Dashboards for NGINX App Protect
Introduction NGINX App Protect is a new generation WAF from F5 which is built in accordance with UNIX philosophy such that it does one thing well everything else comes from integrations. NGINX App Protect is extremely good at HTTP traffic security. It inherited a powerful WAF engine from BIG-IP and light footprint and high performance from NGINX. Therefore NGINX App Protect brings fine-grained security to all kinds of insertion points where NGINX use to be either on-premises or cloud-based. Therefore NGINX App Protect is a powerful and flexible security tool but without any visualization capabilities which are essential for a good security product. As mentioned above everything besides primary functionality comes from integrations. In order to introduce visualization capabilities, I've developed an integration between NGINX App Protect and ELK stack (Elasticsearch, Logstash, Kibana) as one of the most adopted stacks for log collection and visualization. Based on logs from NGINX App Protect ELK generates dashboards to clearly visualize what WAF is doing. Overview Dashboard Currently, there are two dashboards available. "Overview" dashboard provides a high-level view of the current situation and also allows to discover historical trends. You are free to select any time period of interest and filter data simply by clicking on values right on the dashboard. Table at the bottom of the dashboard lists all requests within a time frame and allows to see how exactly a request looked like. False Positives Dashboard Another useful dashboard called "False Positives" helps to identify false positives and adjust WAF policy based on findings. For example, the chart below shows the number of unique IPs that hit a signature. Under normal conditions when traffic is mostly legitimate "per signature" graphs should fluctuate around zero because legitimate users are not supposed to hit any of signatures. Therefore if there is a spike and amount of unique IPs which hit a signature is close to the total amount of sources then likely there is a false positive and policy needs to be adjusted. Conclusion This is an open-source and community-driven project. The more people contribute the better it becomes. Feel free to use it for your projects and contribute code or ideas directly to the repo. The plan is to make these dashboards suitable for all kinds of F5 WAF flavors including AWAF and EAP. This should be simple because it only requires logstash pipeline adjustment to unify logs format stored in elasticsearch index. If you have a project for AWAF or EAP going on and would like to use dashboards please feel free to develop and create a pull request with an adjusted logstash pipeline to normalize logs from other WAFs. Github repo: https://github.com/464d41/f5-waf-elk-dashboards Feel free to reach me with questions. Good luck!1.9KViews4likes1Comment
Implementing BIG-IP WAF logging and visibility with ELK
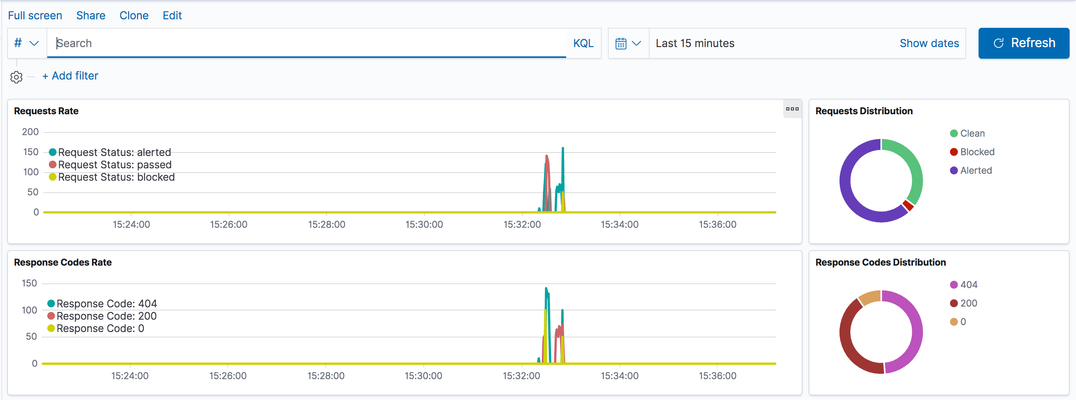
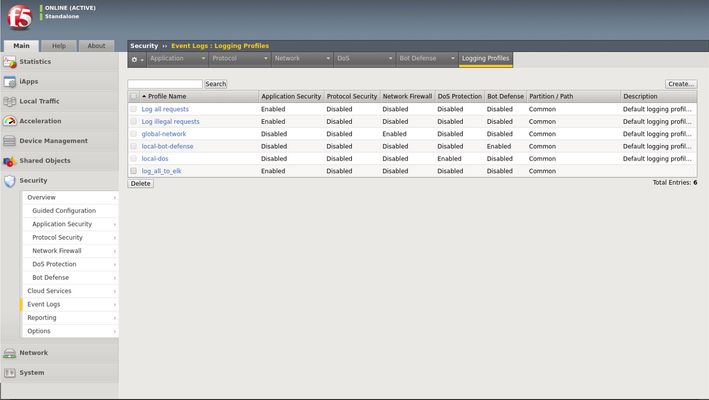
Scope This technical article is useful for BIG-IP users familiar with web application security and the implementation and use of the Elastic Stack.This includes, application security professionals, infrastructure management operators and SecDevOps/DevSecOps practitioners. The focus is for WAF logs exclusively.Firewall, Bot, or DoS mitigation logging into the Elastic Stack is the subject of a future article. Introduction This article focusses on the required configuration for sending Web Application Firewall (WAF) logs from the BIG-IP Advanced WAF (or BIG-IP ASM) module to an Elastic Stack (a.k.a. Elasticsearch-Logstash-Kibana or ELK). First, this article goes over the configuration of BIG-IP.It is configured with a security policy and a logging profile attached to the virtual server that is being protected. This can be configured via the BIG-IP user interface (TMUI) or through the BIG-IP declarative interface (AS3). The configuration of the Elastic Strack is discussed next.The configuration of filters adapted to processing BIP-IP WAF logs. Finally, the article provides some initial guidance to the metrics that can be taken into consideration for visibility.It discusses the use of dashboards and provides some recommendations with regards to the potentially useful visualizations. Pre-requisites and Initial Premise For the purposes of this article and to follow the steps outlined below, the user will need to have at least one BIG-IP Adv. WAF running TMOS version 15.1 or above (note that this may work with previous version but has not been tested).The target BIG-IP is already configured with: A virtual Server A WAF policy An operational Elastic Stack is also required. The administrator will need to have configuration and administrative privileges on both the BIG-IP and Elastic Stack infrastructure.They will also need to be familiar with the network topology linking the BIG-IP with the Elastic Search cluster/infrastructure. It is assumed that you want to use your Elastic Search (ELK) logging infrastructure to gain visibility into BIG-IP WAF events. Logging Profile Configuration An essential part of getting WAF logs to the proper destination(s) is the Logging Profile.The following will go over the configuration of the Logging Profile that sends data to the Elastic Stack. Overview of the steps: Create Logging Profile Associate Logging Profile with the Virtual Server After following the procedure below On the wire, logs lines sent from the BIG-IP are comma separated value pairs that look something like the sample below: Aug 25 03:07:19 localhost.localdomainASM:unit_hostname="bigip1",management_ip_address="192.168.41.200",management_ip_address_2="N/A",http_class_name="/Common/log_to_elk_policy",web_application_name="/Common/log_to_elk_policy",policy_name="/Common/log_to_elk_policy",policy_apply_date="2020-08-10 06:50:39",violations="HTTP protocol compliance failed",support_id="5666478231990524056",request_status="blocked",response_code="0",ip_client="10.43.0.86",route_domain="0",method="GET",protocol="HTTP",query_string="name='",x_forwarded_for_header_value="N/A",sig_ids="N/A",sig_names="N/A",date_time="2020-08-25 03:07:19",severity="Error",attack_type="Non-browser Client,HTTP Parser Attack",geo_location="N/A",ip_address_intelligence="N/A",username="N/A",session_id="0",src_port="39348",dest_port="80",dest_ip="10.43.0.201",sub_violations="HTTP protocol compliance failed:Bad HTTP version",virus_name="N/A",violation_rating="5",websocket_direction="N/A",websocket_message_type="N/A",device_id="N/A",staged_sig_ids="",staged_sig_names="",threat_campaign_names="N/A",staged_threat_campaign_names="N/A",blocking_exception_reason="N/A",captcha_result="not_received",microservice="N/A",tap_event_id="N/A",tap_vid="N/A",vs_name="/Common/adv_waf_vs",sig_cves="N/A",staged_sig_cves="N/A",uri="/random",fragment="",request="GET /random?name=' or 1 = 1' HTTP/1.1\r\n",response="Response logging disabled" Please choose one of the methods below.The configuration can be done through the web-based user interface (TMUI), the command line interface (TMSH), directly with a declarative AS3 REST API call, or with the BIG-IP native REST API.This last option is not discussed herein. TMUI Steps: Create Profile Connect to the BIG-IP web UI and login with administrative rights Navigate to Security >> Event Logs >> Logging Profiles Select “Create” Fill out the configuration fields as follows: Profile Name (mandatory) Enable Application Security Set Storage Destination to Remote Storage Set Logging Format to Key-Value Pairs (Splunk) In the Server Addresses field, enter an IP Address and Port then click on Add as shown below: Click on Create Add Logging Profile to virtual server with the policy Select target virtual server and click on the Security tab (Local Traffic >> Virtual Servers : Virtual Server List >> [target virtualserver] ) Highlight the Log Profile from the Available column and put it in the Selected column as shown in the example below (log profile is “log_all_to_elk”): Click on Update At this time the BIG-IP will forward logs Elastic Stack. TMSH Steps: Create profile ssh into the BIG-IP command line interface (CLI) from the tmsh prompt enter the following: create security log profile [name_of_profile] application add { [name_of_profile] { logger-type remote remote-storage splunk servers add { [IP_address_for_ELK]:[TCP_Port_for_ELK] { } } } } For example: create security log profile dc_show_creation_elk application add { dc_show_creation_elk { logger-type remote remote-storage splunk servers add { 