AS3 Best Practice
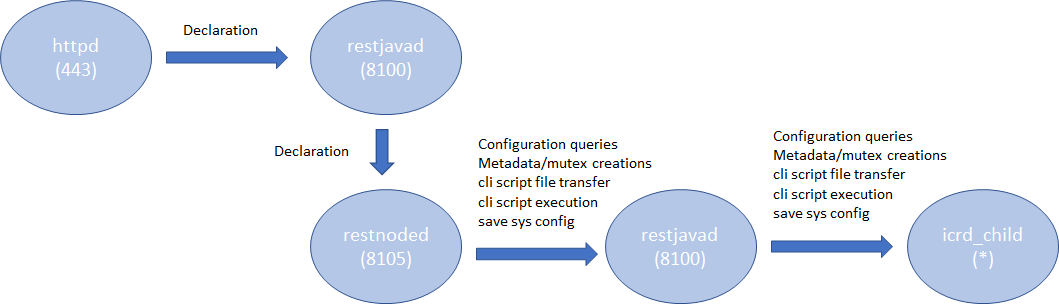
Introduction AS3 is a declarative API that uses JSON key-value pairs to describe a BIG-IP configuration. From virtual IP to virtual server, to the members, pools, and nodes required, AS3 provides a simple, readable format in which to describe a configuration. Once you've got the configuration, all that's needed is to POST it to the BIG-IP, where the AS3 extension will happily accept it and execute the commands necessary to turn it into a fully functional, deployed BIG-IP configuration. If you are new to AS3, start reading the following references: Products - Automation and orchestration toolchain(f5.com; Product information) Application Services 3 Extension Documentation(clouddocs; API documentation and guides) F5 Application Services 3 Extension(AS3) (GitHub; Source repository) This article describes some considerations in order to efficiently deploy the AS3 configurations. Architecture In the TMOS space, the services that AS3 provides are processed by a daemon named 'restnoded'. It relies on the existing BIG-IP framework for deploying declarations. The framework consists of httpd, restjavad and icrd_child as depicted below (the numbers in parenthesis are listening TCP port numbers). These processes are also used by other services. For example, restjavad is a gateway for all the iControl REST requests, and is used by a number of services on BIG-IP and BIG-IQ. When an interaction between any of the processes fails, AS3 operation fails. The failures stem from lack of resources, timeouts, data exceeding predefined thresholds, resource contention among the services, and more. In order to complete AS3 operations successfully, it is advised to follow the Best Practice outlined below. Best Practice Your single source of truth is your declaration Refrain from overwriting the AS3-deployed BIG-IP configurations by the other means such as TMSH, GUI or iControl REST calls. Since you started to use the AS3 declarative model, the source of truth for your device's configurations is in your declaration, not the BIG-IP configuration files. Although AS3 tries to weigh BIG-IP locally stored configurations as much as it can do, discrepancy between the declaration and the current configuration on BIG-IP may cause the AS3 to perform less efficiently or error unexpectedly. When you wish to change a section of a tenant (e.g., pool name change), modify the declaration and submit it. Keep the number of applications in one tenant to a minimum AS3 processes each tenant separately.Having too many applications (virtual servers) in a single tenant (partition) results in a lengthy poll when determining the current configuration. In extreme cases (thousands of virtuals), the action may time out. When you want to deploy a thousand or more applications on a single device, consider chunking the work for AS3 by spreading the applications across multiple tenants (say, 100 applications per tenant). AS3 tenant access behavior behaves as BIG-IP partition behavior.A non-Common partition virtual cannot gain access to another partition's pool, and in the same way, an AS3 application does not have access to a pool or profile in another tenant.In order to share configuration across tenants, AS3 allows configuration of the "Shared" application within the "Common" tenant.AS3 avoids race conditions while configuring /Common/Shared by processing additions first and deletions last, as shown below.This dual process may cause some additional delay in declaration handling. Overwrite rather than patching (POSTing is a more efficient practice than PATCHing) AS3 is a stateless machine and is idempotent. It polls BIG-IP for its full configuration, performs a current-vs-desired state comparison, and generates an optimal set of REST calls to fill the differences.When the initial state of BIG-IP is blank, the poll time is negligible.This is why initial configuration with AS3 is often quicker than subsequent changes, especially when the tenant contains a large number of applications. AS3 provides the means to partially modify using PATCH (seeAS3 API Methods Details), but do not expect PATCH changes to be performant.AS3 processes each PATCH by (1) performing a GET to obtain the last declaration, (2) patching that declaration, and (3) POSTing the entire declaration to itself.A PATCH of one pool member is therefore slower than a POST of your entire tenant configuration.If you decide to use PATCH,make sure that the tenant configuration is a manageable size. Note: Using PATCH to make a surgical change is convenient, but using PATCH over POST breaks the declarative model. Your declaration should be your single source of truth.If you include PATCH, the source of truth becomes "POST this file, then apply one or more PATCH declarations." Get the latest version AS3 is evolving rapidly with new features that customers have been wishing for along with fixes for known issues. Visitthe AS3 section of the F5 Networks Github.Issuessection shows what features and fixes have been incorporated. For BIG-IQ, check K54909607: BIG-IQ Centralized Management compatibility with F5 Application Services 3 Extension and F5 Declarative Onboarding for compatibilities with BIG-IQ versions before installation. Use administrator Use a user with the administrator role when you submit your declaration to a target BIG-IP device. Your may find your role insufficient to manipulate BIG-IP objects that are included in your declaration. Even one authorized item will cause the entire operation to fail and role back. See the following articles for more on BIG-IP user and role. Manual Chapter : User Roles (12.x) Manual Chapter : User Roles (13.x) Manual Chapter : User Roles (14.x) Prerequisites and Requirements(clouddocs AS3 document) Use Basic Authentication for a large declaration You can choose either Basic Authentication (HTTP Authorization header) or Token-Based Authentication (F5 proprietary X-F5-Auth-Token) for accessing BIG-IP. While the Basic Authentication can be used any time, a token obtained for the Token-Based Authentication expires after 1,200 seconds (20 minutes). While AS3 does re-request a new token upon expiry, it requires time to perform the operation, which may cause AS3 to slow down. Also, the number of tokens for a user is limited to 100 (since 13.1), hence if you happen to have other iControl REST players (such as BIG-IQ or your custom iControl REST scripts) using the Token-Based Authentication for the same user, AS3 may not be able to obtain the next token, and your request will fail. See the following articles for more on the Token-Based Authentication. Demystifying iControl REST Part 6: Token-Based Authentication(DevCentral article). iControl REST Authentication Token Management(DevCentral article) Authentication and Authorization(clouddocs AS3 document) Choose the best window for deployment AS3 (restnoded daemon) is a Control Plane process. It competes against other Control Plane processes such as monpd and iRules LX (node.js) for CPU/memory resources. AS3 uses the iControl REST framework for manipulating the BIG-IP resources. This implies that its operation is impacted by any processes that use httpd (e.g., GUI), restjavad, icrd_child and mcpd. If you have resource-hungry processes that run periodically (e.g., avrd), you may want to run your AS3 declaration during some other time window. See the following K articles for alist of processes K89999342 BIG-IP Daemons (12.x) K05645522BIG-IP Daemons (v13.x) K67197865BIG-IP Daemons (v14.x) K14020: BIG-IP ASM daemons (11.x - 15.x) K14462: Overview of BIG-IP AAM daemons (11.x - 15.x) Workarounds If you experience issues such as timeout on restjavad, it is possible that your AS3 operation had resource issues. After reviewing the Best Practice above but still unable to alleviate the problem, you may be able to temporarily fix it by applying the following tactics. Increase the restjavad memory allocation The memory size of restjavad can be increased by the following tmsh sys db commands tmsh modify sys db provision.extramb value <value> tmsh modify sys db restjavad.useextramb value true The provision.extramb db key changes the maximum Java heap memory to (192 + <value> * 8 / 10) MB. The default value is 0. After changing the memory size, you need to restart restjavad. tmsh restart sys service restjavad See the following article for more on the memory allocation: K26427018: Overview of Management provisioning Increase a number of icrd_child processes restjavad spawns a number of icrd_child processes depending on the load. The maximum number of icrd_child processes can be configured from /etc/icrd.conf. Please consult F5 Support for details. See the following article for more on the icrd_child process verbosity: K96840770: Configuring the log verbosity for iControl REST API related to icrd_child Decrease the verbosity levels of restjavad and icrd_child Writing log messages to the file system is not exactly free of charge. Writing unnecessarily large amount of messages to files would increase the I/O wait, hence results in slowness of processes. If you have changed the verbosity levels of restjavad and/or icrd_child, consider rolling back the default levels. See the following article for methods to change verbosity level: K15436: Configuring the verbosity for restjavad logs on the BIG-IP system13KViews12likes2Comments2021 DevCentral MVP Announcement
Congratulations to the 2021 DevCentral MVPs! The DevCentral MVP Award is given annually to an exclusive group of expert users in the technical community who go out of their way to engage with the community by sharing their experience and knowledge with others. This is our way of recognizing their significant contributions, because while all of our users collectively make DevCentral one of the top community sites around and a valuable resource for everyone, MVPs regularly go above and beyond in assisting fellow F5 users both on- and offline.We understand that 2020 was difficult for everyone, and we are extra-grateful to this year's MVPs for going out of their ways to help others. MVPs get badges in their DevCentral profiles so everyone can see that they are recognized experts (you'll also see this if you hover over their name in a thread). This year’s MVPs will receive a glass award, certificate, exclusive thank-you gifts, and invitations to exclusive webinars and behind-the-scenes looks at things like roadmaps and new product sneak-previews. The 2021 DevCentral MVPs (by username) are: ·Andy McGrath ·Austin Geraci ·Amine Kadimi ·Boneyard ·Dario Garrido ·EAA ·FrancisD ·Hamish Marson ·Iaine ·Jad Tabbara (JTI) ·jaikumar_f5 ·JG ·JuniorC · Kai Wilke ·Kees van den Bos ·Kevin Davies ·Leonardo Souza ·lidev ·Manthey ·Mayur Sutare ·Nathan Britton ·Niels van Sluis ·Patrik Jonsson ·Philip Jönsson ·Piotr Lewandowski ·Rob_carr ·Samir Jha ·Sebastian Maniak ·TimRiker ·Vijay ·What Lies Beneath ·Yann Desmaret ·Youssef763Views6likes3Comments
