands in different departments. Distributed Cloud private connectivity orchestration helps streamline this process by eliminating many of the steps required in each cloud provider, including no longer requiring dedicated cloud and routing protocol experts just to configure these services manually. \n To see all of this in action and to see how all the parts come together, watch the following video, a companion to this article. \n \n Visit the following resources for more information about this feature and other Distributed Cloud services: \n Multi-Cloud Network Connect Product Information \n Direct Connect orchestration for AWS TGW Sites \n Direct Connect orchestration for AWS VPC Sites \n ExpressRoutes orchestration for Azure VNet Sites \n YouTube Video \n ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"14412","kudosSumWeight":8,"repliesCount":0,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0zMDgwOTItMjE3MThpQTZEQTcwNTQxRkE3MTAwRQ?revision=10\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDI","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0zMDgwOTItMjE2NDdpODVCRkE3RjlDMjYwQ0IyRg?revision=10\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDM","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0zMDgwOTItMjE2NDlpNTEwQ0ZDQUE4RDlFQkU0MQ?revision=10\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDQ","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0zMDgwOTItMjE2NzVpNTI3RDZDOTBDM0RDM0E0NQ?revision=10\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDU","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0zMDgwOTItMjE2ODRpMDBBODJDRkU0MjgzNThCNQ?revision=10\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDY","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0zMDgwOTItMjE2ODVpNUUyNEJGQ0RBNDg2NERCQg?revision=10\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDc","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0zMDgwOTItMjE2ODZpNkMwQjRFOEZDNEIyNTg3MA?revision=10\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDg","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0zMDgwOTItMjE2ODhpQTcxRDg0MzBFRjY0M0UzOA?revision=10\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDk","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0zMDgwOTItMjE3MTJpNDkwRTA1Qzc0RjIyQThDMQ?revision=10\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDEw","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0zMDgwOTItMjE3MTNpRDgwODhGNTg4RUQwRDQ2OQ?revision=10\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDEx","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0zMDgwOTItMjE3MTFpODE2RDQyRjlFQTI2Qzg5Rg?revision=10\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDEy","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0zMDgwOTItMjE3MTZpOTY4Njk5Rjk0NDYzNkVBNg?revision=10\"}"}}],"totalCount":12,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[{"__typename":"VideoEdge","cursor":"MHxodHRwczovL3lvdXR1LmJlL1ZjOUF2UFVwQmlJfDB8MjU7MjV8fA","node":{"__typename":"AssociatedVideo","videoTag":{"__typename":"VideoTag","vid":"https://youtu.be/Vc9AvPUpBiI","thumbnail":"https://i.ytimg.com/vi/Vc9AvPUpBiI/hqdefault.jpg","uploading":false,"height":338,"width":600,"title":null},"videoAssociationType":"INLINE_BODY"}}],"totalCount":1,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"Conversation:conversation:285459":{"__typename":"Conversation","id":"conversation:285459","topic":{"__typename":"TkbTopicMessage","uid":285459},"lastPostingActivityTime":"2022-11-28T10:31:58.851-08:00","solved":false},"User:user:171720":{"__typename":"User","uid":171720,"login":"Lori_MacVittie","registrationData":{"__typename":"RegistrationData","status":null},"deleted":false,"avatar":{"__typename":"UserAvatar","url":"https://community.f5.com/t5/s/zihoc95639/m_assets/avatars/default/avatar-10.svg?time=0"},"id":"user:171720"},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODU0NTktMTIyMjlpOTRFRDVDOUQ2N0FGNTNGRA?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODU0NTktMTIyMjlpOTRFRDVDOUQ2N0FGNTNGRA?revision=1","title":"0151T000003d880QAA.jpg","associationType":"BODY","width":285,"height":222,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODU0NTktNjQ5MGk2QjIyNUZBODg0OEVGM0Qy?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODU0NTktNjQ5MGk2QjIyNUZBODg0OEVGM0Qy?revision=1","title":"0151T000003d884QAA.jpg","associationType":"BODY","width":263,"height":225,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODU0NTktMTA4MTBpNUYwNzgyOEEwODkxM0I3Mg?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODU0NTktMTA4MTBpNUYwNzgyOEEwODkxM0I3Mg?revision=1","title":"0151T000003d883QAA.jpg","associationType":"BODY","width":240,"height":194,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODU0NTktMTMyMTNpMzYxMDQ0QzhFQ0ZCNUNEQg?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODU0NTktMTMyMTNpMzYxMDQ0QzhFQ0ZCNUNEQg?revision=1","title":"0151T000003d882QAA.jpg","associationType":"BODY","width":240,"height":194,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODU0NTktMTU2MDVpNEQwNkJENUFEODA3OUUyNw?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODU0NTktMTU2MDVpNEQwNkJENUFEODA3OUUyNw?revision=1","title":"0151T000003d881QAA.jpg","associationType":"BODY","width":240,"height":168,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODU0NTktNTM3MGk3MUYxMEFFNUNDMzcyNEU3?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODU0NTktNTM3MGk3MUYxMEFFNUNDMzcyNEU3?revision=1","title":"0151T000003d4RSQAY.png","associationType":"BODY","width":129,"height":129,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODU0NTktNzY2NGk3QzFFMDE4MDg4NjlEQ0E4?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODU0NTktNzY2NGk3QzFFMDE4MDg4NjlEQ0E4?revision=1","title":"0151T000003d4RTQAY.gif","associationType":"BODY","width":18,"height":18,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODU0NTktMTM1MzlpQTg2RDEyODQ4RjI0MDI3OQ?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODU0NTktMTM1MzlpQTg2RDEyODQ4RjI0MDI3OQ?revision=1","title":"0151T000003d4RUQAY.png","associationType":"BODY","width":16,"height":16,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODU0NTktMzE2OGlCMDdCRTdFNDQxNDZEQzY0?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODU0NTktMzE2OGlCMDdCRTdFNDQxNDZEQzY0?revision=1","title":"0151T000003d4RVQAY.gif","associationType":"BODY","width":16,"height":16,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODU0NTktMjI1OGlCRTlBODg1MTJBOEFGNjM3?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODU0NTktMjI1OGlCRTlBODg1MTJBOEFGNjM3?revision=1","title":"0151T000003d4RWQAY.png","associationType":"BODY","width":16,"height":16,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODU0NTktOTYzNGk5NEE2Qjk3NTMwNDg4QzlD?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODU0NTktOTYzNGk5NEE2Qjk3NTMwNDg4QzlD?revision=1","title":"0151T000003d4RXQAY.png","associationType":"BODY","width":16,"height":16,"altText":null},"TkbTopicMessage:message:285459":{"__typename":"TkbTopicMessage","subject":"The Concise Guide to Proxies","conversation":{"__ref":"Conversation:conversation:285459"},"id":"message:285459","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:285459","revisionNum":1,"uid":285459,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:171720"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":4436},"postTime":"2008-10-02T05:01:17.000-07:00","lastPublishTime":"2008-10-02T05:01:17.000-07:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" We often mention that the benefits derived from some application delivery controllers are due to the nature of being a full proxy. And in the same breath we might mention reverse, half, and forward proxies, which makes the technology sound more like a description of the positions on a sports team than an application delivery solution. So what does these terms really mean? Here's the lowdown on the different kinds of proxies in one concise guide. PROXIES Proxies (often called intermediaries in the SOA world) are hardware or software solutions that sit between the client and the server and do something to requests and sometimes responses. The most often heard use of the term proxy is in conjunction with anonymizing Web surfing. That's because proxies sit between your browser and your desired destination and proxy the connection; that is you talk to the proxy while the proxy talks to the web server and neither you nor the web server know about each other. Proxies are not all the same. Some