10.45.0.79:5244 { } } } } 3. ensure that the changes are saved: save sys config partitions all Add Logging Profile to virtual server with the policy 1.From the tmsh prompt (assuming you are still logged in) enter the following: modify ltm virtual [VS_name] security-log-profiles add { [name_of_profile] } For example: modify ltm virtual adv_waf_vs security-log-profiles add { dc_show_creation_elk } 2.ensure that the changes are saved: save sys config partitions all At this time the BIG-IP sends logs to the Elastic Stack. AS3 Application Services 3 (AS3) is a BIG-IP configuration API endpoint that allows the user to create an application from the ground up.For more information on F5’s AS3, refer to link. In order to attach a security policy to a virtual server, the AS3 declaration can either refer to a policy present on the BIG-IP or refer to a policy stored in XML format and available via HTTP to the BIG-IP (ref. link). The logging profile can be created and associated to the virtual server directly as part of the AS3 declaration. For more information on the creation of a WAF logging profile, refer to the documentation found here. The following is an example of a pa rt of an AS3 declaration that will create security log profile that can be used to log to Elastic Stack: "secLogRemote": { "class": "Security_Log_Profile", "application": { "localStorage": false, "maxEntryLength": "10k", "protocol": "tcp", "remoteStorage": "splunk", "reportAnomaliesEnabled": true, "servers": [ { "address": "10.45.0.79", "port": "5244" } ] } In the sample above, the ELK stack IP address is 10.45.0.79 and listens on port 5244 for BIG-IP WAF logs.Note that the log format used in this instance is “Splunk”.There are no declared filters and thus, only the illegal requests will get logged to the Elastic Stack.A sample AS3 declaration can be found here. ELK Configuration The Elastic Stack configuration consists of creating a new input on Logstash.This is achieved by adding an input/filter/ output configuration to the Logstash configuration file.Optionally, the Logstash administrator might want to create a separate pipeline – for more information, refer to this link. The following is a Logstash configuration known to work with WAF logs coming from BIG-IP: input { syslog { port => 5244 } } filter { grok { match => { "message" => [ "attack_type=\"%{DATA:attack_type}\"", ",blocking_exception_reason=\"%{DATA:blocking_exception_reason}\"", ",date_time=\"%{DATA:date_time}\"", ",dest_port=\"%{DATA:dest_port}\"", ",ip_client=\"%{DATA:ip_client}\"", ",is_truncated=\"%{DATA:is_truncated}\"", ",method=\"%{DATA:method}\"", ",policy_name=\"%{DATA:policy_name}\"", ",protocol=\"%{DATA:protocol}\"", ",request_status=\"%{DATA:request_status}\"", ",response_code=\"%{DATA:response_code}\"", ",severity=\"%{DATA:severity}\"", ",sig_cves=\"%{DATA:sig_cves}\"", ",sig_ids=\"%{DATA:sig_ids}\"", ",sig_names=\"%{DATA:sig_names}\"", ",sig_set_names=\"%{DATA:sig_set_names}\"", ",src_port=\"%{DATA:src_port}\"", ",sub_violations=\"%{DATA:sub_violations}\"", ",support_id=\"%{DATA:support_id}\"", "unit_hostname=\"%{DATA:unit_hostname}\"", ",uri=\"%{DATA:uri}\"", ",violation_rating=\"%{DATA:violation_rating}\"", ",vs_name=\"%{DATA:vs_name}\"", ",x_forwarded_for_header_value=\"%{DATA:x_forwarded_for_header_value}\"", ",outcome=\"%{DATA:outcome}\"", ",outcome_reason=\"%{DATA:outcome_reason}\"", ",violations=\"%{DATA:violations}\"", ",violation_details=\"%{DATA:violation_details}\"", ",request=\"%{DATA:request}\"" ] } break_on_match => false } mutate { split => { "attack_type" => "," } split => { "sig_ids" => "," } split => { "sig_names" => "," } split => { "sig_cves" => "," } split => { "staged_sig_ids" => "," } split => { "staged_sig_names" => "," } split => { "staged_sig_cves" => "," } split => { "sig_set_names" => "," } split => { "threat_campaign_names" => "," } split => { "staged_threat_campaign_names" => "," } split => { "violations" => "," } split => { "sub_violations" => "," } } if [x_forwarded_for_header_value] != "N/A" { mutate { add_field => { "source_host" => "%{x_forwarded_for_header_value}"}} } else { mutate { add_field => { "source_host" => "%{ip_client}"}} } geoip { source => "source_host" } } output { elasticsearch { hosts => ['localhost:9200'] index => "big_ip-waf-logs-%{+YYY.MM.dd}" } } After adding the configuration above to the Logstash parameters, you will need to restart the Logstash instance to take the new logs into configuration.The sample above is also available here. The Elastic Stack is now ready to process the incoming logs.You can start sending traffic to your policy and start seeing logs populating the Elastic Stack. If you are looking for a test tool to generate traffic to your Virtual Server, F5 provides a simpleWAF tester tool that can be found here. At this point, you can start creating dashboards on the Elastic Stack that will satisfy your operational needs with the following overall steps: ·Ensure that the log index is being created (Stack Management >> Index Management) ·Create a Kibana Index Pattern (Stack Management>>Index patterns) ·You can now peruse the logs from the Kibana discover menu (Discover) ·And start creating visualizations that will be included in your Dashboards (Dashboards >> Editing Simple WAF Dashboard) A complete Elastic Stack configuration can be found here – note that this can be used with both BIG-IP WAF and NGINX App Protect. Conclusion You can now leverage the widely available Elastic Stack to log and visualize BIG-IP WAF logs.From dashboard perspective it may be useful to track the following metrics: -Request Rate -Response codes -The distribution of requests in term of clean, blocked or alerted status -Identify the top talkers making requests -Track the top URL’s being accessed -Top violator source IP An example or the dashboard might look like the following:11KViews4likes6CommentsL7 DoS Protection with NGINX App Protect DoS
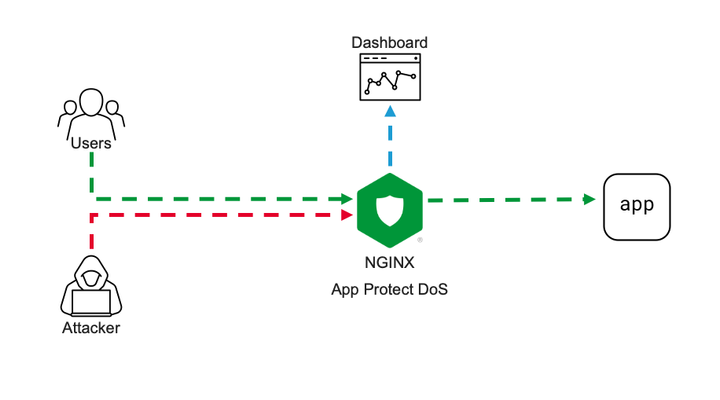
Intro NGINX security modules ecosystem becomes more and more solid. Current App Protect WAF offering is now extended by App Protect DoS protection module. App Protect DoS inherits and extends the state-of-the-art behavioral L7 DoS protection that was initially implemented on BIG-IPand now protects thousands of workloads around the world. In this article, I’ll give a brief explanation of underlying ML-based DDoS prevention technology and demonstrate few examples of how precisely it stops various L7 DoS attacks. Technology It is important to emphasize the difference between the general volumetric-based protection approach that most of the market uses and ML-based technology that powers App Protect DoS. Volumetric-based DDoS protection is an old and well-known mechanism to prevent DDoS attacks. As the name says, such a mechanism counts the number of requests sharing the same source or destination, then simply drops or applies rate-limiting after some threshold crossed. For instance, requests sourcing the same IP are dropped after 100 RPS, requests going to the same URL after 200 RPS, and rate-limiting kicks in after 500 RPS for the entire site. Obviously, the major drawback of such an approach is that the selection criterion is too rough. It can causeerroneous drops of valid user requests and overall service degradation. The phenomenon when a security measure blocks good requests is called a “false positive”. App Protect DoS implements much more intelligent techniques to detect and fight off DDoS attacks. At a high level, it monitors all ongoing traffic and builds a statistical model in other words a baseline in aprocesscalled “learning”. The learning process almost never stops, thereforea baseline automatically adjusts to the current web application layout, a pattern of use, and traffic intensity. This is important because it drastically reduces maintenance cost and reaction speed for the solution. There is no more need to manually customize protection configuration for every application or traffic change. Infinite learning produces a legitimate question. Why can’t the system learn attack traffic as a baseline and how does it detect an attack then? To answer this question let us define what a DDoS attack is. A DDoS attack is a traffic stream that intends to deny or degrade access to a service. Note, the definition above doesn’t focus on the amount of traffic. ‘Low and slow’ DDoS attacks can hurt a service as severely as volumetric do. Traffic is only considered malicious when a service level degrades. So, this means that attack traffic can become a baseline, but it is not a big deal since