A taste of Troubleshooting Automation on F5 boxes using Python
Quick Intro This article is like a getting started guide for those unfamiliar with troubleshooting automation in Python on BIG-IP. We're going to create a very simple script that checks CPU usage of a given process and: If CPU > 90%, it prints a message saying that CPU is high Otherwise, it prints a message saying that CPU is OK The idea of a simple script is so you don't get distracted with the script itself and follow along my thought as I add more features. The following command prints out the current CPU usage of a given process (tmm.0) in this case: Creating a function that returns CPU usage Python has a dynamic prompt known as REPL where we can test our code in real time and all we need to do on BIG-IP is to type keyword python: So, functions in Python abstracts a more complex task and returns a result. Functions are defined like this: For example: Before we create our function to return CPU usage from a particular daemon, we need to know how to execute Linux commands using Python: Now, we can finally create our function that returns CPU usage of a given daemon by storing above command's output into a variable and returning it: Keep above function handy! Creating a loop to check if CPU is high Now we're going to add above function to a loop. Why? Because we want our script to flag to us when CPU usage is above 90%, remember? One solution is to use a while loop. If you don't know what's a while loop then that's a very simple example that shows you that the loop keeps going until a certain condition we define is satisfied. For example, in this case here we set a variable number = 0 and while number is not yet 10, we keep increasing number by 1 and print it: PS: number += 1 is the same as number = number + 1 For our loop, we can just store the value from our previous function into a variable calledactualusageand use anif/elseclause to print out a message when CPU is high and a different one when it's not: PS: while True would just run an infinite loop. The only way to leave such a loop would be to explicitly usebreakkeyword when a condition we specify is satisfied inside our loop.. Adding 1 second break interval to loop Notice that previous loop will probably eat up a lot of CPU resources so we're better off waiting at least 1 second before each check using time.sleep as seen below: Now our script will wait for 1 second between checks. Bundling our script up together Now let's bundle it up together and see what we've got up to now: We're importing commands and time so we can use commands.getoutput() and time.sleep() functions respectively. Notice I've added a path to python executable in the first line of our script above. This will allow us to execute our script using ./script.py rather than python script.py. Isn't it better? Let's test it: Lovely. Our script seems to be working fine. I pressed Ctrl+C to exit the loop. Making our script accept process name as argument Up to now, we've been passing the process name (tmm.0) directly to our script. Wouldn't it be better if we added process name as an argument like./check-cpu-usage.py <process name>? The simplest way to add arguments in Python is to usesys.argv. Here's an example: Note that sys.argv[0]always returns script's name andsys.argv[1]the first parameter we typed in. Yes, if we wanted to return a second parameter it would besys.argv[2]and so on. The idea here is to store whatever we type in as argument into a variable and copy that variable to checkcpu() function: Now let's confirm it works: Much better, eh? Final test Let's create a simplesillyscript.shto eat up a lot of CPU cycles deliberately and finish up our test: If you're a beginner in Python's world, you can stop here and try the script with a few other processes and play with it. Otherwise, I'd suggest going through Appendix sections. Appendix 1: Making our script return an error when no argument is passed to it Let's add the ability to return an error if we accidentally execute the script without any arguments. For this we can usetryandexceptclause: Basically, sys.argv[1] (our first argument) is copied to a variable named argument. Therefore, if we execute the script without any arguments, except clause is triggered printing an error message. Easy eh? Let's try: Now, we can incorporate that to our script: Appendix 2: Making our script automatically stop after 5 seconds We can also add a timer for the script to automatically finish after a certain amount of time. Here's how we do it: If we run the above code, we'll see nothing going on for 5 seconds and script will stop and print a message: We can do something similar to our script and make it exit after 5 seconds by storing the time our script started (in start variable) and testing if current time.time() is ever higher than start + 5 (notice I stored 5 into a variable named MAX_TIME_RUNNING): Now, let's confirm it works The command prompt returned after 5 seconds and there was no need to press Ctrl+C. We could fine tune and improve our script even further but this is enough to give you a taste of Python programming language.1.4KViews6likes3Comments
Understanding Performance Metrics and Network Traffic
Introduction Do you ever look at specification sheets for technology products, and think to yourself, "hmm... these numbers are bigger than those numbers. That's good, right?" This is a reasonable response in the absesnce of precise information. However, an incomplete understanding often results in applying the wrong solution to a problem. Consider that a peregrine falcon is faster than a person on a bicycle, but a person on a bicycle can perform far more work per trip due to an exponentially larger carrying capacity. The falcon would be great for carrying a single message on a slip of paper. It'd be lousy for carrying a stack of books. Selecting the device to use, be it falcon or bicycle, requires at least two metrics. We need to understand both the expected velocity and the carrying capacity. Units of networking equipment, be they virtual or physical, typically have published specifications that one can use to compare performance between solutions. My goal is not to suggest one solution or another. Instead, my goal is to give you the ability to understand what the metrics truly mean. All Hail The OSI Model! The OSI model provides a logical framework for discussing network concepts. This table describes what you can find at each layer: # Name Summary 7 Application HTTP 6 Presentation Data formats 5 Session TLS (strangely debatable) 4 Transport TCP / UDP 3 Network IPv4 / IPv6 2 Data Link Ethernet frames 1 Physical Cabling, optics This gives us a common framework for explaining things like "What is the difference between connections per second (CPS) and transactions per second (TPS)?" or "What does infinite encryption session reuse mean?" The key point is that, in the general case, every layer can support multiple interactions of the layer above it. Consider that I can consume multiple HTTP objects over a single TCP connection when using HTTP/1.1. It is possible to request a large HTTP object by using multiple TCP connections, but the way that actually happens is through sending multiple HTTP requests, each with its own TCP connection, specifying different parts of the same object. CPS, TPS, pps, Stats Excess Now that we have established a common framework for understanding the intent behind the different metrics, I will define some of the common types. Label Meaning Explanation CPS connections per second The number of L4 connections established per second. TPS transactions per second The number of L5-L7 transactions completed per second. RPS requests per second The number of L5-L7 requests satisfied per second, often interchangeable with TPS. RPC requests per connection The number of L5-L7 requests completed for a single L4 connection. Example: HTTP/1.1 with 100 transactions per TCP connection would be 100-RPC. bps or bit/s bits per second The network bandwidth in bits per second. Some people use GB/s, Gb/s and Gbps interchangeably, but the unit is decidedly important. 1 GB/s (gigabyte per second) is 8 Gbps (gigabits per second) See: data-rate units. Things get a bit pedantic with GiB/s vs GB/s, but 8:1 bytes:bits is correct when working from the same base unit. fps frames per second A measure of L2 frames per second, often used for core switching or firewalls. The distinction is that not all network frames contain valid data packets or datagrams. pps packets per second A measure of the L3/L4 packets per second, typically for TCP and UDP traffic. CC concurrent connections The number of concurrently established L4 connections. Example: if you have 100 CPS, and each connection has a lifetime of 100 s, then the resultant CC is 10,000 (connection rate * connection lifetime). As you might expect, there are additional statistics in the wild. The objective is to take a specification sheet label and number, like "800 angry orchids per second", and decompose it. "Where do angry orchids fit in the OSI model? If angry orchids are an L7 concept, how many angry orchids are served through a single TCP session?" This method will allow you to understand any specification sheet metric that is constructed from logical data. More importantly, it will equip you to question metrics that make no sense. How Are These Numbers Generated? You might think this: "Okay, so this specification sheet for a product says that it can do foo CPS and bar Gbps. Surely it can perform those feats at the same time." You would be wrong. A peregrine falcon cannot dive at maximum velocity while carrying a book - the book has a lower terminal velocity in atmosphere. Specification sheet numbers for things in the networking world are generated by a test designed to exercise a single function. Consider a