Maximizing Scalability with F5 CIS: Blue-Green Deployment on OpenShift
The following video tutorials and Github repo will help you learn how F5 Container Ingress Services (CIS) can integrate with Red Hat Advanced Cluster Management (ACM) to maximize scalability and provide a per-application blue-green strategy in an OpenShift multi-cluster environment. In this 20 Minute demo you will get a detailed understanding of: Redhat ACM running in a management cluster fetching KubeConfigs from the ConfigMap for worker clusters (Coffee Pod & Tea Pod) F5 CIS subscribing to KubeConfig and listening for events from worker clusters (Coffee Pod & Tea Pod) F5 CIS posting AS3 declaration to BIG-IP. BIG-IP executing all necessary commands to achieve desired end state (ie increase cluster resources to 6 instances per pod) Demo on YouTubevideo GitHub Reporepo Notes If you want to make sure the service doesn’t take any share of the overall traffic distribution, set the Route base service weight to “0”. Although the pool for the base service gets created (without any pool members for this case), the traffic is distributed among the extended services only. One more point to note is that in the extendedConfigmap mode is set to “ratio”. This is because currently CIS processes the weights only in two cases The route is an A/B route mode is set to ratio However, the cluster ratio doesn't play any role here as we have not defined any cluster ratio values for any of the clusters. So, each cluster will have equal weightage. Therefore, in this case, traffic distribution will be solely based on service weights. (which is the requirement for this case)99Views1like0CommentsF5 BIG-IP deployment with OpenShift - per-application 2-tier deployments
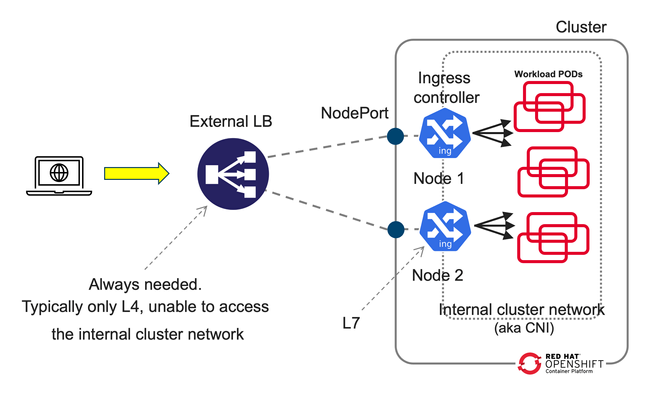
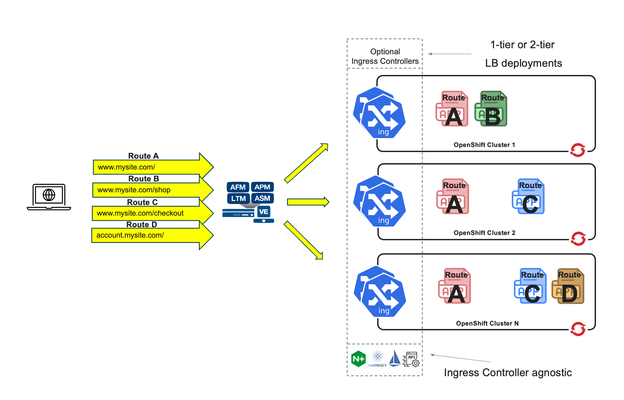
Introduction This article dives deeper in 2-tier deployments introduced in the previous article F5 BIG-IP deployment with OpenShift - platform and networking options yet we will start comparing a common Kubernetes/OpenShift architecture with a more capable and flexible architecture using BIG-IP. Although this type of deployment can be done with the BIG-IP in Layer 4 (L4) mode this article will focus in using the BIG-IP in Layer 7 (L7) mode which allows for more functionality and flexibility. A regular Kubernetes/OpenShift deployment is as follows: Typically, the External LB doesn´t add much added value and just spreads the connections across the ingress controller instances without any service intelligence. This article emphasizes on the added value of F5 BIG-IP with Container Ingress Services (CIS) by operating at L7. Additionally, it is described how CIS is ingress agnostic and can be used at is fullest regardless of the ingress controller, API manager, service mesh used, or even a combination of these! This 2-tier architecture can be seen next, where it is not only shown that traffic is sent directly to the ingress controllers without the NodePort indirection. In the figure, it can also be seen compared to a 1-tier architecture: ClusterIP and NodePort When using a 2-tier deployment, a key aspect that needs to be decided is how it is going to be sent the traffic to the ingress controllers. NodePort With other External LB solutions (ELB), the common way to send traffic to the ingress controllers in Kubernetes is by exposing these as NodePort. This option always works because the ELB doesn't need to deal with the CNI. In this case, when the ELB sends traffic to a node, the NodePort construct by default load balances the traffic to any node in the cluster where the ingress controller is. This means that there would be 3 hops before reaching the workload POD. These hops are: the ELB, the ingress controller, the NodePort, and finally the workload POD. This NodePort load balancing to other nodes can be removed by changing the externalTrafficPolicy from Cluster to Local in the Service definition. Thus reducing the number of hops from 3 to 2. ClusterIP Alternatively, the BIG-IP can send the traffic directly to the POD addresses, aka ClusterIP mode, without any translation or Kubernetes construct in between the BIG-IP and the ingress controller. This is specified in CIS with the --pool-member-type=cluster option and requires support of the CNI. Using OpenShiftSDN and ClusterIP is discouraged because this CNI is being deprecated and will not be covered in this article. When using OVNKubernetes, the BIG-IP sends the traffic without any tunnelling. At this moment, this requires that the clusters are in the same subnet as the BIG-IP. Which option to choose? If the OpenShift cluster is not in the same subnet as the BIG-IP or if the infrastructure doesn´t allow POD addresses traverse the segment (ie: because of a L2 firewall/micro-segmentation), then NodePort would need to be used. I would discourage the use of NodePort with externalTrafficPolicy: Cluster because it doesn´t allow to do adequate health check monitoring because each probe will be sent to a different ingress controller. Moreover, persistence and troubleshooting is more tricky too because of the additional hop that NodePort creates. If NodePort needs to be used, then externalTrafficPolicy: Local referencing the ingress controllers is recommended. If there is no problem in routing the traffic to the OpenShift nodes using the POD addresses, I would encourage using ClusterIP because it is a transparent method, where the application traffic is easier to track: there are no additional hops or address translations. OpenShift´s bundled ingress/router is HA-proxy; In on-prem OpenShift deployments, the default router instance is created using hostNetwork access. HostNetwork can also be used with CIS --pool-member-type=cluster mode. The IP addresses of the pool members will be the node addresses, but there will not be any indirection to the POD. The examples provided in the git repository mentioned in this article use ClusterIP but can be easily modified to NodePort if necessary. 2-tier per-service load balancing and health checking This type of deployment requires that the external load balancer, in this case the F5 BIG-IP, can take actions based on the L7 route path. This includes health-checking the application and performing TLS/SSL termination. From a Kubernetes/OpenShift point of view, the most remarkable is that it is needed to expose the L7 routes twice. That is, for a given L7 route there will be a manifest for the ingress controller and another L7 route manifest for CIS. This is outlined in the next figure: In the above figure, there is only one ingress controller instance with several replicas serving the same L7 routes. It is not relevant which ingress controller it is. This ingress controller can have defined its L7 routes with any resource type. This is transparent from the point of view of CIS. CIS only requires that the ingress controller can be referenced with a selector from a Service. This service is shown in brown. There will be a Service manifest for each L7 route for CIS. Even if all these services point to the same ingress controller instances. This allows you to: Monitor each L7 route´s backends individually. Have a clean NetOps/DevOps separation where DevOps can manipulate the ingress controller configurations freely and NetOps can control the publishing of these in the ELB. Ultimately make load-balancing decisions in a per-application basis The L7 routes for CIS can be defined either as VirtualServer, Route (as NextGen Route) or as Ingress resource types. Using the Ingress resource type is not recommended because of its limited functionalities compared with the other types. Overall, there will be a 1:1:1 mapping between the L7 routes defined for CIS, the Service manifests referenced by CIS´ L7 routes, and the L7 routes defined for the ingress controller. This is shown conceptually in the next figure. With respect to load balancing algorithm, given that the number of ingress controllers in a two-tier deployment is typically small it is sensible to take into account the load of each ingress controller by using an algorithm such as least-connections, least-sessions (if using persistence) or fastest (application response time) which should send more traffic to the ingress controller which is performing better or in other words, would avoid sending more traffic to an ingress controller that is not performing well. Unify all ingresses in a single VIP Thanks to CIS being ingress controller agnostic, it is also possible to combine L7 routes from different ingress controllers, these can be a mix of one or more ingress controllers, including service mesh ingress or API managers. This brings the flexibility of exposing L7 routes from these sources in a single VIP, as shown in the next figure. From the picture above, it can be seen how in this arrangement the ingress controllers are not limited to a single L7 route. Also note that as mentioned previously, it is needed to have a 1:1 mapping between the L7 routes defined in the BIG-IP (1st tier) and in the in-cluster ingress element (2nd tier). By default, these paired L7 routes are expected to match their URL. If necessary, it is possible to do URL translation by using the hostRewrite and rewrite attributes in the VirtualServer CR. OpenShift´s documentation mentions several use cases for creating additional OpenShift router (HA-proxy) instances, referred to as route sharding. These are: Balance Ingress Controllers, or routers, with several routes to speed up responses to changes. Allocate certain routes to have different reliability guarantees than other routes. Allow certain Ingress Controllers to have different policies defined. Allow only specific routes to use additional features. Expose different routes on different addresses so that internal and external users can see different routes, for example. Transfer traffic from one version of an application to another during a blue-green deployment. An additional use case is to isolate the control-plane Routes of the cluster and the application Routes in independent HA-proxy instances. This way it is not only it can be guaranteed different levels of reliability but also guaranteeing resource allocation for the cluster´s own traffic. In the section "Using additional Router instances" section below, it is shown how to do these configurations. Monitoring in a 2-tier deployment For each L7 route, regardless