are half proxies, some are full proxies; some are forward and some are reverse. Yes, that came excruciatingly close to sounding like a Dr. Seuss book. (Go ahead, you know you want to. You may even remember this from .. .well, when it was first circulated.) FORWARD PROXIES Forward proxies are probably the most well known of all proxies, primarily because most folks have dealt with them either directly or indirectly. Forward proxies are those proxies that sit between two networks, usually a private internal network and the public Internet. Forward proxies have also traditionally been employed by large service providers as a bridge between their isolated network of subscribers and the public Internet, such as CompuServe and AOL in days gone by. These are often referred to as \"mega-proxies\" because they managed such high volumes of traffic. Forward proxies are generally HTTP (Web) proxies that provide a number of services but primarily focus on web content filtering and caching services. These forward proxies often include authentication and authorization as a part of their product to provide more control over access to public content. If you've ever gotten a web page that says \"Your request has been denied by blah blah blah. If you think this is an error please contact the help desk/your administrator\" then you've probably used a forward proxy. REVERSE PROXIES A reverse proxy is less well known, generally because we don't use the term anymore to describe products used as such. Load balancers (application delivery controllers) and caches are good examples of reverse proxies. Reverse proxies sit in front of web and application servers and process requests for applications and content coming in from the public Internet to the internal, private network. This is the primary reason for the appellation \"reverse\" proxy - to differentiate it from a proxy that handles outbound requests. Reverse proxies are also generally focused on HTTP but in recent years have expanded to include a number of other protocols commonly used on the web such as streaming audio (RTSP), file transfers (FTP), and generally any application protocol capable of being delivered via UDP or TCP. HALF PROXIES Half-proxy is a description of the way in which a proxy, reverse or forward, handles connections. There are two uses of the term half-proxy: one describing a deployment configuration that affects the way connections are handled and one that describes simply the difference between a first and subsequent connections. The deployment focused definition of half-proxy is associated with a direct server return (DSR) configuration. Requests are proxied by the device, but the responses do not return through the device, but rather are sent directly to the client. For some types of data - particularly streaming protocols - this configuration results in improved performance. This configuration is known as a half-proxy because only half the connection (incoming) is proxied while the other half, the response, is not. The second use of the term \"half-proxy\" describes a solution in which the proxy performs what is known as delayed binding in order to provide additional functionality. This allows the proxy to examine the request before determining where to send it. Once the proxy determines where to route the request, the connection between the client and the server are \"stitched\" together. This is referred to as a half-proxy because the initial TCP handshaking and first requests are proxied by the solution, but subsequently forwarded without interception. Half proxies can look at incoming requests in order to determine where the connection should be sent and can even use techniques to perform layer 7 inspection, but they are rarely capable of examining the responses. Almost all half-proxies fall into the category of reverse proxies. FULL PROXIES Full proxy is also a description of the way in which a proxy, reverse or forward, handles connections. A full proxy maintains two separate connections - one between itself and the client and one between itself and the destination server. A full proxy completely understands the protocols, and is itself an endpoint and an originator for the protocols. Full proxies are named because they completely proxy connections - incoming and outgoing. Because the full proxy is an actual protocol endpoint, it must fully implement the protocols as both a client and a server (a packet-based design does not). This also means the full proxy can have its own TCP connection behavior, such as buffering, retransmits, and TCP options. With a full proxy, each connection is unique; each can have its own TCP connection behavior. This means that a client connecting to the full proxy device would likely have different connection behavior than the full proxy might use for communicating with servers. Full proxies can look at incoming requests and outbound responses and can manipulate both if the solution allows it. Many reverse and forward proxies use a full proxy model today. There is no guarantee that a given solution is a full proxy, so you should always ask your solution provider if it is important to you that the solution is a full proxy. ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"6322","kudosSumWeight":2,"repliesCount":12,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODU0NTktMTIyMjlpOTRFRDVDOUQ2N0FGNTNGRA?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDI","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODU0NTktNjQ5MGk2QjIyNUZBODg0OEVGM0Qy?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDM","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODU0NTktMTA4MTBpNUYwNzgyOEEwODkxM0I3Mg?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDQ","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODU0NTktMTMyMTNpMzYxMDQ0QzhFQ0ZCNUNEQg?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDU","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODU0NTktMTU2MDVpNEQwNkJENUFEODA3OUUyNw?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDY","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODU0NTktNTM3MGk3MUYxMEFFNUNDMzcyNEU3?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDc","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODU0NTktNzY2NGk3QzFFMDE4MDg4NjlEQ0E4?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDg","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODU0NTktMTM1MzlpQTg2RDEyODQ4RjI0MDI3OQ?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDk","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODU0NTktMzE2OGlCMDdCRTdFNDQxNDZEQzY0?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDEw","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODU0NTktMjI1OGlCRTlBODg1MTJBOEFGNjM3?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDEx","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODU0NTktOTYzNGk5NEE2Qjk3NTMwNDg4QzlD?revision=1\"}"}}],"totalCount":11,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"Conversation:conversation:340332":{"__typename":"Conversation","id":"conversation:340332","topic":{"__typename":"TkbTopicMessage","uid":340332},"lastPostingActivityTime":"2025-04-01T15:25:22.118-07:00","solved":false},"User:user:275883":{"__typename":"User","uid":275883,"login":"Tony_Marfil","registrationData":{"__typename":"RegistrationData","status":null},"deleted":false,"avatar":{"__typename":"UserAvatar","url":"https://community.f5.com/t5/s/zihoc95639/images/dS0yNzU4ODMtQ2o3aUZ6?image-coordinates=0%2C0%2C3022%2C3022"},"id":"user:275883"},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0zNDAzMzItRmRnNW9V?revision=3\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0zNDAzMzItRmRnNW9V?revision=3","title":"computerTherm.jpg","associationType":"TEASER","width":980,"height":721,"altText":""},"TkbTopicMessage:message:340332":{"__typename":"TkbTopicMessage","subject":"Simplifying Application Health Monitoring with F5 BIG-IP","conversation":{"__ref":"Conversation:conversation:340332"},"id":"message:340332","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:340332","revisionNum":3,"uid":340332,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:275883"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":" ","introduction":"","metrics":{"__typename":"MessageMetrics","views":329},"postTime":"2025-03-27T05:00:00.030-07:00","lastPublishTime":"2025-04-01T15:25:22.118-07:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" A