protected service doesn’t suffer. Now only the “service degradation” term separates us from the answer. How does the App Protect DoS measure a service degradation? As humans, we usually measure the quality of a web service in delays. The longer it takes to get a response the more we swear. App Protect DoS mimics human behavior by measuring latency for every single transaction and calculates the level of stress for a service. If overall stress crosses a threshold App Protect DoS declares an attack. Think of it; a service degradation triggers an attack signal, not a traffic volume. Volume is harmless if an application servermanages to respond quickly. Nice! The attack is detected for a solid reason. What happens next? First of all, the learning process stops and rolls back to a moment when the stress level was low. The statistical model of the traffic that was collected during peacetime becomes a baseline for anomaly detection. App Protect DoS keeps monitoring the traffic during an attack and uses machine learning to identify the exact request pattern that causes a service degradation. Opposed to old-school volumetric techniques it doesn’t use just a single parameter like source IP or URL, but actually builds as accurate as possible signature of entire request that causes harm. The overall number of parameters that App Protect DoS extracts from every request is in the dozens. A signature usually contains about a dozen including source IP, method, path, headers, payload content structure, and others. Now you can see that App Protect DoS accuracy level is insane comparing to volumetric vectors. The last part is mitigation. App Protect DoS has a whole inventory of mitigation tools including accurate signatures, bad actor detection, rate-limiting or even slowing down traffic across the board, which it usesto return service. The strategy of using those is convoluted but the main objective is to be as accurate as possible and make no harm to valid users. In most cases, App Protect DoS only mitigates requests that match specific signatures and only when the stress threshold for a service is crossed. Therefore, the probability of false positives is vanishingly low. The additional beauty of this technology is that it almost doesn’t require any configuration. Once enabled on a virtual server it does all the job "automagically" and reports back to your security operation center. The following lines present a couple of usage examples. Demo Demo topology is straightforward. On one end I have a couple of VMs. One of them continuously generates steady traffic flow simulating legitimate users. The second one is supposed to generate various L7 DoS attacks pretending to be an attacker. On the other end, one VM hosts a demo application and another one hosts NGINX with App Protect DoS as a protection tool. VM on a side runs ELK cluster to visualize App Protect DoS activity. Workflow of a demo aims to showcase a basic deployment example and overall App Protect DoS protection technology. First, I’ll configure NGINX to forward traffic to a demo application and App Protect DoS to apply for DDoS protection. Then a VM that simulates good users will send continuous traffic flow to App Protect DoS to let it learn a baseline. Once a baseline is established attacker VM will hit a demo app with various DoS attacks. While all this battle is going on our objective is to learn how App Protect DoS behaves, and that good user's experience remains unaffected. Similar to App Protect WAF App Protect DoS is implemented as a separate module for NGINX. It installs to a system as an apt/yum package. Then hooks into NGINX configuration via standard “load_module” directive. load_module modules/ngx_http_app_protect_dos_module.so; Once loaded protection enables under either HTTP, server, or location sections. Depending on what would you like to protect. app_protect_dos_enable [on|off] By default, App Protect DoS takes a protection configuration from a local policy file “/etc/nginx/BADOSDefaultPolicy.json” { "mitigation_mode" : "standard", "use_automation_tools_detection": "on", "signatures" : "on", "bad_actors" : "on" } As I mentioned before App Protect DoS doesn’t require complex config and only takes four parameters. Moreover, default policy covers most of the use cases therefore, a user only needs to enable App Protect DoS on a protected object. The next step is to simulate good users’ traffic to let App Protect DoS learn a good traffic pattern. I use a custom bash script that generates about 6-8 requests per second like an average surfing activity. While inspecting traffic and building a statistical model of good traffic App Protect DoS sends logs and metrics to Elasticsearch so we can monitor all its activity. The dashboard above represents traffic before/after App Protect DoS, degree of application stress, and mitigations in place. Note that the rate of client-side transactions matches the rate of server-side transactions. Meaning that all requests are passing through App Protect DoS and there are not any mitigations applied. Stress value remains steady since the backend easily handles the current rate and latency does not increase. Now I am launching an HTTP flood attack. It generates several thousands of requests per second that can easily overwhelm an unprotected web server. My server has App Protect DoS in front applying all its’ intelligence to fight off the DoS attack. After a few minutes of running the attack traffic, the dashboard shows the following situation. The attack tool generated roughly 1000RPS. Two charts on the left-hand side show that all transactions went through App Protect DoS and were reaching a demo app for a couple of minutes causing service degradation. Right after service stress has reached a threshold an attack was declared (vertical red line on all charts). As soon as the attack has been declared App Protect DoS starts to apply mitigations to resume the service back to life. As I mentioned before App Protect DoS tries its best not to harm legitimate traffic. Therefore, it iterates from less invasive mitigations to more invasive. During the first several seconds when App Protect DoS just detected an attack and specific anomaly signature is not calculated yet. App Protect DoS applies an HTTP redirect to all requests across the board. Such measure only adds a tiny bit of latency for a web browser but allows it to quickly filter out all not-so-intelligent attack tools that can’t follow redirects. In less than a minute specific anomaly signature gets generated. Note how detailed it is. The signature contains 11 attributes that cover all aspects: method, path, headers, and a payload. Such a level of granularity and reaction time is not feasible neither for volumetric vectors nor a SOC operator armed with a regex engine. Once a signature is generated App Protect DoS reduces the scope of mitigation to only requests that match the signature. It eliminates a chance to affect good traffic at all. Matching traffic receives a redirect and then a challenge in case if an attacker is smart enough to follow redirects. After few minutes of observation App Protect DoS identifies bad actors since most of the requests come from the same IP addresses (right-bottom chart). Then switches mitigation to bad actor challenge. Despite this measure hits all the same traffic it allows App Protect DoS to protect itself. It takes much fewer CPU cycles to identify a target by IP address than match requests against the signature with 11 attributes. From now on App Protect DoS continues with the most efficient protection until attack traffic stops and server stress goes away. The technology overview and the demo above expose only a tiny bit of App Protect DoS protection logic. A whole lot of it engages for more complicated attacks. However, the results look impressive. None of the volumetric protection mechanisms or even a human SOC operator can provide such accurate mitigation within such a short reaction time. It is only possible when a machine fights a machine.4.2KViews1like3CommentsWAF Policy Editor - a Web-Based Tool to Configure a Declarative WAF Policy
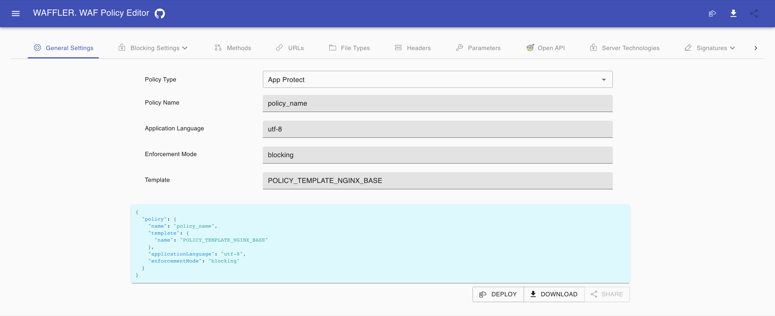