of the resource type used (Ingress, Route or VirtualServer), these share the same schema for monitoring. Next are shown the relevant parameters, where send is the key parameter that specifies L7 route: monitor: type: http send: "GET / HTTP/1.1\r\nHost: www.twotier.com\r\nConnection: close\r\n\r\n" recv: "^HTTP/1.1 200" In many cases, https will be used instead. HA-proxy requires that the health monitor uses TLS 1.2. By default, the https monitor defaults to TLS 1.0, hence we will need to specify one of the BIG-IP default TLS profiles as shown next: monitor: type: https send: "GET / HTTP/1.1\r\nHost: www.twotier.com\r\nConnection: close\r\n\r\n" recv: "^HTTP/1.1 200" sslProfile: /Common/serverssl When using NGINX or Istio ingress gateway, using TLS SNI (Server Name Indication) is requierd. In cases where SNI is required, the following needs to be done: One time, in TMM monitoring needs to be enabled as indicated in https://my.f5.com/manage/s/article/K85210713 For each FQDN it is needed to pre-create a server-side TLS profile in the partition /Common specifying the server name used as TLS SNI. The resulting monitor section will typically look as follows: monitor: type: https send: "GET / HTTP/1.1\r\nHost: www.twotier.com\r\nConnection: close\r\n\r\n" recv: "^HTTP/1.1 200" sslProfile: /Common/serverssl-www.twotier.com Note that this TLS profile is only needed for the monitoring, for application´s traffic the BIG-IP forwards the SNI received in the VIP. Alternative monitoring in a 2-tier deployment In this article, it is preferred to have 1:1 mapping between the L7 routes defined in the BIG-IP and the L7 routes defined in the ingress controller. It is possible to reduce the number of L7 routes and Service manifests for CIS by adding several monitors to a single L7 route manifest. For example we could have a single base L7 route such as www.twotier.com/ and several monitors probing the different applications behind this FQDN, for example: www.twotier.com/, www.twotier.com/account, and www.twotier.com/shop. This alternative monitoring can be configured with the following parameters: In this example, you can see how to create such a configuration. The preference for using a 1:1 mapping instead is because although this alternative strategy creates less manifests, automating the creation of these might be more complex. Additionally, it will be less easy to know in a given moment which applications are not working fine. Using OpenShift´s Router (HA-Proxy) in the second tier CIS can be configured to ingest F5 CRs, OpenShift Routes CRs or Ingress resources. When CIS is configured for using Routes or Ingress, by default HA-Proxy will also ingest these. In other words, both CIS and HA-Proxy will implement the same L7 routes. This behavior also applies to single-tier deployments where the behavior could be desired for testing. In general this behavior is not desired. HA-Proxy can be configured to do-not evaluate Routes or Ingress manifests with a given label or to do-not search for these in namespaces with a given label, for example "router=bigip". This behavior is configured in the IngressController resource type that manages HA-proxy's configuration: { "spec": { "namespaceSelector": { "matchExpressions": [ { "key": "router", "operator": "NotIn", "values": [ "bigip" ] } ] } } } This JSON configuration is applied with the next command for the default ingress controller/router in OpenShift: oc -n openshift-ingress-operator patch ingresscontroller default --patch-file=router-default.shard.json --type=merge More information on Route sharding can be found in this OpenShift document. Using the default Router instance OpenShift´s installer deploys the default HA-proxy instance with endpointPublishingStrategy type set to either hostNetwork or LoadBalancer. This will depend whether the OpenShift deployment is on-prem, in a public cloud, etc... This can be checked with the following command: oc get ingresscontrollers default -n openshift-ingress-operator -o jsonpath='{.status.endpointPublishingStrategy}{"\n"}' Regardless HA-proxy is configured with endpointPublishingStrategy either hostNetwork or LoadBalancer, CIS can be configured in clusterIP mode and refer to the HA-Proxy PODs using the "--orchestration-cni=ovn-k8s" and "--pool-member-type=cluster" options. The Service to refer to these HA-Proxy PODs will look as follows: apiVersion: v1 kind: Service metadata: name: router-default-route-a namespace: openshift-ingress spec: ports: - name: http port: 80 protocol: TCP targetPort: http - name: https port: 443 protocol: TCP targetPort: https selector: ingresscontroller.operator.openshift.io/deployment-ingresscontroller: default type: ClusterIP Where as indicated earlier there will be a Service manifest for each L7 route in order to have per L7 route monitoring. Note that these Services reside in the openshift-ingress namespace, where the HA-Proxy PODs are. Examples of this configuration can be found here using F5 CRs. Using additional Router instances Creating a new HA-Proxy instance just requires creating a new IngressController manifest in the openshift-ingress-operator namespace, such as the following sample: apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: shard-apps namespace: openshift-ingress-operator spec: clientTLS: defaultCertificate: name: router-shard-secret domain: shard-apps.com endpointPublishingStrategy: type: Private namespaceSelector: matchExpressions: - key: router operator: In values: - shard-apps replicas: 1 From this sample, note that: This new Router instance will evaluate only the L7 routes with namespaces with the label "router=shard-apps". the endpointPublishingStrategy is set to type Private, this is because we don´t need further exposure of it when CIS is accessing it in ClusterIP mode. When using an additional HA-proxy instance, the default Router will need to be instructed not to evaluate these same L7 routes as the additional HA-proxy instance. This is shown next: { "spec": { "namespaceSelector": { "matchExpressions": [ { "key": "router", "operator": "NotIn", "values": [ "bigip", "shard-apps" ] } ] } } } An example of this configurationcan be found here using Routes and multiple shards. Using Istio Ingress Gateway / OpenShift Service Mesh Using Istio (aka Service Mesh as packaged in OpenShift) in the second tier is straight-forward because Istio and CIS use different resource types for configuring L7 routes. A sample Service manifest to point to Istio ingress gateway is shown next apiVersion: v1 kind: Service metadata: name: svc-route-a namespace: istio-system spec: ports: - name: https port: 8443 protocol: TCP targetPort: https selector: app: istio-ingressgateway type: ClusterIP Where it can be observed that the Service manifests need to be created in the istio-system namespace and the selector needs to match the Istio ingress gateway´s Deployment's label. An example of this configuration can be found here using F5 CRs. Using NGINX Using NGINX in the second tier is much like using Istio, next is shown a sample Service manifest pointing to NGINX instances: apiVersion: v1 kind: Service metadata: name: svc-route-a namespace: nginx-ingress spec: ports: - name: https port: 443 protocol: TCP targetPort: 443 selector: app.kubernetes.io/instance: nginxingress-sample app.kubernetes.io/name: nginx-ingress type: ClusterIP The only special consideration to be considered, and only if both NGINX and CIS are meant to use the Ingress resource type, is to specify in the Ingress manifests which controller will ingest the manifest. This is specified with the ingressClassName attribute as shown next: in the case of NGINX apiVersion: networking.k8s.io/v1 kind: Ingress [...] spec: ingressClassName: nginx or in the case of CIS spec: ingressClassName: f5 An example of this configuration using F5 CRs in CIS and Ingress in NGINX can be found Using advanced BIG-IP services with CIS BIG-IP has many advanced services that can be easily referenced using F5 VirtualServer CRs, either directly in the manifest or referencing a Policy CR. When using Next Gen Routes these can also reference Policy CR but in a per router-group basis, hence having somewhat less granularity. Next is an overview of some of these advanced functionalities available. VirtualServer CR attributes for configuring advanced services Functionality attribute Advanced Web Application Firewall waf L3 anti-DoS protection dos L7 bot defense botDefense HTML content rewrite htmlProfile Custom iRules to perform advanced traffic management iRules Message routing framework (MRF) functionality for non HTTP traffic httpMrfRoutingEnabled IP intelligence ipIntelligencePolicy L3 Firewall rules firewallPolicy The configuration of these services must be pre-created in the BIG-IP as profiles in the /Common partition which can be referenced freely by CIS. It is expected that CIS 2.17 will incorporate APM and SSLo. Conclusion and closing remarks F5 BIG-IP is an External Loadbalancer with application awareness which allows to do advanced L7 services (not just TLS termination) and unify the different ingress paths into the cluster, allowing to merge several ingress controllers, API managers, service mesh or a combination of these. This solution is ingress type agnostic. A two-tier arrangement allows clean DevOps and NetOps separation. This is done by having separate L7 routes defined for the in-cluster ingress controllers and for the BIG-IPs. To continue your journey, please check the examples inthis GitHub repository using VirtualServer F5 CRs and OpenShift Route CRs.352Views0likes0CommentsF5 BIG-IP per application Red Hat OpenShift cluster migrations
