iControl REST Authentication Token Management
Introduction The Token Authentication (hereinafter "token") is an iControl REST authentication method introduced in BIG-IP v12.0. It allows accesses for not only local users but also remotes users (such as RADIUS or LDAP) unlike the conventional Basic Authentication (uses HTTP's Authorization header) which is only good for local users. This article describes methods for managing tokens. The example calls shown here use curl. The command options used are -s: silent - Do not show the progress meter. -k: insecure - Does not verify the server certificate. -u: user - User name and passwords (e.g., admin:admin). -H: header - Additional HTTP request header. The X-F5-Auth-Token header is used to provide the token. -d: data - The data to POST/PATCH. The following variables embedded in the example calls represents: $HOST - BIG-IP management IP. $TOKEN - A token (e.g., ABCDEFGHIJKLMNOPQRSTUVWXYZ) Things you should know about token When you use tokens, remember the following characteristics: 1. A token expires By default, a token expires after 1,200s (20 min). You can extend the token lifespan by modifying the "timeout" property in the token object. The maximum lifespan is 36,000s (10 hrs). If you attempt to change the timeout property longer than the maximum, you will get the 406 error "Auth-token absolute timeout (36000 seconds) exceeded". 2. Limited number of tokens Each user can request up to 100 tokens at any point in time. Your 101-th token request will be rejected with the 400 error "Bad Request: user xxx has reached maximum active login tokens". You need to either wait for the tokens to expire or explicitly delete them. This limitation applies to all users, irrespective of local/remote and roles (even administrator). The only exception is the "admin" user. 3. You can only manage your own token You cannot view (GET), modify (PATCH) or delete (DELETE) a token generated for somebody else. Such requests will be rejected with the 400 error "Authorization failed". If you need to manage tokens for other users, use the user with an appropriate role (e.g., administrator). Token management 1. Get a token To obtain a token for user foo (and his password is fooPass), run the following call. curl -sk https://$HOST/mgmt/shared/authn/login -X POST -H "Content-Type: application/json" \ -d '{"username":"foo", "password":"fooPass", "loginProviderName":"tmos"}' An example output is shown below: { "generation": 0, "lastUpdateMicros": 0, "loginProviderName": "tmos", "loginReference": { "link": "https://localhost/mgmt/cm/system/authn/providers/tmos/1f44a60e-11a7-3c51-a49f-82983026b41b/login" }, "token": { "address": "192.168.184.10", "authProviderName": "tmos", "expirationMicros": 1588199929471000, "generation": 1, "kind": "shared:authz:tokens:authtokenitemstate", "lastUpdateMicros": 1588198729470534, "name": "DCECRMQ66WOSPTSGPR7OAGG5SI", "partition": "[All]", "selfLink": "https://localhost/mgmt/shared/authz/tokens/DCECRMQ66WOSPTSGPR7OAGG5SI", "startTime": "2020-04-30T10:18:49.471+1200", "timeout": 1200, "token": "DCECRMQ66WOSPTSGPR7OAGG5SI", "user": { "link": "https://localhost/mgmt/cm/system/authn/providers/tmos/1f44a60e-11a7-3c51-a49f-82983026b41b/users/acbd18db-4cc2-385c-adef-654fccc4a4d8" }, "userName": "foo" }, "username": "foo" } The "token" or "name" property inside the "token" property shows the token. It is a 26 character long string consisting of uppercase alphabets and numbers. In the above example, it is DCECRMQ66WOSPTSGPR7OAGG5SI. 2. Find the time when your token will expire In the output above, the "timeout" property shows the lifespan of the token in seconds. As shown, the default value is 1200s (20 min). The "expirationMicros" property shows the date/time that the token will expire. The value is a Unix epoch time in GMT with microseconds precision. You can parse the number by using Node.js (preinstalled on any BIG-IP 12.1 and later) as below: # To GMT node -p 'new Date(1588202764161000/1000)' # To your local time node -p 'new Date(1588197991778710/1000).toString()' 3. Use your token Add the X-F5-Auth-Token HTTP request header with the token value to any call you make. For example, to send a GET request to /mgmt/tm/sys/version (equivallent to 'tmsh show sys version'), run below: curl -sk https://$HOST/mgmt/tm/sys/version -H "X-F5-Auth-Token: $TOKEN" 4. Check your token You can check you token by sending the following GET request. curl -sk https://$HOST/mgmt/shared/authz/tokens/$TOKEN -H "X-F5-Auth-Token: $TOKEN" An example output is shown below: { "address": "192.168.184.10", "authProviderName": "tmos", "expirationMicros": 1588217373992000, "generation": 1, "kind": "shared:authz:tokens:authtokenitemstate", "lastUpdateMicros": 1588216173991714, "name": "7CLLGEKL5UZLUI7BO4SE7MUGMI", "partition": "[All]", "selfLink": "https://localhost/mgmt/shared/authz/tokens/7CLLGEKL5UZLUI7BO4SE7MUGMI", "startTime": "2020-04-30T15:09:33.992+1200", "timeout": 1200, "token": "7CLLGEKL5UZLUI7BO4SE7MUGMI", "user": { "link": "https://localhost/mgmt/cm/system/authn/providers/tmos/1f44a60e-11a7-3c51-a49f-82983026b41b/users/acbd18db-4cc2-385c-adef-654fccc4a4d8" }, "userName": "foo" } 5. Modify the timeout value of your token By changing the value of the timeout property (default 1,200), you can extend or shorten the lifespan of the token. You may need to consider: Extending it if your iControl REST session is expected to last long (e.g., a script with hundreds of calls) to avoid timeout in the middle of the session. Shortening it if you successively run multiple iControl REST calls that request tokens each time to avoid running out the tokens. The example below extends the token's lifespan to 4,200s (70 min). curl -sk https://$HOST/mgmt/shared/authz/tokens/$TOKEN \ -X PATCH -H "Content-type: application/json" -H "X-F5-Auth-Token: $TOKEN" \ -d '{"timeout" : 4200}' 6. Delete your token You can explicitly delete your token. curl -sk https://$HOST/mgmt/shared/authz/tokens/$TOKEN -X DELETE -H "X-F5-Auth-Token: $TOKEN" As aforementioned, you can only delete your own token. If you need to remove ALL the tokens in one shot, run the following call from the authorized user such as admin: curl -sku $PASS https://$HOST/mgmt/shared/authz/tokens -X DELETE 7. Fnd the owner of the token from the user reference link As shown in the Merhod 1 and 4, a token object contains the owner (or the requester) of the token (the "userName" property). If it does not contain the readable user information, alternatively, you can send a GET request to the endpoint shown in the "user" property. curl -sk https:/$HOST/mgmt/cm/system/authn/providers/tmos/1f44a60e-11a7-3c51-a49f-82983026b41b/users/acbd18db-4cc2-385c-adef-654fccc4a4d8 \ -H "X-F5-Auth-Token: $TOKEN" The 8-4-4-4-12 format strings are UUIDs computed from the login provider name (the value you provided via the loginProviderName property when you requested your token) and user name. For example, 1f44a60e-11a7-3c51-a49f-82983026b41b in between "tmos" and "users" is from the string "tmos". acbd18db-4cc2-385c-adef-654fccc4a4d8 is from "foo". An UUID (Universally Unique Identifier) is a 128 bits long unique identifier defined in RFC 4122. There are a number of variants and versions in the UUIDs. F5 iControl REST uses version (0011) and variant (10) (represented in binary). See Section 4.1.3 and 4.1.1 of the RFC for details. An example output from the above call is shown below: { "generation": 23, "id": "acbd18db-4cc2-385c-adef-654fccc4a4d8", "kind": "cm:system:authn:providers:tmos:1f44a60e-11a7-3c51-a49f-82983026b41b:users:usersstate", "lastUpdateMicros": 1585693423008243, "name": "foo", "selfLink": "https://localhost/mgmt/cm/system/authn/providers/tmos/1f44a60e-11a7-3c51-a49f-82983026b41b/users/acbd18db-4cc2-385c-adef-654fccc4a4d8" } References iControl REST User Guide (Clouddocs iControl REST; PDF documents) Auth Token by Login (CloudDocs BIG-IQ API) Demystifying iControl REST Part 6: Token-Based Authentication (DevCentral article) curl man page K04452074: Overview of using the BIG-IQ system authentication token (F5 AskF5 document) Python SDK Cookbook: Working with Auth Tokens (DevCentral article) A Universally Unique IDentifier (UUID) URN Namespace (RFC 4122)17KViews2likes0Comments
Understanding Performance Metrics and Network Traffic
Introduction Do you ever look at specification sheets for technology products, and think to yourself, "hmm... these numbers are bigger than those numbers. That's good, right?" This is a reasonable response in the absesnce of precise information. However, an incomplete understanding often results in applying the wrong solution to a problem. Consider that a peregrine falcon is faster than a person on a bicycle, but a person on a bicycle can perform far more work per trip due to an exponentially larger carrying capacity. The falcon would be great for carrying a single message on a slip of paper. It'd be lousy for carrying a stack of books. Selecting the device to use, be it falcon or bicycle, requires at least two metrics. We need to understand both the expected velocity and the carrying capacity. Units of networking equipment, be they virtual or physical, typically have published specifications that one can use to compare performance between solutions. My goal is not to suggest one solution or another. Instead, my goal is to give you the ability to understand what the metrics truly mean. All Hail The OSI Model! The OSI model provides a logical framework for discussing network concepts. This table describes what you can find at each layer: # Name Summary 7 Application HTTP 6 Presentation Data formats 5 Session TLS (strangely debatable) 4 Transport TCP / UDP 3 Network IPv4 / IPv6 2 Data Link Ethernet frames 1 Physical Cabling, optics This gives us a common framework for explaining things like "What is the difference between connections per second (CPS) and transactions per second (TPS)?" or "What does infinite encryption session reuse mean?" The key point is that, in the general case, every layer can support multiple interactions of the layer above it. Consider that I can consume multiple HTTP objects over a single TCP connection when using HTTP/1.1. It is possible to request a large HTTP object by using multiple TCP connections, but the way that actually happens is through sending multiple HTTP requests, each with its own TCP connection, specifying different parts of the same object. CPS, TPS, pps, Stats Excess Now that we have established a common framework for understanding the intent behind the different metrics, I will define some of the common types. Label Meaning Explanation CPS connections per second The number of L4 connections established per second. TPS transactions per second The number of L5-L7 transactions completed per second. RPS requests per second The number of L5-L7 requests satisfied per second, often interchangeable with TPS. RPC requests per connection The number of L5-L7 requests completed for a single L4 connection. Example: HTTP/1.1 with 100 transactions per TCP connection would be 100-RPC. bps or bit/s bits per second The network bandwidth in bits per second. Some people use GB/s, Gb/s and Gbps interchangeably, but the unit is decidedly important. 