TCP connections per second (CPS) test. The harness will be configured such that a TCP handshake is established, a client will send a single request for an object, a server will reply with an object small enough to fit within a single TCP packet, and then the TCP connection is torn down gracefully. The maximum sustained CPS number typically coincides with the maximum CPU capacity for a physical or virtual device. Now consider a maximum throughput test. The harness will be configured such that a TCP handshake is established, a client will attempt to reuse this TCP connection with HTTP/1.1 to request an object, a server will respond with a large object (typically >= 128 kB), and the TCP connection will not be torn down until multiple HTTP transactions have occurred. If there are no limitations in physical connectivity, and no hardware assistance, then the maximum sustained throughput typically coincides with the maximum CPU capacity for a physical or virtual device. If both of those tests require all of the available CPU resources, then it is generally impossible to satisfy both conditions at the same time. Therefore, if your workload involves any application level inspection or decisions, then your available CPU resources for L4 connection handling will also be reduced. This table describes the test process for some of the core metrics. The labels and meanings are repeated from the previous table. Label Meaning Methodology CPS connections per second Determine the maximum number of fully functional (establishment, single small transaction, graceful termination) connections that can be established per second. Each transaction is a small object such that it will not result in a full size network frame. TPS / RPS transactions per second / requests per second Determine the maximum number of complete transactions that can be completed over a small number of long-lived connections. Each transaction requests a small object such that it will not result in a full size network frame. bps bits per second Determine the maximum sustained throughput for a workload using long-lived connections and large (128 kB or higher) object sizes. This is often expressed for L4 and L7, and the numbers are typically different. Note that ADC industry metrics use a "single count" method for measuring throughput, such that traffic between the client and server is counted, but not the traffic between the client and ADC or between the ADC and the server. fps frames per second Determine the maximum rate at which network frames can be inspected, routed, or mitigated without unintended drops. This is particularly useful when comparing network defense performance, such as TCP SYN flood mitigation. CC concurrent connections Determine the maximum number of concurrent connections that can be established without forcefully terminating any of the connections. This is typically tested by establishing millions of connections over a long period of time, and leaving them in an established state. The test is valid only if the connections can successfully complete one transaction before a graceful termination. Stability is achieved when the new connection rate matches the connection termination rate due to old connections being satisfied. Example: 10,000 CPS with a 300 second wait time and 1-RPC for a 128 byte object will result in a moving plateau of 3.0M CC. The test should run for a minimum of 300 seconds after the initial connections have been established. These tests take a long time, as there are three phases - establishment (300 seconds), wait and transaction (300 seconds), graceful shutdown (300 seconds). What Does Your Traffic Look Like? I used to have the role of customer-facing performance testing. This means that I would use problem descriptions, sample configurations, and other details and constraints from a sales team to create an approximate test harness in the lab. There were two main goals: help the customer to understand how the device will perform with their given workloads, and help the customer and sales team understand what capacity is required for current and future traffic. However, performance is more dependent upon the actual traffic characteristics than the finer points of tuning a configuration. My questions often focused on what the traffic looks like in the target network environment. Anybody that replied with "it's just IMIX" was wrong; nobody has production traffic that looks like IMIX. Defining the device configuration is relatively simple. A customer would have some defined deployment scenarios, like "client-ssl with HTTP inspection and compression for IPv6 traffic" or "NAT44 with policy enforcement and logging." The sales engineering talent would work with the customer engineering talent to build an acceptable configuration. This defined the harness layout and traffic types. However, real traffic has many applications and protocols running concurrently. Clients and servers may have intermittent packet loss or other issues due to over-subscribed resources. Some users have a three-digit number of mostly idle connections. Some users have two video streams incoming and one outgoing. And so on in that fashion. The real mix of network traffic varies wildly between services, and even between points of presence (PoP) within a single service. Real data is required. Quantifying Your Network Traffic Your existing network infrastructure is a valuable source of information. Statistical data from your switches and routers can tell you interesting things for every network segment in your environment: number of network frames in / out number of bytes in / out IPv4 / IPv6 blend Your firewalls, ADCs, and other advanced infrastructure can provide information regarding client behavior, transport protocols, and applications: connection lifetime average frame size per connection number of bytes in / out per connection transport protocol blend (TCP vs. UDP) geographic distribution of traffic ciphers used and key strength actual compression ratios (bits in from server vs. bits out to client, according to compression device) blend of stream traffic vs. transactional traffic ... and so on in that fashion The trick is collecting all of this data, then asking meaningful questions against it. The full discussion of what you can learn goes far beyond the scope of this article. However, here are a handful of common traffic questions and suggestions for how to determine the answers. Q: How many concurrent TCP connections should I expect? A: Concurrency is the product of the average connection lifetime and the average new connection rate. Example: We have determined that a particular application receives 35,000 new connections per second (CPS). We also determined that the average connection lifetime for this application is 100 seconds. The calculation for typical concurrency is 35,000 TCP conn/s x 100 s. The units cancel out to give us 3.5M TCP connections. Q: What kind of UDP concurrency should I expect? A: This question is strangely common, and typically pointless. UDP is a stateless protocol. If required, source / destination hashing or something in the payload can be used to ensure that the same client goes to the same back end resources. Q: How many users can I handle with 1.0 Gbps? A: This can be determined by looking at the average connection lifetime and average bytes in / out for a typical session. The method is to take the total bytes for an average transaction and divide it by the average connection lifetime. This gives you the amount of data per second. Then you divide the data rate capacity by that number. Example: for a typical user session, our application receives 100 kB and transmits 200 kB. The average session length is 10 seconds. This means that, for a typical session, we are receiving 10 kB/s and transmitting 20 kB/s. We convert this to 80 kbps and 160 kbps (bytes to bits). We use the larger value, in this case transmission back to the client, to determine the maximum session capacity. 1.0 Gbps (capacity) divided by 160 kbps (per-session requirement) gives a value of 6,250 sessions. Q: I calculated the values for one point in time. Is this sufficient? A: Absolutely not! Network traffic, much like commuter traffic, tends to have a daily pattern. You should understand your traffic mix and application behavior for at least two points: peak traffic, average traffic. I recommend automating the analysis, and running it hourly for a week. You will find unexpected trends. If you have historical data, analyze that too so you can project growth rates. Consider how your personal internet habits change throughout the day. At work you have long-lived connections to email and other internal services, probably a music streaming service, maybe an instant message service or three, and a lot of open browser tabs. What about when you get home? Media streaming, maybe internet gaming, possibly a VoIP session, and a lot of open browser tabs. Which usage pattern is more correct for capacity planning? You need data to understand which usage pattern is more resource intensive. Closing I hope that this information allows you to make precise decisions around resource planning and resource allocation. The goal is that your capacity planning should cease to be driven solely by CPU load thresholds for auto-scaling. Instead, you should be actively considering the resource allocation of every component of an application and the supporting infrastructure. Use the knowledge above to explain precisely where resources are misapplied and how to correct it. Go make the world a little more efficient.13KViews4likes2CommentsDeclarative Advanced WAF policy lifecycle in a CI/CD pipeline
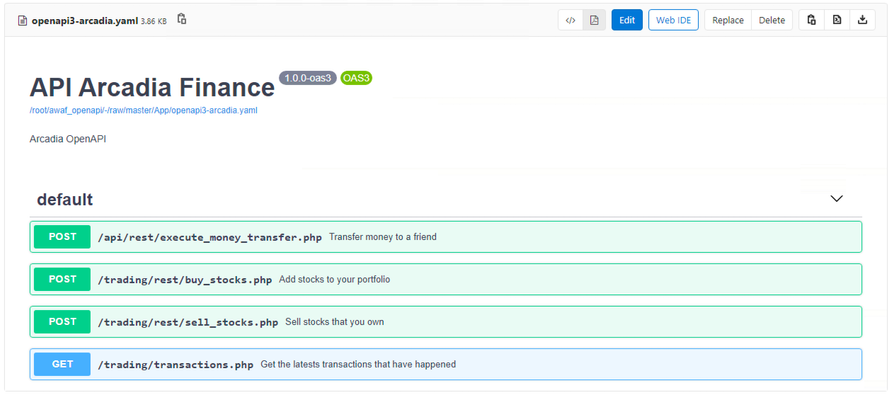