Overview OpenShift migrations are typically done when it is desired to minimise disruption time when performing cluster upgrades. Disruptions can especially occur when performing big changes in the cluster such as changing the CNI from OpenShiftSDN to OVNKubernetes. OpenShift cluster migrations are well covered for applications by using RedHat's Migration Toolkit for Containers (MTC). The F5 BIG-IP has the role of network redirector indicated in the Network considerations chapter. The F5 BIG-IP can perform per L7 route migration without service disruption, hence allowing migration or roll-back on a per-application basis, eliminating disruption and de-risking the maintenance window. How it works As mentioned above, the traffic redirection will be done on a per L7 route basis, this is true regardless of how these L7 routes are implemented: ingress controller, API manager, service mesh, or a combination of these. This L7 awareness is achieved by usingF5 BIG-IP's Controller Ingress Services (CIS) controller for Kubernetes/OpenShift and its multi-cluster functionality which can expose in a single VIP L7 routes of services hosted in multiple Kubernetes/OpenShift clusters. This is shown in the next picture. For a migration operation it will be used a blue/green strategy independent for each L7 route where blue will refer to the application in the older cluster and green will refer to the application in the newer cluster. For each L7 route, it will be specified a weight for each blue or green backend (like in an A/B strategy). This is shown in the next picture. In this example, the migration scenario uses OpenShift´s default ingress controller (HA proxy) as an in-cluster ingress controller where the Route CR is used to indicate the L7 routes. For each L7 route defined in the HA-proxy tier, it will be defined as an L7 route in the F5 BIG-IP tier. This 1:1 mapping allows to have the per-application granularity. The VirtualServer CR is used for the F5 BIG-IP. If desired, it is also possible to use Route resources for the F5 BIG-IP. Next, it is shown the manifests for a given L7 route required for the F5 BIG-IP, in this case, https://www.migration.com/shop (alias route-b) apiVersion: "cis.f5.com/v1" kind: VirtualServer metadata: name: route-b namespace: openshift-ingress labels: f5cr: "true" spec: host: www.migration.com virtualServerAddress: "10.1.10.106" hostGroup: migration.com tlsProfileName: reencrypt-tls profileMultiplex: "/Common/oneconnect-32" pools: - path: /shop service: router-default-route-b-ocp1 servicePort: 443 weight: 100 alternateBackends: - service: router-default-route-b-ocp2 weight: 0 monitor: type: https name: /Common/www.migration.com-shop reference: bigip --- apiVersion: v1 kind: Service metadata: annotations: name: router-default-route-b-ocp1 namespace: openshift-ingress spec: ports: - name: http port: 80 protocol: TCP targetPort: http - name: https port: 443 protocol: TCP targetPort: https selector: ingresscontroller.operator.openshift.io/deployment-ingresscontroller: default type: NodePort --- apiVersion: v1 kind: Service metadata: annotations: name: router-default-route-b-ocp2 namespace: openshift-ingress spec: ports: - name: http port: 80 protocol: TCP targetPort: http - name: https port: 443 protocol: TCP targetPort: https selector: ingresscontroller.operator.openshift.io/deployment-ingresscontroller: default type: NodePort The CIS multi-cluster feature will search for the specified services in both clusters. It is up to DevOps to ensure that blue services are only present in the cluster designated as blue (in this case router-default-route-b-ocp1) and green services are only present in the cluster designated as green (in this case router-default-route-b-ocp2). It is important to remark that the Route manifests for HA-proxy (or any other ingress solution used) doesn't require any modification. That is, this migration mechanism is transparent to the application developers. Demo You can see this feature in action in the next video The manifests used in the demo can be found in the following GitHub repository: https://github.com/f5devcentral/f5-bd-cis-demo/tree/main/crds/demo-mc-twotier-haproxy-noshards Next steps Try it today! CIS is open-source software and is included in your support entitlement. If you want to learn more about CIS and CIS multi-cluster features the following blog articles are suggested. F5 BIG-IP deployment with OpenShift - platform and networking options F5 BIG-IP deployment with OpenShift - publishing application options F5 BIG-IP deployment with OpenShift - multi-cluster architectures344Views0likes0CommentsF5 BIG-IP deployment with OpenShift - multi-cluster architectures
This functionality enables to load balance services that are spread across multiple clusters. It is important to remark that this functionality is Service oriented: the load balancing decisions are independent for each Service. 582Views0likes0Comments
582Views0likes0CommentsScale Multi-Cluster OpenShift Deployments with F5 Container Ingress Services
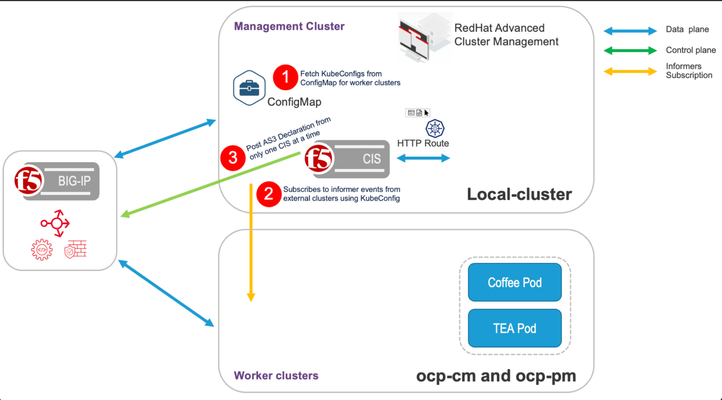
In the realm of enterprise IT, the complexity of managing applications across multiple clusters has long been a significant challenge. Recognizing this, we have introduced a solution with the latest release of BIG-IP Container Ingress Service (CIS). This article explores the challenges of distributing traffic across multiple clusters and how F5's CIS addresses these issues head-on. The Importance of Distributing Traffic Across Multiple Clusters Distributing traffic across multiple clusters is essential for maintaining high availability, ensuring consistent performance, and facilitating agile deployment strategies. However, achieving this is challenged by the complexity of configuring and managing multiple clusters, ensuring consistent application policies, and maintaining uptime during upgrades or deployments. Introducing the Solution: F5 BIG-IP CIS with Multi-Cluster Support