1 GB/s (gigabyte per second) is 8 Gbps (gigabits per second) See: data-rate units. Things get a bit pedantic with GiB/s vs GB/s, but 8:1 bytes:bits is correct when working from the same base unit. fps frames per second A measure of L2 frames per second, often used for core switching or firewalls. The distinction is that not all network frames contain valid data packets or datagrams. pps packets per second A measure of the L3/L4 packets per second, typically for TCP and UDP traffic. CC concurrent connections The number of concurrently established L4 connections. Example: if you have 100 CPS, and each connection has a lifetime of 100 s, then the resultant CC is 10,000 (connection rate * connection lifetime). As you might expect, there are additional statistics in the wild. The objective is to take a specification sheet label and number, like "800 angry orchids per second", and decompose it. "Where do angry orchids fit in the OSI model? If angry orchids are an L7 concept, how many angry orchids are served through a single TCP session?" This method will allow you to understand any specification sheet metric that is constructed from logical data. More importantly, it will equip you to question metrics that make no sense. How Are These Numbers Generated? You might think this: "Okay, so this specification sheet for a product says that it can do foo CPS and bar Gbps. Surely it can perform those feats at the same time." You would be wrong. A peregrine falcon cannot dive at maximum velocity while carrying a book - the book has a lower terminal velocity in atmosphere. Specification sheet numbers for things in the networking world are generated by a test designed to exercise a single function. Consider a TCP connections per second (CPS) test. The harness will be configured such that a TCP handshake is established, a client will send a single request for an object, a server will reply with an object small enough to fit within a single TCP packet, and then the TCP connection is torn down gracefully. The maximum sustained CPS number typically coincides with the maximum CPU capacity for a physical or virtual device. Now consider a maximum throughput test. The harness will be configured such that a TCP handshake is established, a client will attempt to reuse this TCP connection with HTTP/1.1 to request an object, a server will respond with a large object (typically >= 128 kB), and the TCP connection will not be torn down until multiple HTTP transactions have occurred. If there are no limitations in physical connectivity, and no hardware assistance, then the maximum sustained throughput typically coincides with the maximum CPU capacity for a physical or virtual device. If both of those tests require all of the available CPU resources, then it is generally impossible to satisfy both conditions at the same time. Therefore, if your workload involves any application level inspection or decisions, then your available CPU resources for L4 connection handling will also be reduced. This table describes the test process for some of the core metrics. The labels and meanings are repeated from the previous table. Label Meaning Methodology CPS connections per second Determine the maximum number of fully functional (establishment, single small transaction, graceful termination) connections that can be established per second. Each transaction is a small object such that it will not result in a full size network frame. TPS / RPS transactions per second / requests per second Determine the maximum number of complete transactions that can be completed over a small number of long-lived connections. Each transaction requests a small object such that it will not result in a full size network frame. bps bits per second Determine the maximum sustained throughput for a workload using long-lived connections and large (128 kB or higher) object sizes. This is often expressed for L4 and L7, and the numbers are typically different. Note that ADC industry metrics use a "single count" method for measuring throughput, such that traffic between the client and server is counted, but not the traffic between the client and ADC or between the ADC and the server. fps frames per second Determine the maximum rate at which network frames can be inspected, routed, or mitigated without unintended drops. This is particularly useful when comparing network defense performance, such as TCP SYN flood mitigation. CC concurrent connections Determine the maximum number of concurrent connections that can be established without forcefully terminating any of the connections. This is typically tested by establishing millions of connections over a long period of time, and leaving them in an established state. The test is valid only if the connections can successfully complete one transaction before a graceful termination. Stability is achieved when the new connection rate matches the connection termination rate due to old connections being satisfied. Example: 10,000 CPS with a 300 second wait time and 1-RPC for a 128 byte object will result in a moving plateau of 3.0M CC. The test should run for a minimum of 300 seconds after the initial connections have been established. These tests take a long time, as there are three phases - establishment (300 seconds), wait and transaction (300 seconds), graceful shutdown (300 seconds). What Does Your Traffic Look Like? I used to have the role of customer-facing performance testing. This means that I would use problem descriptions, sample configurations, and other details and constraints from a sales team to create an approximate test harness in the lab. There were two main goals: help the customer to understand how the device will perform with their given workloads, and help the customer and sales team understand what capacity is required for current and future traffic. However, performance is more dependent upon the actual traffic characteristics than the finer points of tuning a configuration. My questions often focused on what the traffic looks like in the target network environment. Anybody that replied with "it's just IMIX" was wrong; nobody has production traffic that looks like IMIX. Defining the device configuration is relatively simple. A customer would have some defined deployment scenarios, like "client-ssl with HTTP inspection and compression for IPv6 traffic" or "NAT44 with policy enforcement and logging." The sales engineering talent would work with the customer engineering talent to build an acceptable configuration. This defined the harness layout and traffic types. However, real traffic has many applications and protocols running concurrently. Clients and servers may have intermittent packet loss or other issues due to over-subscribed resources. Some users have a three-digit number of mostly idle connections. Some users have two video streams incoming and one outgoing. And so on in that fashion. The real mix of network traffic varies wildly between services, and even between points of presence (PoP) within a single service. Real data is required. Quantifying Your Network Traffic Your existing network infrastructure is a valuable source of information. Statistical data from your switches and routers can tell you interesting things for every network segment in your environment: number of network frames in / out number of bytes in / out IPv4 / IPv6 blend Your firewalls, ADCs, and other advanced infrastructure can provide information regarding client behavior, transport protocols, and applications: connection lifetime average frame size per connection number of bytes in / out per connection transport protocol blend (TCP vs. UDP) geographic distribution of traffic ciphers used and key strength actual compression ratios (bits in from server vs. bits out to client, according to compression device) blend of stream traffic vs. transactional traffic ... and so on in that fashion The trick is collecting all of this data, then asking meaningful questions against it. The full discussion of what you can learn goes far beyond the scope of this article. However, here are a handful of common traffic questions and suggestions for how to determine the answers. Q: How many concurrent TCP connections should I expect? A: Concurrency is the product of the average connection lifetime and the average new connection rate. Example: We have determined that a particular application receives 35,000 new connections per second (CPS). We also determined that the average connection lifetime for this application is 100 seconds. The calculation for typical concurrency is 35,000 TCP conn/s x 100 s. The units cancel out to give us 3.5M TCP connections. Q: What kind of UDP concurrency should I expect? A: This question is strangely common, and typically pointless. UDP is a stateless protocol. If required, source / destination hashing or something in the payload can be used to ensure that the same client goes to the same back end resources. Q: How many users can I handle with 1.0 Gbps? A: This can be determined by looking at the average connection lifetime and average bytes in / out for a typical session. The method is to take the total bytes for an average transaction and divide it by the average connection lifetime. This gives you the amount of data per second. Then you divide the data rate capacity by that number. Example: for a typical user session, our application receives 100 kB and transmits 200 kB. The average session length is 10 seconds. This means that, for a typical session, we are receiving 10 kB/s and transmitting 20 kB/s. We convert this to 80 kbps and 160 kbps (bytes to bits). We use the larger value, in this case transmission back to the client, to determine the maximum session capacity. 