Layer 4 vs Layer 7 DoS Attack
Not all DoS (Denial of Service) attacks are the same. While the end result is to consume as much - hopefully all - of a server or site's resources such that legitimate users are denied service (hence the name) there is a subtle difference in how these attacks are perpetrated that makes one easier to stop than the other. SYN Flood A Layer 4 DoS attack is often referred to as a SYN flood. It works at the transport protocol (TCP) layer. A TCP connection is established in what is known as a 3-way handshake. The client sends a SYN packet, the server responds with a SYN ACK, and the client responds to that with an ACK. After the "three-way handshake" is complete, the TCP connection is considered established. It is as this point that applications begin sending data using a Layer 7 or application layer protocol, such as HTTP. A SYN flood uses the inherent patience of the TCP stack to overwhelm a server by sending a flood of SYN packets and then ignoring the SYN ACKs returned by the server. This causes the server to use up resources waiting a configured amount of time for the anticipated ACK that should come from a legitimate client. Because web and application servers are limited in the number of concurrent TCP connections they can have open, if an attacker sends enough SYN packets to a server it can easily chew through the allowed number of TCP connections, thus preventing legitimate requests from being answered by the server. SYN floods are fairly easy for proxy-based application delivery and security products to detect. Because they proxy connections for the servers, and are generally hardware-based with a much higher TCP connection limit, the proxy-based solution can handle the high volume of connections without becoming overwhelmed. Because the proxy-based solution is usually terminating the TCP connection (i.e. it is the "endpoint" of the connection) it will not pass the connection to the server until it has completed the 3-way handshake. Thus, a SYN flood is stopped at the proxy and legitimate connections are passed on to the server with alacrity. The attackers are generally stopped from flooding the network through the use of SYN cookies. SYN cookies utilize cryptographic hashing and are therefore computationally expensive, making it desirable to allow a proxy/delivery solution with hardware accelerated cryptographic capabilities handle this type of security measure. Servers can implement SYN cookies, but the additional burden placed on the server alleviates much of the gains achieved by preventing SYN floods and often results in available, but unacceptably slow performing servers and sites. HTTP GET DoS A Layer 7 DoS attack is a different beast and it's more difficult to detect. A Layer 7 DoS attack is often perpetrated through the use of HTTP GET. This means that the 3-way TCP handshake has been completed, thus fooling devices and solutions which are only examining layer 4 and TCP communications. The attacker looks like a legitimate connection, and is therefore passed on to the web or application server. At that point the attacker begins requesting large numbers of files/objects using HTTP GET. They are generally legitimate requests, there are just a lot of them. So many, in fact, that the server quickly becomes focused on responding to those requests and has a hard time responding to new, legitimate requests. When rate-limiting was used to stop this type of attack, the bad guys moved to using a distributed system of bots (zombies) to ensure that the requests (attack) was coming from myriad IP addresses and was therefore not only more difficult to detect, but more difficult to stop. The attacker uses malware and trojans to deposit a bot on servers and clients, and then remotely includes them in his attack by instructing the bots to request a list of objects from a specific site or server. The attacker might not use bots, but instead might gather enough evil friends to launch an attack against a site that has annoyed them for some reason. Layer 7 DoS attacks are more difficult to detect because the TCP connection is valid and so are the requests. The trick is to realize when there are multiple clients requesting large numbers of objects at the same time and to recognize that it is, in fact, an attack. This is tricky because there may very well be legitimate requests mixed in with the attack, which means a "deny all" philosophy will result in the very situation the attackers are trying to force: a denial of service. Defending against Layer 7 DoS attacks usually involves some sort of rate-shaping algorithm that watches clients and ensures that they request no more than a configurable number of objects per time period, usually measured in seconds or minutes. If the client requests more than the configurable number, the client's IP address is blacklisted for a specified time period and subsequent requests are denied until the address has been freed from the blacklist. Because this can still affect legitimate users, layer 7 firewall (application firewall) vendors are working on ways to get smarter about stopping layer 7 DoS attacks without affecting legitimate clients. It is a subtle dance and requires a bit more understanding of the application and its flow, but if implemented correctly it can improve the ability of such devices to detect and prevent layer 7 DoS attacks from reaching web and application servers and taking a site down. The goal of deploying an application firewall or proxy-based application delivery solution is to ensure the fast and secure delivery of an application. By preventing both layer 4 and layer 7 DoS attacks, such solutions allow servers to continue serving up applications without a degradation in performance caused by dealing with layer 4 or layer 7 attacks.18KViews0likes3Comments
Bidirectional Forwarding Detection (BFD) Protocol Cheat Sheet