The purpose of this article is to show the configuration used to deploy a declarative Advanced WAF policy to a BIG-IP and automatically configure it to protect an API workload by consuming an OpenAPI file describing the application. For this experiment, a Gitlab CI/CD pipeline was used to deploy an API workload to Kubernetes, configure a declarative Adv. WAF policy to a BIG-IP device and tuning it by incorporating learning suggestions exported from the BIG-IP. Lastly, the F5 WAF tester tool was used to determine and improve the defensive posture of the Adv. WAF policy. Deploying the declarative Advanced WAF policy through a CI/CD pipeline To deploy the Adv. WAF policy, the Gitlab CI/CD pipeline is calling an Ansible playbook that will in turn deploy an AS3 application referencing the Adv.WAF policy from a separate JSON file. This allows the application definition and WAF policy to be managed by 2 different groups, for example NetOps and SecOps, supporting separation of duties. The following Ansible playbook was used; --- - hosts: bigip connection: local gather_facts: false vars: my_admin: "xxxx" my_password: "xxxx" bigip: "xxxx" tasks: - name: Deploy AS3 API AWAF policy uri: url: "https://{{ bigip }}/mgmt/shared/appsvcs/declare" method: POST headers: "Content-Type": "application/json" "Authorization": "Basic xxxxxxxxxx body: "{{ lookup('file','as3_waf_openapi.json') }}" body_format: json validate_certs: no status_code: 200 The Advanced WAF policy 'as3_waf_openapi.json' was specified as follows: { "class": "AS3", "action": "deploy", "persist": true, "declaration": { "class": "ADC", "schemaVersion": "3.2.0", "id": "Prod_API_AS3", "API-Prod": { "class": "Tenant", "defaultRouteDomain": 0, "arcadia": { "class": "Application", "template": "generic", "VS_API": { "class": "Service_HTTPS", "remark": "Accepts HTTPS/TLS connections on port 443", "virtualAddresses": ["xxxxx"], "redirect80": false, "pool": "pool_NGINX_API", "policyWAF": { "use": "Arcadia_WAF_API_policy" }, "securityLogProfiles": [{ "bigip": "/Common/Log all requests" }], "profileTCP": { "egress": "wan", "ingress": { "use": "TCP_Profile" } }, "profileHTTP": { "use": "custom_http_profile" }, "serverTLS": { "bigip": "/Common/arcadia_client_ssl" } }, "Arcadia_WAF_API_policy": { "class": "WAF_Policy", "url": "http://xxxx/root/awaf_openapi/-/raw/master/WAF/ansible/bigip/policy-api.json", "ignoreChanges": true }, "pool_NGINX_API": { "class": "Pool", "monitors": ["http"], "members": [{ "servicePort": 8080, "serverAddresses": ["xxxx"] }] }, "custom_http_profile": { "class": "HTTP_Profile", "xForwardedFor": true }, "TCP_Profile": { "class": "TCP_Profile", "idleTimeout": 60 } } } } } The AS3 declaration will provision a separate Administrative Partition ('API-Prod') containing a Virtual Server ('VS_API'), an Adv. WAF policy ('Arcadia_WAF_API_policy') and a pool ('pool_NGINX_API'). The Adv.WAF policy being referenced ('policy-api.json') is stored in the same Gitlab repository but can be downloaded from a separate location. { "policy": { "name": "policy-api-arcadia", "description": "Arcadia API", "template": { "name": "POLICY_TEMPLATE_API_SECURITY" }, "enforcementMode": "transparent", "server-technologies": [ { "serverTechnologyName": "MySQL" }, { "serverTechnologyName": "Unix/Linux" }, { "serverTechnologyName": "MongoDB" } ], "signature-settings": { "signatureStaging": false }, "policy-builder": { "learnOnlyFromNonBotTraffic": false }, "open-api-files": [ { "link": "http://xxxx/root/awaf_openapi/-/raw/master/App/openapi3-arcadia.yaml" } ] }, "modifications": [ ] } The declarative Adv.WAF policy is referencing in turn the OpenAPI file ('openapi3-arcadia.yaml') that describes the application being protected. Executing the Ansible playbook results in the AS3 application being deployed, along with the Adv.WAF policy that is automatically configured according to the OpenAPI file. Handling learning suggestions in a CI/CD pipeline The next step in the CI/CD pipeline used for this experiment was to send legitimate traffic using the API and collect the learning suggestions generated by the Adv.WAF policy, which will allow a simple way to customize the WAF policy further for the specific application being protected. The following Ansible playbook was used to retrieve the learning suggestions: --- - hosts: bigip connection: local gather_facts: true vars: my_admin: "xxxx" my_password: "xxxx" bigip: "xxxxx" tasks: - name: Get all Policy_key/IDs for WAF policies uri: url: 'https://{{ bigip }}/mgmt/tm/asm/policies?$select=name,id' method: GET headers: "Authorization": "Basic xxxxxxxxxxx" validate_certs: no status_code: 200 return_content: yes register: waf_policies - name: Extract Policy_key/ID of Arcadia_WAF_API_policy set_fact: Arcadia_WAF_API_policy_ID="{{ item.id }}" loop: "{{ (waf_policies.content|from_json)['items'] }}" when: item.name == "Arcadia_WAF_API_policy" - name: Export learning suggestions uri: url: "https://{{ bigip }}/mgmt/tm/asm/tasks/export-suggestions" method: POST headers: "Content-Type": "application/json" "Authorization": "Basic xxxxxxxxxxx" body: "{ \"inline\": \"true\", \"policyReference\": { \"link\": \"https://{{ bigip }}/mgmt/tm/asm/policies/{{ Arcadia_WAF_API_policy_ID }}/\" } }" body_format: json validate_certs: no status_code: - 200 - 201 - 202 - name: Get learning suggestions uri: url: "https://{{ bigip }}/mgmt/tm/asm/tasks/export-suggestions" method: GET headers: "Authorization": "Basic xxxxxxxxx" validate_certs: no status_code: 200 register: result - name: Print learning suggestions debug: var=result A sample learning suggestions output is shown below: "json": { "items": [ { "endTime": "xxxxxxxxxxxxx", "id": "ZQDaRVecGeqHwAW1LDzZTQ", "inline": true, "kind": "tm:asm:tasks:export-suggestions:export-suggestions-taskstate", "lastUpdateMicros": 1599953296000000.0, "result": { "suggestions": [ { "action": "add-or-update", "description": "Enable Evasion Technique", "entity": { "description": "Directory traversals" }, "entityChanges": { "enabled": true }, "entityType": "evasion" }, { "action": "add-or-update", "description": "Enable HTTP Check", "entity": { "description": "Check maximum number of parameters" }, "entityChanges": { "enabled": true }, "entityType": "http-protocol" }, { "action": "add-or-update", "description": "Enable HTTP Check", "entity": { "description": "No Host header in HTTP/1.1 request" }, "entityChanges": { "enabled": true }, "entityType": "http-protocol" }, { "action": "add-or-update", "description": "Enable enforcement of policy violation", "entity": { "name": "VIOL_REQUEST_MAX_LENGTH" }, "entityChanges": { "alarm": true, "block": true }, "entityType": "violation" } Incorporating the learning suggestions in the Adv.WAF policy can be done by simple copy&pasting the self-contained learning suggestions blocks into the "modifications" list of the Adv.WAF policy: { "policy": { "name": "policy-api-arcadia", "description": "Arcadia API", "template": { "name": "POLICY_TEMPLATE_API_SECURITY" }, "enforcementMode": "transparent", "server-technologies": [ { "serverTechnologyName": "MySQL" }, { "serverTechnologyName": "Unix/Linux" }, { "serverTechnologyName": "MongoDB" } ], "signature-settings": { "signatureStaging": false }, "policy-builder": { "learnOnlyFromNonBotTraffic": false }, "open-api-files": [ { "link": "http://xxxxxx/root/awaf_openapi/-/raw/master/App/openapi3-arcadia.yaml" } ] }, "modifications": [ { "action": "add-or-update", "description": "Enable Evasion Technique", "entity": { "description": "Directory traversals" }, "entityChanges": { "enabled": true }, "entityType": "evasion" } ] } Enhancing Advanced WAF policy posture by using the F5 WAF tester The F5 WAF tester is a tool that generates known attacks and checks the response of the WAF policy. For example, running the F5 WAF tester against a policy that has a "transparent" enforcement mode will cause the tests to fail as the attacks will not be blocked. The F5 WAF tester can suggest possible enhancement of the policy, in this case the change of the enforcement mode. An abbreviated sample output of the F5 WAF Tester: ................................................................ "100000023": { "CVE": "", "attack_type": "Server Side Request Forgery", "name": "SSRF attempt (AWS Metadata Server)", "results": { "parameter": { "expected_result": { "type": "signature", "value": "200018040" }, "pass": false, "reason": "ASM Policy is not in blocking mode", "support_id": "" } }, "system": "All systems" }, "100000024": { "CVE": "", "attack_type": "Server Side Request Forgery", "name": "SSRF attempt - Local network IP range 10.x.x.x", "results": { "request": { "expected_result": { "type": "signature", "value": "200020201" }, "pass": false, "reason": "ASM Policy is not in blocking mode", "support_id": "" } }, "system": "All systems" } }, "summary": { "fail": 48, "pass": 0 } Changing the enforcement mode from "transparent" to "blocking" can easily be done by editing the same Adv. WAF policy file: { "policy": { "name": "policy-api-arcadia", "description": "Arcadia API", "template": { "name": "POLICY_TEMPLATE_API_SECURITY" }, "enforcementMode": "blocking", "server-technologies": [ { "serverTechnologyName": "MySQL" }, { "serverTechnologyName": "Unix/Linux" }, { "serverTechnologyName": "MongoDB" } ], "signature-settings": { "signatureStaging": false }, "policy-builder": { "learnOnlyFromNonBotTraffic": false }, "open-api-files": [ { "link": "http://xxxxx/root/awaf_openapi/-/raw/master/App/openapi3-arcadia.yaml" } ] }, "modifications": [ { "action": "add-or-update", "description": "Enable Evasion Technique", "entity": { "description": "Directory traversals" }, "entityChanges": { "enabled": true }, "entityType": "evasion" } ] } A successful run will will be achieved when all the attacks will be blocked. ......................................... "100000023": { "CVE": "", "attack_type": "Server Side Request Forgery", "name": "SSRF attempt (AWS Metadata Server)", "results": { "parameter": { "expected_result": { "type": "signature", "value": "200018040" }, "pass": true, "reason": "", "support_id": "17540898289451273964" } }, "system": "All systems" }, "100000024": { "CVE": "", "attack_type": "Server Side Request Forgery", "name": "SSRF attempt - Local network IP range 10.x.x.x", "results": { "request": { "expected_result": { "type": "signature", "value": "200020201" }, "pass": true, "reason": "", "support_id": "17540898289451274344" } }, "system": "All systems" } }, "summary": { "fail": 0, "pass": 48 } Conclusion By adding the Advanced WAF policy into a CI/CD pipeline, the WAF policy can be integrated in the lifecycle of the application it is protecting, allowing for continuous testing and improvement of the security posture before it is deployed to production. The flexible model of AS3 and declarative Advanced WAF allows the separation of roles and responsibilities between NetOps and SecOps, while providing an easy way for tuning the policy to the specifics of the application being protected. Links UDF lab environment link. Short instructional video link.1.8KViews3likes1CommentAgility 2020 - you're invited!