1.0 Gbps (capacity) divided by 160 kbps (per-session requirement) gives a value of 6,250 sessions. Q: I calculated the values for one point in time. Is this sufficient? A: Absolutely not! Network traffic, much like commuter traffic, tends to have a daily pattern. You should understand your traffic mix and application behavior for at least two points: peak traffic, average traffic. I recommend automating the analysis, and running it hourly for a week. You will find unexpected trends. If you have historical data, analyze that too so you can project growth rates. Consider how your personal internet habits change throughout the day. At work you have long-lived connections to email and other internal services, probably a music streaming service, maybe an instant message service or three, and a lot of open browser tabs. What about when you get home? Media streaming, maybe internet gaming, possibly a VoIP session, and a lot of open browser tabs. Which usage pattern is more correct for capacity planning? You need data to understand which usage pattern is more resource intensive. Closing I hope that this information allows you to make precise decisions around resource planning and resource allocation. The goal is that your capacity planning should cease to be driven solely by CPU load thresholds for auto-scaling. Instead, you should be actively considering the resource allocation of every component of an application and the supporting infrastructure. Use the knowledge above to explain precisely where resources are misapplied and how to correct it. Go make the world a little more efficient.13KViews4likes2CommentsAS3 Best Practice
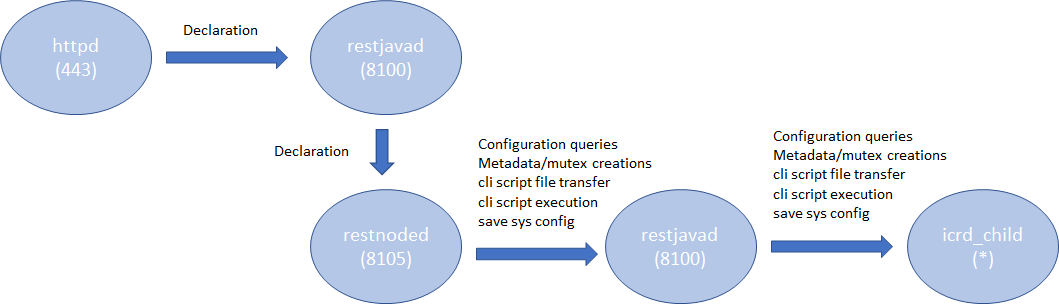
Introduction AS3 is a declarative API that uses JSON key-value pairs to describe a BIG-IP configuration. From virtual IP to virtual server, to the members, pools, and nodes required, AS3 provides a simple, readable format in which to describe a configuration. Once you've got the configuration, all that's needed is to POST it to the BIG-IP, where the AS3 extension will happily accept it and execute the commands necessary to turn it into a fully functional, deployed BIG-IP configuration. If you are new to AS3, start reading the following references: Products - Automation and orchestration toolchain(f5.com; Product information) Application Services 3 Extension Documentation(clouddocs; API documentation and guides) F5 Application Services 3 Extension(AS3) (GitHub; Source repository) This article describes some considerations in order to efficiently deploy the AS3 configurations. Architecture In the TMOS space, the services that AS3 provides are processed by a daemon named 'restnoded'. It relies on the existing BIG-IP framework for deploying declarations. The framework consists of httpd, restjavad and icrd_child as depicted below (the numbers in parenthesis are listening TCP port numbers). These processes are also used by other services. For example, restjavad is a gateway for all the iControl REST requests, and is used by a number of services on BIG-IP and BIG-IQ. When an interaction between any of the processes fails, AS3 operation fails. The failures stem from lack of resources, timeouts, data exceeding predefined thresholds, resource contention among the services, and more. In order to complete AS3 operations successfully, it is advised to follow the Best Practice outlined below. Best Practice Your single source of truth is your declaration Refrain from overwriting the AS3-deployed BIG-IP configurations by the other means such as TMSH, GUI or iControl REST calls. Since you started to use the AS3 declarative model, the source of truth for your device's configurations is in your declaration, not the BIG-IP configuration files. Although AS3 tries to weigh BIG-IP locally stored configurations as much as it can do, discrepancy between the declaration and the current configuration on BIG-IP may cause the AS3 to perform less efficiently or error unexpectedly. When you wish to change a section of a tenant (e.g., pool name change), modify the declaration and submit it. Keep the number of applications in one tenant to a minimum AS3 processes each tenant separately.Having too many applications (virtual servers) in a single tenant (partition) results in a lengthy poll when determining the current configuration. In extreme cases (thousands of virtuals), the action may time out. When you want to deploy a thousand or more applications on a single device, consider chunking the work for AS3 by spreading the applications across multiple tenants (say, 100 applications per tenant). AS3 tenant access behavior behaves as BIG-IP partition behavior.A non-Common partition virtual cannot gain access to another partition's pool, and in the same way, an AS3 application does not have access to a pool or profile in another tenant.In order to share configuration across tenants, AS3 allows configuration of the "Shared" application within the "Common" tenant.AS3 avoids race conditions while configuring /Common/Shared by processing additions first and deletions last, as shown below.This dual process may cause some additional delay in declaration handling. Overwrite rather than patching (POSTing is a more efficient practice than PATCHing) AS3 is a stateless machine and is idempotent. It polls BIG-IP for its full configuration, performs a current-vs-desired state comparison, and generates an optimal set of REST calls to fill the differences.When the initial state of BIG-IP is blank, the poll time is negligible.This is why initial configuration with AS3 is often quicker than subsequent changes, especially when the tenant contains a large number of applications. AS3 provides the means to partially modify using PATCH (seeAS3 API Methods Details), but do not expect PATCH changes to be performant.AS3 processes each PATCH by (1) performing a GET to obtain the last declaration, (2) patching that declaration, and (3) POSTing the entire declaration to itself.A PATCH of one pool member is therefore slower than a POST of your entire tenant configuration.If you decide to use PATCH,make sure that the tenant configuration is a manageable size. Note: Using PATCH to make a surgical change is convenient, but using PATCH over POST breaks the declarative model. Your declaration should be your single source of truth.If you include PATCH, the source of truth becomes "POST this file, then apply one or more PATCH declarations." Get the latest version AS3 is evolving rapidly with new features that customers have been wishing for along with fixes for known issues. Visitthe AS3 section of the F5 Networks Github.Issuessection shows what features and fixes have been incorporated. For BIG-IQ, check K54909607: BIG-IQ Centralized Management compatibility with F5 Application Services 3 Extension and F5 Declarative Onboarding for compatibilities with BIG-IQ versions before installation. Use administrator Use a user with the administrator role when you submit your declaration to a target BIG-IP device. Your may find your role insufficient to manipulate BIG-IP objects that are included in your declaration. Even one authorized item will cause the entire operation to fail and role back. See the following articles for more on BIG-IP user and role. Manual Chapter : User Roles (12.x) Manual Chapter : User Roles (13.x) Manual Chapter : User Roles (14.x) Prerequisites and Requirements(clouddocs AS3 document) Use Basic Authentication for a large declaration You can choose either Basic Authentication (HTTP Authorization header) or Token-Based Authentication (F5 proprietary X-F5-Auth-Token) for accessing BIG-IP. While the Basic Authentication can be used any time, a token obtained for the Token-Based Authentication expires after 1,200 seconds (20 minutes). While AS3 does re-request a new token upon expiry, it requires time to perform the operation, which may cause AS3 to slow down. Also, the number of tokens for a user is limited to 100 (since 13.1), hence if you happen to have other iControl REST players (such as BIG-IQ or your custom iControl REST scripts) using the Token-Based Authentication for the same user, AS3 may not be able to obtain the next token, and your request will fail. See the following articles for more on the Token-Based Authentication. Demystifying iControl REST Part 6: Token-Based Authentication(DevCentral article). iControl REST Authentication Token Management(DevCentral article) Authentication and Authorization(clouddocs AS3 document) Choose the best window for deployment AS3 (restnoded daemon) is a Control Plane process. It competes against other Control