simple agreement between BIG-IP administrators and application owners can foster smooth collaboration between teams. Application owners define their own simple or complex health monitors and agree to expose a conventional /health endpoint. When a /health endpoint responds with an HTTP 200 request, BIG-IP assumes the application is healthy based on the application owners' own criteria. \n The Challenge of Health Monitoring in Modern Environments \n F5 BIG-IP administrators in Network Operations (NetOps) teams often work with application teams because the BIG-IP acts as a full proxy, providing services like: \n \n TLS termination \n Load balancing \n Health monitoring \n \n Health checks are crucial for effective load balancing. The BIG-IP uses them to determine where to send traffic among back-end application servers. However, health monitoring frequently causes friction between teams. \n Problems with the Traditional Approach \n Traditionally, BIG-IP administrators create and maintain health monitors ranging from simple ICMP pings to complex monitors that: \n \n Simulate user transactions \n Verify HTTP response codes \n Validate payload contents \n Track application dependencies \n \n This leads to several issues: \n \n Knowledge Gap: NetOps may not fully grasp each application's intricacies. \n Change Management Overhead: Application updates require retesting monitors, causing delays. \n Production Risk: Monitors can break after application changes, incorrectly marking services as up/down. \n Team Friction: Troubleshooting failed health checks involves tedious back-and-forth between teams. \n \n A Cloud-Native Solution \n The cloud-native and microservices communities have patterns that elegantly solve these problems. One widely used pattern is the [health endpoint], which adapts well to BIG-IP environments. \n The /health Endpoint Convention \n Cloud-native applications commonly expose dedicated health endpoints like /health, /healthy, or /ready. These return standard status codes reflecting the application's state. \n The /health endpoint provides a clear contract between NetOps and application teams for BIG-IP integration. \n Implementing the Contract \n This approach establishes a simple agreement: \n Application Team Responsibilities: \n \n Implement /health to return HTTP 200 when the application is ready for traffic \n Define \"healthy\" based on application needs (database connectivity, dependencies, etc.) \n Maintain the health check logic as the application changes \n \n BIG-IP Team Responsibilities: \n \n Configure an HTTP monitor targeting the /health endpoint \n Treat 200 as \"healthy\", anything else as \"unhealthy\" \n \n Benefits of This Approach \n \n Aligned Expertise: Application teams define health based on their knowledge. \n Less Friction: BIG-IP configuration stays stable as applications evolve. \n Better Reliability: Health checks reflect true application health, including dependencies. \n Easier Troubleshooting: The /health endpoint can return detailed diagnostic info, but this is ignored by the BIG-IP and used strictly for troubleshooting. \n \n Implementation Examples \n F5 BIG-IP Health Monitor Configuration \n ltm monitor http /Common/app-health-monitor { \n defaults-from /Common/http\n destination *:*\n interval 5 \n recv 200\n recv-disable none\n send \"GET /health HTTP/1.1\\r\\nHost: example.com\\r\\nConnection: close\\r\\n\\r\\n\"\n time-until-up 0\n timeout 16 \n} \n \n Node.js Health Endpoint Implementation \n const express = require('express');\nconst app = express();\nconst port = 3000;\n\napp.get('/', (req, res) => {\n res.send('Application is running'); \n});\n\napp.get('/health', async (req, res) => {\n try {\n const dbStatus = await checkDatabaseConnection();\n const serviceStatus = await checkDependentServices();\n \n if (dbStatus && serviceStatus) {\n return res.status(200).json({\n status: 'healthy',\n database: 'connected', \n services: 'available',\n timestamp: new Date().toISOString()\n });\n }\n \n res.status(503).json({\n status: 'unhealthy', \n database: dbStatus ? 'connected' : 'disconnected',\n services: serviceStatus ? 'available' : 'unavailable', \n timestamp: new Date().toISOString()\n });\n \n } catch (error) {\n res.status(500).json({\n status: 'error',\n message: error.message,\n timestamp: new Date().toISOString() \n });\n }\n});\n\nasync function checkDatabaseConnection() {\n // Check real database connection\n return true; \n}\n\nasync function checkDependentServices() {\n // Check required service connections\n return true;\n}\n\napp.listen(port, () => {\n console.log(`Application listening at http://localhost:${port}`);\n}); \n \n Adopting this health check pattern can greatly reduce friction between NetOps and application teams while improving reliability. The simple contract of HTTP 200 for healthy provides the needed integration while letting each team focus on their expertise. \n For apps that can't implement a custom /health endpoint, BIG-IP admins can still use traditional ICMP or TCP port monitoring. However, these basic checks can't accurately reflect an app's true health and complex dependencies. \n This approach fosters collaboration and leverages the specialized knowledge of both network and application teams. The result is more reliable services and smoother operations. ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"5441","kudosSumWeight":1,"repliesCount":0,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0zNDAzMzItRmRnNW9V?revision=3\"}"}}],"totalCount":1,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"Conversation:conversation:286089":{"__typename":"Conversation","id":"conversation:286089","topic":{"__typename":"TkbTopicMessage","uid":286089},"lastPostingActivityTime":"2017-10-24T07:11:41.000-07:00","solved":false},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYwODktNTkzNWlDNTFGRUY3RUIyMkRGOUQ5?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYwODktNTkzNWlDNTFGRUY3RUIyMkRGOUQ5?revision=1","title":"0151T000003d7vHQAQ.png","associationType":"BODY","width":443,"height":314,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYwODktMTUwOThpRTUzRTUzMjJDODFFREJCMQ?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYwODktMTUwOThpRTUzRTUzMjJDODFFREJCMQ?revision=1","title":"0151T000003d7ljQAA.png","associationType":"BODY","width":493,"height":300,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYwODktMTA4MDBpREEyNzc5QTZCRTI3RTQwNw?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYwODktMTA4MDBpREEyNzc5QTZCRTI3RTQwNw?revision=1","title":"0151T000003d4HeQAI.png","associationType":"BODY","width":129,"height":129,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYwODktMTA1NzlpMEUyMzcxRDMwMjE0QjIwQQ?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYwODktMTA1NzlpMEUyMzcxRDMwMjE0QjIwQQ?revision=1","title":"0151T000003d4HfQAI.gif","associationType":"BODY","width":18,"height":18,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYwODktNTMxNmlBOEM2RTdBQUQ3RDMxMTcx?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYwODktNTMxNmlBOEM2RTdBQUQ3RDMxMTcx?revision=1","title":"0151T000003d4HmQAI.png","associationType":"BODY","width":16,"height":16,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYwODktNTQ4MmlGQzM0RDg1RjAyQTZDQ0Mw?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYwODktNTQ4MmlGQzM0RDg1RjAyQTZDQ0Mw?revision=1","title":"0151T000003d4IgQAI.png","associationType":"BODY","width":16,"height":16,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYwODktMTMzNjBpMjA1REZBREVFOUNENUU1NA?