BIG-IP DNS
95 Topics
BIG-IP DNS Resource Record Types: Architecture, Design and Configuration
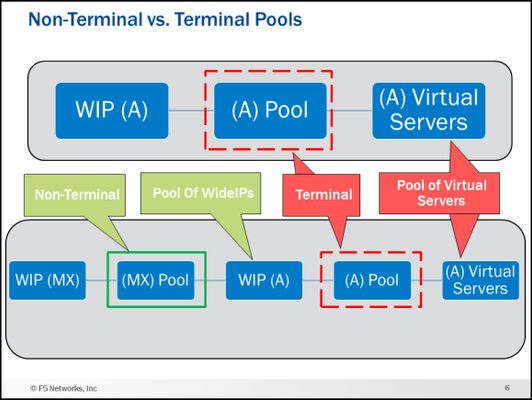
Welcome to my first article on DevCentral! This article starts a series about BIG-IP DNS (the artist formerly known as GTM). This article and accompanying videos take a look at the support for Domain Name System (DNS) Resource Record (RR) types that were introduced in BIG-IP version 12.0. This enhancement represented a major step forward in the capabilities available on the BIG-IP. I created these videos during the initial introduction of the feature in BIG-IP 12.0 release. Based on the timestamp in the BIG-IP GUI, that would be October of 2015. The information presented here is still relevant for later versions of BIG-IP and will be of benefit to anyone trying to understand the different DNS resource record types available on the BIG-IP. The videos assume you have used BIG-IP DNS before, and you understand the basics of DNS. If you need a refresher on DNS resource records, I present an overview of the new and existing resource records supported by BIG-IP DNS. I then go into the feature itself and the architecture and implementation details for each of the records on BIG-IP DNS. In the last video, I do a configuration walk-through of a NAPTR and SRV wideIP along with the NAPTR and SRV pools. Be sure and see the attachment at the end of the article. It is a zip file that contains a PDF of many of the slides I use in the videos. Executive Summary (9 Minutes) First up is the Executive Summary. This video introduces, at a high level, everything that will be covered in the later videos. It also talks about some things that are not explicitly called out in any of the other content. Technology Overview (8 Minutes) Next is a DNS technology overview for the different resource record types supported by BIG-IP DNS. If you are already familiar with the different DNS RR types (A, AAAA, CNAME, NAPTR, SRV, MX), you can skip this part. If you need a quick refresher on what each record type is and the fields used in them this content is for you! NOTE: This is not a discussion of how the BIG-IP DNS implements these resource records but rather a discussion of the record types themselves in a purely DNS sense. Feature/Architecture Overview If you do not watch any of the other videos in this series, watch these!! I go over the concepts and architecture behind how the different resource records are implemented and configured on BIG-IP DNS with lots of diagrams. The configurations of the different resource record types and all the associated pools can get confusing. These videos will give you a solid foundation to follow the configuration walk-through. I am going to be bold here and say that I guarantee you will learn something you did not know about BIG-IP DNS if you watch the next five videos. As a polling mechanism, hit the “Like” button on the article if I was correct in my prediction. General Information and A/AAAA Records (11:30 Minutes) This video covers general information about the DNS RR implementation along with the A and AAAA record types. For example, the video talks about a new concept in BIG-IP DNS called Non-Terminal and Terminal Pools and what they mean in wideIP configurations. CNAMEs (9 Minutes) This is a long discussion about CNAMEs. Who knew they were so interesting? Well, they are, and it is worth listening to how they are implemented on BIG-IP DNS. NAPTR, SRV and MX Records (5:30 Minutes) NAPTR, SRV and MX records are next. The configuration walk-through later in this article will implement NAPTR and SRV wideIPs. Health Checks (7:30 Minutes) Let’s talk about one of the reasons you have a BIG-IP DNS…health checks! Now that wideIPs can be pool member, the game has changed. Persistence (8 Minutes) Persistence also has some new wrinkles. If you use persistence, you want to watch this. Configuration Walk-through (11:30 Minutes) Finally, we have the configuration walk-through. This is where things get real. In this video, I do a configuration of NAPTR and SRV wideIPs along with the NAPTR and SRV pools. You can see the configuration objects I will create and the order in the diagram below. Conclusion That is all I have for this article. I hope you learned something and most importantly have a better understanding of the different DNS resource record types available on the BIG-IP DNS. I have more articles and videos to come so stay tuned. Be sure and grab the attachment if you want a copy of some of the diagrams used in the videos. Trivia: iQuery uses port 4353 for its communication. Do you know the significance/meaning of that particular port number? Drop a comment at the bottom if you know the answer.4.7KViews9likes9CommentsConfiguring BIG-IP for Zone Transfer and DNSSEC
This article is for organizations that use our F5 BIG-IP as their primary DNS. The guide consists of two parts. First, it shows you how to configure BIG-IP DNS to perform a zone transfer to a secondary DNS server. Second, it demonstrates how to enable DNSSEC (Domain Name System Security Extensions) on BIG-IP DNS. Part 1: Configure BIG-IP DNS for Zone Transfer This part of the article will focus on guiding you on how to set up BIG-IP for zone transfer. I assume at this point in time that you already have DNS records configured via Zone Runner. Having said that, let's proceed to set up BIG-IP for zone transfer to a secondary DNS, which in our case will be F5 Distributed Cloud DNS. Step 1: Create a custom DNS Profile On the Main tab, click DNS > Delivery > Profiles. click Create. Type a Name for the custom DNS profile. Select 'dns' as the Parent Profile from which it will inherits settings. Under DNS Traffic area, Zone Transfer, select Enabled. Click Save & Close. Step 2: Create a custom DNS Listener On the Main tab, click DNS > Delivery > Listeners, click Create. In the Name field, type a unique name for the listener. For the Destination setting, in the Address field, type an IPv4 address on which BIG-IP DNS listens for network traffic. In the Service area, from the Protocol list, select UDP. In the Service area, from the DNS Profile list, select the custom profile created on Step 1. Click Finished. Repeat steps 1-6 to create a TCP listener, but on step 4, select TCP. Step 3: Generate a TSIG Key On BIG-IP DNS Command Line, enter the following in bash: tsig-keygen -a HMAC-SHA256 <tsig name> Example: tsig-keygen -a HMAC-SHA256 example The output should be similar to this key "example" { algorithm hmac-sha256; secret "UAHXLiErXSTXw84QcaeWk2jLnU0GYXGWBQ2IT+rtfCU="; }; Step 4: Configure TSIG Key In the BIG-IP GUI, go to DNS > Delivery > Keys > TSIG Key List, click Create. Name: example Algorithm: HMAC SHA-256 Secret: <paste the secret output generated from Step 3> Step 5: Create Nameservers Go to DNS > Delivery > Nameservers > Nameserver List, click Create. Create the following nameserver objects: Name: localbind, Address: 127.0.0.1, Service Port: 53 Name: f5xcdns1, Address: 52.14.213.208, Service Port: 53, TSIG Key: example Name: f5xcdns2, Address: 3.140.118.214, Service Port: 53, TSIG Key: example The IP address details of F5XC to be used in Zone Transfers can be found here https://docs.cloud.f5.com/docs/reference/network-cloud-ref Step 6: Create DNS Zone for Zone Transfer Go to DNS > Zones > Zones > Zones List, click Create. Fill the following details: Name: f5sg.com DNS Express :: Server: localbind Zone Transfer Clients :: Nameservers: Select f5xcdns1 & f5xcdns2 TSIG :: Server Key: example Step 7: Include TSIG in named.conf On BIG-IP command line, create and open a new file named tsig.key in the /var/named/config directory. For example, use vi editor to create a new file named tsig.key in the /var/named/config directory, enter the following command: vi /var/named/config/tsig.key To add the TSIG key, paste the following output we generated earlier: key "example" { algorithm hmac-sha256; secret "UAHXLiErXSTXw84QcaeWk2jLnU0GYXGWBQ2IT+rtfCU="; }; Save the tsig.key file. To create the necessary symbolic link to the tsig.key file in the /config directory, enter the following command: ln -s /var/named/config/tsig.key /config/tsig.key To set the correct owner for the tsig.key file, enter the following command: chown named:named /var/named/config/tsig.key Using a text editor, open the /var/named/config/named.conf file for editing. For example, to use vi editor to edit the /var/named/config/named.conf file, enter the following command: vi /var/named/config/named.conf Add the following include statement to the top of the named.conf file, below the first two comments in the file: include "/config/tsig.key"; Save the file. Step 8: Add the Secondary DNS (F5XC DNS) IP addresses in Zone Transfer allow list Using a text editor, open the /var/named/config/named.conf file for editing. For example, to use vi editor to edit the /var/named/config/named.conf file, enter the following command: vi /var/named/config/named.conf Add the following acl statement at the bottom of the named.conf file (Note: The IP address details of F5XC to be used in Zone Transfers can be found here https://docs.cloud.f5.com/docs/reference/network-cloud-ref) acl "F5XC" { 52.14.213.208/32; 3.140.118.214/32; }; Insert the following inside the allow-transfer block (this will allow F5XC to perform AXFR requests) allow-transfer { localhost; F5XC; <--- Add this line }; Save the file (Optional) Part 2: Configure a BIG-IP DNS Zone for DNSSEC Assuming you already have a zone configured for DNS zone transfer and you want to enable DNSSEC on this zone, you can follow the steps below. The generated cryptographic keys for DNSSEC will be synced to the secondary DNS as part of the zone transfer. Step 1: Create automatically-managed zone-signing keys (ZSK) On the Main tab, DNS > Delivery > Keys > DNSSEC Key List, click Create. In the Name field, type a name for the key (Zone names are limited to 63 characters) From the Type list, select Zone Signing Key. From the State list, select Enabled. **You can leave all other setting to default and click Finish on this point. But if you can also modify other settings based on your requirement Click Finished. Step 2: Create automatically-managed zone-signing keys (KSK) On the Main tab, DNS > Delivery > Keys > DNSSEC Key List, click Create. In the Name field, type a name for the key (Zone names are limited to 63 characters) From the Type list, select Key Signing Key. From the State list, select Enabled. **You can leave all other setting to default and click Finish on this point. But if you can also modify other settings based on your requirement Click Finished. Step 3: Creating a DNSSEC zone On the Main tab, click DNS > Zones > DNSSEC Zones, click Create. In the Name field, type a domain name. For example, use a zone name of f5sg.com to handle DNSSEC requests for www.f5sg.com and *.www.f5sg.com. From the State list, select Enabled. For the Zone Signing Key setting, assign at least one enabled zone-signing key to the zone. You can associate the same zone-signing key with multiple zones. For the Key Signing Key setting, assign at least one enabled key-signing key to the zone. You can associate the same key-signing key with multiple zones. Click Finished. Step 4: Upload generated DS record to parent zone Upload the DS records for this zone to the organization that manages the parent zone. The administrators of the parent zone sign the DS record with their own key and upload it to their zone. You can find the DS records in the Configuration utility.646Views4likes0CommentsEdge to Pulse: IP Geolocation Database Migration