Plane processes such as monpd and iRules LX (node.js) for CPU/memory resources. AS3 uses the iControl REST framework for manipulating the BIG-IP resources. This implies that its operation is impacted by any processes that use httpd (e.g., GUI), restjavad, icrd_child and mcpd. If you have resource-hungry processes that run periodically (e.g., avrd), you may want to run your AS3 declaration during some other time window. See the following K articles for alist of processes K89999342 BIG-IP Daemons (12.x) K05645522BIG-IP Daemons (v13.x) K67197865BIG-IP Daemons (v14.x) K14020: BIG-IP ASM daemons (11.x - 15.x) K14462: Overview of BIG-IP AAM daemons (11.x - 15.x) Workarounds If you experience issues such as timeout on restjavad, it is possible that your AS3 operation had resource issues. After reviewing the Best Practice above but still unable to alleviate the problem, you may be able to temporarily fix it by applying the following tactics. Increase the restjavad memory allocation The memory size of restjavad can be increased by the following tmsh sys db commands tmsh modify sys db provision.extramb value <value> tmsh modify sys db restjavad.useextramb value true The provision.extramb db key changes the maximum Java heap memory to (192 + <value> * 8 / 10) MB. The default value is 0. After changing the memory size, you need to restart restjavad. tmsh restart sys service restjavad See the following article for more on the memory allocation: K26427018: Overview of Management provisioning Increase a number of icrd_child processes restjavad spawns a number of icrd_child processes depending on the load. The maximum number of icrd_child processes can be configured from /etc/icrd.conf. Please consult F5 Support for details. See the following article for more on the icrd_child process verbosity: K96840770: Configuring the log verbosity for iControl REST API related to icrd_child Decrease the verbosity levels of restjavad and icrd_child Writing log messages to the file system is not exactly free of charge. Writing unnecessarily large amount of messages to files would increase the I/O wait, hence results in slowness of processes. If you have changed the verbosity levels of restjavad and/or icrd_child, consider rolling back the default levels. See the following article for methods to change verbosity level: K15436: Configuring the verbosity for restjavad logs on the BIG-IP system13KViews12likes2CommentsiControl REST Fine-Grained Role Based Access Control
Introduction F5's role based access control (RBAC) mechanism allows a BIG-IP administrator to assign appropriate access privileges to the users (see Manual Chapter: User Roles). For example, with the operator role, the user is specifically allowed to enable or disable nodes and pool members. The mechanism is generally the best way to manage users easily and consistently, however, finer access management may be required from time to time: e.g., allow only to view the stats of a predefined set of virtuals. Restricting access is especially important in iControl REST because users can remotely and directly access the system. The existing roles and their access permissions are defined in /mgmt/shared/authz/roles and /mgmt/shared/authz/resource-groups . You can add custom roles with custom permissions for particular users to these resources (iControl REST endpoints). The resources are described in BIG-IQ Systems REST API References, however, they are not exactly easy to follow. To fill the gap, this article describes a method to configure users and roles in a muchfiner manner. Note This method is only applicable to iControl REST: It does not apply to Configuration Utility or ssh. The method relies on the resources for local users (i.e., /mgmt/tm/auth/user and /mgmt/shared/authz/users ). It does not work for remote authentication mechanisms such as RADIUS or Active Directory. Setup In this example, a local user "foo" and a custom role "testRole" are created. The role allows users to GET (list) only the virtual server "vs". The access method and resource are defined in "testResourceGroup", that is referenced from the "testRole". No other operation such as PATCH (modify) or DELETE is permitted. Also, no other resource such as another virtual is allowed. All the REST calls are done using curl: You may want to consider using other methods such as F5 Python SDK . 1. Create a new user The following curl command creates the user "foo". The password is "foo", the description is "Foo Bar", and the role is "operator" for all the partitions. curl -sku admin:<pass> https://<mgmtIP>/mgmt/tm/auth/user -X POST -H "Content-Type: application/json" \ -d '{"name":"foo", "password":"foo", "description":"Foo Bar", "partitionAccess":[ { "name":"all-partitions", "role":"operator"} ] }' You get the following JSON object: { "description": "Foo Bar", "encryptedPassword": "$6$jwL4UUxv$IUrzWGEUsyJaXlOB2oyyTPflHFdvDBXb6f3f/No4KNfQb.V6bpQZBgvxl3KkBDXGtpttej79DDphEGRh8d4iA/", "fullPath": "foo", "generation": 1023, "kind": "tm:auth:user:userstate", "name": "foo", "partitionAccess": [ { "name": "all-partitions", "nameReference": { "link": "https://localhost/mgmt/tm/auth/partition/all-partitions?ver=13.1.1.2" }, "role": "operator" } ], "selfLink": "https://localhost/mgmt/tm/auth/user/satoshi?ver=13.1.1.2" } The role is important. When the access privileges conflict between the role and the fine grained RBAC, the stricter authorization is chosen. For example, if the RBAC is configured to allow PATCH or POST but the user's role is guest (no alteration allowed), the user won't be able to perform these methods. You can create a user from tmsh or Configuration Utility if that's your preferred method. 2. (13.1.0 and later) Remove the user from /mgmt/shared/authz/roles/iControl_REST_API_User From v13.1.0, a newly created local user is automatically added to iControl_REST_API_User , which grants access to iControl REST without any setup. To avoid assigning multiple permissions, you need to remove the user reference from /mgmt/shared/authz/roles/iControl_REST_API_User . First, get the data from /mgmt/shared/authz/roles/iControl_REST_API_User and redirect it to a file. curl -sku admin:<pass> https://<mgmtIP>/mgmt/shared/authz/roles/iControl_REST_API_User \ | python -m json.tool > file Edit the file. The file contains a line for the user "foo" like this. "name": "iControl_REST_API_User", "userReferences": [ { "link": "https://localhost/mgmt/shared/authz/users/foo" }, .... Remove the line including the opening and ending curly brackets plus the comma. Save the file. Overwrite the current data by putting the file to the endpoint. curl -sku admin:<pass> https://<mgmtIP>/mgmt/shared/authz/roles/iControl_REST_API_User -X PUT -d@file 3. Create a custom resource-group A resource-group consists of a set of resources and methods. In this example, the resource-group is named "testResourceGroup", which allows a role to perform GET request to the resource /mgmt/tm/ltm/virtual/vs . "testResourceGroup" is later used in the custom role. curl -sku admin:<pass> https://<mgmtIP>/mgmt/shared/authz/resource-groups -X POST -H "Content-Type: application/json" \ -d '{"name":"testResourceGroup", "resources":[ {"restMethod":"GET", "resourceMask":"/mgmt/tm/ltm/virtual/vs" } ]}' You get the following JSON object. { "id": "fe7a1ebc-3e61-30aa-8a5d-c7721f7c6ce2", "name": "testResourceGroup", "resources": [ { "resourceMask": "/mgmt/tm/ltm/virtual/vs", "restMethod": "GET" } ], "generation": 1, "lastUpdateMicros": 1521682571723849, "kind": "shared:authz:resource-groups:roleresourcegroupstate", "selfLink": "https://localhost/mgmt/shared/authz/resource-groups/fe7a1ebc-3e61-30aa-8a5d-c7721f7c6ce2" } Note that a resource-group entry is keyed by "id", not "name". The id is automatically generated. As you can see, the resources field is a list of multiple objects, each containing the endpoint and the method. To add more permissions to the resource-group, add objects to the list. 4. Create a custom role Create a role "testRole" with the user "foo" and the resource-groups "testResourceGroup". This makes the user to become a member of therole "testRole", hence allows the users to perform GET only to the /mgmt/tm/ltm/virtual/vs . curl -sku admin:<pass> https://<mgmtIP>/mgmt/shared/authz/roles -X POST -H "Content-Type: application/json" \ -d '{"name":"testRole", "userReferences":[ {"link":"https://localhost/mgmt/shared/authz/users/foo"} ], "resourceGroupReferences":[{"link":"https://localhost/mgmt/shared/authz/resource-groups/fe7a1ebc-3e61-30aa-8a5d-c7721f7c6ce2"}]}' Please note that the reference to the user foo in the userReferences field is different from Step #1: The user created was /mgmt/tm/auth/user/foo while the reference is /mgmt/shared/authz/users/foo . The /mgmt/shared/authz/users/foo is automatically created. J ust use /mgmt/shared/authz/users/ + user name . Again, please observe that the resource-groups reference is not by name but by ID. See the selfLink in the step #3. You get the following JSON object. { "name": "testRole", "userReferences": [ { "link": "https://localhost/mgmt/shared/authz/users/foo" } ], "resourceGroupReferences": [ { "link": "https://localhost/mgmt/shared/authz/resource-groups/fe7a1ebc-3e61-30aa-8a5d-c7721f7c6ce2" } ], "generation": 1, "lastUpdateMicros": 1521682931708662, "kind": "shared:authz:roles:rolesworkerstate", "selfLink": "https://localhost/mgmt/shared/authz/roles/testRole" } Test The following REST calls demonstrate that the user "foo" can GET the virtual "vs" but nothing else. curl -D - -sku foo:foo https://192.168.226.155/mgmt/tm/ltm/virtual/vs | grep HTTP HTTP/1.1 200 OK curl -D - -sku foo:foo https://192.168.226.155/mgmt/tm/ltm/virtual | grep HTTP HTTP/1.1 401 F5 Authorization Required curl -D - -sku foo:foo https://192.168.226.155/mgmt/tm/ltm/virtual -X PATCH -d '{"test":"test"}' | grep HTTP HTTP/1.1 401 F5 Authorization Required curl -D - -sku foo:foo https://192.168.226.155/mgmt/tm/sys/version | grep HTTP HTTP/1.1 401 F5 Authorization Required Cleanup Removing users that are no longer used is a good admin practice. The cleanup procedure is describedbelow (response JSON blobs are not shown): 1. Delete the resource-group. Use ID. curl -sku admin:<pass> https://<mgmtIP>/mgmt/shared/authz/resource-groups/fe7a1ebc-3e61-30aa-8a5d-c7721f7c6ce2 -X DELETE 2. Delete the custom role. curl -sku admin:<pass> https://<mgmtIP>/mgmt/shared/authz/roles/testRole -X DELETE 3. Delete the user. You can perform this step from tmsh or Configuration Utility. curl -sku admin:<pass> https://<mgmtIP>/mgmt/tm/auth/user/foo -X DELETE9.9KViews2likes41Comments