Definition This is a protocol initially described inRFC5880and IPv4/IPv6 specifics inRFC5881. I would say this is an aggressive 'hello-like' protocol with shorter timers but very lightweight on the wire and requiring very little processing as it is designed to be implemented in forwarding plane (although RFC does not forbid it to be implemented in control plane). It also contains a feature called Echo that further leaves cpu processing cycle to roughly ZERO which literally just 'loops' BFD control packets sent from peer back to them without even 'touching' (processing) it. BFD helps routing protocol detects peers failure at sub-second level and BIG-IP supports it on all its routing protocols. On BIG-IP it is control-plane independent as TMM that takes care of BFD sending/receivingunicastprobes (yes,no multicast!) and BIG-IP's Advanced Routing Module® being responsible only for its configuration (of course!) and to receive state information from TMM that is displayed in show commands. BIG-IP's control plane daemon communicates with TMM isoamd. This daemon starts when BFD is enabled in the route domain like any other routing protocol. BFD Handshake Explained 218: BFD was configured on Cisco Router but not on BIG-IP so neighbour signals BIG-IP sessionstate is Down and no flags 219: I had just enabled BFD on BIG-IP, session state is now Init and only Control Plane Independent flag set¹ 220: Poll flag is set to validate initial bidirectional connectivity (expecting Final flag set in response) 221: BIG-IP sets Final flag and handshake is complete² ¹Control Plane Independentflag is set because BFD is not actively performed by BIG-IP's control plane. BIG-IP's BFD control plane daemon (oamd) just signals TMM what BFD sessions are required and TMM takes care of sending/receiving of all BFD control traffic and informs session state back to Advanced Routing Module's daemon. ²Packets 222-223are just to show that after handshake is finished all flags are cleared unless there is another event that triggers them. Packet 218 is how Cisco Router sees BIG-IP when BFD is not enabled. Control Plane Independent flag on BIG-IP remains though for the reasons already explained above. Protocol fields Diagnostic codes 0 (No Diagnostic): Typically seen when BFD session is UP and there are no errors. 1 (Control Detection Time Expired):BFD Detect Timer expired and session was marked down. 2 (Echo Function Failed):BFD Echo packet loop verification failed, session is marked down and this is the diagnostic code number. 3 (Neighbor Signaled Session Down):If either neighbour advertised state or our local state is down you will see this diagnostic code 4 (Forwarding Planet Reset):When forwarding-plane (TMM) is reset and peer should not rely on BFD so session is marked down. 5 (Path Down):Ondemand mode external application can signal BFD that path is down so we can set session down using this code 6 Concatenated Path Down): 7 (Administratively Down):Session is marked down by an administrator 8 (Reverse Concatenated Path Down): 9-31:Reserved for future use BFD verification 'show' commands ³Type IP address to see specific session Modes Asynchronous(default): hello-like mode where BIG-IP periodically sends (and receives) BFD control packets and if control detection timer expires, session is marked as down.It uses UDP port3784. Demand: BFD handshake is completed but no periodic BFD control packets are exchanged as this mode assumes system has its own way of verifying connectivity with peer and may trigger BFD verification on demand, i.e. when it needs to use it according to its implementation.BIG-IP currently does not support this mode. Asynchronous + Echo Function: When enabled, TMM literally loops BFDecho-specificcontrol packetson UDP port 3785sent from peers back to them without processing it as it wasn't enough that this protocol is already lightweight. In this mode, a less aggressive timer (> 1 second) should be used for regularBFD control packets over port 3784 and more aggressive timer is used by echo function.BIG-IP currently does not support this mode. Header Fields Protocol Version:BFD version used. Latest one is v1 (RFC5880) Diagnostic Code: BFD error code for diagnostics purpose. Session State: How transmitting system sees the session state which can be AdminDown, Down, Init or Up. Message Flags:Additional session configuration or functionality (e.g. flag that says authentication is enabled) Detect Time Multiplier:Informs remote peer BFD session is supposed to be marked down ifDesired Min TX Intervalmultiplied by this value is reached Message Length(bytes):Length of BFD Control packet My Discriminator:For each BFD session each peer will use a unique discriminator to differentiate multiple session. Your Discriminator:When BIG-IP receives BFD control message back from its peer we add peer's My Discriminator to Your Discriminator in our header. Desired Min TX Interval(microseconds):Fastest we can send BFD control packets to remote peer (no less than configured value here) Required Min RX Interval(microseconds):Fastest we can receive BFD control packets from remote peer (no less than configured value here) Required Min Echo Interval(microseconds):Fastest we can loop BFD echo packets back to remote system (0 means Echo function is disabled) Session State AdminDown:Administratively forced down by command Down: Either control detection time expired in an already established BFD session or it never came up.If probing time (min_tx) is set to 100ms for example, and multiplier is 3 then no response after 300ms makes system go down. Init:Signals a desire to bring session up in the beginning of BFD handshake. Up:Indicates session is Up Message Flags Poll:Pool flag is just a 'ping' that requires peer box to respond with Final flag. In BFD handshake as well as in Demand mode pool message is a request to validate bidirectional connectivity. Final:Sent in response to packet with Poll bit set Control Plane Independent:Set if BFD can continue to function if control plane is disrupted¹ Authentication Present:Only set if authentication is being used Demand:If set, it is implied that periodic BFD control packets are no longer sent and another mechanism (on demand) is used instead. Multipoint:Reserved for future use of point-to-multipoint extension. Should be 0 on both sides. ¹ This is the case for BIG-IP as BFD is implemented in forwarding plane (TMM) BFD Configuration Configure desired transmit and receive intervals as well as multiplier on BIG-IP. And Cisco Router: You will typically configure the above regardless of routing protocol used. BFD BGP Configuration And Cisco Router: BFD OSPFv2/v3 Configuration BFD ISIS Configuration BFD RIPv1/v2 Configuration BFD Static Configuration All interfaces no matter what: Specific interface only: Tie BFD configuration to static route:8.8KViews0likes7CommentsThe Disadvantages of DSR (Direct Server Return)