UPDATE (August 2023): Previously, we announced the end of support of the Edge legacy database. However, support for the Edge database has been extended indefinitely. All supported versions of F5 BIG-IP can now use both types of IP geolocation databases: Edge and Pulse, provided by Digital Envoy. The Edge database is based off of partner-supplied data gathered from IP traffic. The Pulse database relies on information derived from mobile devices and Wi-Fi connection points, increasing the accuracy for certain aspects, but also significantly increasing file size. Because of this, F5 does not support City level for the Pulse database. Last month, F5’s BIG-IP DNS team released the new, Pulse database from our third-party vendor, Digital Envoy. F5 migrated its IP geolocation database from the Edge database to the Pulse database because Pulse provides a higher number of available subnets. This allows for improved geolocation accuracy for querying IP addresses. Because Pulse captures more granular data of locations than Edge, it is larger than the Edge database. This installation update may take longer than expected after the migration due to the size of the database. As with any infrastructure shift, there are a few important things to know: This migration applies to all supported BIG-IP versions and is transparent to users If using City Database from Digital Envoy, then please follow the KB article before installing the Pulse City RPM (K78974041 - link below) There is no change of database format, downloading, or installation procedures Edge and Pulse databases are available for an additional three months from release date to ease the migration process Both databases are seamlessly available for customer download until the end of 2022 Beginning in January 2023, only the Pulse database will be accessible Edge database will reach End of Life by the end of December 20222.4KViews3likes4CommentsWhat Is BIG-IP?
tl;dr - BIG-IP is a collection of hardware platforms and software solutions providing services focused on security, reliability, and performance. F5's BIG-IP is a family of products covering software and hardware designed around application availability, access control, and security solutions. That's right, the BIG-IP name is interchangeable between F5's software and hardware application delivery controller and security products. This is different from BIG-IQ, a suite of management and orchestration tools, and F5 Silverline, F5's SaaS platform. When people refer to BIG-IP this can mean a single software module in BIG-IP's software family or it could mean a hardware chassis sitting in your datacenter. This can sometimes cause a lot of confusion when people say they have question about "BIG-IP" but we'll break it down here to reduce the confusion. BIG-IP Software BIG-IP software products are licensed modules that run on top of F5's Traffic Management Operation System® (TMOS). This custom operating system is an event driven operating system designed specifically to inspect network and application traffic and make real-time decisions based on the configurations you provide. The BIG-IP software can run on hardware or can run in virtualized environments. Virtualized systems provide BIG-IP software functionality where hardware implementations are unavailable, including public clouds and various managed infrastructures where rack space is a critical commodity. BIG-IP Primary Software Modules BIG-IP Local Traffic Manager (LTM) - Central to F5's full traffic proxy functionality, LTM provides the platform for creating virtual servers, performance, service, protocol, authentication, and security profiles to define and shape your application traffic. Most other modules in the BIG-IP family use LTM as a foundation for enhanced services. BIG-IP DNS - Formerly Global Traffic Manager, BIG-IP DNS provides similar security and load balancing features that LTM offers but at a global/multi-site scale. BIG-IP DNS offers services to distribute and secure DNS traffic advertising your application namespaces. BIG-IP Access Policy Manager (APM) - Provides federation, SSO, application access policies, and secure web tunneling. Allow granular access to your various applications, virtualized desktop environments, or just go full VPN tunnel. Secure Web Gateway Services (SWG) - Paired with APM, SWG enables access policy control for internet usage. You can allow, block, verify and log traffic with APM's access policies allowing flexibility around your acceptable internet and public web application use. You know.... contractors and interns shouldn't use Facebook but you're not going to be responsible why the CFO can't access their cat pics. BIG-IP Application Security Manager (ASM) - This is F5's web application firewall (WAF) solution. Traditional firewalls and layer 3 protection don't understand the complexities of many web applications. ASM allows you to tailor acceptable and expected application behavior on a per application basis . Zero day, DoS, and click fraud all rely on traditional security device's inability to protect unique application needs; ASM fills the gap between traditional firewall and tailored granular application protection. BIG-IP Advanced Firewall Manager (AFM) - AFM is designed to reduce the hardware and extra hops required when ADC's are paired with traditional firewalls. Operating at L3/L4, AFM helps protect traffic destined for your data center. Paired with ASM, you can implement protection services at L3 - L7 for a full ADC and Security solution in one box or virtual environment. BIG-IP Hardware BIG-IP hardware offers several types of purpose-built custom solutions, all designed in-house by our fantastic engineers; no white boxes here. BIG-IP hardware is offered via series releases, each offering improvements for performance and features determined by customer requirements. These may include increased port capacity, traffic throughput, CPU performance, FPGA feature functionality for hardware-based scalability, and virtualization capabilities. There are two primary variations of BIG-IP hardware, single chassis design, or VIPRION modular designs. Each offer unique advantages for internal and collocated infrastructures. Updates in processor architecture, FPGA, and interface performance gains are common so we recommend referring to F5's hardware page for more information.75KViews3likes3CommentsThe Power of &: F5 Hybrid DNS solution