The Three HTTP Routing Patterns You Should Know
HTTP is the de-facto application transport layer. The majority of applications and APIs today are delivered via HTTP, regardless of their content (HTML, JSON, XML). That means most of the scaling going on is focused on scaling HTTP-based apps. In fact, when I peek at our latest data from nearly 4 million virtual servers, 63% of them are HTTP/S. In MuleSoft’s latest Connectivity Benchmark, respondents reported an average of 1020 applications in their enterprise environments. Even if only 63% are HTTP/S, that’s still a lot of HTTP - with not a lot of IP space to give it. Most organizations aren’t lucky enough to own significant ranges of publicly accessible IP addresses. That’s one of the reasons why “virtual servers” exist in the realm of web serving. So that a single IP address can service multiple servers (or applications). Host-based (virtual) routing has been a go-to for the Internet for years. And though it’s the most commonly used (and best known) type of HTTP routing, there are actually three types of HTTP routing NetOps should get familiar with. That’s because increasingly the world of applications is clashing with that of the network, and many of the deployment patterns being used by DevOps rely on HTTP-based routing capabilities. 1. Host-based The old standard. Host-based routing is what enables virtual servers on web servers. It’s also used by application services like load balancing and ingress controllers to achieve the same thing. One IP address, many hosts. Host-based routing allows you to send a request for api.example.com and for web.example.com to the same endpoint with the certainty it will be delivered to the correct back-end application. 2. Path-based Increasingly common – particularly in the realm of scaling containers using ingress controllers – is path-based routing. Path-based routing requires visibility into the URI portion of an HTTP request. You can route based on the entire path (not advisable) or a portion of the path. For example, you could search for /getprofile in this path and route it to one application while routing all others to a different application. You can also search for /v1 in the path and use it to implement a type of API versioning. Because of the focus on API-only communication in modern apps (like mobile) and architectures (like microservices), the use of path-based routing is increasingly important to enabling not only scale but simple delivery. When everything you need to know is found in the URI (in the path), it becomes imperative that you can dissect that path into its composite pieces and make decisions on where that request needs to go. 3. Header-based Header-based is a broad category that includes some familiar routing patterns such as persistence (sticky sessions). Header-based routing simply means that you use an arbitrary HTTP header as the basis for determining how to route a request. This might be a standard header, like content-type or cookie, or it might be a custom header, like x-custom-header-for-my-app. The use of HTTP headers to route requests is a long-standing tradition of sorts. The concept of sticky sessions (persistence) is based on the use of Cookies to aid in scaling stateful applications. It’s also instrumental in maintaining secure sessions (SSL/TLS). Note that Header-based is usually separated from host-based routing even though host is technically one of the many HTTP headers. Many systems were able to perform host-based routing but not general header-based routing, though today it is hard to find a load balancer/proxy that cannot support routing based on any header. Despite the apparent simplicity of these routing patterns, their importance should not be underestimated. API Gateways, web application firewalls (particularly inspection capabilities), ingress controllers, and a robust set of other application services rely on being able to route based on this information.5.8KViews0likes0Comments
How to use Ansible with Cisco routers
Quick Intro For those who don't know, there is an Ansible plugin callednetwork_clito retrieve network device configuration for backup, inspection and even execute commands. So, let's assume we have Ansible already installed and 2 routers: I used Debian Linux here and I had to install Python 3: I've also installed pip as we can see above because I wanted to install a specific version of Ansible (2.5.+) that would allow myself to use network_cli plugin: Note: we can list available Ansible versions by just typingpip install ansible== I've also created a user namedansible: Edited Linuxsudoersfile withvisudocommand: And addedAnsible user permission to run root commands without prompting for password so my file looked liked this: Quick Set Up This is my directory structure: These are the files I used for this lab test: Note: we can replace cisco1.rodrigo.example for an IP address too. In Ansible, there is a default config file (ansible.cfg) where we store the global config, i.e. how we want Ansible to behave. We also keep the list of our hosts into an inventory file (inventory.yml here). There is a default folder (group_vars) where we can store variables that would apply to any router we ran Ansible against and in this case it makes sense as my router credentials are the same. Lastly, retrieve_backup.yml is my actual playbook, i.e. where I tell Ansible what to do. Note: I manually logged in to cisco1.rodrigo.example and cisco2.rodrigo.example to populate ssh known_hosts files, otherwise Ansible complains these hosts are untrusted. Populating our Playbook file retrieve_backup.yml Let's say we just want to retrieve the OSPF configuration from our Cisco routers. We can useios_commandto type in any command to Cisco router and useregisterto store the output to a variable: Note: be careful with the indentation. I used 2 spaces here. We can then copy the content of the variable to a file in a given directory. In this case, we copied whatever is inospf_outputvariable toospf_configdirectory. From the Playbook file above we can work out that variables are referenced between{{ }}and we might probably be wondering why do we need to append stdout[0] to ospf_output right? If you know Python, you might be interested in knowing a bit more about what's going on under the hood so I'll clarify things a bit more here. The variableospf_outputis actually a dictionary andstdoutis one of its keys. In reality, ospf_output.stdout could be represented as ospf_output['stdout'] We add the[0] because the object retrieved by the key stdout is not a string. It's a list! And[0] just represents the first object in the list. Executing our Playbook I'll create ospf_config first: And we execute our playbook by issuingansible-playbookcommand: Now let's check if our OSPF config was retrieved: We can pretty much type in any IOS command we'd type in a real router, either to configure it or to retrieve its configuration. We could also append the date to the file name but it's out of the scope of this article. That's it for now.3.1KViews1like1CommentAgility 2020 - you're invited!
In-person event for Agility 2020 has been cancelled. Please see the Agility Event Page for more details. (Update 2/28/2020) In an abundance of caution for our customers, partners and employees, we have made the tough decision to cancel our in-person event for Agility 2020 due to the escalating travel and safety concerns related to the global COVID-19 (Coronavirus) outbreak. While we are disappointed to miss sharing ideas and solving problems with customers and partners from around the globe in person, we believe this is the best decision for everyone's welfare. We are rapidly developing an alternative to Agility as a virtual experience in the near term to deliver valuable Lab, Break-out Session, Certification and Keynote content to our customers and partners. Check back regularly for more details on the virtual event or email F5Agility@F5.com for additional information. <Professor Farnsworth imitation>Good news, everybody!</Professor Farnsworth imitation> As you know, there was no Agility 2019. This was in part so that we could reset the time of year for the conference from August to March. Agility 2020will be held from March 16-19, 2020 at theSwan & Dolphinin Orlando, Florida. Orlando, and Disney, and putt-putt golfing... That's right, *puts on ears* we're going to Disneyworld - and you are all cordially invited to participate in labs and breakouts, meet fellow F5 users, talk with F5 and partner subject-matter experts, learn to develop and deploy applications in days instead of months, secure your apps at scale in a multi-cloud environment, and hear about our vision for the future of F5 and NGINX. Registration is now open! The DevCentral team will be busy as usual that week. We areallflying over, and will be: hosting our usual booth and giving out swag in the expo hall, hosting a walk-in Nerdery zone next to our booth, where folks can drop in to speak with one of our subject-matter experts, presenting breakout sessions, hanging out at Geekfest, connecting community, enjoying the exclusive community area at the final night party, and of course, spoiling the dev/central MVPs during the joint 2019-20 MVP Summit at Agility with special sessions and activities. If you'd like to do more than pick up all the knowledge being dropped, if you have some cool technical stories or lessons-learned to share, please stay tuned for the open call for proposals which should go live in early December - so please start getting those great breakout, lightening round, and open talk ideas ready. Hope to see you there!2.4KViews3likes1Comment