Introduction The declarative policy is a great step forward to unify WAF configuration across F5 WAFs. However, the policy format is JSON; easy for machines to deal with but not so easy for humans. Currently, the process of putting together a declarative WAF policy requires a human to carefully read through tons of online documentation, figure out what features need to be enabled, and how each feature works. Once understood, the typical human will readone more time to examine configuration examples and then type out the JSON structure, without typos. Any typo may cause theWAF engine to reject a policy. Not a terriblyuser-friendly procedure. The following project exists to address this kind of complexity. The Project WAF Policy Editoris a web-based tool that implements a UI to put together a declarative WAF policy. The basic concept is simple. Everything you configure in the UI will translate into aJSON file automatically and vice versa. The following screenshot gives an overview of the UI. The menu ribbon at the very top lists all of the supported features. Input fields in the middle configure a policy. The text area at the bottom represents the current policy state. The user is free to modify a policy via either input fields or directly in the JSON. Both representations are synchronized. Another important aspect is that the policy editor continuously verifies policy validity and notifies a user if the configuration doesn't comply with a policy schema. For instance, the screenshot below informs a user that an application language field can only contain specific values. The Workflows There are few workflows for which this tool is designed. The basic workflow is when a user configures a policy from scratch using the UI to set up desired features. Once done a policy can be simply either copied or downloaded as a file. The second approach allows modifying an existing policy. It is similar to previous, however, once a user pastes an existing policy JSON to the text area it gets automatically translated to UI so a user can make desired modifications. The last workflow allows to modify the existing policy as well but instead of pasting a policy a user can simply reference it as a query string parameter "ref". This is handy when a policy is locatedin a repository.Example link Even though it is just a small community team working on this project it actively evolving. Every week new features arrive. If you find the project useful pleasegive it a tryand leave your feedback right toGitHub issues. Your feedback is critical in order to steer as many efforts as possible tothe most votedfeatures.1.5KViews1like0CommentsCloud Template for App Protect WAF
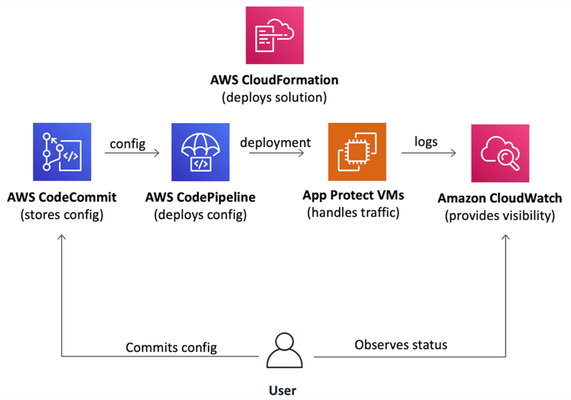
Introduction Everybody needs a WAF. However, when it gets to a deployment stage a team usually realizes that production-grade deployment going to be far more complex than a demo environment. In the case of a cloud deployment VPC networking, infrastructure security, VM images, auto-scaling, logging, visibility, automation, and many more topics require detailed analysis. Usually, it takes at least a few weeks for an average team to design and implement a production-grade WAF in a cloud. That is the one side of the problem. Additionally, cloud deployment best practices are the same for everyone, therefore most of well-made WAF deployments follow a similar path and become similar at the end. The statements above bring us to an obvious conclusion that proper WAF deployment can be templatized. So a team doesn’t spend time on deployment and maintenance but starts to use a WAF from day zero. The following paragraphs introduce a project that implements a Cloud Formation template to deploy production-grade WAF in AWS cloud just in a few clicks. Project (GitHub) On a high level, the project implements a Cloud Formation template that automatically deploys a production-grade WAF to AWS cloud. The template aims to follow cloud deployment best practices to set up a complete solution that is fully automated, requires minimum to no infrastructure management, therefore, allows a team to focus on application security. The following picture represents the overall solution structure. The solution includes a definition of three main components. Auto-scalingdata planebased on official NGINX App Protect AWS AMI images. Git repository as the source of data plane and securityconfiguration. Visibilitydashboards displaying the WAF health and security data. Therefore it becomes a complete and easy-to-use solution to protect applications whether they run in AWS or in any other location. Data Plane: Data plane auto-scales based on the amount of incoming traffic and uses official NGINX App Protect AWS AMIs to spin up new VM instances. That removes the operational headache and optimizes costs since WAF dynamically adjusts the amount of computing resources and charges a user on an as-you-go basis. Configuration Plane: Solution configuration follows GitOps principles. The template creates the AWS CodeCommit git repository as a source of forwarding and security configuration. AWS CodeDeploy pipeline automatically delivers a configuration across all data plane VMs. Visibility: Alongside the data plane and configuration repository the template sets up a set of visibility dashboards in AWS CloudWatch. Data plane VMs send logs and metrics to CloudWatch service that visualizes incoming data as a set of charts and tables showing WAF health and security violations. Therefore these three components form a complete WAF solution that is easy to deploy, doesn't impose any operational headache and provides handy interfaces for WAF configuration and visibility right out of the box. Demo As mentioned above, one of the main advantages of this project is the ease of WAF deployment. It only requires downloading the AWS CloudFormation template file from the project repository and deploy it whether via AWS Console or AWS CLI. Template requests a number of parameters, however, all they are optional. As soon as stack creation is complete WAF is ready to use. Template outputs contain WAF URL and pointer to configuration repository. By default the WAF responds with static page. As a next step, I'll put this cloud WAF instance in front of a web application. Similar to any other NGINX instance, I'll configure it to forward traffic to the app and inspect all requests with App Protect WAF. As mentioned before, all config lives in a git repo that resides in the AWS CodeCommit service. I'm adjusting the NGINX configuration to forward traffic to the protected application. Once committed to the repo, a pipeline delivers the change to all data plane VMs. Therefore all traffic redirects to a protected application (screenshot below is not of a real company, and used for demo purposes only). Similar to NGINX configuration App Protect policy resides in the same repository. Similarly, all changes reflect running VMs. Once the configuration is complete, a user can observe system health and security-related data via pre-configured AWS CloudWatch dashboards. Outline As you can see, the use of a template to deploy a cloud WAF allows to significantly reduce time spent on WAF deployment and maintenance. Handy interfaces for configuration and visibility turn this project into a boxed solution allowing a user to easily operate a WAF and focus on application security. Please comment if you find useful to have this kind of solution in major public clouds marketplaces. It is a community project so far, and we need as much feedback as possible to steer one properly. Feel free to give it a try and leave feedback here or at the project's git repository. P.S.: Take a look to another community project that contributes to F5 WAF ecosystem: WAF Policy Editor639Views3likes0CommentsDeploying NGINXplus with AppProtect in Tanzu Kubernetes Grid