While some organizations prioritize the advantages of a SaaS solution like scalability, others value the benefits of an on-premises solution, such as data control and migration flexibility. This is why having the option to deploy a hybrid model can be beneficial, not just for redundancy, but also for allowing organizations to blend the best of both worlds. Understanding the Architecture’s components F5 BIG-IP DNS - (formerly BIG-IP GTM) is a well-known on-premise solution for delivering high-performance DNS services such as DNSExpress and DNS Caching. It is also recognized for offering intelligent DNS responses that are based on various factors such as LDNS’ Geolocation (GSLB) and health status of applications. F5 Distributed Cloud DNS (F5 XC DNS) – It is F5’s SaaS-based DNS solution which is built on a global data plane, ensuring automatic scalability to meet high-volume demand. Additionally, it also provides GSLB and security such as DNS DoS protection. On the diagram above, BIG-IP DNS will be the hidden primary DNS, acting as the source of truth for DNS records. This setup ensures centralized control and adds an extra layer of security by reducing exposure to potential attacks. F5XC DNS will function as the secondary DNS server, receiving DNS records from BIG-IP via Zone Transfer. It will be responsible for handling public DNS queries and providing domain name resolution services to clients. In the first part of this article, we will show you how to set up and configure BIG-IP DNS as the hidden primary and F5XC DNS as the authoritative secondary DNS server. For some, this setup is sufficient for their requirements, but for others, there may be additional requirements to consider in this hybrid design. In the later part of this article, we will demonstrate how we can address these challenges by leveraging F5's platform features and capabilities! Steps on Implementing F5 Hybrid DNS Solution Step 1: Configure BIG-IP DNS First, we need to configure BIG-IP DNS to be able to perform a zone transfer to F5XC DNS. For more details on the configuration, you can check this link: https://community.f5.com/kb/technicalarticles/configuring-big-ip-for-zone-transfer-and-dnssec/330359 Step 2: Configure F5XC DNS Now after you've configured BIG-IP DNS, we need to configure F5 XC DNS to be a secondary DNS server. For more details, check the steps below: Log into XC Console, select DNS Management option, click Add Zone. In Domain Name field, enter the domain/subdomain. In our example, it will be f5sg.com Zone Type: Secondary DNS Configuration Under the Secondary DNS Configuration field, click Configure On the DNS primary server IP field, enter the public IP address of the Primary DNS. In our example it will be the Public IP of BIG-IP DNS. On TSIG key, enter the name we used to generate TSIG earlier in BIG-IP. In our example, used example. On the TSIG Key algorithm field and select an algorithm from the drop-down. Select hmac-sha256. Click Configure in the TSIG key value in base 64 format section, On the Secret Type field, select Clear Secret and paste the secret in the Secret field. Use the same secret we generated earlier in BIG-IP DNS. Click Apply. You should see the DNS records transferred from BIG-IP DNS to F5XC DNS Step 3: Configure Domain Registrar In this example, the domain registrar I'm using is Namecheap. I'll configure it so that the authoritative name server for the domain f5sg.com is set to F5XC (ns1.f5clouddns.com and ns2.f5clouddns.com). The steps will vary depending on which domain registrar you are using. Refer to the documentation of your registrar. See the screenshots below for how I configured it in Namecheap. F5 XC DNS should now be able to answer DNS queries since it is set to be the authoritative DNS. Now, let's do some testing! On my local machine, I will perform a dig on the f5sg.com domain. See below: You can see that on the dig result, the NS for f5sg.com is set to ns1.f5clouddns.com & ns2.f5clouddns.com! I can also resolve sales.f5sg.com! We have successfully implemented BIG-IP as Hidden Primary and F5XC as Authoritative Secondary DNS! Challenges and Considerations Now let's discuss the additional requirements or challenges that we might encounter with this hybrid setup solution: Security: We need to comply with security compliance. Nowadays, there are laws requiring the implementation of DNSSEC (DNS Security Extensions). We need to consider this in the design and implement it without adding complexity. Resiliency: Although F5XC DNS Infrastructure is built to be resilient, we still want a backup plan to failover to the BIG-IP Primary DNS in case of unforeseen events. This process will be manual, as we need to change the NS records at the registrar to promote the hidden BIG-IP Primary DNS as the authoritative NS for the domain once F5XC is unavailable. Synchronization: BIG-IP will not be able to synchronize the GSLB functionality with F5XC because Wide-IP records are non-standard and cannot be transferred as part of zone transfers. Solution to Challenges Now comes the fun part: tackling the challenges we’ve laid out! Fortunately, F5 Distributed Cloud is an API-first platform that enables us to automate configuration. At the same time, we have the power of the BIG-IP