I read a very nice blog post yesterday discussing some of the traditional pros and cons of load-balancing configurations. The author comes to the conclusion that if you can use direct server return, you should. I agree with the author's list of pros and cons; DSR is the least intrusive method of deploying a load-balancer in terms of network configuration. But there are quite a few disadvantages missing from the author's list. Author's List of Disadvantages of DSR The disadvantages of Direct Routing are: Backend server must respond to both its own IP (for health checks) and the virtual IP (for load balanced traffic) Port translation or cookie insertion cannot be implemented. The backend server must not reply to ARP requests for the VIP (otherwise it will steal all the traffic from the load balancer) Prior to Windows Server 2008 some odd routing behavior could occur in In some situations either the application or the operating system cannot be modified to utilse Direct Routing. Some additional disadvantages: Protocol sanitization can't be performed. This means vulnerabilities introduced due to manipulation of lax enforcement of RFCs and protocol specifications can't be addressed. Application acceleration can't be applied. Even the simplest of acceleration techniques, e.g. compression, can't be applied because the traffic is bypassing the load-balancer (a.k.a. application delivery controller). Implementing caching solutions become more complex. With a DSR configuration the routing that makes it so easy to implement requires that caching solutions be deployed elsewhere, such as via WCCP on the router. This requires additional configuration and changes to the routing infrastructure, and introduces another point of failure as well as an additional hop, increasing latency. Error/Exception/SOAP fault handling can't be implemented. In order to address failures in applications such as missing files (404) and SOAP Faults (500) it is necessary for the load-balancer to inspect outbound messages. Using a DSR configuration this ability is lost, which means errors are passed directly back to the user without the ability to retry a request, write an entry in the log, or notify an administrator. Data Leak Prevention can't be accomplished. Without the ability to inspect outbound messages, you can't prevent sensitive data (SSN, credit card numbers) from leaving the building. Connection Optimization functionality is lost. TCP multiplexing can't be accomplished in a DSR configuration because it relies on separating client connections from server connections. This reduces the efficiency of your servers and minimizes the value added to your network by a load balancer. There are more disadvantages than you're likely willing to read, so I'll stop there. Suffice to say that the problem with the suggestion to use DSR whenever possible is that if you're an application-aware network administrator you know that most of the time, DSR isn't the right solution because it restricts the ability of the load-balancer (application delivery controller) to perform additional functions that improve the security, performance, and availability of the applications it is delivering. DSR is well-suited, and always has been, to UDP-based streaming applications such as audio and video delivered via RTSP. However, in the increasingly sensitive environment that is application infrastructure, it is necessary to do more than just "load balancing" to improve the performance and reliability of applications. Additional application delivery techniques are an integral component to a well-performing, efficient application infrastructure. DSR may be easier to implement and, in some cases, may be the right solution. But in most cases, it's going to leave you simply serving applications, instead of delivering them. Just because you can, doesn't mean you should.5.7KViews0likes4CommentsPersistent and Persistence, What's the Difference?
The English language is one of the most expressive, and confusing, in existence. Words can have different meaning based not only on context, but on placement within a given sentence. Add in the twists that come from technical jargon and suddenly you've got words meaning completely different things. This is evident in the use of persistent and persistence. While the conceptual basis of persistence and persistent are essentially the same, in reality they refer to two different technical concepts. Both persistent and persistence relate to the handling of connections. The former is often used as a general description of the behavior of HTTP and, necessarily, TCP connections, though it is also used in the context of database connections. The latter is most often related to TCP/HTTP connection handling but almost exclusively in the context of load-balancing. Persistent Persistent connections are connections that are kept open and reused. The most commonly implemented form of persistent connections are HTTP, with database connections a close second. Persistent HTTP connections were implemented as part of the HTTP 1.1 specification as a method of improving the efficiency Related Links HTTP 1.1 RFC Persistent Connection Behavior of Popular Browsers Persistent Database Connections Apache Keep-Alive Support Cookies, Sessions, and Persistence of HTTP in general. Before HTTP 1.1 a browser would generally open one connection per object on a page in order to retrieve all the appropriate resources. As the number of objects in a page grew, this became increasingly inefficient and significantly reduced the capacity of web servers while causing browsers to appear slow to retrieve data. HTTP 1.1 and the Keep-Alive header in HTTP 1.0 were aimed at improving the performance of HTTP by reusing TCP connections to retrieve objects. They made the connections persistent such that they could be reused to send multiple HTTP requests using the same TCP connection. Similarly, this notion was implemented by proxy-based load-balancers as a way to improve performance of web applications and increase capacity on web servers. Persistent connections between a load-balancer and web servers is usually referred to as TCP multiplexing. Just like browsers, the load-balancer opens a few TCP connections to the servers and then reuses them to send multiple HTTP requests. Persistent connections, both in browsers and load-balancers, have several advantages: Less network traffic due to less TCP setup/teardown. It requires no less than 7 exchanges of data to set up and tear down a TCP connection, thus each connection that can be reused reduces the number of exchanges required resulting in less traffic. Improved performance. Because subsequent requests do not need to setup and tear down a TCP connection, requests arrive faster and responses are returned quicker. TCP has built-in mechanisms, for example window sizing, to address network congestion. Persistent connections give TCP the time to adjust itself appropriately to current network conditions, thus improving overall performance. Non-persistent connections are not able to adjust because they are open and almost immediately closed. Less server overhead. Servers are able to increase the number of concurrent users served because each user requires fewer connections through which to complete requests. Persistence Persistence, on the other hand, is related to the ability of a load-balancer or other traffic management solution to maintain a virtual connection between a client and a specific server. Persistence is often referred to in the application delivery networking world as "stickiness" while in the web and application server demesne it is called "server