Introduction Tanzu Kubernetes Grid (aka TKG) is VMware's main Kubernetes offering. Although Tanzu Kubernetes Grid is a certified conformant Kubernetes offering the different Kubernetes offerings can be customized in different ways. In the case of TKG a remarkable feature is the use of Pod Security Policies by default. TKG clusters are very easily spin-up in either public or private clouds by means of creating a single declaration YAML file such as the following: apiVersion: run.tanzu.vmware.com/v1alpha1 kind: TanzuKubernetesCluster metadata: name: tkg1 namespace: tkg1 spec: distribution: version: v1.18.15+vmware.1-tkg.1.600e412 topology: controlPlane: count: 1 class: best-effort-medium storageClass: vsan-default-storage-policy workers: count: 1 class: best-effort-medium storageClass: vsan-default-storage-policy As you can see from the schema a TKG cluster is deployed just as another Kubernetes resource. How does it work? In the case of public clouds, these TanzuKubernetesCluster resources are instantiated from a bootstrap cluster named "management Kubernetes cluster" whilst when using vSphere with Tanzu, the TanzuKubernetesCluster resources are instantiated from vSphere with Tanzu's supervisor cluster. In this blog post it will be shown an example from start to end: Creating wildcard certificate from custom CA with easy-rsa. Enabling Harbor registry. Installing NGINXplus with AppProtect. Using NGINXplus Ingress Controller without AppProtect. Adding AppProtect to an Ingress resource. AppProtect is an NGINXplus module for WAF and Bot protection based on market leading F5 BIG-IP's ASM. AppProtect provides enhanced capabilities and performance for those who require more than what mod_auth provides. We will finish with two relevant considerations: Updating NGINXplus Ingress controller using Helm. This is used for example for scaling-out NGINXplus hence improving the overall performance. Using NGINXplus alongside with other Ingress Controllers (such as Contour). Prerequisites You need an NGINXplus license which can be retrieved from https://www.nginx.com/free-trial-request-nginx-ingress-controller/. This license is in practice a cert/key pair with the file names nginx-repo.{crt,key} referenced later on. The following software needs to be present in your in your machine: Docker v18.09+ GNU Make git Helm3 OpenSSL https://github.com/OpenVPN/easy-rsa.git Create a wildcard certificate with easy-rsa In the next steps it will be created a Certificate Authority (CA) and from it a wildcard certificate/key pair which will be loaded into Kubernetes as a TLS secret. This wildcard certificate will be used by all the services which will expose through Ingress. Retrieve easy-rsa and initialize a CA (output summarized): $ git clone https://github.com/OpenVPN/easy-rsa.git $ cd easyrsa3/ $ ./easyrsa init-pki $ ./easyrsa build-ca Generate the wildcard key/cert pair (output summarized): $ ./easyrsa gen-req wildcard Common Name (eg: your user, host, or server name) [wildcard]:*.tkg.bd.f5.com Keypair and certificate request completed. Your files are: req: /Users/alonsocamaro/Documents/VMware-Tanzu/tanzu/easy-rsa/easyrsa3/pki/reqs/wildcard.req key: /Users/alonsocamaro/Documents/VMware-Tanzu/tanzu/easy-rsa/easyrsa3/pki/private/wildcard.key $ ./easyrsa sign-req server wildcard Request subject, to be signed as a server certificate for 825 days: subject= commonName= *.tkg.bd.f5.com The Subject's Distinguished Name is as follows commonName:ASN.1 12:'*.tkg.bd.f5.com' Certificate is to be certified until Aug 21 15:58:24 2023 GMT (825 days) Write out database with 1 new entries Data Base Updated Certificate created at: /Users/alonsocamaro/Documents/VMware-Tanzu/tanzu/easy-rsa/easyrsa3/pki/issued/wildcard.crt The certificate is stored in ./pki/issued/wildcard.crt and the key is stored encrypted in pki/private/wildcard.key. Import these into a Kubernetes secret using the next steps: $ openssl rsa -in ./pki/private/wildcard.key -out ./pki/private/wildcard-unencrypted.key Enter pass phrase for ./pki/private/wildcard.key: writing RSA key $ kubectl create ns ingress-nginx $ kubectl create -n ingress-nginx secret tls wildcard-tls --key ./pki/private/wildcard-unencrypted.key --cert ./pki/issued/wildcard.crt secret/wildcard-tls created $ rm ./pki/private/wildcard-unencrypted.key As you might have noticed the secret is loaded in the namespace ingress-nginx where NGINXplus Ingress Controller will be installed. Enable your image registry in Tanzu You need an image registry. When using vSphere with Tanzu this comes with Harbor. In this case you have to follow the next steps: Enable Harbor by following https://docs.vmware.com/en/VMware-vSphere/7.0/vmware-vsphere-with-tanzu/GUID-AE24CF79-3C74-4CCD-B7C7-757AD082D86A.html. Trust Harbor's self-signed certificate: In the case of using vSphere with Tanzu Update 2 (U2) follow https://tanzu.vmware.com/content/blog/how-to-set-up-harbor-registry-self-signed-certificates-tanzu-kubernetes-clusters. If using a previous version follow https://cormachogan.com/2020/06/23/integrating-embedded-vsphere-with-kubernetes-harbor-registry-with-tkg-guest-clusters/ with the caveat that you will need to re-apply the changes if you upgrade the TKG cluster. Alternatively, you could also use your own certificates and follow https://docs.vmware.com/en/VMware-Tanzu-Kubernetes-Grid/1.3/vmware-tanzu-kubernetes-grid-13/GUID-cluster-lifecycle-secrets.html#trust-custom-ca-certificates-on-cluster-nodes-3. Installing NGINXplus Ingress Controller This blog shows step by step everything that needs to be done to create an AppProtect-secured Ingress Controller with a wildcard certificate that will created as well. This blog only assumes that the TKG cluster is up and running. If you want to perform further customizations you can check https://docs.nginx.com/nginx-ingress-controller and https://docs.nginx.com/nginx-app-protect/configuration. In this blog it has been used TKG 1.3 in vSphere with Tanzu with NSX-T. The steps are similar when using any other supported TKG environment. Build the NGINXplus DOCKER image Define the registry endpoint and namespace where the TKG cluster will be deployed: $ REGISTRY=<registry IP or FQDN> $ NS=<your namespace> Log in the registry $ docker login $REGISTRY Username: <your user> Password: <your password> Login Succeeded Retrieve NGINXplus $ git clone https://github.com/nginxinc/kubernetes-ingress/ $ cd kubernetes-ingress $ git checkout v1.11.1 Copy the license files into base folder of NGINXplus $ cp $LICDIR/nginx-repo.{crt,key} . Build the image $ make debian-image-nap-plus PREFIX=$REGISTRY/$NS/nginx-plus-ingress TARGET=container Docker version 19.03.8, build afacb8b docker build --build-arg IC_VERSION=1.11.1-32745366 --build-arg GIT_COMMIT=32745366 --build-arg VERSION=1.11.1 --target container -f build/Dockerfile -t 10.105.210.67/tkg1/nginx-plus-ingress:1.11.1 . --build-arg BUILD_OS=debian-plus-ap --build-arg PLUS=-plus --secret id=nginx-repo.crt,src=nginx-repo.crt --secret id=nginx-repo.key,src=nginx-repo.key [+] Building 4.9s (24/24) FINISHED After this we can verify the image is ready in our local docker: $ docker images REPOSITORYTAGIMAGE IDCREATEDSIZE $REGISTRY/$NS/nginx-plus-ingress1.11.170113ec3891435 minutes ago626MB If we wanted to push it into another namespace we would perform an image tag operation as follows: docker image tag 70113ec38914 $REGISTRY/$ANOTHERNS/nginx-plus-ingress:1.11.1 Upload the image into the repository: make push PREFIX=$REGISTRY/$NS/nginx-plus-ingress Configure NGINXplus installation Switch to the helm chart folder cd deployments/helm-chart Make a backup of the default nginx-plus config file cp values-plus.yaml values-plus.yaml.orig We will edit the file values-plus.yaml as follows in order to: Enable AppProtect Allow to specify a wildcard TLS certificate that we will use for all the services. Expose NGINXplus using a LoadBalancer with a Cluster externalTrafficPolicy. Exposing NGINXplus (or any other Ingress Controller such as Contour) using Cluster externalTrafficPolicy is required given that the NSX-T native load balancer doesn't perform any health checking when creating a Service of Type LoadBalancer. We will see how to improve this in future blogs with the use of BIG-IP. controller: nginxplus: true image: repository: nginx-plus-ingress tag: "1.11.1" service: externalTrafficPolicy: Cluster appprotect: ## Enable the App Protect module in the Ingress Controller. enable: true wildcardTLS: ## The base64-encoded TLS certificate for every Ingress host that has TLS enabled but no secret specified. ## If the parameter is not set, for such Ingress hosts NGINX will break any attempt to establish a TLS connection. cert: "" ## The base64-encoded TLS key for every Ingress host that has TLS enabled but no secret specified. ## If the parameter is not set, for such Ingress hosts NGINX will break any attempt to establish a TLS connection. key: "" ## The secret with a TLS certificate and key for every Ingress host that has TLS enabled but no secret specified. ## The value must follow the following format: `<namespace>/<name>`. ## Used as an alternative to specifying a certificate and key using `controller.wildcardTLS.cert` and `controller.wildcardTLS.key` parameters. ## Format: <namespace>/<secret_name> secret: ingress-nginx/wildcard-tls This file can also be found in https://raw.githubusercontent.com/f5devcentral/f5-bd-tanzu-tkg-nginxplus/main/values-plus.yaml Apply the required PodSecurityPolicy before NGINXplus installation The next step creates a PodSecurityPolicy which is required by Tanzu Kubernetes Grid and it is bound to the Service Account ingress-nginx used in the regular NGINXplus install. $ kubectl apply -f