platform, where you can run custom scripts that will enable us to integrate it with F5XC through API. Solution to Challenge #1: This is easy. DNSSEC records like RRSIG, DNSKEY, DS, NSEC, and NSEC3 are standardized and can be synchronized as part of a zone transfer. Since BIG-IP DNS is our primary DNS and supports DNSSEC, we can enable it. The records will synchronize to F5XC DNS and still respond with signed records, maintaining the integrity and security of our DNS infrastructure. How do you enable it? Check the last part of the technical article below: https://community.f5.com/kb/technicalarticles/configuring-big-ip-for-zone-transfer-and-dnssec/330359 Solution to Challenge #2: We need to automate failover! But when automating tasks, you need two things: a trigger and an action. In our scenario, our trigger should be the availability of F5XC DNS to resolve DNS queries, and the action should be to change our nameserver to BIG-IP on the domain registrar. If you can create and run a script in BIG-IP, it means you can continuously monitor the health of F5XC DNS, allowing us to determine the trigger. But what about the action to change the domain name server records in the registrar? It's easy—check if it can be configured via API, then the problem is solved! Let's explore using Namecheap as our registrar for this example. We will use the BIG-IP EAV (external) monitor to run the script. If you're unfamiliar with the BIG-IP external monitor and its capabilities, check this out → https://my.f5.com/manage/s/article/K71282813 A dummy pool configured with an external monitor will run at intervals. The attached script is designed to monitor F5XC and check if it can resolve DNS queries. If it cannot, the script will trigger an API call to Namecheap (our domain registrar) to change the nameservers back to BIG-IP DNS. Simultaneously, the script will update the domain's NS records from F5XC to BIG-IP. Step 1: Create an external monitor using the custom script. Refer to article K71282813 how to create the external monitor. See the codeshare link for the sample custom script I used: Namecheap and BIG-IP Integration via API | DevCentral Step 2: Create a dummy pool and attach the custom external monitor Let's do some tests! See the results in the later part of this article. Solution to Challenge #3: We can't use Zone Transfer to synchronize GSLB configurations? No problem! Instead, we'll harness the power of APIs. We can run a custom script in BIG-IP to convert Wide-IP configurations into F5XC DNSLB records via API. Let's see below how we can do this. On BIG-IP DNS, configure the zone records for the domain f5sg.com to delegate the subdomains needed for GSLB. For example, we need to perform GSLB for www.f5sg.com, we will configure the zone like below: www.f5sg.com CNAME www.gslb.f5sg.com gslb.f5sg.com NS ns1.f5clouddns.com On BIG-IP we will create Wide-IP configuration for www.gslb.f5sg.com which should hold the A records. These Wide-IP configurations can be converted by a script to F5XC DNSLB configurations. Check the sample script on this codeshare link: BIG-IP Wide-IP to F5XC DNSLB converter | DevCentral Testing and Result Challenge #2: Failover Testing To simulate the scenario in which F5XC is unable to respond to DNS queries, we designed the script to execute a dig command to F5XC for a TXT record. If F5XC responds with "RESPONSE-OK," no further action is needed. However, if it fails to respond correctly or does not respond at all, the script will trigger a failover action. Scenario 1: When F5XC responds to DNS queries (TXT record value is RESPONSE-OK) Namecheap dashboard shows F5XC nameservers BIG-IP DNS zone records shows F5XC nameservers F5XC zone records shows F5XC nameservers Result when performing dig to resolve sales.f5sg.com -> it shows that F5XC nameservers are Authoritative Scenario: When F5XC doesn't respond to DNS queries (TXT record value is RESPONSE-NOT-OK) We changed the TXT record value to 'RESPONSE-NOT-OK,' which should mark the monitor as down. The dummy pool went down, which means the script inside the monitor detected that the dig result was not what it expected. You can see from the zone records below that the NS records have now changed to GTM (gtm1.f5sg.com and gtm2.f5sg.com) When we check our domain registrar, Namecheap, we can see that the nameservers are now automatically set to BIG-IP GTMs. When I issue a dig command from my workstation, I can see that the nameserver responding to my query is gtm1.f5sg.com Online DNS tools (like MXToolbox) also report that gtm1.f5sg.com is the authoritative NS that responds to the DNS queries for sales.f5sg.com, which resolves to 2.2.2.2 We have now solved one of the challenges by implementing a backup failover plan using custom monitors and automations, made possible by the power of BIG-IP and APIs! Challenge #3: Synchronization Testing Using this script, we can convert and synchronize the BIG-IP Wide-IP configuration to its F5XC equivalent configuration Note: The sample script is limited to handling a Wide-IP with a single GTM pool. Inside the pool is where you will define the IP addresses that you want to load balance. The pool load balancing method is also limited to Round Robin, Ratio, Static Persist, and Global Availability. The script is designed to run at intervals. There are several ways to execute it: you can use external monitors (as we did earlier) or utilize a cronjob, etc. For testing and simplicity, I will use a cronjob set to run every 10 minutes. Let's begin creating our GSLB configuration. If you've configured BIG-IP GTM/DNS before, one of the first objects you need to create is a GTM server. I've configured two Generic Servers representing the application in two different Data Centers. Next is we create a GTM Pool which we will associate the Virtual Server