affinity". Persistence ensures that once a client has made a connection to a specific server that subsequent requests are sent to the same server. This is very important to maintain state and session-specific information in some application architectures and for handling of SSL-enabled applications. Examples of Persistence Hash Load Balancing and Persistence LTM Source Address Persistence Enabling Session Persistence 20 Lines or Less #7: JSessionID Persistence When the first request is seen by the load-balancer it chooses a server. On subsequent requests the load-balancer will automatically choose the same server to ensure continuity of the application or, in the case of SSL, to avoid the compute intensive process of renegotiation. This persistence is often implemented using cookies but can be based on other identifying attributes such as IP address. Load-balancers that have evolved into application delivery controllers are capable of implementing persistence based on any piece of data in the application message (payload), headers, or at in the transport protocol (TCP) and network protocol (IP) layers. Some advantages of persistence are: Avoid renegotiation of SSL. By ensuring that SSL enabled connections are directed to the same server throughout a session, it is possible to avoid renegotiating the keys associated with the session, which is compute and resource intensive. This improves performance and reduces overhead on servers. No need to rewrite applications. Applications developed without load-balancing in mind may break when deployed in a load-balanced architecture because they depend on session data that is stored only on the original server on which the session was initiated. Load-balancers capable of session persistence ensure that those applications do not break by always directing requests to the same server, preserving the session data without requiring that applications be rewritten. Summize So persistent connections are connections that are kept open so they can be reused to send multiple requests, while persistence is the process of ensuring that connections and subsequent requests are sent to the same server through a load-balancer or other proxy device. Both are important facets of communication between clients, servers, and mediators like load-balancers, and increase the overall performance and efficiency of the infrastructure as well as improving the end-user experience.4.7KViews0likes2CommentsWhat is server offload and why do I need it?
One of the tasks of an enterprise architect is to design a framework atop which developers can implement and deploy applications consistently and easily. The consistency is important for internal business continuity and reuse; common objects, operations, and processes can be reused across applications to make development and integration with other applications and systems easier. Architects also often decide where functionality resides and design the base application infrastructure framework. Application server, identity management, messaging, and integration are all often a part of such architecture designs. Rarely does the architect concern him/herself with the network infrastructure, as that is the purview of “that group”; the “you know who I’m talking about” group. And for the most part there’s no need for architects to concern themselves with network-oriented architecture. Applications should not need to know on which VLAN they will be deployed or what their default gateway might be. But what architects might need to know – and probably should know – is whether the network infrastructure supports “server offload” of some application functions or not, and how that can benefit their enterprise architecture and the applications which will be deployed atop it. WHAT IT IS Server offload is a generic term used by the networking industry to indicate some functionality designed to improve the performance or security of applications. We use the term “offload” because the functionality is “offloaded” from the server and moved to an application network infrastructure device instead. Server offload works because the application network infrastructure is almost always these days deployed in front of the web/application servers and is in fact acting as a broker (proxy) between the client and the server. Server offload is generally offered by load balancers and application delivery controllers. You can think of server offload like a relay race. The application network infrastructure device runs the first leg and then hands off the baton (the request) to the server. When the server is finished, the application network infrastructure device gets to run another leg, and then the race is done as the response is sent back to the client. There are basically two kinds of server offload functionality: Protocol processing offload Protocol processing offload includes functions like SSL termination and TCP optimizations. Rather than enable SSL communication on the web/application server, it can be “offloaded” to an application network infrastructure device and shared across all applications requiring secured communications. Offloading SSL to an application network infrastructure device improves application performance because the device is generally optimized to handle the complex calculations involved in encryption and decryption of secured data and web/application servers are not. TCP optimization is a little different. We say TCP session management is “offloaded” to the server but that’s really not what happens as obviously TCP connections are still opened, closed, and managed on the server as well. Offloading TCP session management means that the application network infrastructure is managing the connections between itself and the server in such a way as to reduce the total number of connections needed without impacting the capacity of the application. This is more commonly referred to as TCP multiplexing and it “offloads” the overhead of TCP connection management from the web/application server to the application network infrastructure device by effectively giving up control over those connections. By allowing an application network infrastructure device to decide how many connections to maintain and which ones to use to communicate with the server, it can manage thousands of client-side connections using merely hundreds of server-side connections. Reducing the overhead associated with opening and closing TCP sockets on the web/application server improves application performance and actually increases the user capacity of servers. TCP offload is beneficial to all TCP-based applications, but is particularly beneficial for Web 2.0 applications making use of AJAX and other near real-time technologies that maintain one or more connections to the server for its functionality. Protocol