https://raw.githubusercontent.com/f5devcentral/f5-bd-tanzu-tkg-nginxplus/main/nginx-psp.yaml podsecuritypolicy.policy/ingress-nginx created clusterrole.rbac.authorization.k8s.io/ingress-nginx-psp created clusterrolebinding.rbac.authorization.k8s.io/ingress-nginx-psp created Install NGINXplus Ingress controller using Helm From the deployments/helm-chart directory of the downloaded NGINXplus, it is just needed to run the next command: $ helm -n ingress-nginx install ingress-nginx -f values-plus.yaml . NAME: ingress-nginx LAST DEPLOYED: Mon May 17 15:16:20 2021 NAMESPACE: ingress-nginx STATUS: deployed REVISION: 1 TEST SUITE: None NOTES: The NGINX Ingress Controller has been installed. Checking the resulting installation When checking the resulting resources we can see that by default a single POD is created. We can scale up/down this as required by using Helm. This will be shown later on. Note also that by default the NGINXplus Ingress Controller is automatically exposed using the Service Type LoadBalancer resource which configures an external load balancer. In this case the external load balancer is NSX-T's native LB as shown in the screenshot. below When using vSphere networking this would have been HAproxy by default. In next blogs we will show how to use F5 BIG-IP in TKG clusters instead. $ kubectl -n ingress-nginx get all NAMEREADYSTATUSRESTARTSAGE pod/ingress-nginx-nginx-ingress-7d4587b44c-n9b8l1/1Running016h NAMETYPECLUSTER-IPEXTERNAL-IPPORT(S)AGE service/ingress-nginx-nginx-ingressLoadBalancer100.69.127.6610.105.210.6880:30527/TCP,443:31185/TCP16h NAMEREADYUP-TO-DATEAVAILABLEAGE deployment.apps/ingress-nginx-nginx-ingress1/11116h NAMEDESIREDCURRENTREADYAGE replicaset.apps/ingress-nginx-nginx-ingress-7d4587b44c11116h In the next screenshots we can see the resulting configuration in NSX-T: Both pools for port 80 and port 443 point to the worker's node addresses. This means that the traffic flow will be NSX-T LB -> ClusterIP -> Ingress Controller's POD address (in the same or in another node). This is the case of any regular Ingress Controller including TKG's provided Contour. In next blogs it will be shown how these many layers of indirection can be bypassed using F5 BIG-IP. Using NGINXplus Ingress Controller without AppProtect Creating a regular Ingress resource In this initial example we will create two services (coffee and tea) which will be exposed with an Ingress resource called cafe-ingress. This will expose the services in the URL https://cafe.tkg.bd.f5.com/coffee and https://cafe.tkg.bd.f5.com/tea using the previously created wildcard certificate for *.tkg.bd.f5.com as depicted in the next diagram. To create this setup run the following commands: $ kubectl create ns test $ kubectl -n test -f https://raw.githubusercontent.com/f5devcentral/f5-bd-tanzu-tkg-nginxplus/main/cafe-rbac.yaml $ kubectl -n test -f https://raw.githubusercontent.com/f5devcentral/f5-bd-tanzu-tkg-nginxplus/main/cafe.yaml $ kubectl -n test -f https://raw.githubusercontent.com/f5devcentral/f5-bd-tanzu-tkg-nginxplus/main/cafe-ingress.yaml This is the same example provided in the official NGINXplus documentation but we add the cafe-rbac.yaml declaration which creates the necessary PodSecurity policies and bindings for TKG. To verify the result first we will check the Ingress resource itself: $ kubectl -n test get ingress NAMECLASSHOSTSADDRESSPORTSAGE cafe-ingressnginxcafe.tkg.bd.f5.com10.105.210.6880, 4433m44s where we can observe that the IP address is the one of the external loadbalancer seen before. To verify it is all working as expected we will use curl as follows: $ curl --cacert ca-tkg.bd.f5.com.crt --resolve cafe.tkg.bd.f5.com:443:10.105.210.68 https://cafe.tkg.bd.f5.com/coffee Server address: 100.96.1.16:8080 Server name: coffee-86954d94fd-pnvpq Date: 18/May/2021:16:18:59 +0000 URI: /coffee Request ID: 63964930a2d1038af5f204ef8fbe91fc which has the following key parameters: Use --cacert to specify our CA crt file previously created Use --resolve to allow curl resolve the FQDN of the request Adding AppProtect to an Ingress resource Additional configuration Our deployed NGINXplus has AppProtect built-in. It is up to the user of the Ingress resource if it wants to enable it, on a per Ingress basis. In our example we will apply the AppProtect security policies in the user namespace "test". We will also create a syslog store in the ingress-nginx namespace. All these can be customized. Ultimately, the user just needs to add the following annotations in order to secure the cafe site: annotations: appprotect.f5.com/app-protect-policy: "test/dataguard-alarm" appprotect.f5.com/app-protect-enable: "True" appprotect.f5.com/app-protect-security-log-enable: "True" appprotect.f5.com/app-protect-security-log: "test/logconf" appprotect.f5.com/app-protect-security-log-destination: "syslog:server=100.70.175.24:514" The custom AppProtect policy used in this example contains DataGuard protection for Credit Card Number, US Social Security number leaks and a custom signature. It is also defined where to send the AppProtect logs. These are sent in SYSLOG/TCP mode independently of the regular logs generated by NGINXplus. To make all these happen first we will create the syslog server: kubectl apply -n ingress-nginx -f https://raw.githubusercontent.com/f5devcentral/f5-bd-tanzu-tkg-nginxplus/main/syslog-rbac.yaml kubectl apply -n ingress-nginx -f https://raw.githubusercontent.com/f5devcentral/f5-bd-tanzu-tkg-nginxplus/main/syslog.yaml Next, we will create the AppProtect policies: kubectl apply -n test -f https://raw.githubusercontent.com/f5devcentral/f5-bd-tanzu-tkg-nginxplus/main/ap-apple-uds.yaml kubectl apply -n test -f https://raw.githubusercontent.com/f5devcentral/f5-bd-tanzu-tkg-nginxplus/main/ap-dataguard-alarm-policy.yaml kubectl apply -n test -f https://raw.githubusercontent.com/f5devcentral/f5-bd-tanzu-tkg-nginxplus/main/ap-logconf.yaml Finally we will add the above annotations to the Ingress resource. For that, we will need to get SYSLOG's POD address and replace it in the cafe-ingress-ap.yaml definition. curl -O https://raw.githubusercontent.com/f5devcentral/f5-bd-tanzu-tkg-nginxplus/main/cafe-ingress-ap.yaml SYSLOG_IP=<IP address of syslog's POD> sed -e "s/SYSLOG/$SYSLOG_IP/" cafe-ingress-ap.yaml > cafe-ingress-ap-syslog.yaml kubectl apply -n test -f cafe-ingress-ap-syslog.yaml Note: it might take few seconds to make the AppProtect configuration effective. Verifying AppProtect Run the following command to watch the requests live as handled by AppProtect: kubectl -n ingress-nginx exec -it <SYSLOG POD NAME> -- tail -f /var/log/messages Send a request that triggers the custom signature: curl --cacert ca-tkg.bd.f5.com.crt --resolve cafe.tkg.bd.f5.com:443:10.105.210.69 "https://cafe.tkg.bd.f5.com/coffee/" -X POST -d "apple" You should see a log similar to the following one in the syslog logs: May 24 13:43:23 ingress-nginx-nginx-ingress-7d4587b44c-wvrxs ASM:attack_type="Non-browser Client,Brute Force Attack",blocking_exception_reason="N/A",date_time="2021-05-24 13:43:23",dest_port="443",ip_client="10.105.210.69",is_truncated="false",method="POST",policy_name="dataguard-alarm",protocol="HTTPS",request_status="blocked",response_code="0",severity="Critical",sig_cves="N/A",sig_ids="300000000",sig_names="Apple_medium_acc [Fruits]",sig_set_names="{apple_sigs}",src_port="4096",sub_violations="N/A",support_id="15704273797572010868",threat_campaign_names="N/A",unit_hostname="ingress-nginx-nginx-ingress-7d4587b44c-wvrxs",uri="/coffee/",violation_rating="3",vs_name="24-cafe.tkg.bd.f5.com:9-/coffee",x_forwarded_for_header_value="N/A",outcome="REJECTED",outcome_reason="SECURITY_WAF_VIOLATION",violations="Attack signature detected,Bot Client Detected",violation_details="<?xml version='1.0' encoding='UTF-8'?