inside the GTM server we created earlier. (i.e. I'm assigning 1.1.1.1 and 2.2.2.2 as the members of the pool) Lastly, we will create the Wide-IP record and attach the GTM Pool we created earlier After this, the script should get triggered and convert this BIG-IP DNS Wide-IP configuration into F5XC DNS configuration. We should see that a new Primary Zone will be created in F5XC (gslb.f5sg.com) When you view the resource records, we should see a DNSLB record which has the record name equivalent to the subdomain of the wide-IP record. (BIG-IP DNS Wide-IP record is www.glsb.f5sg.com, In F5XC DNS zone gslb.f5sg.com, the record name is www and pointing to DNSLB object) The load balancing rules should have the DNSLB pool (pool-www) which is the equivalent of the GTM Pool (pool_www) configured in BIG-IP DNS The DNSLB pool members will include the same IP addresses we defined as GTM Pool members in BIG-IP DNS. There are four load balancing methods available in F5XC, and there is an equivalent BIG-IP DNS load balancing method. The script was created to match this methods but if you configure the BIG-IP DNS pool load balancing method to something other than these four, it will default to Round Robin. BIG-IP DNS F5XC DNS Round Robin Round-Robin Ratio Ratio-Member Static Persist Static-Persist Global Availability Priority Based on the results above, we have successfully converted and synchronize BIG-IP DNS Wide-IP configuration into F5XC DNSLB records! Conclusion We have resolved DNS challenges using the power and integration of F5 solutions! By utilizing both BIG-IP and F5XC platforms, which can sign and serve DNSSEC records, we can seamlessly implement DNSSEC in a hybrid setup without complexity. Furthermore, our scalable F5XC Cloud DNS will shield you from myriad DNS DoS attacks, which are continually evolving, especially with the rise of AI. In terms of DNS resiliency, with the power of our API-first platforms and automation, we can create a DNS hybrid solution capable of automatically failing over from Cloud DNS to on-prem DNS. Lastly, we can synchronize the configurations of both platforms using standards like Zone Transfer and APIs. This capability allows us to convert and synchronize GSLB configurations between our on-prem DNS and Cloud DNS, making administration easier, and establishing a single source of truth.998Views2likes0CommentsUsing Client Subnet in DNS Requests
BIG-IP DNS 14.0 now supports edns-client-subnet (ECS) for both responding to client requests (GSLB) or forwarding client requests (screening). The following is a quick start on using this feature. What is EDNS-Client-Subnet (ECS) If you are familiar with X-Forwarded-For headers in HTTP requests, ECS solves a similar problem. The problem is how to forward a DNS request through a proxy and preserve information about the original request (IP Address). Some of this discussion I also cover in a previous article,Implementing Client Subnet in DNS Requests . Traditional DNS Requests When a traditional DNS request is made, a client makes a request to a “local” DNS server (LDNS), and that request is forwarded to the authoritative DNS server for that domain. When a topology (send different responses based on the source address) record is evaluated it will use the source IP of the LDNS server. Usually this is OK for most applications, but it would be ideal to be able to forward more precise information from the LDNS server. ECS DNS Requests Using ECS a LDNS server can inject additional meta-data about the request that includes information about the source IP address of the client. In the following example a “Client Subnet” of 192.0.2.0/24 is forwarded to the DNS server. ECS on BIG-IP DNS F5 BIG-IP DNS can use ECS in two ways. Use ECS when handling topology requests Inject ECS when “screening” a DNS server Using ECS with BIG-IP DNS Topology There are two methods of configuring BIG-IP DNS to use ECS. Either at the wide-ip or globally. To configure ECS on a wide-ip: To configure ECS globally. Under DNS Settings. Injecting ECS records BIG-IP DNS can also proxy requests to other DNS servers (BIG-IP DNS or other vendors). When you modify the DNS profile to insert an ECS record. You will observe that the original /32 address will be forwarded to any DNS servers that are in the pool for that particular Virtual Server. The following is a diagram of the above.12KViews2likes27CommentsUnbreaking the Internet and Converting Protocols
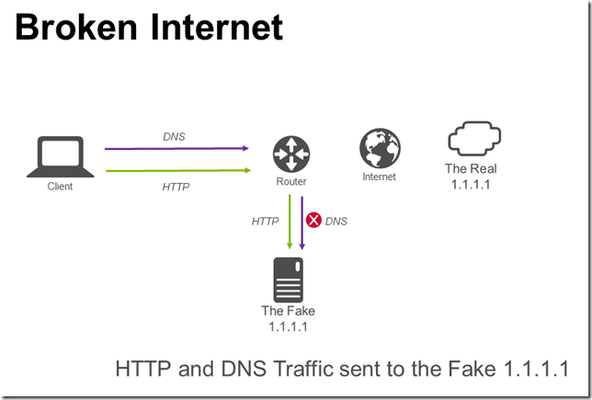
When CloudFlare took over 1.1.1.1 for their DNS service; this got me thinking about a couple of issues: A. What do you do if you’ve been using 1.1.1.1 on your network, how do you unbreak the Internet? B. How can you enable use of DNS over TLS for clients that don’t have native support? C. How can you enable use of DNS over HTTPS for clients that don’t have native support? A. Unbreaking the Internet RFC1918 lays out “private” addresses that you should use for internal use, i.e. my home network is 192.168.1.0/24. But, we all have issues where sometimes we “forget” about the RFC and you are using routable IP space on your internal network. 1.1.1.1 is a good example of this, it’s just so nice looking and easy to type. In my home network I created a contrived situation to simulate breaking the Internet; creating a network route on my home router that sends all traffic for 1.1.1.1/32 to a Linux host on my internal network. I imagined a situation where I wanted to continue to send HTTP traffic to my own server, but send DNS traffic to the “real” 1.1.1.1. In the picture above, I have broken the Internet. It is now impossible for me to route traffic to 1.1.1.1/32. To “fix” the Internet (image below), I used a F5 BIG-IP to send HTTP traffic to my internal server and DNS traffic to 1.1.1.1. The BIG-IP configuration is straight-forward. 