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYwODktMTMzNjBpMjA1REZBREVFOUNENUU1NA?revision=1","title":"0151T000003d8I1QAI.jpg","associationType":"BODY","width":16,"height":16,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYwODktNTMzNmk1MEQ1NTNEOTc0RTJDQjAx?revision=1\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYwODktNTMzNmk1MEQ1NTNEOTc0RTJDQjAx?revision=1","title":"0151T000003d8MMQAY.png","associationType":"BODY","width":16,"height":16,"altText":null},"TkbTopicMessage:message:286089":{"__typename":"TkbTopicMessage","subject":"WILS: Virtual Server versus Virtual IP Address","conversation":{"__ref":"Conversation:conversation:286089"},"id":"message:286089","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:286089","revisionNum":1,"uid":286089,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:171720"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":3020},"postTime":"2009-12-28T05:00:00.000-08:00","lastPublishTime":"2009-12-28T05:00:00.000-08:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" load balancing intermediaries have long used the terms “virtual server” and “virtual IP address”. With the widespread adoption of virtualization these terms have become even more confusing to the uninitiated. Here’s how load balancing and application delivery use the terminology. \n\n \n\n I often find it easiest to explain the difference between a “virtual server” and a “virtual IP address (VIP)” by walking through the flow of traffic as it is received from the client. \n\n When a client queries for “www.yourcompany.com” they get an IP address, of course. In many cases if the site is served by a load balancer or application delivery controller that IP address is a virtual IP address. That simply means the IP address is not tied to a specific host. It’s kind of floating out there, waiting for requests. It’s more like a taxi than a public bus in that a public bus has a predefined route from which it does not deviate. A taxi, however, can take you wherever you want within the confines of its territory. In the case of a virtual IP address that territory is the set of virtual servers and services offered by the organization. \n\n The client (the browser, probably) uses the virtual IP address to make a request to “www.yourcompany.com” for a particular resource such as a web application (HTTP) or to send an e-mail (SMTP). Using the VIP and a TCP port appropriate for the resource, the application delivery controller directs the request to a “virtual server”. The virtual server is also an abstraction. It doesn’t really “exist” anywhere but in the application delivery controller’s configuration. The virtual server determines – via myriad options – which pool of resources will best serve to meet the user’s request. That pool of resources contains “nodes”, which ultimately map to one (or more) physical or virtual web/application servers (or mail servers, or X servers). \n\n A virtual IP address can represent multiple virtual servers and the correct mapping between them is generally accomplished by further delineating virtual servers by TCP destination port. So a single virtual IP address can point to a virtual “HTTP” server, a virtual “SMTP” server, a virtual “SSH” server, etc… Each virtual “X” server is a separate instantiation, all essentially listening on the same virtual IP address. \n\n It is also true, however, that a single virtual server can be represented by multiple virtual IP addresses. So “www1” and “www2” may represent different virtual IP addresses, but they might both use the same virtual server. This allows an application delivery controller to make routing decisions based on the host name, so “images.yourcompany.com” and “content.yourcompany.com” might resolve to the same virtual IP address and the same virtual server, but the “pool” of resources to which requests for images is directed will be different than the “pool” of resources to which content is directed. This allows for greater flexibility in architecture and scalability of resources at the content-type and application level rather than at the server level. \n\n WILS: Write It Like Seth. Seth Godin always gets his point across with brevity and wit. WILS is an ATTEMPT TO BE concise about application delivery TOPICS AND just get straight to the point. NO DILLY DALLYING AROUND. \n\n \n\n \n\n Server Virtualization versus Server Virtualization Architects Need to Better Leverage Virtualization Using \"X-Forwarded-For\" in Apache or PHP SNAT Translation Overflow WILS: Client IP or Not Client IP, SNAT is the Question WILS: Why Does Load Balancing Improve Application Performance? WILS: The Concise Guide to *-Load Balancing WILS: Network Load Balancing versus Application Load Balancing All WILS Topics on DevCentral If Load Balancers Are Dead Why Do We Keep Talking About Them? ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"3891","kudosSumWeight":1,"repliesCount":1,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYwODktNTkzNWlDNTFGRUY3RUIyMkRGOUQ5?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDI","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYwODktMTUwOThpRTUzRTUzMjJDODFFREJCMQ?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDM","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYwODktMTA4MDBpREEyNzc5QTZCRTI3RTQwNw?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDQ","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYwODktMTA1NzlpMEUyMzcxRDMwMjE0QjIwQQ?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDU","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYwODktNTMxNmlBOEM2RTdBQUQ3RDMxMTcx?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDY","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYwODktNTQ4MmlGQzM0RDg1RjAyQTZDQ0Mw?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDc","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYwODktMTMzNjBpMjA1REZBREVFOUNENUU1NA?revision=1\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDg","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODYwODktNTMzNmk1MEQ1NTNEOTc0RTJDQjAx?revision=1\"}"}}],"totalCount":8,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"Conversation:conversation:282793":{"__typename":"Conversation","id":"conversation:282793","topic":{"__typename":"TkbTopicMessage","uid":282793},"lastPostingActivityTime":"2023-03-23T04:49:00.974-07:00","solved":false},"User:user:321706":{"__typename":"User","uid":321706,"login":"PSilva","registrationData":{"__typename":"RegistrationData","status":null},"deleted":false,"avatar":{"__typename":"UserAvatar","url":"https://community.f5.com/t5/s/zihoc95639/images/dS0zMjE3MDYtMjE0NTFpRDA4NDA4QzE2MUZCREM5NA"},"id":"user:321706"},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODI3OTMtMTI1ODhpOUIwMzkwRERDMDU5MTBGOQ?revision=2\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODI3OTMtMTI1ODhpOUIwMzkwRERDMDU5MTBGOQ?revision=2","title":"0151T000003d5rsQAA.png","associationType":"BODY","width":950,"height":40,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODI3OTMtMzQzMGlDMTUyNUNBOTlGRjYzMDE3?revision=2\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODI3OTMtMzQzMGlDMTUyNUNBOTlGRjYzMDE3?revision=2","title":"0151T000003d6wZQAQ.png","associationType":"BODY","width":749,"height":415,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODI3OTMtMTU1NDZpMzFDNkUzMkI2NTQ2QTYzRA?revision=2\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODI3OTMtMTU1NDZpMzFDNkUzMkI2NTQ2QTYzRA?revision=2","title":"0151T000003d6waQAA.png","associationType":"BODY","width":820,"height":353,"altText":null},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODI3OTMtMTA4MjBpNkM1ODVGNkIxNkQ4OUE4RQ?revision=2\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yODI3OTMtMTA4MjBpNkM1ODVGNkIxNkQ4OUE4RQ?revision=2","title":"0EM1T000001Mr9x.png","associationType":"BODY","width":1024,"height":388,"altText":null},"TkbTopicMessage:message:282793":{"__typename":"TkbTopicMessage","subject":"What is Load Balancing?","conversation":{"__ref":"Conversation:conversation:282793"},"id":"message:282793","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:282793","revisionNum":2,"uid":282793,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:321706"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":22759},"postTime":"2017-01-23T03:00:00.000-08:00","lastPublishTime":"2023-03-23T04:49:00.974-07:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" \n tl;dr - Load Balancing is the process of distributing data across disparate services to provide redundancy, reliability, and improve performance. \n The entire intent of load balancing is to create a system that virtualizes the \"service\" from the physical servers that actually run that service. A more basic definition is to balance the load across a bunch of physical servers and make those servers look like one great big server to the outside world. There are many reasons to do this, but the primary drivers can be summarized as \"scalability,\" \"high availability,\" and \"predictability.