><BAD_MSG><violation_masks><block>10000000200c00-3030430000070</block><alarm>2477f0ffcbbd0fea-8003f35cb000007c</alarm><learn>200000-20</learn><staging>0-0</staging></violation_masks><request-violations><violation><viol_index>42</viol_index><viol_name>VIOL_ATTACK_SIGNATURE</viol_name><context>request</context><sig_data><sig_id>300000000</sig_id><blocking_mask>7</blocking_mask><kw_data><buffer>YXBwbGU=</buffer><offset>0</offset><length>5</length></kw_data></sig_data></violation></request-violations></BAD_MSG>",bot_signature_name="curl",bot_category="HTTP Library",bot_anomalies="N/A",enforced_bot_anomalies="N/A",client_class="Untrusted Bot",request="POST /coffee/ HTTP/1.1\r\nHost: cafe.tkg.bd.f5.com\r\nUser-Agent: curl/7.64.1\r\nAccept: */*\r\nContent-Length: 5\r\nContent-Type: application/x-www-form-urlencoded\r\n\r\napple" Updating NGINXplus Ingress controller using Helm By default a single NGINXplus instance is created, if you want to increase the performance of it, scaling-out is as simple as editing the values-plus.yaml file and setting a replicaCount parameter with the desired value: controller: replicaCount: 4 And running helm upgrade as follows $ helm -n ingress-nginx upgrade ingress-nginx -f values-plus.yaml . Release "ingress-nginx" has been upgraded. Happy Helming! NAME: ingress-nginx LAST DEPLOYED: Thu May 20 14:20:38 2021 NAMESPACE: ingress-nginx STATUS: deployed REVISION: 2 TEST SUITE: None NOTES: The NGINX Ingress Controller has been installed. Using NGINXplus alongside with other Ingress Controllers (such as Contour). NGINXplus does support Ingress/v1 resource version available in Kubernetes 1.18+ as well as previous Ingress/v1beta1 API resource version for backwards compatibility. Contour Ingress Controller is provided in TKG by VMware as an add-on which is not installed by default. If installed, you have to be aware that Contour, at time of this writting (May 2021), only supports the older Ingress/v1beta1 API resource version. This means that when defining Ingress resources you have to specify the Ingress Controller to use by means of adding the following annotation: kubernetes.io/ingress.class: <ingress conroller name> where <ingress controller name> could be nginx or contour. For further details on this topic you can check https://docs.nginx.com/nginx-ingress-controller/installation/running-multiple-ingress-controllers/ Conclusion In this blog post we have gone through all the steps required to install and use NGINXplus with AppProtect in Tanzu Kubernetes Grid with a real world example. Overall, the installation is the same as in any Kubernetes but the following two items need to be taken into account: Before deploying, make sure that the appropriate PodSecurityPolicies are in place for either NGINXplus or the workloads. PodSecurityPolicies are not enabled by default in many Kubernetes distributions so this represents a change from the usual practice. If deploying NGINXplus alongside another Ingress Controller make sure that the Ingress resources are defined appropriately in order to select the right Ingress Controller for the corresponding Ingress resource. In this blog we used NGINXplus in a TKG cluster deployed in an on-premises infrastructure (vSphere with Tanzu) with the Antrea CNI and NSX-T networking. The steps would have been the same if it had been used vSphere networking or Calico CNI. The only difference could come when exposing it through the external load balancer. If the external load balancer performed health checking it would be preferable to use local externalTrafficPolicy since this avoids a hop and allows keeping the client source address. In future blogs we will post how to expose NGINXplus more effectively and in a cloud-agnostic manner by using BIG-IP as external load balancer.1.2KViews1like0CommentsOf Ransom and Redemption: The 2021 Application Protection Report
The information security professional’s mission has gradually become extraordinarily complex. At times, this mission borders on contradiction. Quite often, responsibility for the various components that form an enterprise environment is spread not only among multiple teams within the enterprise but also among vendors, partners, and service providers. In this 2021 Application Protection Report by F5 Labs, Sander, Ray, Shahnawaz, and Malcom look at the breaches in the past year as a series of attacker techniques, explore the outcomes, and provide some recommendations for controls you can implement in your environment. Some Highlights Two-thirds of API incidents in 2020 were attributable to either no authentication, no authorization, or failed authentication and authorization. In 2020, four sectors—finance/insurance, education, health care, and professional/technical services—experienced a greater number of breaches than retail (the leader in 2018 and 2019), partly driven by the growth in ransomware. The most important controls are privileged account management, network segmentation, restricting web-based content, data backup, and exploit protection (i.e., WAF). DevCentral Connects featuring Sander Vinberg Or, if you prefer, listen to Jason & John talk to Sander, directly, on DevCentral Connects.195Views0likes0Comments
Mitigating New Gadget Leveraging JNDI Injection into Remote Code Execution Using Advanced WAF
Recently a new gadget that bypass existing Java restrictions for JNDI injection was published via Tweet made by a security researcher identified by the twitter handle @PewGrand. JNDI – Java Naming and Directory Interface is a Java API that allows the application developer to retrieve objects based on a given name. JNDI supports different implementations like Remote Method Invocation (RMI), Lightweight Directory Access Protocol (LDAP) and others. The JNDI Injection vulnerability class was first presented in Black Hat 2016 by Alvaro Munoz and Oleksandr Mirosh who demonstrated the different ways where applications utilizing JNDI can be exploited into Remote Code Execution. Applications are vulnerable to JNDI Injections when user-controlled input is being passed as argument to methods like “lookup” of the “InitialContext” Java class, which is part of the Java Naming API. This method is responsible for resolving a name it received into an object identified by the supplied name. Figure 1: Example of vulnerable endpoint in a Spring application The name that the “lookup” method receives can also be in the form of LDAP or RMI URLs and therefore vulnerable applications may be forced to fetch a malicious object from attacker controlled RMI or LDAP server. In the last few years Oracle has applied several restrictions that aimed to prevent attackers from exploiting JNDI Injection vulnerabilities. One example of such restriction is the “trustURLCodebase” property which was introduced in Java Development Kit 8 – Update 121. This property prevents vulnerable applications from loading malicious objects from remote RMI repositories. Later, similar restriction was added also to cover LDAP repositories. Since those restrictions were added, exploiting JNDI Injection vulnerabilities now depends on existing gadgets, which means the classes used in the exploit must reside in the vulnerable application class path for the exploit to work. The new gadget discovered by @PewGrand uses similar approach as another previously disclosed gadget. They both start a rogue LDAP server that hosts an LDAP entry which specifies the “javaClassName” and “javaSerializedData” attributes. Those attributes can be used by Java LDAP implementations to reference Java objects in LDAP entries. Once the vulnerable application will fetch this entry from the attacker-controlled LDAP server the object referenced by the “javaSerializedData” attribute will be deserialized. Another point of similarity to the previously disclosed gadget is that both gadgets specify the BeanFactory class of Apache Tomcat as the object factory of the serialized object stored in the LDAP entry. The factory class is responsible for creating an instance of the class specified in the LDAP entry. The reason that the BeanFactory is a good pick for both gadgets is because it allows the rogue LDAP server to also specify a method that receives a string as a parameter which should be invoked after creating the instance from the specified class. This is achieved by specifying the “forceString” JNDI Reference. This is also where the difference between the two gadgets relies - the previous gadget was pointing to the “ELProcessor” class and specified the “eval” method as the “forceString” JNDI Reference, which allowed the gadget to execute arbitrary Java EL Expression template and thus achieve arbitrary code execution. Figure 2: Previous gadget creating instance of the ELProcessor class and invoking its “eval” method. The newly discovered gadget specifies the SnakeYAML Yaml class as the one that should be instantiated by Tomcat BeanFactory, and specifies the “load” method of the Yaml class in order to make the application parse a Yaml that loads JAR file from a remote server by using the Java URLClassLoader. Figure 3: New gadget creating instance of the SnakeYaml Yaml class and invoking the load method. Figure 4: Exploiting the vulnerable application using the new gadget. Mitigating JNDI Injections with Advanced WAF Advanced WAF customers under any supported version are now protected against this vulnerability. The exploitation attempt will be detected by newly released Java code injection attack signatures which can be found in signature sets that include the “Server Side Code Injection” attack type. Figure 5: Exploit attempt blocked by signature id 200104722. Additional resources https://twitter.com/steventseeley/status/1380065046458433536 https://gist.github.com/TheGrandPew/748ac740698511975eaeed5d77ecb2d9 https://www.blackhat.com/docs/us-16/materials/us-16-Munoz-A-Journey-From-JNDI-LDAP-Manipulation-To-RCE-wp.pdf https://www.veracode.com/blog/research/exploiting-jndi-injections-java1.2KViews0likes0CommentsHow to deploy NGINX App Protect as an Overlay Security Protection Solution for Your Existing API Management Platform