In-person event for Agility 2020 has been cancelled. Please see the Agility Event Page for more details. (Update 2/28/2020) In an abundance of caution for our customers, partners and employees, we have made the tough decision to cancel our in-person event for Agility 2020 due to the escalating travel and safety concerns related to the global COVID-19 (Coronavirus) outbreak. While we are disappointed to miss sharing ideas and solving problems with customers and partners from around the globe in person, we believe this is the best decision for everyone's welfare. We are rapidly developing an alternative to Agility as a virtual experience in the near term to deliver valuable Lab, Break-out Session, Certification and Keynote content to our customers and partners. Check back regularly for more details on the virtual event or email F5Agility@F5.com for additional information. <Professor Farnsworth imitation>Good news, everybody!</Professor Farnsworth imitation> As you know, there was no Agility 2019. This was in part so that we could reset the time of year for the conference from August to March. Agility 2020will be held from March 16-19, 2020 at theSwan & Dolphinin Orlando, Florida. Orlando, and Disney, and putt-putt golfing... That's right, *puts on ears* we're going to Disneyworld - and you are all cordially invited to participate in labs and breakouts, meet fellow F5 users, talk with F5 and partner subject-matter experts, learn to develop and deploy applications in days instead of months, secure your apps at scale in a multi-cloud environment, and hear about our vision for the future of F5 and NGINX. Registration is now open! The DevCentral team will be busy as usual that week. We areallflying over, and will be: hosting our usual booth and giving out swag in the expo hall, hosting a walk-in Nerdery zone next to our booth, where folks can drop in to speak with one of our subject-matter experts, presenting breakout sessions, hanging out at Geekfest, connecting community, enjoying the exclusive community area at the final night party, and of course, spoiling the dev/central MVPs during the joint 2019-20 MVP Summit at Agility with special sessions and activities. If you'd like to do more than pick up all the knowledge being dropped, if you have some cool technical stories or lessons-learned to share, please stay tuned for the open call for proposals which should go live in early December - so please start getting those great breakout, lightening round, and open talk ideas ready. Hope to see you there!2.4KViews3likes1Comment
Telemetry streaming - One click deploy using Ansible
In this article we will focus on using Ansible to enable and install telemetry streaming (TS) and associated dependencies. Telemetry streaming The F5 BIG-IP is a full proxy architecture, which essentially means that the BIG-IP LTM completely understands the end-to-end connection, enabling it to be an endpoint and originator of client and server side connections. This empowers the BIG-IP to have traffic statistics from the client to the BIG-IP and from the BIG-IP to the server giving the user the entire view of their network statistics. To gain meaningful insight, you must be able to gather your data and statistics (telemetry) into a useful place.Telemetry streaming is an extension designed to declaratively aggregate, normalize, and forward statistics and events from the BIG-IP to a consumer application. You can earn more about telemetry streaming here, but let's get to Ansible. Enable and Install using Ansible The Ansible playbook below performs the following tasks Grab the latest Application Services 3 (AS) and Telemetry Streaming (TS) versions Download the AS3 and TS packages and install them on BIG-IP using a role Deploy AS3 and TS declarations on BIG-IP using a role from Ansible galaxy If AVR logs are needed for TS then provision the BIG-IP AVR module and configure AVR to point to TS Prerequisites Supported on BIG-IP 14.1+ version If AVR is required to be configured make sure there is enough memory for the module to be enabled along with all the other BIG-IP modules that are provisioned in your environment The TS data is being pushed to Azure log analytics (modify it to use your own consumer). If azure logs are being used then change your TS json file with the correct workspace ID and sharedkey Ansible is installed on the host from where the scripts are run Following files are present in the directory Variable file (vars.yml) TS poller and listener setup (ts_poller_and_listener_setup.declaration.json) Declare logging profile (as3_ts_setup_declaration.json) Ansible playbook (ts_workflow.yml) Get started Download the following roles from ansible galaxy. ansible-galaxy install f5devcentral.f5app_services_package --force This role performs a series of steps needed to download and install RPM packages on the BIG-IP that are a part of F5 automation toolchain. Read through the prerequisites for the role before installing it. ansible-galaxy install f5devcentral.atc_deploy --force This role deploys the declaration using the RPM package installed above. Read through the prerequisites for the role before installing it. By default, roles get installed into the /etc/ansible/role directory. Next copy the below contents into a file named vars.yml. Change the variable file to reflect your environment # BIG-IP MGMT address and username/password f5app_services_package_server: "xxx.xxx.xxx.xxx" f5app_services_package_server_port: "443" f5app_services_package_user: "*****" f5app_services_package_password: "*****" f5app_services_package_validate_certs: "false" f5app_services_package_transport: "rest" # URI from where latest RPM version and package will be downloaded ts_uri: "https://github.com/F5Networks/f5-telemetry-streaming/releases" as3_uri: "https://github.com/F5Networks/f5-appsvcs-extension/releases" #If AVR module logs needed then set to 'yes' else leave it as 'no' avr_needed: "no" # Virtual servers in your environment to assign the logging profiles (If AVR set to 'yes') virtual_servers: - "vs1" - "vs2" Next copy the below contents into a file named ts_poller_and_listener_setup.declaration.json. { "class": "Telemetry", "controls": { "class": "Controls", "logLevel": "debug" }, "My_Poller": { "class": "Telemetry_System_Poller", "interval": 60 }, "My_Consumer": { "class": "Telemetry_Consumer", "type": "Azure_Log_Analytics", "workspaceId": "<<workspace-id>>", "passphrase": { "cipherText": "<<sharedkey>>" }, "useManagedIdentity": false, "region": "eastus" } } Next copy the below contents into a file named as3_ts_setup_declaration.json { "class": "ADC", "schemaVersion": "3.10.0", "remark": "Example depicting creation of BIG-IP module log profiles", "Common": { "Shared": { "class": "Application", "template": "shared", "telemetry_local_rule": { "remark": "Only required when TS is a local listener", "class": "iRule", "iRule": "when CLIENT_ACCEPTED {\n node 127.0.0.1 6514\n}" }, "telemetry_local": { "remark": "Only required when TS is a local listener", "class": "Service_TCP", "virtualAddresses": [ "255.255.255.254" ], "virtualPort": 6514, "iRules": [ "telemetry_local_rule" ] }, "telemetry": { "class": "Pool", "members": [ { "enable": true, "serverAddresses": [ "255.255.255.254" ], "servicePort": 6514 } ], "monitors": [ { "bigip": "/Common/tcp" } ] }, "telemetry_hsl": { "class": "Log_Destination", "type": "remote-high-speed-log", "protocol": "tcp", "pool": { "use": "telemetry" } }, "telemetry_formatted": { "class": "Log_Destination", "type": "splunk", "forwardTo": { "use": "telemetry_hsl" } }, "telemetry_publisher": { "class": "Log_Publisher", "destinations": [ { "use": "telemetry_formatted" } ] }, "telemetry_traffic_log_profile": { "class": "Traffic_Log_Profile", "requestSettings": { "requestEnabled": true, "requestProtocol": "mds-tcp", "requestPool": { "use": "telemetry" }, "requestTemplate": "event_source=\"request_logging\",hostname=\"$BIGIP_HOSTNAME\",client_ip=\"$CLIENT_IP\",server_ip=\"$SERVER_IP\",http_method=\"$HTTP_METHOD\",http_uri=\"$HTTP_URI\",virtual_name=\"$VIRTUAL_NAME\",event_timestamp=\"$DATE_HTTP\"" } } } } } NOTE: To better understand the above declarations check out our clouddocs page: https://clouddocs.f5.com/products/extensions/f5-telemetry-streaming/latest/telemetry-system.html Next copy the below contents into a file named