F5's BIG-IP CIS now offers multi-cluster support, revolutionizing how applications are deployed across multiple OpenShift clusters. This new feature caters to a variety of deployment strategies and operational requirements: Deployment Strategies: Supports both Blue-Green Deployments and A/B Testing, allowing for more flexible and risk-averse application rollouts. High Availability (HA): Ensures continuous application availability by spanning across 'N' clusters, reducing the risk of downtime. Load Balancing: Implements Ratio-Based Load Distribution, optimizing resource utilization and ensuring efficient traffic management. Cluster Management: Facilitates Seamless Cluster Upgrades, ensuring that the latest features and security updates are implemented without impacting ongoing operations. How F5 BIG-IP CIS Works The picture below shows how the Multi-Cluster feature works. Notice that in the picture, we are showing 2 OpenShift Cluster, each with a CIS instance running. In a real deployment, we can run more than 2 clusters, but with only 2 CIS instances running in 2 of the clusters for redundancy purposes. Here is a brief workflow of the solution: Fetch KubeConfigs from ConfigMap: This stepinvolves accessing the ConfigMap repository and extracting the necessary KubeConfig files for each external cluster. Subscribes to Informer Events: Utilizes thepreviously fetched KubeConfigto set up informers for external clusters. The informers continuously listen for and capture any events or changes occurring in these clusters, thereby maintaining a real-time monitoring system. Heartbeat Check for Primary CIS:The workflow includes regular heartbeat checks on the primary CIS. This involves sending periodic signals to the primary CIS to verify its operational status and ensure it is actively functioning. Post AS3 Declaration: In this final step, the system coordinates the posting of AS3 declarations to the external clusters. This is managed to ensure that only one CIS posts an AS3 declaration at any given time, thereby avoiding conflicts and ensuring orderly updates. Conclusion F5's BIG-IP CIS with Multi-Cluster Support is a strategic enabler for businesses relying on OpenShift. By simplifying the management of multi-cluster environments, organizations can focus more on innovation and less on multi-cluster application operational complexities. Watch our detailed demo on the F5 DevCentral YouTube channel to see how this solution can transform your OpenShift deployments. Explore the Demo: 205Views2likes0Comments
205Views2likes0CommentsIntroducing F5 BIG-IP Next CNF Solutions for Red Hat OpenShift
5G and Red Hat OpenShift 5G standards have embraced Cloud-Native Network Functions (CNFs) for implementing network services in software as containers. This is a big change from previous Virtual Network Functions (VNFs) or Physical Network Functions (PNFs). The main characteristics of Cloud-Native Functions are: Implementation as containerized microservices Small performance footprint, with the ability to scale horizontally Independence of guest operating system,since CNFs operate as containers Lifecycle manageable by Kubernetes Overall, these provide a huge improvement in terms of flexibility, faster service delivery, resiliency, and crucially using Kubernetes as unified orchestration layer. The later is a drastic change from previous standards where each vendor had its own orchestration. This unification around Kubernetes greatly simplifies network functions for operators, reducing cost of deploying and maintaining networks. Additionally, by embracing the container form factor, allows Network Functions (NFs) to be deployed in new use cases like far edge. This is thanks to the smaller footprint while at the same time these can be also deployed at large scale in a central data center because of the horizontal scalability. In this article we focus on Red Hat OpenShift which is the market leading and industry reference implementation of Kubernetes for IT and Telco workloads. Introduction to F5 BIG-IP Next CNF Solutions F5 BIG-IP Next CNF Solutions is a suite of Kubernetes native 5G Network Functions, implemented as microservices. It shares the same Cloud Native Engine (CNE) as F5 BIG-IP Next SPK introduced last year. The functionalities implemented by the CNF Solutions deal mainly with user plane data. User plane data has the particularity that the final destination of the traffic is not the Kubernetes cluster but rather an external end-point, typically the Internet. In other words, the traffic gets in the Kubernetes cluster and it is forwarded out of the cluster again. This is done using dedicated interfaces that are not used for the regular ingress and egress paths of the regular traffic of a Kubernetes cluster. In this case, the main purpose of using Kubernetes is to make use of its orchestration, flexibility, and scalability. The main functionalities implemented at initial GA release of the CNF Solutions are: F5 Next Edge Firewall CNF, an IPv4/IPv6 firewall with the main focus in protecting the 5G core networks from external threads, including DDoS flood protection and IPS DNS protocol inspection. F5 Next CGNAT CNF, which offers large scale