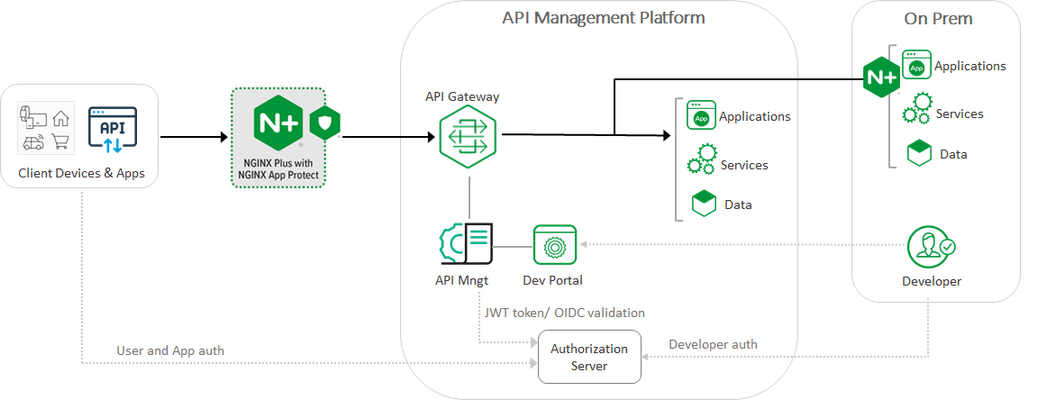
Solution Overview NGINX App Protect combines the proven effectiveness of F5's Advanced WAF technology with the agility and performance of NGINX Plus. It runs natively on NGINX Plus and addresses some of the most difficult challenges facing modern DevOps environments. NGINX App Protect, when deployed as an overlay security solution to complement your third-party API Management platforms such as MuleSoft, Kong, Google’s Apigee, and others, provides: Seamlessly integrateswith NGINXPlus and NGINX Ingress Controller Strong security controls to protect against malicious attacks Reduces complexity and tool sprawl while delivering modern apps Enforces security and regulatory requirements. With NGINX App Protect, you can detect and defend against OWASP App Security's Top Ten attack types like data exfiltration, malicious infections inputs, and many others. Figure: NGINX App Protect as an overlay security protection solution for your existing API Management Platform Solution Deployment This solution deployment procedure assumes that you have an understanding of the NGINX+ platform. If you like to learn more about NGINX, click this link. Install NGINX App Protect Install the most recent version of the NGINX Plus App Protect package (which includes NGINX Plus): sudo yum install -y app-protect Edit the NGINX configuration file and enable the NGINX App Protect module. user nginx; worker_processes auto; error_log /var/log/nginx/error.log notice; pid /var/run/nginx.pid; load_module modules/ngx_http_app_protect_module.so; events { worker_connections 1024; } http { include /etc/nginx/mime.types; default_type application/octet-stream; sendfile on; keepalive_timeout 65; log_format main '$remote_addr - $remote_user [$time_local] "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"'; access_log /var/log/nginx/access.log main; server { listen 80; server_name localhost; proxy_http_version 1.1; app_protect_enable on; app_protect_policy_file "/etc/nginx/NginxDefaultPolicy.json"; app_protect_security_log_enable on; app_protect_security_log "/etc/nginx/log-default.json" syslog:server=10.1.20.6:5144; location / { resolver 10.1.1.9; resolver_timeout 5s; client_max_body_size 0; default_type text/html; proxy_pass http://k8s.arcadia-finance.io:30274$request_uri; } } } Create a Log Configuration Create a log configuration file log_default.json sudo vi log-default.json { "filter": { "request_type": "all" }, "content": { "format": "default", "max_request_size": "any", "max_message_size": "5k" } } Restart the NGINX Service Restart the NGINX service and check the logs. sudo systemctl start nginx less /var/log/nginx/error.log Update Signatures To add NGINX Plus App Protect signatures repository, download and update the signature package. sudo yum install -y app-protect-attack-signatures sudo yum --showduplicates list app-protect-attack-signatures sudo yum install -y app-protect-attack-signatures-2020.04.30 Reload NGINX process to apply the new signatures. sudo nginx -s reload Advanced features NGINX App Protect supports various advanced security features like Bot Protection, Cryptonice integration, API Security with OpenAPI file import. Let's look at how to deploy Bot Protection in this example. Create a new NAP policy JSON file with Bot sudo vi /etc/nginx/policy_bots.json { "policy": { "name": "bot_defense_policy", "template": { "name": "POLICY_TEMPLATE_NGINX_BASE" }, "applicationLanguage": "utf-8", "enforcementMode": "blocking", "bot-defense": { "settings": { "isEnabled": true }, "mitigations": { "classes": [ { "name": "trusted-bot", "action": "alarm" }, { "name": "untrusted-bot", "action": "block" }, { "name": "malicious-bot", "action": "block" } ] } } } Modify the nginx.conf file to reference this new policy JSON file. sudo vi /etc/nginx/nginx.conf user nginx; worker_processes 1; load_module modules/ngx_http_app_protect_module.so; error_log /var/log/nginx/error.log debug; events { worker_connections 1024; } http { include /etc/nginx/mime.types; default_type application/octet-stream; sendfile on; keepalive_timeout 65; server { listen 80; server_name localhost; proxy_http_version 1.1; app_protect_enable on; app_protect_policy_file "/etc/nginx/policy_bots.json"; app_protect_security_log_enable on; app_protect_security_log "/etc/nginx/app-protect-log-policy.json" syslog:server=10.1.20.6:5144; location / { resolver 10.1.1.9; resolver_timeout 5s; client_max_body_size 0; default_type text/html; proxy_pass http://k8s.arcadia-finance.io:30274$request_uri; } } } Verification We will verify the NGINX App Protect deployment for illegal requests in the below example. Test with curl and with the browser using both the correct URL and the illegal URL: curl http://localhost curl http://localhost/?a=%3Cscript%3E Simultaneously open a second terminal window to see there are three types of violations noted in the log. tail -f /var/log/app_protect/class_illegal_security.log Request ID 1035880152621768133: GET / received on 2021-06-14 16:09:55 from IP 127.0.01 had the following violations: Illegal meta character in value, Attack Signature detected, Violation Rating Thereat detected. Note: NGINX App Protect logs all violations that occur. Therefore, we see not only the illegal character noted but also that it detected an attack signature and there is a rating threat also detected. Additional Resources NGINX App Protect: Configuration Guide NGINX: Installation and Deployment Guides Try NGINX App Protect: 30 days free trial2.5KViews0likes0CommentsCVE-2021-26855 (SSRF) HAFNIUM APT Group Exploiting Microsoft Exchange Vulnerabilities
Recently, Microsoft has issued an out of band patch that aims to mitigate seven Remote Code Execution vulnerabilities in Microsoft Exchange. Microsoft Threat Intelligence Center (MSTIC) has observed active exploitation of four of those vulnerabilities in the wild. Figure 1: Microsoft Exchange 0-Day vulnerabilities exploited in the wild The attacks are attributed to an APT group named HAFNIUM, which exploited those vulnerabilities mainly against targets from different industry sectors in the United States. After gaining access to the vulnerable Exchange servers HAFNIUM operators exfiltrated data like Exchange address book from the compromised server. Currently there are no public technical details on the vulnerabilities neither proof of concept exploits for those. Meanwhile we have successfully recreated the exploit flow for the insecure deserialization vulnerability (CVE-2021-26857) and we have released a dedicated attack signature for mitigating it. We will continue the analysis process for rest of the vulnerabilities, and we are closely monitoring for public POC exploits related to them. Mitigating CVE-2021-26855 and CVE-2021-26857 with Advanced WAF Advanced WAF customers under any supported version are already protected against those vulnerabilities as exploitation attempts will be detected by a dedicated signatures recently released. The signatures could be found under the "Server Side Code Injection Signatures” and "Other Application Attacks Signatures" signature sets. Figure 2: CVE-2021-26855 Exploit attempt blocked by signature id 200018127 Figure 3: CVE-2021-26855 Exploit attempt blocked by signature id 200018128 Figure 4: CVE-2021-26857 Exploit attempt blocked by signature id 200104705 Mitigating CVE-2021-26855 and CVE-2021-26857 with Threat Campaigns Advanced WAF customers with Threat Campaign license could detect and block campaigns targeting those vulnerabilities with the following Threat Campaigns: Microsoft Exchange Resource Cookie SSRF Microsoft Exchange ContactInfo Unsafe Deserialization Figure 5: CVE-2021-26855 Exploit attempt blocked by Threat Campaigns feature Figure 6: CVE-2021-26857 Exploit attempt blocked by Threat Campaigns feature Additional References https://www.microsoft.com/security/blog/2021/03/02/hafnium-targeting-exchange-servers/1.1KViews0likes3Comments