ts_workflow.yml - name: Telemetry streaming setup hosts: localhost connection: local any_errors_fatal: true vars_files: vars.yml tasks: - name: Get latest AS3 RPM name action: shell wget -O - {{as3_uri}} | grep -E rpm | head -1 | cut -d "/" -f 7 | cut -d "=" -f 1 | cut -d "\"" -f 1 register: as3_output - debug: var: as3_output.stdout_lines[0] - set_fact: as3_release: "{{as3_output.stdout_lines[0]}}" - name: Get latest AS3 RPM tag action: shell wget -O - {{as3_uri}} | grep -E rpm | head -1 | cut -d "/" -f 6 register: as3_output - debug: var: as3_output.stdout_lines[0] - set_fact: as3_release_tag: "{{as3_output.stdout_lines[0]}}" - name: Get latest TS RPM name action: shell wget -O - {{ts_uri}} | grep -E rpm | head -1 | cut -d "/" -f 7 | cut -d "=" -f 1 | cut -d "\"" -f 1 register: ts_output - debug: var: ts_output.stdout_lines[0] - set_fact: ts_release: "{{ts_output.stdout_lines[0]}}" - name: Get latest TS RPM tag action: shell wget -O - {{ts_uri}} | grep -E rpm | head -1 | cut -d "/" -f 6 register: ts_output - debug: var: ts_output.stdout_lines[0] - set_fact: ts_release_tag: "{{ts_output.stdout_lines[0]}}" - name: Download and Install AS3 and TS RPM ackages to BIG-IP using role include_role: name: f5devcentral.f5app_services_package vars: f5app_services_package_url: "{{item.uri}}/download/{{item.release_tag}}/{{item.release}}?raw=true" f5app_services_package_path: "/tmp/{{item.release}}" loop: - {uri: "{{as3_uri}}", release_tag: "{{as3_release_tag}}", release: "{{as3_release}}"} - {uri: "{{ts_uri}}", release_tag: "{{ts_release_tag}}", release: "{{ts_release}}"} - name: Deploy AS3 and TS declaration on the BIG-IP using role include_role: name: f5devcentral.atc_deploy vars: atc_method: POST atc_declaration: "{{ lookup('template', item.file) }}" atc_delay: 10 atc_retries: 15 atc_service: "{{item.service}}" provider: server: "{{ f5app_services_package_server }}" server_port: "{{ f5app_services_package_server_port }}" user: "{{ f5app_services_package_user }}" password: "{{ f5app_services_package_password }}" validate_certs: "{{ f5app_services_package_validate_certs | default(no) }}" transport: "{{ f5app_services_package_transport }}" loop: - {service: "AS3", file: "as3_ts_setup_declaration.json"} - {service: "Telemetry", file: "ts_poller_and_listener_setup_declaration.json"} #If AVR logs need to be enabled - name: Provision BIG-IP with AVR bigip_provision: provider: server: "{{ f5app_services_package_server }}" server_port: "{{ f5app_services_package_server_port }}" user: "{{ f5app_services_package_user }}" password: "{{ f5app_services_package_password }}" validate_certs: "{{ f5app_services_package_validate_certs | default(no) }}" transport: "{{ f5app_services_package_transport }}" module: "avr" level: "nominal" when: avr_needed == "yes" - name: Enable AVR logs using tmsh commands bigip_command: commands: - modify analytics global-settings { offbox-protocol tcp offbox-tcp-addresses add { 127.0.0.1 } offbox-tcp-port 6514 use-offbox enabled } - create ltm profile analytics telemetry-http-analytics { collect-geo enabled collect-http-timing-metrics enabled collect-ip enabled collect-max-tps-and-throughput enabled collect-methods enabled collect-page-load-time enabled collect-response-codes enabled collect-subnets enabled collect-url enabled collect-user-agent enabled collect-user-sessions enabled publish-irule-statistics enabled } - create ltm profile tcp-analytics telemetry-tcp-analytics { collect-city enabled collect-continent enabled collect-country enabled collect-nexthop enabled collect-post-code enabled collect-region enabled collect-remote-host-ip enabled collect-remote-host-subnet enabled collected-by-server-side enabled } provider: server: "{{ f5app_services_package_server }}" server_port: "{{ f5app_services_package_server_port }}" user: "{{ f5app_services_package_user }}" password: "{{ f5app_services_package_password }}" validate_certs: "{{ f5app_services_package_validate_certs | default(no) }}" transport: "{{ f5app_services_package_transport }}" when: avr_needed == "yes" - name: Assign TCP and HTTP profiles to virtual servers bigip_virtual_server: provider: server: "{{ f5app_services_package_server }}" server_port: "{{ f5app_services_package_server_port }}" user: "{{ f5app_services_package_user }}" password: "{{ f5app_services_package_password }}" validate_certs: "{{ f5app_services_package_validate_certs | default(no) }}" transport: "{{ f5app_services_package_transport }}" name: "{{item}}" profiles: - http - telemetry-http-analytics - telemetry-tcp-analytics loop: "{{virtual_servers}}" when: avr_needed == "yes" Now execute the playbook: ansible-playbook ts_workflow.yml Verify Login to the BIG-IP UI Go to menu iApps->Package Management LX. Both the f5-telemetry and f5-appsvs RPM's should be present Login to BIG-IP CLI Check restjavad logs present at /var/log for any TS errors Login to your consumer where the logs are being sent to and make sure the consumer is receiving the logs Conclusion The Telemetry Streaming (TS) extension is very powerful and is capable of sending much more information than described above. Take a look at the complete list of logs as well as consumer applications supported by TS over on CloudDocs: https://clouddocs.f5.com/products/extensions/f5-telemetry-streaming/latest/using-ts.html615Views3likes0CommentsF5 and Cisco ACI Essentials - Design guide for a Single Pod APIC cluster
Deployment considerations It is usually an easy decision to have BIG-IP as part of your ACI deployment as BIG-IP is a mature feature rich ADC solution. Where time is spent is nailing down the design and the deployment options for the BIG-IP in the environment. Below we will discuss a few of the most commonly asked questions: SNAT or no SNAT There are various options you can use to insert the BIG-IP into the ACI environment. One way is to use the BIG-IP as a gateway for servers or as a routing next hop for routing instances. Another option is to use Source Network Address Translation (SNAT) on the BIG-IP, however with enabling SNAT the visibility into the real source IP address is lost. If preserving the source IP is a requirement then ACI's Policy-Based Redirect (PBR) can be used to make sure the return traffic goes back to the BIG-IP. BIG-IP redundancy F5 BIG-IP can be deployed in different high-availability modes. The two common BIG-IP deployment modes: active-active and active-standby. Various design considerations, such as endpoint movement during fail-overs, MAC masquerade, source MAC-based forwarding, Link Layer Discovery Protocol (LLDP), and IP aging should also be taken into account for each of the deployment modes. Multi-tenancy Multi-tenancy is supported by both Cisco ACI and F5 BIG-IP in different ways. There are a few ways that multi-tenancy constructs on ACI can be mapped to multi-tenancy on BIG-IP. The constructs revolve around tenants, virtual routing and forwarding (VRF), route domains, and partitions. Multi-tenancy can also be based on the BIG-IP form factor (appliance, virtual edition and/or virtual clustered multiprocessor (vCMP)). Tighter integration Once a design option is selected there are questions around what more can be done from an operational or automation perspective now that we have a BIG-IP and ACI deployment? The F5 ACI ServiceCenter is an application developed on the Cisco ACI App Center platform built for exactly that purpose. It is an integration point between the F5 BIG-IP and Cisco ACI. The application provides an APIC administrator a unified way to manage both L2-L3 and L4-L7 infrastructure. Once day-0 activities are performed and BIG-IP is deployed within the ACI fabric using any of the design options selected for your environment, then the F5 ACI ServiceCenter can be used to handle day-1 and day-2 operations. The day-1 and day-2 operations provided by the application are well suited for both new/greenfield and existing/brownfield deployments of BIG-IP and ACI deployments. The integration is loosely coupled, which allows the F5 ACI ServiceCenter to be installed or uninstalled with no disruption to traffic flow, as well as no effect on the F5 BIG-IP and Cisco ACI configuration. Check here to find out more. All of the above topics and more are discussed in detail here in the single pod white paper.1.6KViews3likes0CommentsGo in Plain English: Setting things up and Hello World!