NAT with the following features: NAPT, Port Block Allocation, Static NAT, Address Pooling Paired, and Endpoint Independent mapping modes. Inbound NAT and Hairpining. Egress path filtering and address exclusions. ALG support: FTP/FTPS, TFTP, RTSP and PPTP. F5 Next DNS CNF, which offers a transparent DNS resolver and caching services. Other remarkable features are: Zero rating DNS64 which allows IPv6-only clients connect to IPv4-only services via synthetic IPv6 addresses. F5 Next Policy Enforcer CNF, which provides traffic classification, steering and shaping, and TCP and video optimization. This product is launched as Early Access in February 2023 with basic functionalities. Static TCP optimization is now GA in the initial release. Although the CGNAT (Carrier Grade NAT) and the Policy Enforcer functionalities are specific to User Plane use cases, the Edge Firewall and DNS functionalities have additional uses in other places of the network. F5 and OpenShift BIG-IP Next CNF Solutions fully supportsRed Hat OpenShift Container Platform which allows the deployment in edge or core locations with a unified management across the multiple deployments. OpenShift operators greatly facilitates the setup and tuning of telco grade applications. These are: Node Tuning Operator, used to setup Hugepages. CPU Manager and Topology Manager with NUMA awareness which allows to schedule the data plane PODs within a NUMA domain which is aligned with the SR-IOV NICs they are attached to. In an OpenShift platform all these are setup transparently to the applications and BIG-IP Next CNF Solutions uniquely require to be configured with an appropriate runtimeClass. F5 BIG-IP Next CNF Solutions architecture F5 BIG-IP Next CNF Solutions makes use of the widely trusted F5 BIG-IP Traffic Management Microkernel (TMM) data plane. This allows for a high performance, dependable product from the start. The CNF functionalities come from a microservices re-architecture of the broadly used F5 BIG-IP VNFs. The below diagram illustrates how a microservices architecture used. The data plane POD scales vertically from 1 to 16 cores and scales horizontally from 1 to 32 PODs, enabling it to handle millions of subscribers. NUMA nodes are supported. The next diagram focuses on the data plane handling which is the most relevant aspect for this CNF suite: Typically, each data plane POD has two IP address, one for each side of the N6 reference point. These could be named radio and Internet sides as shown in the diagram above. The left-side L3 hop must distribute the traffic amongst the lef-side addresses of the CNF data plane. This left-side L3 hop can be a router with BGP ECMP (Equal Cost Multi Path), an SDN or any other mechanism which is able to: Distribute the subscribers across the data plane PODs, shown in [1] of the figure above. Keep these subscribers in the same PODs when there is a change in the number of active data plane PODs (scale-in, scale-out, maintenance, etc...) as shown in [2] in the figure above. This minimizes service disruption. In the right side of the CNFs, the path towards the Internet, it is typical to implement NAT functionality to transform telco's private addresses to public addresses. This is done with the BIG-IP Next CG-NAT CNF. This NAT makes the return traffic symmetrical by reaching the same POD which processed the outbound traffic. This is thanks to each POD owning part of this NAT space, as shown in [3] of the above figure. Each POD´s NAT address space can be advertised via BGP. When not using NAT in the right side of the CNFs, it is required that the network is able to send the return traffic back to the same POD which is processing the same connection. The traffic must be kept symmetrical at all times, this is typically done with an SDN. Using F5 BIG-IP Next CNF Solutions As expected in a fully integrated Kubernetes solution, both the installation and configuration is done using the Kubernetes APIs. The installation is performed using helm charts, and the configuration using Custom Resource Definitions (CRDs). Unlike using ConfigMaps, using CRDs allow for schema validation of the configurations before these are applied. Details of the CRDs can be found in this clouddocs site. Next it is shown an overview of the most relevant CRDs. General network configuration Deploying in Kubernetes automatically configures and assigns IP addresses to the CNF PODs. The data plane interfaces will require specific configuration. The required steps are: Create Kubernetes NetworkNodePolicies and NetworkAttchment definitions which will allow to expose SR-IOV VFs to the CNF data planes PODs (TMM). To make use of these SR-IOV VFs these are referenced in the BIG-IP controller's Helm chart values file. This is described in theNetworking Overview page. Define the L2 and L3 configuration of the exposed SR-IOV interfaces using the F5BigNetVlan CRD. If static routes need to be configured, these can be added using the F5BigNetStaticroute CRD. If BGP configuration needs to be added, this is configured in the BIG-IP controller's Helm chart values file. This is described in the BGP Overview page. It is expected this will be configured using a CRD in the future. Traffic