1.1.1.1:80 points to the local server and 1.1.1.1:53 points to 1.0.0.1. Note that I have used 1.0.0.1 since I broke routing to 1.1.1.1 (1.0.0.1 works the same as 1.1.1.1). B. DNS over TLS After fixing the Internet, I started to think about the challenge of how to use DNS over TLS. RFC7858 is a proposed standard for wrapping DNS traffic in TLS. Many clients do not support DNS over TLS unless you install additional software. I started to wonder, is it possible to have a BIG-IP “upgrade” a standard DNS request to DNS over TLS? There are two issues. DNS over TLS uses TLS (encryption) DNS over TLS uses TCP (most clients default to UDP unless handling large DNS requests) For the first issue, the BIG-IP can already wrap a TCP connection with TLS (often used in providing SSL visibility to security devices that cannot inspect SSL traffic, BIG-IP terminates SSL connection, passes traffic to security device, re-encrypts traffic to final destination). The second issue can be solved with configuring BIG-IP DNS as a caching DNS resolver that accepts UDP and TCP DNS requests and only forwards TCP DNS requests. This results in an architecture that looks like the following. The virtual server is configured with a TCP profile and serverssl profile. The serverssl profile is configure to verify the authenticity of the server certificate. The DNS cache is configured to use the virtual server that performs the UDP to TCP over TLS connection. .wlemoticon { behavior: url(#default#.WLEMOTICON_WRITER_BEHAVIOR) } img { behavior: url(#default#IMG_WRITER_BEHAVIOR) } .wlwritereditablesmartcontent { behavior: url(#default#.WLWRITEREDITABLESMARTCONTENT_WRITER_BEHAVIOR) } .wlwritersmartcontent, .wlwriterpreserve { behavior: url(#default#.WLWRITERSMARTCONTENT,_.WLWRITERPRESERVE_WRITER_BEHAVIOR) } .wlwritereditablesmartcontent > .wleditfield { behavior: url(#default#.WLWRITEREDITABLESMARTCONTENT_>_.WLEDITFIELD_WRITER_BEHAVIOR) } blockquote { behavior: url(#default#BLOCKQUOTE_WRITER_BEHAVIOR) } #extendedentrybreak { behavior: url(#default##EXTENDEDENTRYBREAK_WRITER_BEHAVIOR) } .postbody table { behavior: url(#default#.POSTBODY_TABLE_WRITER_BEHAVIOR) } .postbody td { behavior: url(#default#.POSTBODY_TD_WRITER_BEHAVIOR) } .postbody th { behavior: url(#default#.POSTBODY_TH_WRITER_BEHAVIOR) } .posttitle {margin: 0px 0px 10px 0px; padding: 0px; border: 0px;} .postbody {margin: 0px; padding: 0px; border: 0px; min-height: 400px;} A bonus of using the DNS cache is that subsequent DNS queries are extremely fast! C. DNS over HTTPS I felt pretty good after solving these two issues (A and B), but there was a third nagging issue (C) of how to support DNS over HTTPS. If you have ever looked at DNS traffic it is a binary format over UDP or TCP that is visible on the network. HTTPS traffic is very different in comparison; TCP traffic that is encrypted. The draft RFC (draft-ietf-doh-dns-over-https-05) has a handy specification for “DNS Wire Format”. Take a DNS packet, shove it into an HTTPS message, get back a DNS packet in a HTTPS response. Hmm, I bet an iRule could solve this problem of converting DNS to HTTPS. Using iRulesLX I created a process where a TCL iRule takes a UDP payload off the network from a DNS client, sends it to a Node.JS iRuleLX extension that invokes the HTTPS API, returns the payload to the TCL iRule that sends the result back to the DNS client on the network. The solution looks like the following. This works on my home network, but I did notice occasional 405 errors from the HTTPS services while testing. The TCL iRule is simple, grab a UDP payload. when CLIENT_DATA { set payload [UDP::payload] set encoded_payload [b64encode $payload] set RPC_HANDLE [ILX::init dns_over_https_plugin dns_over_https] set rpc_response [ILX::call $RPC_HANDLE query_dns $encoded_payload] UDP::respond [b64decode $rpc_response] } The Node.JS iRuleLX Extension makes the API call to the HTTPS service. ... ilx.addMethod('query_dns', function(req, res) { var dns_query = atob(req.params()[0]); var options = { host: '192.168.1.254', port: 80, path: '/dns-query?ct=application/dns-udpwireformat&dns=' + req.params()[0], method: 'GET', headers: { 'Host':'cloudflare-dns.com' } }; var cfreq = http.request(options, function(cfres) { var output = ""; cfres.setEncoding('binary'); cfres.on('data', function (chunk) { output += chunk; }); cfres.on('end', () => { res.reply(btoa(output)); }); }); cfreq.on('error', function(e) { console.log('problem with request: ' + e.message); }); cfreq.write(dns_query); cfreq.end(); }); ... After deploying the iRule; you can update your DNS cache to point to the Virtual Server hosting the iRule. Note that the Node.JS code connects back to another Virtual Server on the BIG-IP that does a similar upgrade from HTTP to HTTPS and uses a F5 OneConnect profile. You could also have it connect directly to the HTTPS server and recreate a new connection on each call. All done? Before I started I wasn’t sure whether I could unbreak the Internet or upgrade old DNS protocols into more secure methods, but F5 BIG-IP made it possible. Until the next time that the Internet breaks.2.5KViews2likes5CommentsPool member status on F5 DNS objects via iControl REST