Related Articles: Go In Plain English: Playing with Strings Go In Plain English: Creating your First WebServer Quick Intro I like to keep things short so just do what I do here and you will pick things up. In this article we'll cover the following: Installation (1 liner) Hello world! The directory structure of Go BONUS! VS Code for Golang Installation →https://golang.org/doc/install Note:If you never programmed in Go, please go straight to the bonus section, install VS Code and come back here! Hello World! At the moment just keep in mind that you'll typically see package, import and func in a Go program. If you're just getting started then this is not the time to go really in-depth but package main signals go that our piece of code is an executable. The import statement is where you tell go which additional package you'd like to import. In this case, we're importing fmt package (the one that has the Printf method). Lastly, func main() is where you're going to add your code to, i.e. the entry point of our program. Running your Go code! You can pick a folder of your choice to run your Go apps. In my case I picked /Users/albuquerque/Documents/go-apps/ directory here: Inside of it, you create a src directory to keep your *.go source code inside: go run When you type go run you're telling Go that you don't care about executable (for now) so go compiles your code, keeps executable into a temporary directory and runs it for you. go build When you type go build, Go compiles the executable and saves it to your current directory: go install There is a variable called $GOPATH where we tell Go where to look for source files. Let's set it to our go-apps directory: When we type go install, Go creates a bin directory to keep the executable: go doc In case you want to know what a particular command does, just use go doc command: BONUS! VS Code for Golang The program I use to code in Go and Python is VS Code: It has autocompletion and roughly all you expect from a proper code editor. You can download it from here:https://code.visualstudio.com/download You can choose themes too:767Views3likes5Commentsimport f5!
We are super excited to announce a preview of the F5 SDK, a set of client tools which facilitate consuming some of our popular APIs/Services, and currently consists of the following: f5-sdk-python - a new python client library f5-cli - a remote CLI that is built-off the f5-sdk-python Getting existential, as the old saying goes, the most valuable commodity in the world is time. Our short time here on earth is finite, the average lifespan is only around 70-71 years (according to Wikipedia), and if we’re not doing everything we can to try to save you every sliver of time possible, we’re not doing one of our fiduciary duties as a technology company. As software developers know, code is the ultimate embodiment of saving time (after all, a “for loop” is nothing but a modern marvel that repeats something dutifully to save time). So, as a convenience to developers and system integrators, vendors / platforms provide Software Development Kits (SDKs) to help them save even more time on that last mile. Developers/Integrators also hate having to re-invent the wheel (which often translates to code “not related” to their business logic) and look to leverage something that already exists. In hardware, you may leverage drivers. In software, you import libraries/modules. In this case, these SDK client libraries provide objects in their own language to help abstract you from low level implementation details like having to know the service’s exact URLs, authentication mechanisms, transport required (ex. REST, SOAP, GRPC), file download/uploads, etc. and let you focus on your business logic.Here at F5, we rely on SDKs like the Broadcom SDK, Octeon SDK, Intel DPDK (for hardware), Cloud SDKs (for software), etc. and the age-old value of offering an SDK hasn’t gone anywhere. SDKs are getting released and making headlines every day. ex. https://www.engadget.com/2020/01/24/boston-dynamics-robotic-dog-spot-sdk/ We’ve actually had an unofficial SDK for a while with a project called the f5-common-python. It was a “common” library for the core underlying component in one our integrations (LBaaS driver for Openstack) but, when looking at it from a more current end-user’s perspective, there were some significant enough changes we wanted to implement that mandated a fresh start. Nevertheless, it gathered a fair amount of traction and the value of a generic reusable client library was a great pattern we wanted to officially expand upon. And now what’s this CLI?I thought it was all about the API now and clients didn't matter? Yes, the main value is obviously in the API itself since that is what scales and where you deliver your main value proposition. However, there is still a client user experience (UX) to your APIs and doing everything you can to optimize / enhance the overall client experience is key to firing on all cylinders. SDKs/CLIs are like the client browser UX to your service … but for programmatic access and automation. From articles like below, you can see some of the traditional values of having a CLI component. https://www.zdnet.com/article/good-news-for-developers-the-cli-is-back/ "CLI is arguably better for ad hoc tasksorquick exploratory operations since it is more human-readable." Source: https://nordicapis.com/the-return-of-the-cli-clis-being-used-by-api-related-companies/ The familiar CLI UX is a common entry point for everyone, whether it is developers testing/exploring your API or network/system admins automating common tasks. And don’t you already have a CLI called TMSH? Well, this is a little different. Everyone today knows how useful *remote* CLIs like AWS’s aws-cli, Azure’s az, Google's gcloud, Openstack’s osc, Kubernete’s kubectl, etc. are in consuming and developing against a service or platform. Instead of SSH’ing to a single device, remote CLIs use transports/protocols like HTTP or GRPC to talk to a service’s remote APIs. The f5-cli, inspired by popular public cloud shells (which are all built on python SDKs) will focus on providing the same ease and convenience to some our most popular APIs/Services and aims to be demand/use case driven (high usage APIs vs. exposing the entire portfolio of APIs). For example, the Automation Tool Chain APIs. For some of you that may have not heard about them yet, those are some of the powerful declarative APIs that allow you to provision entire configurations in a single API call / JSON payload. Application Services 3 (AS3) = Virtual Services Declarative Onboarding (DO) = System related config like licensing, provisioning, networking,clustering, etc. Telemetry Streaming (TS) – Analytics, Logging That would normally require 10s to 100s of imperative API calls.As with any API(s), however, there is some amount of overhead (authentication, async transaction handling, best practices, etc.) in consuming them that can be optimized and captured via client libraries. Probably the most common use case: "I want to create a Virtual Service" (using AS3). Putting the CLI in debug, you can see some of the low level details the SDK is handling: Managing Authentication (dependencies on other APIs) Managing Tasks for Async Operations Retry Attempt logic Even convenience functions like installing the required extension package (an RPM) if not already installed > export F5_SDK_LOG_LEVEL=DEBUG > f5 bigip extension service create --component as3 --install-component --declaration as3.json user1@desktop: f5-cli $ f5 bigip extension service create --component as3 --declaration as3.json --install-component 2020-03-10 00:17:49,779 - f5sdk.bigip.mgmt_client - DEBUG: Performing ready check using port 8443 2020-03-10 00:17:49,810 - f5sdk.bigip.mgmt_client - DEBUG: Logging in using user + password 2020-03-10 00:17:49,810 - f5sdk.bigip.mgmt_client - DEBUG: Getting authentication token 2020-03-10 00:17:49,814 - f5sdk.utils.http_utils - DEBUG: Making HTTP request: POST /mgmt/shared/authn/login 2020-03-10 00:17:50,009 - f5sdk.utils.http_utils - DEBUG: HTTP response: 200 OK 2020-03-10 00:17:50,010 - f5sdk.utils.http_utils - DEBUG: Making HTTP request: PATCH /mgmt/shared/authz/tokens/EEPEH4IXVKX7TVP27NECH76VQJ 2020-03-10 00:17:50,131 - f5sdk.utils.http_utils - DEBUG: HTTP response: 200 OK 2020-03-10 00:17:50,134 - f5sdk.utils.http_utils - DEBUG: Making HTTP request: POST /mgmt/shared/iapp/package-management-tasks 2020-03-10 00:17:50,252 - f5sdk.utils.http_utils - DEBUG: HTTP response: 202 Accepted 2020-03-10 00:17:50,253 - f5sdk.utils.http_utils - DEBUG: Making HTTP request: GET /mgmt/shared/iapp/package-management-tasks/11fc9258-a2c2-495b-8687-2e427fd64091 2020-03-10 00:17:50,363 - f5sdk.utils.http_utils - DEBUG: HTTP response: 200 OK 2020-03-10 00:17:59,798 - f5sdk.utils.http_utils - DEBUG: Making HTTP request: POST /mgmt/shared/file-transfer/uploads/f5-appsvcs-3.17.1-1.noarch.rpm 2020-03-10 00:18:01,605 - f5sdk.utils.http_utils - DEBUG: HTTP response: 200 OK 2020-03-10 00:18:01,608 - f5sdk.utils.http_utils - DEBUG: Making HTTP request: POST /mgmt/shared/file-transfer/uploads/f5-appsvcs-3.17.1-1.noarch.rpm 2020-03-10 00:18:03,814 - f5sdk.utils.http_utils - DEBUG: HTTP response: 200 OK 2020-03-10 00:18:03,815 - f5sdk.utils.http_utils - DEBUG: Making HTTP request: POST /mgmt/shared/file-transfer/uploads/f5-appsvcs-3.17.1-1.noarch.rpm 2020-03-10 00:18:05,678 - f5sdk.utils.http_utils - DEBUG: HTTP response: 200 OK 2020-03-10 00:18:05,680 - f5sdk.utils.http_utils - DEBUG: Making HTTP request: POST /mgmt/shared/file-transfer/uploads/f5-appsvcs-3.17.1-1.noarch.rpm 2020-03-10 00:18:07,905 - f5sdk.utils.http_utils - DEBUG: HTTP response: 200 OK 2020-03-10 00:18:07,908 - f5sdk.utils.http_utils - DEBUG: Making HTTP request: POST /mgmt/shared/file-transfer/uploads/f5-appsvcs-3.17.1-1.noarch.rpm 2020-03-10 00:18:09,642 - f5sdk.utils.http_utils - DEBUG: HTTP response: 200 OK 2020-03-10 00:18:09,644 - f5sdk.utils.http_utils - DEBUG: Making HTTP request: POST /mgmt/shared/file-transfer/uploads/f5-appsvcs-3.17.1-1.noarch.rpm 2020-03-10 00:18:11,707 - f5sdk.utils.http_utils - DEBUG: HTTP response: 200 OK 2020-03-10 00:18:11,709 - f5sdk.utils.http_utils - DEBUG: Making HTTP request: POST /mgmt/shared/file-transfer/uploads/f5-appsvcs-3.17.1-1.noarch.rpm 2020-03-10 00:18:13,915 - f5sdk.utils.http_utils - DEBUG: HTTP response: 200 OK 2020-03-10 00:18:13,918 - f5sdk.utils.http_utils - DEBUG: Making HTTP request: POST /mgmt/shared/file-transfer/uploads/f5-appsvcs-3.17.1-1.noarch.rpm 2020-03-10 00:18:16,050 - f5sdk.utils.http_utils - DEBUG: HTTP response: 200 OK 2020-03-10 00:18:16,052 - f5sdk.utils.http_utils - DEBUG: Making HTTP request: POST /mgmt/shared/file-transfer/uploads/f5-appsvcs-3.17.1-1.noarch.rpm 2020-03-10 00:18:18,042 - f5sdk.utils.http_utils - DEBUG: HTTP response: 200 OK 2020-03-10 00:18:18,044 - f5sdk.utils.http_utils - DEBUG: Making HTTP request: POST /mgmt/shared/file-transfer/uploads/f5-appsvcs-3.17.1-1.noarch.rpm 2020-03-10 00:18:20,623 - f5sdk.utils.http_utils - DEBUG: HTTP response: 200 OK 2020-03-10 00:18:20,625 - f5sdk.utils.http_utils - DEBUG: Making HTTP request: POST /mgmt/shared/file-transfer/uploads/f5-appsvcs-3.17.1-1.noarch.rpm 2020-03-10 00:18:22,823 - f5sdk.utils.http_utils - DEBUG: HTTP response: 200 OK 2020-03-10 00:18:22,826 - f5sdk.utils.http_utils - DEBUG: Making HTTP request: POST /mgmt/shared/file-transfer/uploads/f5-appsvcs-3.17.1-1.noarch.rpm 2020-03-10 00:18:24,864 - f5sdk.utils.http_utils - DEBUG: HTTP response: 200 OK 2020-03-10 00:18:24,866 - f5sdk.utils.http_utils - DEBUG: Making HTTP request: POST /mgmt/shared/file-transfer/uploads/f5-appsvcs-3.17.1-1.noarch.rpm 2020-03-10 00:18:26,624 - f5sdk.utils.http_utils - DEBUG: HTTP response: 200 OK 2020-03-10 00:18:26,625 - f5sdk.utils.http_utils - DEBUG: Making HTTP request: POST /mgmt/shared/file-transfer/uploads/f5-appsvcs-3.17.1-1.noarch.rpm 2020-03-10 00:18:28,922 - f5sdk.utils.http_utils - DEBUG: HTTP response: 200 OK 2020-03-10 00:18:28,924 - f5sdk.utils.http_utils - DEBUG: Making HTTP request: POST /mgmt/shared/file-transfer/uploads/f5-appsvcs-3.17.1-1.noarch.rpm 2020-03-10 00:18:31,068 - f5sdk.utils.http_utils - DEBUG: HTTP response: 200 OK 2020-03-10 00:18:31,070 - f5sdk.utils.http_utils - DEBUG: Making HTTP request: POST /mgmt/shared/file-transfer/uploads/f5-appsvcs-3.17.1-1.noarch.rpm 2020-03-10 00:18:31,503 - f5sdk.utils.http_utils - DEBUG: HTTP response: 200 OK 2020-03-10 00:18:31,508 - f5sdk.utils.http_utils - DEBUG: Making HTTP request: POST /mgmt/shared/iapp/package-management-tasks 2020-03-10 00:18:32,618 - f5sdk.utils.http_utils - DEBUG: HTTP response: 202 Accepted 2020-03-10 00:18:32,618 - f5sdk.utils.http_utils - DEBUG: Making HTTP request: GET /mgmt/shared/iapp/package-management-tasks/a7c839c3-b340-4497-a520-437a237aef30 2020-03-10 00:18:32,727 - f5sdk.utils.http_utils - DEBUG: HTTP response: 200 OK 2020-03-10 00:18:33,733 - f5sdk.utils.http_utils - DEBUG: Making HTTP request: GET /mgmt/shared/iapp/package-management-tasks/a7c839c3-b340-4497-a520-437a237aef30 2020-03-10 00:18:33,865 - f5sdk.utils.http_utils - DEBUG: HTTP response: 200 OK 2020-03-10 00:18:33,866 - f5sdk.utils.http_utils - DEBUG: Making HTTP request: GET /mgmt/shared/appsvcs/declare 2020-03-10 00:18:37,066 - f5sdk.utils.http_utils - DEBUG: Making HTTP request: GET /mgmt/shared/appsvcs/declare 2020-03-10 00:18:37,877 - f5sdk.utils.http_utils - DEBUG: Making HTTP request: POST /mgmt/shared/iapp/package-management-tasks 2020-03-10 00:18:37,998 - f5sdk.utils.http_utils - DEBUG: HTTP response: 202 Accepted 2020-03-10 00:18:37,999 - f5sdk.utils.http_utils - DEBUG: Making HTTP request: GET /mgmt/shared/iapp/package-management-tasks/093dfa5a-eb52-4002-a3d8-88d3edf4ad71 2020-03-10 00:18:38,116 - f5sdk.utils.http_utils - DEBUG: HTTP response: 200 OK 2020-03-10 00:18:38,125 - f5sdk.utils.http_utils - DEBUG: Making HTTP request: POST /mgmt/shared/appsvcs/declare 2020-03-10 00:18:56,120 - f5sdk.utils.http_utils - DEBUG: HTTP response: 200 OK { "declaration": { "Sample_app_sec_Tenant": { "HTTPS_Service": { "Pool1": { "class": "Pool", "members": [ { "serverAddresses": [ "10.0.1.11" ], "servicePort": 80 } ], "monitors": [ "http" ] }, "WAFPolicy": { "class": "WAF_Policy", "ignoreChanges": true, "url": "https://raw.githubusercontent.com/f5devcentral/f5-asm-policy-templates/master/owasp_ready_template/owasp-no-auto-tune-v1.1.xml" }, "class": "Application", "serviceMain": { "class": "Service_HTTPS", "policyWAF": { "use": "WAFPolicy" }, "pool": "Pool1", "redirect80": false, "serverTLS": { "bigip": "/Common/clientssl" }, "snat": "auto", "virtualAddresses": [ "0.0.0.0" ] }, "template": "https" }, "class": "Tenant" }, "class": "ADC", "controls": { "archiveTimestamp": "2020-03-10T00:18:55.759Z" }, "id": "autogen_3a78cbd8-7aa4-4fb6-8db9-3e458f583513", "label": "ASM_VS1", "remark": "ASM_VS1", "schemaVersion": "3.0.0", "updateMode": "selective" }, "results": [ { "code": 200, "host": "localhost", "lineCount": 28, "message": "success", "runTime": 16658, "tenant": "Sample_app_sec_Tenant" } ] } That’s actually quite a bit of work offloaded to accelerate getting you up and going on an API. As our portfolio expands to offer more and more products and services, this will hopefully save our users some extra time. DISCLAIMER:it’s in public preview and we have many enhancements already planned F5 SDK Documentation: https://clouddocs.f5.com/sdk/f5-sdk-python/ Github repo: https://github.com/f5devcentral/f5-sdk-python F5 CLI Documentation: https://clouddocs.f5.com/sdk/f5-cli/ Github repo: https://github.com/f5devcentral/f5-cli Please take look soon and provide any feedback by filing an issue on Github repos.717Views3likes1Comment