\" \n Scalability is the capability of dynamically, or easily, adapting to increased load without impacting existing performance. Service virtualization presented an interesting opportunity for scalability; if the service, or the point of user contact, was separated from the actual servers, scaling of the application would simply mean adding more servers or cloud resources which would not be visible to the end user. \n High Availability (HA) is the capability of a site to remain available and accessible even during the failure of one or more systems. Service virtualization also presented an opportunity for HA; if the point of user contact was separated from the actual servers, the failure of an individual server would not render the entire application unavailable. Predictability is a little less clear as it represents pieces of HA as well as some lessons learned along the way. However, predictability can best be described as the capability of having confidence and control in how the services are being delivered and when they are being delivered in regards to availability, performance, and so on. \n A Little Background \n Back in the early days of the commercial Internet, many would-be dot-com millionaires discovered a serious problem in their plans. Mainframes didn't have web server software (not until the AS/400e, anyway) and even if they did, they couldn't afford them on their start-up budgets. What they could afford was standard, off-the-shelf server hardware from one of the ubiquitous PC manufacturers. The problem for most of them? There was no way that a single PC-based server was ever going to handle the amount of traffic their idea would generate and if it went down, they were offline and out of business. Fortunately, some of those folks actually had plans to make their millions by solving that particular problem; thus was born the load balancing market. \n In the Beginning, There Was DNS \n Before there were any commercially available, purpose-built load balancing devices, there were many attempts to utilize existing technology to achieve the goals of scalability and HA. The most prevalent, and still used, technology was DNS round-robin. Domain name system (DNS) is the service that translates human-readable names (www.example.com) into machine recognized IP addresses. DNS also provided a way in which each request for name resolution could be answered with multiple IP addresses in different order. \n \n Figure 1: Basic DNS response for redundancy \n The first time a user requested resolution for www.example.com, the DNS server would hand back multiple addresses (one for each server that hosted the application) in order, say 1, 2, and 3. The next time, the DNS server would give back the same addresses, but this time as 2, 3, and 1. This solution was simple and provided the basic characteristics of what customer were looking for by distributing users sequentially across multiple physical machines using the name as the virtualization point. \n From a scalability standpoint, this solution worked remarkable well; probably the reason why derivatives of this method are still in use today particularly in regards to global load balancing or the distribution of load to different service points around the world. As the service needed to grow, all the business owner needed to do was add a new server, include its IP address in the DNS records, and voila, increased capacity. One note, however, is that DNS responses do have a maximum length that is typically allowed, so there is a potential to outgrow or scale beyond this solution. \n This solution did little to improve HA. First off, DNS has no capability of knowing if the servers listed are actually working or not, so if a server became unavailable and a user tried to access it before the DNS administrators knew of the failure and removed it from the DNS list, they might get an IP address for a server that didn't work. \n Proprietary Load Balancing in Software \n One of the first purpose-built solutions to the load balancing problem was the development of load balancing capabilities built directly into the application software or the operating system (OS) of the application server. While there were as many different implementations as there were companies who developed them, most of the solutions revolved around basic network trickery. For example, one such solution had all of the servers in a cluster listen to a \"cluster IP\" in addition to their own physical IP address. \n \n Figure 2: Proprietary cluster IP load balancing \n When the user attempted to connect to the service, they connected to the cluster IP instead of to the physical IP of the server. Whichever server in the cluster responded to the connection request first would redirect them to a physical IP address (either their own or another system in the cluster) and the service session would start. One of the key benefits of this solution is that the application developers could use a variety of information to determine which physical IP address the client should connect to. For instance, they could have each server in the cluster maintain a count of how many sessions each clustered member was already servicing and have any new requests directed to the least utilized server. \n Initially, the scalability of this solution was readily apparent. All you had to do was build a new server, add it to the cluster, and you grew the capacity of your application. Over time, however, the scalability of application-based load balancing came into question. Because the clustered members needed to stay in constant contact with each other concerning who the next connection should go to, the network traffic between the clustered members increased exponentially with each new server added to the cluster. The scalability was great as long as you didn't need to exceed a small number of servers. \n HA was dramatically increased with these solutions. However, since each iteration of intelligence-enabling HA characteristics had a corresponding server and network utilization impact, this also limited scalability. The other negative HA impact was in the realm of reliability. \n Network-Based Load balancing Hardware \n The second iteration of purpose-built load balancing came about as network-based appliances. These are the true founding fathers of today's Application Delivery Controllers. Because these boxes were application-neutral and resided outside of the application servers themselves, they could achieve their load balancing using much more straight-forward network techniques. In essence, these devices would present a virtual server address to the outside world and when users attempted to connect, it would forward the connection on the most appropriate real server doing bi-directional network address translation (NAT). \n \n Figure 3: Load balancing with network-based hardware \n The load balancer could control exactly which server received which connection and employed \"health monitors\" of increasing complexity to ensure that the application server (a real, physical server) was responding as needed; if not, it would automatically stop sending traffic to that server until it produced the desired response (indicating that the server was functioning properly). Although the health monitors were rarely as comprehensive as the ones built by the application developers themselves, the network-based hardware approach could provide at least basic load balancing services to nearly every application in a uniform, consistent manner—finally creating a truly virtualized service entry point unique to the application servers serving it. \n Scalability with this solution was only limited by the throughput of the load balancing equipment and the networks attached to it. It was not uncommon for organization replacing software-based load balancing with a hardware-based solution to see a dramatic drop in the utilization of their servers. HA was also dramatically reinforced with a hardware-based solution. Predictability was a core component added by the network-based load balancing hardware since it was much easier to predict where a new connection would be directed and much easier to manipulate. \n The advent of the network-based load balancer ushered in a whole new era in the architecture of applications. HA discussions that once revolved around \"uptime\" quickly became arguments about the meaning of \"available\" (if a user has to wait 30 seconds for a response, is it available? What about one minute?). \n This is the basis from which Application Delivery Controllers (ADCs) originated. \n The ADC \n Simply put, ADCs are what all