management listener configuration As with classic BIG-IP, once the CNFs are running and plumbed in the network, no traffic is processed by default. The traffic management functionalities implemented by BIG-IP Next CNF Solutions are the same of the analogous modules in the classic BIG-IP, and the CRDs in BIG-IP Next to configure these functionalities are conceptually similar too. Analogous to Virtual Servers in classic BIG-IP, BIG-IP Next CNF Solutions have a set of CRDs that create listeners of traffic where traffic management policies are applied. This is mainly the F5BigContextSecure CRD which allows to specify traffic selectors indicating VLANs, source, destination prefixes and ports where we want the policies to be applied. There are specific CRDs for listeners of Application Level Gateways (ALGs) and protocol specific solutions. These required several steps in classic BIG-IP: first creating the Virtual Service, then creating the profile and finally applying it to the Virtual Server. In BIG-IP Next this is done in a single CRD. At time of this writing, these CRDs are: F5BigZeroratingPolicy - Part of Zero-Rating DNS solution; enabling subscribers to bypass rate limits. F5BigDnsApp - High-performance DNS resolution, caching, and DNS64 translations. F5BigAlgFtp - File Transfer Protocol (FTP) application layer gateway services. F5BigAlgTftp - Trivial File Transfer Protocol (TFTP) application layer gateway services. F5BigAlgPptp - Point-to-Point Tunnelling Protocol (PPTP) application layer gateway services. F5BigAlgRtsp - Real Time Streaming Protocol (RTSP) application layer gateway services. Traffic management profiles and policies configuration Depending on the type of listener created, these can have attached different types of profiles and policies. In the case of F5BigContextSecure it can get attached thefollowing CRDs to define how traffic is processed: F5BigTcpSetting - TCP options to fine-tune how application traffic is managed. F5BigUdpSetting - UDP options to fine-tune how application traffic is managed. F5BigFastl4Setting - FastL4 option to fine-tune how application traffic is managed. and the following policies for security and NAT: F5BigDdosPolicy - Denial of Service (DoS/DDoS) event detection and mitigation. F5BigFwPolicy - Granular stateful-flow filtering based on access control list (ACL) policies. F5BigIpsPolicy - Intelligent packet inspection protects applications from malignant network traffic. F5BigNatPolicy - Carrier-grade NAT (CG-NAT) using large-scale NAT (LSN) pools. The ALG listeners require the use of F5BigNatPolicy and might make use for the F5BigFwPolicyCRDs.These CRDs have also traffic selectors to allow further control over which traffic these policies should be applied to. Firewall Contexts Firewall policies are applied to the listener with best match. In addition to theF5BigFwPolicy that might be attached, a global firewall policy (hence effective in all listeners) can be configured before the listener specific firewall policy is evaluated. This is done with F5BigContextGlobal CRD, which can have attached a F5BigFwPolicy. F5BigContextGlobal also contains the default action to apply on traffic not matching any firewall rule in any context (e.g. Global Context or Secure Context or another listener). This default action can be set to accept, reject or drop and whether to log this default action. In summary, within a listener match, the firewall contexts are processed in this order: ContextGlobal Matching ContextSecure or another listener context. Default action as defined by ContextGlobal's default action. Event Logging Event logging at high speed is critical to provide visibility of what the CNFs are doing. For this the next CRDs are implemented: F5BigLogProfile - Specifies subscriber connection information sent to remote logging servers. F5BigLogHslpub - Defines remote logging server endpoints for the F5BigLogProfile. Demo F5 BIG-IP Next CNF Solutions roadmap What it is being exposed here is just the begin of a journey. Telcos have embraced Kubernetes as compute and orchestration layer. Because of this, BIG-IP Next CNF Solutions will eventually replace the analogous classic BIG-IP VNFs. Expect in the upcoming months that BIG-IP Next CNF Solutions will match and eventually surpass the features currently being offered by the analogous VNFs. Conclusion This article introduces fully re-architected, scalable solution for Red Hat OpenShift mainly focused on telco's user plane. This new microservices architecture offers flexibility, faster service delivery, resiliency and crucially the use of Kubernetes. Kubernetes is becoming the unified orchestration layer for telcos, simplifying infrastructure lifecycle, and reducing costs. OpenShift represents the best-in-class Kubernetes platform thanks to its enterprise readiness and Telco specific features. The architecture of this solution alongside the use of OpenShift also extends network services use cases to the edge by allowing the deployment of Network Functions in a smaller footprint. Please check the official BIG-IP Next CNF Solutions documentation for more technical details and check www.f5.com for a high level overview.1.8KViews2likes1Comment