F5 & Cisco ACI Essentials - Take advantage of Policy Based Redirect
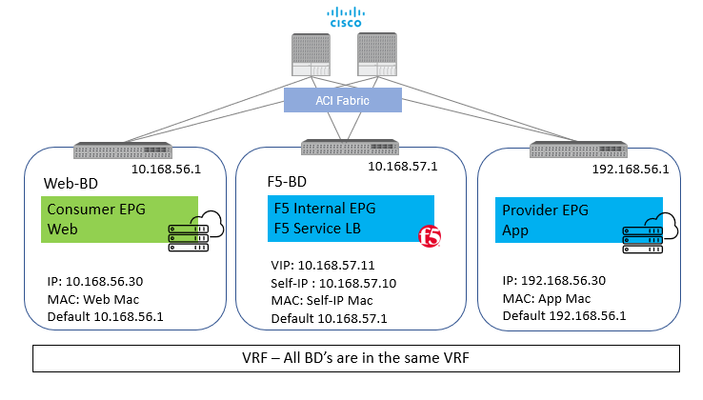
Different applications and environments have unique needs on how traffic is to be handled. Some applications due to the nature of their functionality or maybe due to a business need do require that the application server(s) are able to view the real IP of the client making the request to the application. Now when the request comes to the BIG-IP it has the option to change the real IP of the request or to keep it intact. In order to keep it intact the setting on the F5 BIG-IP ‘Source Address Translation’ is set to ‘None’. Now as simple as it may sound to just toggle a setting on the BIG-IP, a change of this setting causes significant change in traffic flow behavior. Let’s take an example with some actual values. Starting with a simple setup of a standalone BIG-IP with one interface on the BIG-IP for all traffic (one-arm) Client – 10.168.56.30 BIG-IP Virtual IP – 10.168.57.11 BIG-IP Self IP – 10.168.57.10 Server – 192.168.56.30 Scenario 1: With SNAT From Client : Src: 10.168.56.30 Dest: 10.168.57.11 From BIG-IP to Server: Src: 10.168.57.10 (Self-IP) Dest: 192.168.56.30 With this the server will respond back to 10.168.57.10 and BIG-IP will take care of forwarding the traffic back to the client. Here the application server see’s the IP 10.168.57.10 and not the client IP Scenario 2: No SNAT From Client : Src: 10.168.56.30 Dest: 10.168.57.11 From BIG-IP to Server: Src: 10.168.56.30 Dest: 192.168.56.30 With this the server will respond back to 10.168.56.30 and here where comes in the complication, the return traffic needs to go back to the BIG-IP and not the real client. One way to achieve this is to set the default GW of the server to the Self-IP of the BIG-IP and then the server will send the return traffic to the BIG-IP. BUT what if the server default gateway is not to be changed for whatsoever reason. It is at this time Policy based redirect will help. The default gw of the server will point to the ACI fabric, the ACI fabric will be able to intercept the traffic and send it over to the BIG-IP. With this the advantage of using PBR is two-fold The server(s) default gateway does not need to point to BIG-IP but can point to the ACI fabric The real client IP is preserved for the entire traffic flow Avoid server originated traffic to hit BIG-IP, resulting BIG-IP to configure a forwarding virtual to handle that traffic.If server originated traffic volume is high it could result unnecessary load the BIG-IP Before we get to the deeper into the topic of PRB below are a few links to help you refresh on some of the Cisco ACI and BIG-IP concepts ACI fundamentals: https://www.cisco.com/c/en/us/td/docs/switches/datacenter/aci/apic/sw/1-x/aci-fundamentals/b_ACI-Fundamentals.html SNAT and Automap: https://support.f5.com/csp/article/K7820 BIG-IP modes of deployment: https://support.f5.com/csp/article/K96122456#link_02_01 Now let’s look at what it takes to configure PBR using a Standalone BIG-IP Virtual Edition in One-Arm mode Network diagram for reference: To use the PBR feature on APIC - Service graph is a MUST Details on L4-L7 service graph on APIC To get hands on experience on deploying a service graph (without pbr) Configuration on APIC 1) Bridge domain ‘F5-BD’ Under Tenant->Networking->Bridge domains->’F5-BD’->Policy IP Data plane learning - Disabled 2) L4-L7 Policy-Based Redirect Under Tenant->Policies->Protocol->L4-L7 Policy based redirect, create a new one Name: ‘bigip-pbr-policy’ L3 destinations: BIG-IP Self-IP and MAC IP: 10.168.57.10 MAC: Find the MAC of interface the above Self-IP is assigned from logging into the BIG-IP (example: 00:50:56:AC:D2:81) 3) Logical Device Cluster- Under Tenant->Services->L4-L7, create a logical device Managed – unchecked Name: ‘pbr-demo-bigip-ve` Service Type: ADC Device Type: Virtual (in this example) VMM domain (choose the appropriate VMM domain) Devices: Add the BIG-IP VM from the dropdown and assign it an interface Name: ‘1_1’, VNIC: ‘Network Adaptor 2’ Cluster interfaces Name: consumer, Concrete interface Device1/[1_1] Name: provider, Concrete interface: Device1/[1_1] 4) Service graph template Under Tenant->Services->L4-L7->Service graph templates, create a service graph template Give the graph a name:’ pbr-demo-sgt’ and then drag and drop the logical device cluster (pbr-demo-bigip-ve) to create the service graph ADC: one-arm Route redirect: true 5) Click on the service graph created and then go to the Policy tab, make sure the Connections for the connectors C1 and C2 and set as follows: Connector C1 Direct connect – False (Not mandatory to set to 'True' because PBR is not enabled on consumer connector for the consumer to VIP traffic) Adjacency type – L3 Connector C2 Direct connect - True Adjacency type - L3 6) Apply the service graph template Right click on the service graph and apply the service graph Choose the appropriate consumer End point group (‘App’) provider End point group (‘Web’) and provide a name for the new contract For the connector select the following: BD: ‘F5-BD’ L3 destination – checked Redirect policy – ‘bigip-pbr-policy’ Cluster interface – ‘provider’ Once the service graph is deployed, it is in applied state and the network path between the consumer, BIG-IP and provider has been successfully setup on the APIC. 7) Verify the connector configuration for PBR. Go to Device selection policy under Tenant->Services-L4-L7. Expand the menu and click on the device selection policy deployed for your service graph. For the consumer connector where PBR is not enabled Connector name - Consumer Cluster interface - 'provider' BD- ‘F5-BD’ L3 destination – checked Redirect policy – Leave blank (no selection) For the provider connector where PBR is enabled: Connector name - Provider Cluster interface - 'provider' BD - ‘F5-BD’ L3 destination – checked Redirect policy – ‘bigip-pbr-policy’ Configuration on BIG-IP 1) VLAN/Self-IP/Default route Default route – 10.168.57.1 Self-IP – 10.168.57.10 VLAN – 4094 (untagged) – for a VE the tagging is taken care by vCenter 2) Nodes/Pool/VIP VIP – 10.168.57.11 Source address translation on VIP: None 3)iRule (end of the article) that can be helpful for debugging Few differences in configuration when the BIG-IP is a Virtual edition and is setup in a High availability pair 1)BIG-IP: Set MAC Masquerade (https://support.f5.com/csp/article/K13502) 2)APIC: Logical device cluster Promiscuous mode – enabled Add both BIG-IP devices as part of the cluster 3) APIC: L4-L7 Policy-Based Redirect L3 destinations: Enter the Floating BIG-IP Self-IP and MAC masquerade ------------------------------------------------------------------------------------------------------------------------------------------------------------------ Configuration is complete, let’s take a look at the traffic flows Client-> F5 BIG-IP -> Server Server-> F5 BIG-IP -> Client In Step 2 when the traffic is returned from the client, ACI uses the Self-IP and MAC that was defined in the L4-L7 redirect policy to send traffic to the BIG-IP iRule to help with debugging on the BIG-IP when LB_SELECTED { log local0. "==================================================" log local0. "Selected server [LB::server]" log local0. "==================================================" } when HTTP_REQUEST { set LogString "[IP::client_addr] -> [IP::local_addr]" log local0. "==================================================" log local0. "REQUEST -> $LogString" log local0. "==================================================" } when SERVER_CONNECTED { log local0. "Connection from [IP::client_addr] Mapped -> [serverside {IP::local_addr}] \ -> [IP::server_addr]" } when HTTP_RESPONSE { set LogString "Server [IP::server_addr] -> [IP::local_addr]" log local0. "==================================================" log local0. "RESPONSE -> $LogString" log local0. "==================================================" } Output seen in /var/log/ltm on the BIG-IP, look at the event <SERVER_CONNECTED> Scenario 1: No SNAT -> Client IP is preserved Rule /Common/connections <HTTP_REQUEST>: Src: 10.168.56.30 -> Dest: 10.168.57.11 Rule /Common/connections <SERVER_CONNECTED>: Src: 10.168.56.30 Mapped -> 10.168.56.30 -> Dest: 192.168.56.30 Rule /Common/connections <HTTP_RESPONSE>: Src: 192.168.56.30 -> Dest: 10.168.56.30 If you are curious of the iRule output if SNAT is enabled on the BIG-IP - Enable AutoMap on the virtual server on the BIG-IP Scenario 2: With SNAT -> Client IP not preserved Rule /Common/connections <HTTP_REQUEST>: Src: 10.168.56.30 -> Dest: 10.168.57.11 Rule /Common/connections <SERVER_CONNECTED>: Src: 10.168.56.30 Mapped -> 10.168.57.10-> Dest: 192.168.56.30 Rule /Common/connections <HTTP_RESPONSE>: Src: 192.168.56.30 -> Dest: 10.168.56.30 References: ACI PBR whitepaper: https://www.cisco.com/c/en/us/solutions/collateral/data-center-virtualization/application-centric-infrastructure/white-paper-c11-739971.html Troubleshooting guide: https://www.cisco.com/c/dam/en/us/td/docs/switches/datacenter/aci/apic/sw/4-x/troubleshooting/Cisco_TroubleshootingApplicationCentricInfrastructureSecondEdition.pdf Layer4-Layer7 services deployment guide https://www.cisco.com/c/en/us/td/docs/switches/datacenter/aci/apic/sw/4-x/L4-L7-services/Cisco-APIC-Layer-4-to-Layer-7-Services-Deployment-Guide-401/Cisco-APIC-Layer-4-to-Layer-7-Services-Deployment-Guide-401_chapter_011.html Service graph: https://www.cisco.com/c/en/us/td/docs/switches/datacenter/aci/apic/sw/4-x/L4-L7-services/Cisco-APIC-Layer-4-to-Layer-7-Services-Deployment-Guide-401/Cisco-APIC-Layer-4-to-Layer-7-Services-Deployment-Guide-401_chapter_0111.html https://www.cisco.com/c/en/us/td/docs/switches/datacenter/aci/apic/sw/4-x/L4-L7-services/Cisco-APIC-Layer-4-to-Layer-7-Services-Deployment-Guide-401.pdf2.3KViews1like3CommentsParsing complex BIG-IP json structures made easy with Ansible filters like json_query