processing offload does not require any modifications to the applications. Application-oriented offload Application-oriented offload includes the ability to implement shared services on an application network infrastructure device. This is often accomplished via a network-side scripting capability, but some functionality has become so commonplace that it is now built into the core features available on application network infrastructure solutions. Application-oriented offload can include functions like cookie encryption/decryption, compression, caching, URI rewriting, HTTP redirection, DLP (Data Leak Prevention), selective data encryption, application security functionality, and data transformation. When network-side scripting is available, virtually any kind of pre or post-processing can be offloaded to the application network infrastructure and thereafter shared with all applications. Application-oriented offload works because the application network infrastructure solution is mediating between the client and the server and it has the ability to inspect and manipulate the application data. The benefits of application-oriented offload are that the services implemented can be shared across multiple applications and in many cases the functionality removes the need for the web/application server to handle a specific request. For example, HTTP redirection can be fully accomplished on the application network infrastructure device. HTTP redirection is often used as a means to handle application upgrades, commonly mistyped URIs, or as part of the application logic when certain conditions are met. Application security offload usually falls into this category because it is application – or at least application data – specific. Application security offload can include scanning URIs and data for malicious content, validating the existence of specific cookies/data required for the application, etc… This kind of offload improves server efficiency and performance but a bigger benefit is consistent, shared security across all applications for which the service is enabled. Some application-oriented offload can require modification to the application, so it is important to design such features into the application architecture before development and deployment. While it is certainly possible to add such functionality into the architecture after deployment, it is always easier to do so at the beginning. WHY YOU NEED IT Server offload is a way to increase the efficiency of servers and improve application performance and security. Server offload increases efficiency of servers by alleviating the need for the web/application server to consume resources performing tasks that can be performed more efficiently on an application network infrastructure solution. The two best examples of this are SSL encryption/decryption and compression. Both are CPU intense operations that can consume 20-40% of a web/application server’s resources. By offloading these functions to an application network infrastructure solution, servers “reclaim” those resources and can use them instead to execute application logic, serve more users, handle more requests, and do so faster. Server offload improves application performance by allowing the web/application server to concentrate on what it is designed to do: serve applications and putting the onus for performing ancillary functions on a platform that is more optimized to handle those functions. Server offload provides these benefits whether you have a traditional client-server architecture or have moved (or are moving) toward a virtualized infrastructure. Applications deployed on virtual servers still use TCP connections and SSL and run applications and therefore will benefit the same as those deployed on traditional servers. I am wondering why not all websites enabling this great feature GZIP? 3 Really good reasons you should use TCP multiplexing SOA & Web 2.0: The Connection Management Challenge Understanding network-side scripting I am in your HTTP headers, attacking your application Infrastructure 2.0: As a matter of fact that isn't what it means2.6KViews0likes1CommentReactive, Proactive, Predictive: SDN Models
#SDN #openflow A session at #interop sheds some light on SDN operational models One of the downsides of speaking at conferences is that your session inevitably conflicts with another session that you'd really like to attend. Interop NY was no exception, except I was lucky enough to catch the tail end of a session I was interested in after finishing my own. I jumped into OpenFlow and Software Defined Networks: What Are They and Why Do You Care? just as discussion about an SDN implementation at CERN labs was going on, and was quite happy to sit through the presentation. CERN labs has implemented an SDN, focusing on the use of OpenFlow to manage the network. They partner with HP for the control plane, and use a mix of OpenFlow-enabled switches for their very large switching fabric. All that's interesting, but what was really interesting (to me anyway) was the answer to my question with respect to the rate of change and how it's handled. We know, after all, that there are currently limitations on the number of inserts per second into OpenFlow-enabled switches and CERN's environment is generally considered pretty volatile. The response became a discussion of SDN models for handling change. The speaker presented three approaches that essentially describe SDN models for OpenFlow-based networks: Reactive Reactive models are those we generally associate with SDN and OpenFlow. Reactive models are constantly adjusting and are in flux as changes are made immediately as a reaction to current network conditions. This is the base volatility management model in which there is a high rate of change in the location of end-points (usually virtual machines) and OpenFlow is used to continually update the location and path through the network to each end-point. The speaker noted that this model is not scalable for any organization and certainly not CERN. Proactive Proactive models anticipate issues in the network and attempt to address them before they become a real problem (which would require reaction). Proactive models can be based on details such as increasing utilization in specific parts of the network, indicating potential forthcoming bottlenecks. Making changes to the routing of data through the network before utilization becomes too high can mitigate potential performance problems. CERN takes advantage of sFlow and Netflow to gather this data. Predictive A predictive approach uses historical data regarding the performance of the network to adjust routes and flows periodically. This approach is less disruptive as it occurs with less frequency that a reactive model but still allows for trends in flow and data volume to inform appropriate routes. CERN uses a combination of proactive and predictive methods for managing its network and indicated satisfaction with current outcomes. I walked out with two takeaways. First was validation that a reactive, real-time network operational model based on OpenFlow was inadequate for managing high rates of change. Second was the use of OpenFlow as more of an operational management toolset than an automated, real-time self-routing network system is certainly a realistic option to address the operational complexity introduced by virtualization, cloud and even very large traditional networks. The Future of Cloud: Infrastructure as a Platform SDN, OpenFlow, and Infrastructure 2.0 Applying ‘Centralized Control, Decentralized Execution’ to Network Architecture Integration Topologies and SDN SDN is Network Control. ADN is Application Control. The Next IT Killer Is… Not SDN How SDN Is Defined Within ADN Architectures2KViews0likes0CommentsBack to Basics: The Many Modes of Proxies