good load balancers grew up to be. While most ADC conversations rarely mention load balancing, without the capabilities of the network-based hardware load balancer, they would be unable to affect application delivery at all. Today, we talk about security, availability, and performance, but the underlying load balancing technology is critical to the execution of all. \n Next Steps \n Ready to plunge into the next level of Load Balancing? Take a peek at these resources: \n \n Go Beyond POLB (Plain Old Load Balancing) \n The Cloud-Ready ADC \n BIG-IP Virtual Edition Products, The Virtual ADCs Your Application Delivery Network Has Been Missing \n Cloud Balancing: The Evolution of Global Server Load Balancing \n ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"9970","kudosSumWeight":1,"repliesCount":1,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODI3OTMtMTI1ODhpOUIwMzkwRERDMDU5MTBGOQ?revision=2\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDI","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODI3OTMtMzQzMGlDMTUyNUNBOTlGRjYzMDE3?revision=2\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDM","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODI3OTMtMTU1NDZpMzFDNkUzMkI2NTQ2QTYzRA?revision=2\"}"}},{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDQ","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yODI3OTMtMTA4MjBpNkM1ODVGNkIxNkQ4OUE4RQ?revision=2\"}"}}],"totalCount":4,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"Conversation:conversation:273759":{"__typename":"Conversation","id":"conversation:273759","topic":{"__typename":"TkbTopicMessage","uid":273759},"lastPostingActivityTime":"2023-03-22T17:50:08.744-07:00","solved":false},"User:user:50312":{"__typename":"User","uid":50312,"login":"Don_MacVittie_1","registrationData":{"__typename":"RegistrationData","status":null},"deleted":false,"avatar":{"__typename":"UserAvatar","url":"https://community.f5.com/t5/s/zihoc95639/m_assets/avatars/default/avatar-2.svg?time=0"},"id":"user:50312"},"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzM3NTktMTg3MWlGNEEzNzMwNTg2OEY0QjZE?revision=2\"}":{"__typename":"AssociatedImage","url":"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzM3NTktMTg3MWlGNEEzNzMwNTg2OEY0QjZE?revision=2","title":"0151T000003d4gFQAQ.jpg","associationType":"BODY","width":205,"height":216,"altText":null},"TkbTopicMessage:message:273759":{"__typename":"TkbTopicMessage","subject":"Intro to Load Balancing for Developers – The Algorithms","conversation":{"__ref":"Conversation:conversation:273759"},"id":"message:273759","entityType":"TKB_ARTICLE","eventPath":"category:Articles/community:zihoc95639board:TechnicalArticles/message:273759","revisionNum":2,"uid":273759,"depth":0,"board":{"__ref":"Tkb:board:TechnicalArticles"},"author":{"__ref":"User:user:50312"},"teaser@stripHtml({\"removeProcessingText\":true,\"truncateLength\":-1})":"","introduction":"","metrics":{"__typename":"MessageMetrics","views":21612},"postTime":"2009-03-31T23:02:19.000-07:00","lastPublishTime":"2023-03-22T17:50:08.744-07:00","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})":" \n If you’re new to this series, you can find the complete list of articles in the series on my personal page here \n If you are writing applications to sit behind a Load Balancer, it behooves you to at least have a clue what the algorithm your load balancer uses is about. We’re taking this week’s installment to just chat about the most common algorithms and give a plain- programmer description of how they work. While historically the algorithm chosen is both beyond the developers’ control, you’re the one that has to deal with performance problems, so you should know what is happening in the application’s ecosystem, not just in the application. Anything that can slow your application down or introduce errors is something worth having reviewed. \n For algorithms supported by the BIG-IP, the text here is paraphrased/modified versions of the help text associated with the Pool Member tab of the BIG-IP UI. If they wrote a good description and all I needed to do was programmer-ize it, then I used it. For algorithms not supported by the BIG-IP I wrote from scratch. Note that there are many, many more algorithms out there, but as you read through here you’ll see why these (or minor variants of them) are the ones you’ll see the most. \n Plain Programmer Description: Is not intended to say anything about the way any particular dev team at F5 or any other company writes these algorithms, they’re just an attempt to put the process into terms that are easier for someone with a programming background to understand. Hopefully a successful attempt. \n Interestingly enough, I’ve pared down what BIG-IP supports to a subset. That means that F5 employees and aficionados will be going “But you didn’t mention…!” and non-F5 employees will likely say “But there’s the Chi-Squared Algorithm…!” (no, chi-squared is theoretical distribution method I know of because it was presented as a proof for testing the randomness of a 20 sided die, ages ago in Dragon Magazine). The point being that I tried to stick to a group that builds on each other in some connected fashion. So send me hate mail… I’m good. Unless you can say more than 2-5% of the world’s load balancers are running the algorithm, I won’t consider that I missed something important. The point is to give developers and software architects a familiarity with core algorithms, not to build the worlds most complete lexicon of algorithms. \n \n Random: This load balancing method randomly distributes load across the servers available, picking one via random number generation and sending the current connection to it. While it is available on many load balancing products, its usefulness is questionable except where uptime is concerned – and then only if you detect down machines. \n \n \n Plain Programmer Description: The system builds an array of Servers being load balanced, and uses the random number generator to determine who gets the next connection… Far from an elegant solution, and most often found in large software packages that have thrown load balancing in as a feature. \n \n \n Round Robin: Round Robin passes each new connection request to the next server in line, eventually distributing connections evenly across the array of machines being load balanced. Round Robin works well in most configurations, but could be better if the equipment that you are load balancing is not roughly equal in processing speed, connection speed, and/or memory. \n \n \n Plain Programmer Description: The system builds a standard circular queue and walks through it, sending one request to each machine before getting to the start of the queue and doing it again. While I’ve never seen the code (or actual load balancer code for any of these for that matter), we’ve all written this queue with the modulus function before. In school if nowhere else. \n \n \n Weighted Round Robin (called Ratio on the BIG-IP): With this method, the number of connections that each machine receives over time is proportionate to a ratio weight you define for each machine. This is an improvement over Round Robin because you can say “Machine 3 can handle 2x the load of machines 1 and 2”, and the load balancer will send two requests to machine #3 for each request to the others. \n \n \n Plain Programmer Description: The simplest way to explain for this one is that the system makes multiple entries in the Round Robin circular queue for servers with larger ratios. So if you set ratios at 3:2:1:1 for your four servers, that’s what the queue would look like – 3 entries for the first server, two for the second, one each for the third and fourth. In this version, the weights are set when the load balancing is configured for your application and never change, so the system will just keep looping through that circular queue. Different vendors use different weighting systems – whole numbers, decimals that must total 1.0 (100%), etc. but this is an implementation detail, they all end up in a circular queue style layout with more entries for larger ratings. \n \n \n Dynamic Round Robin (Called Dynamic Ratio on the BIG-IP): is similar to Weighted Round Robin, however, weights are based on continuous monitoring of the servers and are therefore continually changing. This is a dynamic load balancing method, distributing connections based