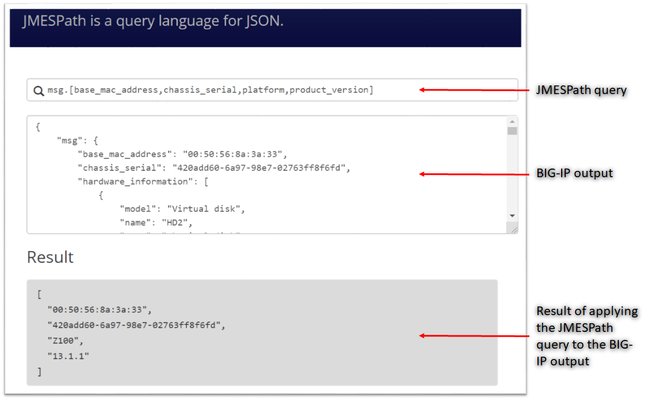
JMESPath and json_query JMESPath (JSON Matching Expression paths) is a query language for searching JSON documents. It allows you to declaratively extract elements from a JSON document. Have a look at this tutorial to learn more. The json_query filter lets you query a complex JSON structure and iterate over it using a loop structure.This filter is built upon jmespath, and you can use the same syntax as jmespath. Click here to learn more about the json_query filter and how it is used in Ansible. In this article we are going to use the bigip_device_info module to get various facts from the BIG-IP and then use the json_query filter to parse the output to extract relevant information. Ansible bigip_device_info module Playbook to query the BIG-IP and gather system based information. - name: "Get BIG-IP Facts" hosts: bigip gather_facts: false connection: local tasks: - name: Query BIG-IP facts bigip_device_info: provider: validate_certs: False server: "xxx.xxx.xxx.xxx" user: "*****" password: "*****" gather_subset: - system-info register: bigip_facts - set_fact: facts: '{{bigip_facts.system_info}}' - name: debug debug: msg="{{facts}}" To view the output on a different subset, below are a few examples to change the gather_subset and set_fact values in the above playbook from gather_subset: system-info, facts: bigip_facts.system_info to any of the below: gather_subset: vlans , facts: bigip_facts.vlans gather_subset: self-ips, facts: bigip_facts.self_ips gather_subset: nodes. facts: bigip_facts.nodes gather_subset: software-volumes, facts: bigip_facts.software_volumes gather_subset: virtual-servers, facts: bigip_facts.virtual_servers gather_subset: system-info, facts: bigip_facts.system_info gather_subset: ltm-pools, facts: bigip_facts.ltm_pools Click here to view all the information that can be obtained from the BIG-IP using this module. Parse the JSON output Once we have the output lets take a look at how to parse the output. As mentioned above the jmespath syntax can be used by the json_query filter. Step 1: We will get the jmespath syntax for the information we want to extract Step 2: We will see how the jmespath syntax and then be used with json_query in an Ansible playbook The website used in this article to try out the below syntax: https://jmespath.org/ Some BIG-IP sample outputs are attached to this article as well (Check the attachments section after the References). The attachment file is a combined output of a few configuration subsets.Copy paste the relevant information from the attachment to test the below examples if you do not have a BIG-IP. System information The output for this section is obtained with above playbook using parameters: gather_subset: system-info, facts: bigip_facts.system_info Once the above playbook is run against your BIG-IP or if you are using the sample configuration attached, copy the output and paste it in the relevant text box. Try different queries by placing them in the text box next to the magnifying glass as shown in image below # Get MAC address, serial number, version information msg.[base_mac_address,chassis_serial,platform,product_version] # Get MAC address, serial number, version information and hardware information msg.[base_mac_address,chassis_serial,platform,product_version,hardware_information[*].[name,type]] Software volumes The output for this section is obtained with above playbook using parameters: gather_subset: software-volumes facts: bigip_facts.software_volumes # Get the name and version of the software volumes installed and its status msg[*].[name,active,version] # Get the name and version only for the software volume that is active msg[?active=='yes'].[name,version] VLANs and Self-Ips The output for this section is obtained with above playbook using parameters gather_subset: vlans and self-ips facts: bigip_facts Look at the following example to define more than one subset in the playbook # Get all the self-ips addresses and vlans assigned to the self-ip # Also get all the vlans and the interfaces assigned to the vlan [msg.self_ips[*].[address,vlan], msg.vlans[*].[full_path,interfaces[*]]] Nodes The output for this section is obtained with above playbook using parameters gather_subset: nodes, facts: bigip_facts.nodes # Get the address and availability status of all the nodes msg[*].[address,availability_status] # Get availability status and reason for a particular node msg[?address=='192.0.1.101'].[full_path,availability_status,status_reason] Pools The output for this section is obtained with above playbook using parameters gather_subset: ltm-pools facts: bigip_facts.ltm_pools # Get the name of all pools msg[*].name # Get the name of all pools and their associated members msg[*].[name,members[*]] # Get the name of all pools and only address of their associated members msg[*].[name,members[*].address] # Get the name of all pools along with address and status of their associated members msg[*].[name,members[*].address,availability_status] # Get status of pool members of a particular pool msg[?name=='/Common/pool'].[members[*].address,availability_status] # Get status of pool # Get address, partition, state of pool members msg[*].[name,members[*][address,partition,state],availability_status] # Get status of a particular pool and particular member (multiple entries on a member) msg[?full_name=='/Common/pool'].[members[?address=='192.0.1.101'].[address,partition],availability_status] Virtual Servers The output for this section is obtained with above playbook using parameters gather_subset: virtual-servers facts: bigip_facts.virtual_servers # Get destination IP address of all virtual servers msg[*].destination # Get destination IP and default pool of all virtual servers msg[*].[destination,default_pool] # Get me all destination IP of all virtual servers that a particular pool as their default pool msg[?default_pool=='/Common/pool'].destination # Get me all profiles assigned to all virtual servers msg[*].[destination,profiles[*].name] Loop and display using Ansible We have seen how to use the jmespath syntax and extract information, now lets see how to use it within an Ansible playbook - name: Parse the output hosts: localhost connection: local gather_facts: false tasks: - name: Setup provider set_fact: provider: server: "xxx.xxx.xxx.xxx" user: "*****" password: "*****" server_port: "443" validate_certs: "no" - name: Query BIG-IP facts bigip_device_info: provider: "{{provider}}" gather_subset: - system_info register: bigip_facts - debug: msg="{{bigip_facts.system_info}}" # Use json query filter. The query_string will be the jmespath syntax # From the jmespath query remove the 'msg' expression and use it as it is - name: "Show relevant information" set_fact: result: "{{bigip_facts.system_info | json_query(query_string)}}" vars: query_string: "[base_mac_address,chassis_serial,platform,product_version,hardware_information[*].[name,type]]" - debug: "msg={{result}}" Another example of what would change if you use a different query (only highlighting the changes that need to made below from the entire playbook) - name: Query BIG-IP facts bigip_device_info: provider: "{{provider}}" gather_subset: - ltm-pools register: bigip_facts - debug: msg="{{bigip_facts.ltm_pools}}" - name: "Show relevant information" set_fact: result: "{{bigip_facts.ltm_pools | json_query(query_string)}}" vars: query_string: "[*].[name,members[*][address,partition,state],availability_status]" The key is to get the jmespath syntax for the information you are looking for and then its a simple step to incorporate it within your Ansible playbook References Try the queries - https://jmespath.org/ Learn more jmespath syntax and example - https://jmespath.org/tutorial.html Ansible lab that can be used as a sandbox - https://clouddocs.f5.com/training/automation-sandbox/1.9KViews2likes2CommentsDeclarative Advanced WAF policy lifecycle in a CI/CD pipeline
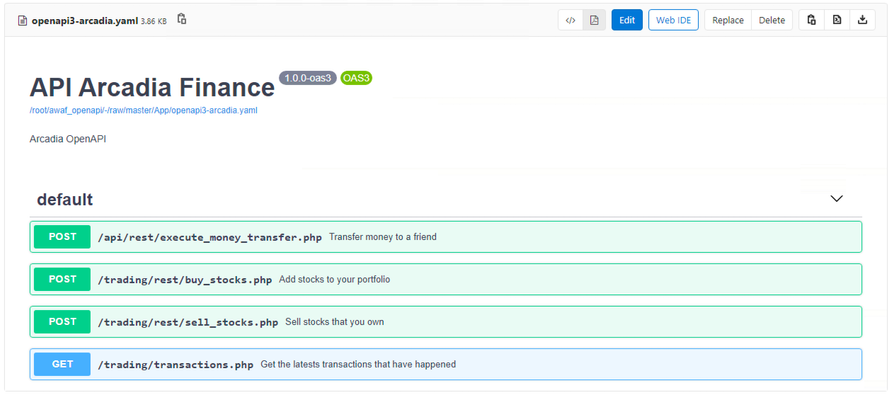