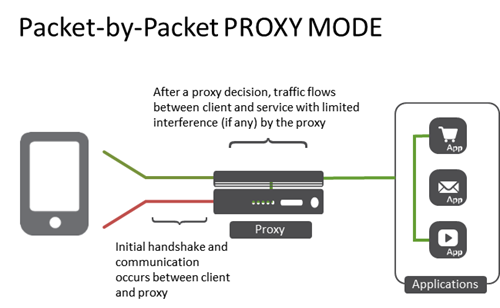
The simplicity of the term "proxy" belies the complex topological options available. Understanding the different deployment options will enable your proxy deployment to fit your environment and, more importantly, your applications. It seems so simple in theory. A proxy is a well-understood concept that is not peculiar to networking. Indeed, some folks vote by proxy, they speak by proxy (translators), and even on occasion, marry by proxy. A proxy, regardless of its purpose, sits between two entities and performs a service. In network architectures the most common use of a proxy is to provide load balancing services to enable scale, reliability and even performance for applications. Proxies can log data exchanges, act as a gatekeeper (authentication and authorization), scan inbound and outbound traffic for malicious content and more. Proxies are a key strategic point of control in the data center because they are typically deployed as the go-between for end-users and applications. These go-between services are often referred to as virtual services, and for purposes of this blog that's what we'll call them. It's an important distinction because a single proxy can actually act in multiple modes on a per-virtual service basis. That's all pretty standard stuff. What's not simple is when you start considering how you want your proxy to act. Should it be a full proxy? A half proxy? Should it route or forward? There are multiple options for these components and each has its pros and cons. Understanding each proxy "mode" is an important step toward architecting a suitable solution for your environment as the mode determines the behavior of traffic as it traverses the proxy. Standard Virtual Service (Full Application Proxy) The standard virtual service provided by a full proxy fully terminates the transport layer connections (typically TCP) and establishes completely separate transport layer connections to the applications. This enables the proxy to intercept, inspect and ultimate interact with the data (traffic) as its flowing through the system. Any time you need to inspect payloads (JSON, HTML, XML, etc...) or steer requests based on HTTP headers (URI, cookies, custom variables) on an ongoing basis you'll need a virtual service in full proxy mode. A full proxy is able to perform application layer services. That is, it can act on protocol and data transported via an application protocol, such as HTTP. Performance Layer 4 Service (Packet by Packet Proxy) Before application layer proxy capabilities came into being, the primary model for proxies (and load balancers) was layer 4 virtual services. In this mode, a proxy can make decisions and interact with packets up to layer 4 - the transport layer. For web traffic this almost always equates to TCP. This is the highest layer of the network stack at which SDN architectures based on OpenFlow are able to operate. Today this is often referred to as flow-based processing, as TCP connections are generally considered flows for purposes of configuring network-based services. In this mode, a proxy processes each packet and maps it to a connection (flow) context. This type of virtual service is used for traffic that requires simple load balancing, policy network routing or high-availability at the transport layer. Many proxies deployed on purpose-built hardware take advantage of FPGAs that make this type of virtual service execute at wire speed. A packet-by-packet proxy is able to make decisions based on information related to layer 4 and below. It cannot interact with application-layer data. The connection between the client and the server is actually "stitched" together in this mode, with the proxy primarily acting as a forwarding component after the initial handshake is completed rather than as an endpoint or originating source as is the case with a full proxy. IP Forwarding Virtual Service (Router) For simple packet forwarding where the destination is based not on a pooled resource but simply on a routing table, an IP forwarding virtual service turns your proxy into a packet layer forwarder. A IP forwarding virtual server can be provisioned to rewrite the source IP address as the traffic traverses the service. This is done to force data to return through the proxy and is referred to as SNATing traffic. It uses transport layer (usually TCP) port multiplexing to accomplish stateful address translation. The address it chooses can be load balanced from a pool of addresses (a SNAT pool) or you can use an automatic SNAT capability. Layer 2 Forwarding Virtual Service (Bridge) For situations where a proxy should be used to bridge two different Ethernet collision domains, a layer 2 forwarding virtual service an be used. It can be provisioned to be an opaque, semi-opaque, or transparent bridge. Bridging two Ethernet domains is like an old timey water brigade. One guy fills a bucket of water (the client) and hands it to the next guy (the proxy) who hands it to the destination (the server/service) where it's thrown on the fire. The guy in the middle (the proxy) just bridges the gap (you're thinking what I'm thinking - that's where the term came from, right?) between the two Ethernet domains (networks).1.9KViews0likes3CommentsIP::addr and IPv6