on various aspects of real-time server performance analysis, such as the current number of connections per node or the fastest node response time. This Application Delivery Controller method is rarely available in a simple load balancer. \n \n \n Plain Programmer Description: If you think of Weighted Round Robin where the circular queue is rebuilt with new (dynamic) weights whenever it has been fully traversed, you’ll be dead-on. \n \n \n Fastest: The Fastest method passes a new connection based on the fastest response time of all servers. This method may be particularly useful in environments where servers are distributed across different logical networks. On the BIG-IP, only servers that are active will be selected. \n \n \n Plain Programmer Description: The load balancer looks at the response time of each attached server and chooses the one with the best response time. This is pretty straight-forward, but can lead to congestion because response time right now won’t necessarily be response time in 1 second or two seconds. Since connections are generally going through the load balancer, this algorithm is a lot easier to implement than you might think, as long as the numbers are kept up to date whenever a response comes through. \n \n \n These next three I use the BIG-IP name for. They are variants of a generalized algorithm sometimes called Long Term Resource Monitoring. \n \n \n Least Connections: With this method, the system passes a new connection to the server that has the least number of current connections. Least Connections methods work best in environments where the servers or other equipment you are load balancing have similar capabilities. This is a dynamic load balancing method, distributing connections based on various aspects of real-time server performance analysis, such as the current number of connections per node or the fastest node response time. This Application Delivery Controller method is rarely available in a simple load balancer. \n \n \n Plain Programmer Description: This algorithm just keeps track of the number of connections attached to each server, and selects the one with the smallest number to receive the connection. Like fastest, this can cause congestion when the connections are all of different durations – like if one is loading a plain HTML page and another is running a JSP with a ton of database lookups. Connection counting just doesn’t account for that scenario very well. \n \n \n Observed: The Observed method uses a combination of the logic used in the Least Connections and Fastest algorithms to load balance connections to servers being load-balanced. With this method, servers are ranked based on a combination of the number of current connections and the response time. Servers that have a better balance of fewest connections and fastest response time receive a greater proportion of the connections. This Application Delivery Controller method is rarely available in a simple load balancer. \n \n \n Plain Programmer Description: This algorithm tries to merge Fastest and Least Connections, which does make it more appealing than either one of the above than alone. In this case, an array is built with the information indicated (how weighting is done will vary, and I don’t know even for F5, let alone our competitors), and the element with the highest value is chosen to receive the connection. This somewhat counters the weaknesses of both of the original algorithms, but does not account for when a server is about to be overloaded – like when three requests to that query-heavy JSP have just been submitted, but not yet hit the heavy work. \n \n \n Predictive: The Predictive method uses the ranking method used by the Observed method, however, with the Predictive method, the system analyzes the trend of the ranking over time, determining whether a servers performance is currently improving or declining. The servers in the specified pool with better performance rankings that are currently improving, rather than declining, receive a higher proportion of the connections. The Predictive methods work well in any environment. This Application Delivery Controller method is rarely available in a simple load balancer. \n \n \n Plain Programmer Description: This method attempts to fix the one problem with Observed by watching what is happening with the server. If its response time has started going down, it is less likely to receive the packet. Again, no idea what the weightings are, but an array is built and the most desirable is chosen. \n \n \n You can see with some of these algorithms that persistent connections would cause problems. Like Round Robin, if the connections persist to a server for as long as the user session is working, some servers will build a backlog of persistent connections that slow their response time. The Long Term Resource Monitoring algorithms are the best choice if you have a significant number of persistent connections. Fastest works okay in this scenario also if you don’t have access to any of the dynamic solutions. \n \n That’s it for this week, next week we’ll start talking specifically about Application Delivery Controllers and what they offer – which is a whole lot – that can help your application in a variety of ways. \n Until then! \n Don. ","body@stripHtml({\"removeProcessingText\":true,\"removeSpoilerMarkup\":true,\"removeTocMarkup\":true,\"truncateLength\":-1})@stringLength":"10535","kudosSumWeight":1,"repliesCount":9,"readOnly":false,"images":{"__typename":"AssociatedImageConnection","edges":[{"__typename":"AssociatedImageEdge","cursor":"MjUuNHwyLjF8b3wyNXxfTlZffDE","node":{"__ref":"AssociatedImage:{\"url\":\"https://community.f5.com/t5/s/zihoc95639/images/bS0yNzM3NTktMTg3MWlGNEEzNzMwNTg2OEY0QjZE?revision=2\"}"}}],"totalCount":1,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}},"videos":{"__typename":"VideoConnection","edges":[],"totalCount":0,"pageInfo":{"__typename":"PageInfo","hasNextPage":false,"endCursor":null,"hasPreviousPage":false,"startCursor":null}}},"CachedAsset:text:en_US-components/community/Navbar-1753121700619":{"__typename":"CachedAsset","id":"text:en_US-components/community/Navbar-1753121700619","value":{"community":"Community Home","inbox":"Inbox","manageContent":"Manage Content","tos":"Terms of Service","forgotPassword":"Forgot Password","themeEditor":"Theme Editor","edit":"Edit Navigation Bar","skipContent":"Skip to content","migrated-link-9":"Groups","migrated-link-7":"Technical Articles","migrated-link-8":"DevCentral News","migrated-link-1":"Technical Forum","migrated-link-10":"Community Groups","migrated-link-2":"Water Cooler","migrated-link-11":"F5 Groups","Common-external-link":"How Do I...?","migrated-link-0":"Forums","article-series":"Article Series","migrated-link-5":"Community Articles","migrated-link-6":"Articles","security-insights":"Security Insights","migrated-link-3":"CrowdSRC","migrated-link-4":"CodeShare","migrated-link-12":"Events","migrated-link-13":"Suggestions"},"localOverride":false},"CachedAsset:text:en_US-components/community/NavbarHamburgerDropdown-1753121700619":{"__typename":"CachedAsset","id":"text:en_US-components/community/NavbarHamburgerDropdown-1753121700619","value":{"hamburgerLabel":"Side Menu"},"localOverride":false},"CachedAsset:text:en_US-components/community/BrandLogo-1753121700619":{"__typename":"CachedAsset","id":"text:en_US-components/community/BrandLogo-1753121700619","value":{"logoAlt":"Khoros","themeLogoAlt":"Brand Logo"},"localOverride":false},"CachedAsset:text:en_US-components/community/NavbarTextLinks-1753121700619":{"__typename":"CachedAsset","id":"text:en_US-components/community/NavbarTextLinks-1753121700619","value":{"more":"More"},"localOverride":false},"CachedAsset:text:en_US-components/authentication/AuthenticationLink-1753121700619":{"__typename":"CachedAsset","id":"text:en_US-components/authentication/AuthenticationLink-1753121700619","value":{"title.login":"Sign In","title.registration":"Register","title.forgotPassword":"Forgot Password","title.multiAuthLogin":"Sign In"},"localOverride":false},"CachedAsset:text:en_US-components/nodes/NodeLink-1753121700619":{"__typename":"CachedAsset","id":"text:en_US-components/nodes/NodeLink-1753121700619","value":{"place":"Place {name}"},"localOverride":false},"CachedAsset:text:en_US-components/tags/TagSubscriptionAction-1753121700619":{"__typename":"CachedAsset","id":"text:en_US-components/tags/TagSubscriptionAction-1753121700619","value":{"success.follow.title":"Following