The purpose of this article is to show the configuration used to deploy a declarative Advanced WAF policy to a BIG-IP and automatically configure it to protect an API workload by consuming an OpenAPI file describing the application. For this experiment, a Gitlab CI/CD pipeline was used to deploy an API workload to Kubernetes, configure a declarative Adv. WAF policy to a BIG-IP device and tuning it by incorporating learning suggestions exported from the BIG-IP. Lastly, the F5 WAF tester tool was used to determine and improve the defensive posture of the Adv. WAF policy. Deploying the declarative Advanced WAF policy through a CI/CD pipeline To deploy the Adv. WAF policy, the Gitlab CI/CD pipeline is calling an Ansible playbook that will in turn deploy an AS3 application referencing the Adv.WAF policy from a separate JSON file. This allows the application definition and WAF policy to be managed by 2 different groups, for example NetOps and SecOps, supporting separation of duties. The following Ansible playbook was used; --- - hosts: bigip connection: local gather_facts: false vars: my_admin: "xxxx" my_password: "xxxx" bigip: "xxxx" tasks: - name: Deploy AS3 API AWAF policy uri: url: "https://{{ bigip }}/mgmt/shared/appsvcs/declare" method: POST headers: "Content-Type": "application/json" "Authorization": "Basic xxxxxxxxxx body: "{{ lookup('file','as3_waf_openapi.json') }}" body_format: json validate_certs: no status_code: 200 The Advanced WAF policy 'as3_waf_openapi.json' was specified as follows: { "class": "AS3", "action": "deploy", "persist": true, "declaration": { "class": "ADC", "schemaVersion": "3.2.0", "id": "Prod_API_AS3", "API-Prod": { "class": "Tenant", "defaultRouteDomain": 0, "arcadia": { "class": "Application", "template": "generic", "VS_API": { "class": "Service_HTTPS", "remark": "Accepts HTTPS/TLS connections on port 443", "virtualAddresses": ["xxxxx"], "redirect80": false, "pool": "pool_NGINX_API", "policyWAF": { "use": "Arcadia_WAF_API_policy" }, "securityLogProfiles": [{ "bigip": "/Common/Log all requests" }], "profileTCP": { "egress": "wan", "ingress": { "use": "TCP_Profile" } }, "profileHTTP": { "use": "custom_http_profile" }, "serverTLS": { "bigip": "/Common/arcadia_client_ssl" } }, "Arcadia_WAF_API_policy": { "class": "WAF_Policy", "url": "http://xxxx/root/awaf_openapi/-/raw/master/WAF/ansible/bigip/policy-api.json", "ignoreChanges": true }, "pool_NGINX_API": { "class": "Pool", "monitors": ["http"], "members": [{ "servicePort": 8080, "serverAddresses": ["xxxx"] }] }, "custom_http_profile": { "class": "HTTP_Profile", "xForwardedFor": true }, "TCP_Profile": { "class": "TCP_Profile", "idleTimeout": 60 } } } } } The AS3 declaration will provision a separate Administrative Partition ('API-Prod') containing a Virtual Server ('VS_API'), an Adv. WAF policy ('Arcadia_WAF_API_policy') and a pool ('pool_NGINX_API'). The Adv.WAF policy being referenced ('policy-api.json') is stored in the same Gitlab repository but can be downloaded from a separate location. { "policy": { "name": "policy-api-arcadia", "description": "Arcadia API", "template": { "name": "POLICY_TEMPLATE_API_SECURITY" }, "enforcementMode": "transparent", "server-technologies": [ { "serverTechnologyName": "MySQL" }, { "serverTechnologyName": "Unix/Linux" }, { "serverTechnologyName": "MongoDB" } ], "signature-settings": { "signatureStaging": false }, "policy-builder": { "learnOnlyFromNonBotTraffic": false }, "open-api-files": [ { "link": "http://xxxx/root/awaf_openapi/-/raw/master/App/openapi3-arcadia.yaml" } ] }, "modifications": [ ] } The declarative Adv.WAF policy is referencing in turn the OpenAPI file ('openapi3-arcadia.yaml') that describes the application being protected. Executing the Ansible playbook results in the AS3 application being deployed, along with the Adv.WAF policy that is automatically configured according to the OpenAPI file. Handling learning suggestions in a CI/CD pipeline The next step in the CI/CD pipeline used for this experiment was to send legitimate traffic using the API and collect the learning suggestions generated by the Adv.WAF policy, which will allow a simple way to customize the WAF policy further for the specific application being protected. The following Ansible playbook was used to retrieve the learning suggestions: --- - hosts: bigip connection: local gather_facts: true vars: my_admin: "xxxx" my_password: "xxxx" bigip: "xxxxx" tasks: - name: Get all Policy_key/IDs for WAF policies uri: url: 'https://{{ bigip }}/mgmt/tm/asm/policies?$select=name,id' method: GET headers: "Authorization": "Basic xxxxxxxxxxx" validate_certs: no status_code: 200 return_content: yes register: waf_policies - name: Extract Policy_key/ID of Arcadia_WAF_API_policy set_fact: Arcadia_WAF_API_policy_ID="{{ item.id }}" loop: "{{ (waf_policies.content|from_json)['items'] }}" when: item.name == "Arcadia_WAF_API_policy" - name: Export learning suggestions uri: url: "https://{{ bigip }}/mgmt/tm/asm/tasks/export-suggestions" method: POST headers: "Content-Type": "application/json" "Authorization": "Basic xxxxxxxxxxx" body: "{ \"inline\": \"true\", \"policyReference\": { \"link\": \"https://{{ bigip }}/mgmt/tm/asm/policies/{{ Arcadia_WAF_API_policy_ID }}/\" } }" body_format: json validate_certs: no status_code: - 200 - 201 - 202 - name: Get learning suggestions uri: url: "https://{{ bigip }}/mgmt/tm/asm/tasks/export-suggestions" method: GET headers: "Authorization": "Basic xxxxxxxxx" validate_certs: no status_code: 200 register: result - name: Print learning suggestions debug: var=result A sample learning suggestions output is shown below: "json": { "items": [ { "endTime": "xxxxxxxxxxxxx", "id": "ZQDaRVecGeqHwAW1LDzZTQ", "inline": true, "kind": "tm:asm:tasks:export-suggestions:export-suggestions-taskstate", "lastUpdateMicros": 1599953296000000.0, "result": { "suggestions": [ { "action": "add-or-update", "description": "Enable Evasion Technique", "entity": { "description": "Directory traversals" }, "entityChanges": { "enabled": true }, "entityType": "evasion" }, { "action": "add-or-update", "description": "Enable HTTP Check", "entity": { "description": "Check maximum number of parameters" }, "entityChanges": { "enabled": true }, "entityType": "http-protocol" }, { "action": "add-or-update", "description": "Enable HTTP Check", "entity": { "description": "No Host header in HTTP/1.1 request" }, "entityChanges": { "enabled": true }, "entityType": "http-protocol" }, { "action": "add-or-update", "description": "Enable enforcement of policy violation", "entity": { "name": "VIOL_REQUEST_MAX_LENGTH" }, "entityChanges": { "alarm": true, "block": true }, "entityType": "violation" } Incorporating the learning suggestions in the Adv.WAF policy can be done by simple copy&pasting the self-contained learning suggestions blocks into the "modifications" list of the Adv.WAF policy: { "policy": { "name": "policy-api-arcadia", "description": "Arcadia API", "template": { "name": "POLICY_TEMPLATE_API_SECURITY" }, "enforcementMode": "transparent", "server-technologies": [ { "serverTechnologyName": "MySQL" }, { "serverTechnologyName": "Unix/Linux" }, { "serverTechnologyName": "MongoDB" } ], "signature-settings": { "signatureStaging": false }, "policy-builder": { "learnOnlyFromNonBotTraffic": false }, "open-api-files": [ { "link": "http://xxxxxx/root/awaf_openapi/-/raw/master/App/openapi3-arcadia.yaml" } ] }, "modifications": [ { "action": "add-or-update", "description": "Enable Evasion Technique", "entity": { "description": "Directory traversals" }, "entityChanges": { "enabled": true }, "entityType": "evasion" } ] } Enhancing Advanced WAF policy posture by using the F5 WAF tester The F5 WAF tester is a tool that generates known attacks and checks the response of the WAF policy. For example, running the F5 WAF tester against a policy that has a "transparent" enforcement mode will cause the tests to fail as the attacks will not be blocked. The F5 WAF tester can suggest possible enhancement of the policy, in this case the change of the enforcement mode. An abbreviated sample output of the F5 WAF Tester: ................................................................ "100000023": { "CVE": "", "attack_type": "Server Side Request Forgery", "name": "SSRF attempt (AWS Metadata Server)", "results": { "parameter": { "expected_result": { "type": "signature", "value": "200018040" }, "pass": false, "reason": "ASM Policy is not in blocking mode", "support_id": "" } }, "system": "All systems" }, "100000024": { "CVE": "", "attack_type": "Server Side Request Forgery", "name": "SSRF attempt - Local network IP range 10.x.x.x", "results": { "request": { "expected_result": { "type": "signature", "value": "200020201" }, "pass": false, "reason": "ASM Policy is not in blocking mode", "support_id": "" } }, "system": "All systems" } }, "summary": { "fail": 48, "pass": 0 } Changing the enforcement mode from "transparent" to "blocking" can easily be done by editing the same Adv. WAF policy file: { "policy": { "name": "policy-api-arcadia", "description": "Arcadia API", "template": { "name": "POLICY_TEMPLATE_API_SECURITY" }, "enforcementMode": "blocking", "server-technologies": [ { "serverTechnologyName": "MySQL" }, { "serverTechnologyName": "Unix/Linux" }, { "serverTechnologyName": "MongoDB" } ], "signature-settings": { "signatureStaging": false }, "policy-builder": { "learnOnlyFromNonBotTraffic": false }, "open-api-files": [ { "link": "http://xxxxx/root/awaf_openapi/-/raw/master/App/openapi3-arcadia.yaml" } ] }, "modifications": [ { "action": "add-or-update", "description": "Enable Evasion Technique", "entity": { "description": "Directory traversals" }, "entityChanges": { "enabled": true }, "entityType": "evasion" } ] } A successful run will will be achieved when all the attacks will be blocked. ......................................... "100000023": { "CVE": "", "attack_type": "Server Side Request Forgery", "name": "SSRF attempt (AWS Metadata Server)", "results": { "parameter": { "expected_result": { "type": "signature", "value": "200018040" }, "pass": true, "reason": "", "support_id": "17540898289451273964" } }, "system": "All systems" }, "100000024": { "CVE": "", "attack_type": "Server Side Request Forgery", "name": "SSRF attempt - Local network IP range 10.x.x.x", "results": { "request": { "expected_result": { "type": "signature", "value": "200020201" }, "pass": true, "reason": "", "support_id": "17540898289451274344" } }, "system": "All systems" } }, "summary": { "fail": 0, "pass": 48 } Conclusion By adding the Advanced WAF policy into a CI/CD pipeline, the WAF policy can be integrated in the lifecycle of the application it is protecting, allowing for continuous testing and improvement of the security posture before it is deployed to production. The flexible model of AS3 and declarative Advanced WAF allows the separation of roles and responsibilities between NetOps and SecOps, while providing an easy way for tuning the policy to the specifics of the application being protected. Links UDF lab environment link. Short instructional video link.1.8KViews3likes1Comment