Did you know that all address internal to tmm are kept in IPv6 format? If you’ve written external monitors, I’m guessing you knew this. In the external monitors, for IPv4 networks the IPv6 “header” is removed with the line: IP=`echo $1 | sed 's/::ffff://'` IPv4 address are stored in what’s called “IPv4-mapped” format. An IPv4-mapped address has its first 80 bits set to zero and the next 16 set to one, followed by the 32 bits of the IPv4 address. The prefix looks like this: 0000:0000:0000:0000:0000:ffff: (abbreviated as ::ffff:, which looks strickingly simliar—ok, identical—to the pattern stripped above) Notation of the IPv4 section of the IPv4-formatted address vary in implementations between ::ffff:192.168.1.1 and ::ffff:c0a8:c8c8, but only the latter notation (in hex) is supported. If you need the decimal version, you can extract it like so: % puts $x ::ffff:c0a8:c8c8 % if { [string range $x 0 6] == "::ffff:" } { scan [string range $x 7 end] "%2x%2x:%2x%2x" ip1 ip2 ip3 ip4 set ipv4addr "$ip1.$ip2.$ip3.$ip4" } 192.168.200.200 Address Comparisons The text format is not what controls whether the IP::addr command (nor the class command) does an IPv4 or IPv6 comparison. Whether or not the IP address is IPv4-mapped is what controls the comparison. The text format merely controls how the text is then translated into the internal IPv6 format (ie: whether it becomes a IPv4-mapped address or not). Normally, this is not an issue, however, if you are trying to compare an IPv6 address against an IPv4 address, then you really need to understand this mapping business. Also, it is not recommended to use 0.0.0.0/0.0.0.0 for testing whether something is IPv4 versus IPv6 as that is not really valid a IP address—using the 0.0.0.0 mask (technically the same as /0) is a loophole and ultimately, what you are doing is loading the equivalent form of a IPv4-mapped mask. Rather, you should just use the following to test whether it is an IPv4-mapped address: if { [IP::addr $IP1 equals ::ffff:0000:0000/96] } { log local0. “Yep, that’s an IPv4 address” } These notes are covered in the IP::addr wiki entry. Any updates to the command and/or supporting notes will exist there, so keep the links handy. Related Articles F5 Friday: 'IPv4 and IPv6 Can Coexist' or 'How to eat your cake ... Service Provider Series: Managing the ipv6 Migration IPv6 and the End of the World No More IPv4. You do have your IPv6 plan running now, right ... Question about IPv6 - BIGIP - DevCentral - F5 DevCentral ... Insert IPv6 address into header - DevCentral - F5 DevCentral ... Business Case for IPv6 - DevCentral - F5 DevCentral > Community ... We're sorry. The IPv4 address you are trying to reach has been ... Don MacVittie - F5 BIG-IP IPv6 Gateway Module1.1KViews1like1CommentWILS: Load Balancing and Ephemeral Port Exhaustion
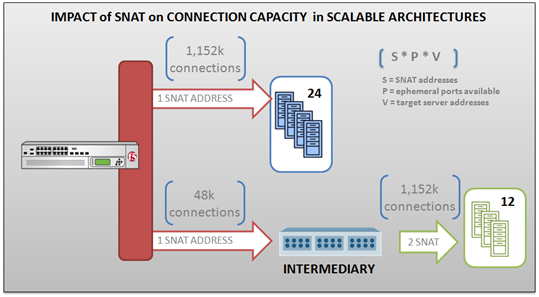
Understanding the relationship between SNAT and connection limitations in full proxy intermediaries. If you’ve previously delved into the world of SNAT (which is becoming increasingly important in large-scale implementations, such as those in the service provider world) you remember that SNAT essentially provides an IP address from which a full-proxy intermediary can communicate with server-side resources and maintain control over the return routing path. There is an interesting relationship between intermediaries that leverage two separate TCP stacks (such as full-proxies) and SNAT in terms of concurrent (open) connections that can be supported by any given “virtual” server (or virtual IP address, as they are often referred to in the industry). The number of ephemeral ports that can be used by any client IP address is 65535. Programmer types will recognize that as a natural limitation imposed by the use of an unsigned short integer (16 bits) in many programming languages. Now, what that means is that for each SNAT address assigned to a virtual IP address, a theoretical total of 65535 connections can be open at any other single address at any given time. This is because in a full-proxy architecture the intermediary is acting as a client and while servers use well-known ports for communication, clients do not. They use ephemeral (temporary) ports, the value of which is communicated to the server in the source port field in the request. Each additional SNAT address available increases the total number of connections by some portion of that space. As you should never use ephemeral ports in the privileged range (port numbers under 1024 are traditionally reserved for firewall and other sanity checkers - see /etc/services on any Unix box) that number can be as many as 64512 available ports between the SNAT address and any other IP address. For example, if a server pool (virtual or iron) has 24 members and assuming the SNAT address is configured to use ephemeral ports in the range of 1024-65535, then a single SNAT address results in a total of 24 x 48k = 1,152k concurrent connections to the pool. If the SNAT is assigned to a virtual server that is targeting a single address (like another virtual server or another intermediate device) then the total connections is 1 x 48k = 48k connections. Obviously this has a rather profound impact on scalability and capacity planning. If you only have one SNAT address available and you need the capabilities of a full-proxy (such as payload inspection inbound and out) you can only support a limited number of connections (and by extension, users). Some solutions provide the means by which these limitations can be mitigated, such as the ability to configure a SNAT pool (a set of dedicated IP addresses) from which SNAT addresses can be automatically pulled and used to automatically increase the number of available ephemeral ports. Running out of ephemeral ports is known as “ephemeral port exhaustion” as you have exhausted the ports available from which a connection to the server resource can be made. In practice the number of ephemeral ports available for any given IP address can be limited by operating system implementations and is always much lower than the 65535 available per IP address. For example, the IANA official suggestion is that ephemeral ports use 49152 through 65535, which means a limitation of 16383 open connections per address. Any full-proxy intermediary that has adopted this suggestion would necessarily require more SNAT addresses to scale an application to more concurrent connections. One of the advantages of a solution implementing a custom TCP/IP stack, then, is that they can ignore the suggestion on ephemeral port assignment typically imposed at the operating system or underlying software layer and increase the range to the full 65535 if desired. Another major advantage is making aggressive use of TIME-WAIT recycling. Normal TCP stacks hold on to the ephemeral port for seconds to minutes after a connection closes. This leads to odd bursting behavior. With proper use of TCP timestamps you can recycle that ephemeral port almost immediately. Regardless, it is an important relationship to remember, especially if it appears that the Load balancer (intermediary) is suddenly the bottleneck when demand increases. It may be that you don’t have enough IP addresses and thus ports available to handle the load. WILS: Write It Like Seth. Seth Godin always gets his point across with brevity and wit. WILS is an ATTEMPT TO BE concise about application delivery TOPICS AND just get straight to the point. NO DILLY DALLYING AROUND. Related Posts All WILS Topics on DevCentral Server Virtualization versus Server Virtualization850Views0likes0CommentsArchitecting Scalable Infrastructures: CPS versus DPS