Tag","success.unfollow.title":"Unfollowed Tag","success.follow.message.followAcrossCommunity":"You will be notified when this tag is used anywhere across the community","success.unfollowtag.message":"You will no longer be notified when this tag is used anywhere in this place","success.unfollowtagAcrossCommunity.message":"You will no longer be notified when this tag is used anywhere across the community","unexpected.error.title":"Error - Action Failed","unexpected.error.message":"An unidentified problem occurred during the action you took. Please try again later.","buttonTitle":"{isSubscribed, select, true {Unfollow} false {Follow} other{}}","unfollow":"Unfollow"},"localOverride":false},"CachedAsset:text:en_US-shared/client/components/common/QueryHandler-1753121700619":{"__typename":"CachedAsset","id":"text:en_US-shared/client/components/common/QueryHandler-1753121700619","value":{"title":"Query Handler"},"localOverride":false},"CachedAsset:text:en_US-components/community/NavbarDropdownToggle-1753121700619":{"__typename":"CachedAsset","id":"text:en_US-components/community/NavbarDropdownToggle-1753121700619","value":{"ariaLabelClosed":"Press the down arrow to open the menu"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageListTabs-1753121700619":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageListTabs-1753121700619","value":{"mostKudoed":"{value, select, IDEA {Most Votes} other {Most Likes}}","mostReplies":"Most Replies","mostViewed":"Most Viewed","newest":"{value, select, IDEA {Newest Ideas} OCCASION {Newest Events} other {Newest Topics}}","newestOccasions":"Newest Events","mostRecent":"Most Recent","noReplies":"No Replies Yet","noSolutions":"No Solutions Yet","solutions":"Solutions","mostRecentUserContent":"Most Recent","trending":"Trending","draft":"Drafts","spam":"Spam","abuse":"Abuse","moderation":"Moderation","tags":"Tags","PAST":"Past","UPCOMING":"Upcoming","sortBymostRecent":"Sort By Most Recent","sortBymostRecentUserContent":"Sort By Most Recent","sortBymostKudoed":"Sort By Most Likes","sortBymostReplies":"Sort By Most Replies","sortBymostViewed":"Sort By Most Viewed","sortBynewest":"Sort By Newest Topics","sortBynewestOccasions":"Sort By Newest Events","otherTabs":" Messages list in the {tab} for {conversationStyle}","guides":"Guides","archives":"Archives"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageView/MessageViewInline-1753121700619":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageView/MessageViewInline-1753121700619","value":{"bylineAuthor":"{bylineAuthor}","bylineBoard":"{bylineBoard}","anonymous":"Anonymous","place":"Place {bylineBoard}","gotoParent":"Go to parent {name}"},"localOverride":false},"CachedAsset:text:en_US-components/customComponent/CustomComponent-1753121700619":{"__typename":"CachedAsset","id":"text:en_US-components/customComponent/CustomComponent-1753121700619","value":{"errorMessage":"Error rendering component id: {customComponentId}","bannerTitle":"Video provider requires cookies to play the video. Accept to continue or {url} it directly on the provider's site.","buttonTitle":"Accept","urlText":"watch"},"localOverride":false},"CachedAsset:text:en_US-shared/client/components/common/OverflowNav-1753121700619":{"__typename":"CachedAsset","id":"text:en_US-shared/client/components/common/OverflowNav-1753121700619","value":{"toggleText":"More"},"localOverride":false},"CachedAsset:text:en_US-components/users/UserLink-1753121700619":{"__typename":"CachedAsset","id":"text:en_US-components/users/UserLink-1753121700619","value":{"authorName":"View Profile: {author}","anonymous":"Anonymous"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageSubject-1753121700619":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageSubject-1753121700619","value":{"noSubject":"(no subject)"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageBody-1753121700619":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageBody-1753121700619","value":{"showMessageBody":"Show More","mentionsErrorTitle":"{mentionsType, select, board {Board} user {User} message {Message} other {}} No Longer Available","mentionsErrorMessage":"The {mentionsType} you are trying to view has been removed from the community.","videoProcessing":"Video is being processed. Please try again in a few minutes.","bannerTitle":"Video provider requires cookies to play the video. Accept to continue or {url} it directly on the provider's site.","buttonTitle":"Accept","urlText":"watch"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageTime-1753121700619":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageTime-1753121700619","value":{"postTime":"Published: {time}","lastPublishTime":"Last Update: {time}","conversation.lastPostingActivityTime":"Last posting activity time: {time}","conversation.lastPostTime":"Last post time: {time}","moderationData.rejectTime":"Rejected time: {time}"},"localOverride":false},"CachedAsset:text:en_US-shared/client/components/nodes/NodeIcon-1753121700619":{"__typename":"CachedAsset","id":"text:en_US-shared/client/components/nodes/NodeIcon-1753121700619","value":{"contentType":"Content Type {style, select, FORUM {Forum} BLOG {Blog} TKB {Knowledge Base} IDEA {Ideas} OCCASION {Events} other {}} icon"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageUnreadCount-1753121700619":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageUnreadCount-1753121700619","value":{"unread":"{count} unread","comments":"{count, plural, one { unread comment} other{ unread comments}}"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageViewCount-1753121700619":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageViewCount-1753121700619","value":{"textTitle":"{count, plural,one {View} other{Views}}","views":"{count, plural, one{View} other{Views}}"},"localOverride":false},"CachedAsset:text:en_US-components/kudos/KudosCount-1753121700619":{"__typename":"CachedAsset","id":"text:en_US-components/kudos/KudosCount-1753121700619","value":{"textTitle":"{count, plural,one {{messageType, select, IDEA{Vote} other{Like}}} other{{messageType, select, IDEA{Votes} other{Likes}}}}","likes":"{count, plural, one{like} other{likes}}"},"localOverride":false},"CachedAsset:text:en_US-components/messages/MessageRepliesCount-1753121700619":{"__typename":"CachedAsset","id":"text:en_US-components/messages/MessageRepliesCount-1753121700619","value":{"textTitle":"{count, plural,one {{conversationStyle, select, IDEA{Comment} OCCASION{Comment} other{Reply}}} other{{conversationStyle, select, IDEA{Comments} OCCASION{Comments} other{Replies}}}}","comments":"{count, plural, one{Comment} other{Comments}}"},"localOverride":false},"CachedAsset:text:en_US-shared/client/components/users/UserAvatar-1753121700619":{"__typename":"CachedAsset","id":"text:en_US-shared/client/components/users/UserAvatar-1753121700619","value":{"altText":"{login}'s avatar","altTextGeneric":"User's avatar"},"localOverride":false}}}},"page":"/tags/TagPage/TagPage","query":{"nodeId":"board:TechnicalArticles","messages.widget.messagelistfornodebyrecentactivitywidget-tab-main-messages-list-for-tag-widget-0":"mostKudoed","tagName":"adc"},"buildId":"3XH0qYWYCnEYycuN5W4S8","runtimeConfig":{"buildInformationVisible":false,"logLevelApp":"info","logLevelMetrics":"info","surveysEnabled":true,"openTelemetry":{"clientEnabled":false,"configName":"f5","serviceVersion":"25.4.0","universe":"prod","collector":"http://localhost:4318","logLevel":"error","routeChangeAllowedTime":"5000","headers":"","enableDiagnostic":"false","maxAttributeValueLength":"4095"},"apolloDevToolsEnabled":false,"quiltLazyLoadThreshold":"3"},"isFallback":false,"isExperimentalCompile":false,"dynamicIds":["components_customComponent_CustomComponent","components_community_Navbar_NavbarWidget","components_community_Breadcrumb_BreadcrumbWidget","components_tags_TagsHeaderWidget","components_messages_MessageListForNodeByRecentActivityWidget","components_tags_TagSubscriptionAction","components_customComponent_CustomComponentContent_TemplateContent","shared_client_components_common_List_ListGroup","components_messages_MessageView","components_messages_MessageView_MessageViewInline","components_customComponent_CustomComponentContent_HtmlContent","components_customComponent_CustomComponentContent_CustomComponentScripts"],"appGip":true,"scriptLoader":[]}