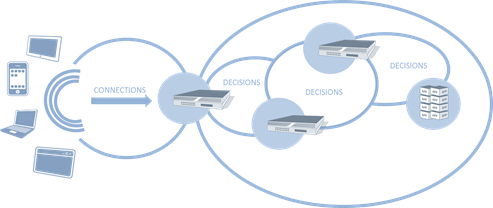
#webperf As we continue to find new ways to make connections more efficient, capacity planning must look to other metrics to ensure scalability without compromising performance. Infrastructure metrics have always been focused on speeds and feeds. Throughput, packets per second, connections per second, etc… These metrics have been used to evaluate and compare network infrastructure for years, ultimately being used as a critical component in data center design. This makes sense. After all, it's not rocket science to figure out that a firewall capable of handling 10,000 connections per second (CPS) will overwhelm a next hop (load balancer, A/V scanner, etc… ) device only capable of 5,000 CPS. Or will it? The problem with old skool performance metrics is they focus on ingress, not egress capacity. With SDN pushing a new focus on both northbound and southbound capabilities, it makes sense to revisit the metrics upon which we evaluate infrastructure and design data centers. CONNECTIONS versus DECISIONS As we've progressed from focusing on packets to sessions, from IP addresses to users, from servers to applications, we've necessarily seen an evolution in the intelligence of network components. It's not just application delivery that's gotten smarter, it's everything. Security, access control, bandwidth management, even routing (think NAC), has become much more intelligent. But that intelligence comes at a price: processing. That processing turns into latency as each device takes a certain amount of time to inspect, evaluate and ultimate decide what to do with the data. And therein lies the key to our conundrum: it makes a decision. That decision might be routing based or security based or even logging based. What the decision is is not as important as the fact that it must be made. SDN necessarily brings this key differentiator between legacy and next-generation infrastructure to the fore, as it's just software-defined but software-deciding networking. When a switch doesn't know what to do with a packet in SDN it asks the controller, which evaluates and makes a decision. The capacity of SDN – and of any modern infrastructure – is at least partially determined by how fast it can make decisions. Examples of decisions: URI-based routing (load balancers, application delivery controllers) Virus-scanning SPAM scanning Traffic anomaly scanning (IPS/IDS) SQLi / XSS inspection (web application firewalls) SYN flood protection (firewalls) BYOD policy enforcement (access control systems) Content scrubbing (web application firewalls) The DPS capacity of a system is not the same as its connection capacity, which is merely the measure of how many new connections a second can be established (and in many cases how many connections can be simultaneously sustained). Such a measure is merely determining how optimized the networking stack of any given solution might be, as connections – whether TCP or UDP or SMTP – are protocol oriented and it is the networking stack that determines how well connections are managed. The CPS rate of any given device tells us nothing about how well it will actually perform its appointed tasks. That's what the Decisions Per Second (DPS) metric tells us. CONSIDERING BOTH CPS and DPS Reality is that most systems will have a higher CPS compared to its DPS. That's not necessarily bad, as evaluating data as it flows through a device requires processing, and processing necessarily takes time. Using both CPS and DPS merely recognizes this truth and forces it to the fore, where it can be used to better design the network. A combined metric helps design the network by offering insight into the real capacity of a given device, rather than a marketing capacity. When we look only at CPS, for example, we might feel perfectly comfortable with a topological design with a flow of similar CPS capacities. But what we really want is to make sure that DPS –> CPS (and vice-versa) capabilities were matched up correctly, lest we introduce more latency than is necessary into a given flow. What we don't want is to end up with is a device with a high DPS rate feeding into a device with a lower CPS rate. We also don't want to design a flow in which DPS rates successively decline. Doing so means we're adding more and more latency into the equation. The DPS rate is a much better indicator of capacity than CPS for designing high-performance networks because it is a realistic measure of performance, and yet a high DPS coupled with a low CPS would be disastrous. Luckily, it is almost always the case that a mismatch in CPS and DPS will favor CPS, with DPS being the lower of the two metrics in almost all cases. What we want to see is as close a CPS:DPS ratio as possible. The ideal is 1:1, of course, but given the nature of inspecting data it is unrealistic to expect such a tight ratio. Still, if the ratio becomes too high, it indicates a potential bottleneck in the network that must be addressed. For example, assume an extreme case of a CPS:DPS of 2:1. The device can establish 10,000 CPS, but only process at a rate of 5,000 DPS, leading to increasing latency or other undesirable performance issues as connections queue up waiting to be processed. Obviously there's more at play than just new CPS and DPS (concurrent connection capability is also a factor) but the new CPS and DPS relationship is a good general indicator of potential issues. Knowing the DPS of a device enables architects to properly scale out the infrastructure to remediate potential bottlenecks. This is particularly true when TCP multiplexing is in play, because it necessarily reduces CPS to the target systems but in no way impacts the DPS. On the ingress, too, are emerging protocols like SPDY that make more efficient use of TCP connections, making CPS an unreliable measure of capacity, especially if DPS is significantly lower than the CPS rating of the system. Relying upon CPS alone – particularly when using TCP connection management technologies - as a means to achieve scalability can negatively impact performance. Testing systems to understand their DPS rate is paramount to designing a scalable infrastructure with consistent performance. The Need for (HTML5) Speed SPDY versus HTML5 WebSockets Y U No Support SPDY Yet? Curing the Cloud Performance Arrhythmia F5 Friday: Performance, Throughput and DPS Data Center Feng Shui: Architecting for Predictable Performance On Cloud, Integration and Performance728Views0likes0Comments