I got a question on how to retrieve the status of pool members on F5 DNS objects via the iControl REST interface. In the GUI you get fancy red, yellow, black, blue, and green painted circles, diamonds, squares, and triangles to communicate availability. At the command line, however, it’s harder to map that visual data. There are two important settings underlying an object’s availability: availability state and enabled state. You can see when using the field-fmt option on the tmsh command to show the pool member status that both GTM and LTM objects report the same data (the remaining fields are removed for brevity): gtm pool pool gslb_pool_1:A { members { testvip:ltm3 { status.availability-state available status.enabled-state enabled status.status-reason Available } } status.availability-state available status.enabled-state enabled status.status-reason Available } ltm pool testpool { members { 192.168.103.20:80 { status.availability-state available status.enabled-state enabled status.status-reason Pool member is available } } status.availability-state available status.enabled-state enabled status.status-reason The pool is available } Through the REST interface, both status fields are available in the LTM pool object. Calling the pool member and selecting on session and state, the following request returns the data as expected: GET https://ltm3.test.local/mgmt/tm/ltm/pool/testpool/members/~Common~192.168.103.20:80?$select=session,state { "session": "monitor-enabled", "state": "up" } However, these same status fields are not available on GTM pool/pool member REST objects. Calling a GTM pool member, the following request returns no information on monitor status (that's the availability-state field from above) but does indicate the enabled state, albeit unconventionally by changing the field name: GET https://ltm3.test.local/mgmt/tm/gtm/pool/a/~Common~gslb_pool_1/members/~Common~ltm3:~Common~front_door # when enabled: { "name": "front_door", "enabled": true, } # when disabled: { "name": "front_door", "disabled": true, } So if the information is not available directly from the REST interface, how do you get it? Well, you have options. The newest approach (and one I am currently investigating for things like this) is writing your own API via the iControl LX extensions. That's not the approach I'll take here, however. Instead, I'll use a tmsh script to return the appropriate data via a bash call from iControl REST. The tmsh script is quite simple. It takes an argument for the type of GTM pool you wish to query, and then the pool name. It will then iterate through the members and return for each member the pool member name, its availability state, and its enabled state. proc script::run {} { if { $tmsh::argc != 3 } { puts "A pool type and name must be provided" exit } set pool_type [lindex $tmsh::argv 1] set pool_name [lindex $tmsh::argv 2] foreach obj [tmsh::get_status /gtm pool $pool_type $pool_name detail] { foreach member [tmsh::get_field_value $obj members] { puts "[tmsh::get_name $member],[tmsh::get_field_value $member status.availability-state],[tmsh::get_field_value $member status.enabled-state]" } } } total-signing-status not-all-signed } Running the script from bash on the BIG-IP, I get the following results: [root@ltm3:Active:Standalone] tmp # tmsh run cli script pool-status.tcl a gslb_pool_1 front_door:ltm3,available,disabled testvip:ltm3,available,enabled testvip2:ltm3,available,enabled And finally, calling this with the F5 python SDK returns the same results: >>> from f5.bigip import ManagementRoot >>> mgmt = ManagementRoot('ltm3.test.local', 'admin', 'admin', token=True) >>> ps = mgmt.tm.util.bash.exec_cmd('run', utilCmdArgs='-c "tmsh run cli script pool-status.tcl a gslb_pool_1"') >>> ps.commandResult u'front_door:ltm3,available,disabled\ntestvip:ltm3,available,enabled\ntestvip2:ltm3,available,enabled\n' You can of course modify the tmsh script to return the data in a different format, I opted for quick and dirty here to model the problem and solution. Thanks go to community member Aaron Murray for the question and the inspiration, happy coding out there!2.4KViews1like13CommentsLightboard Lessons: F5 DNS Order of Operations
In this episode of Lightboard Lessons, Jason covers the order in which all the fantastic services available within the F5 BIG-IP DNS offering are processed. Resources K14510: Overview of DNS query processing on BIG-IP systems Lightboard Lessons: Life of a Packet Getting Started with BIG-IP DNS (GTM) Configuring BIG-IP DNS (GTM)606Views1like0CommentsConfiguring Decision Logging for the F5 BIG-IP Global Traffic Manager
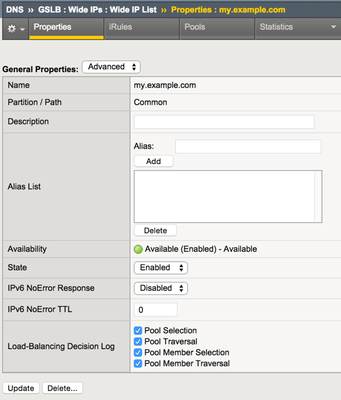
I was working on a GTM solution and with my limited lab I wanted to make sure that the decisions that F5 BIG-IP Global Traffic Manager made at the wideIP and pool level were as evident in the logs as they were consistent in my test results. It turns out there are some fancy little checkboxes in the wideIP configuration that you can check to enable such logs. You might notice, however, that upon enabling these checkboxes the logs are nowhere to be found. This is because there are other necessary steps. You need to configure a few objects to get those logs flowing. Log Publisher The first object is the log publisher. For as much detail as flows in the decision logging, I’d highly recommend using an HSL profile to log to a remote server, but for the purposes of testing I used the local syslog. This can also be done with tmsh. sys log-config publisher gtm_decision_logging { destinations { local-syslog { } } } DNS Logging Profile Next, create a DNS logging profile, make sure to select the Log Publisher you created in the previous step. For testing purpose I enabled the log responses and query ID as well, but those are disabled by default. This also can be created in tmsh. ltm profile dns-logging gtm_decision_logging { enable-response-logging yes include-query-id yes log-publisher gtm_decision_logging } Custom DNS Profile Now create a custom DNS profile. The only custom properties necessary are at the bottom of the profile where you enable logging and select the logging profile. This can also be configured in tmsh. ltm profile dns gtm_decision_logging { app-service none defaults-from dns enable-logging yes log-profile gtm_decision_logging } Apply the DNS Profile Now that all the objects are created, you can reference the DNS profile in the listener. in tmsh, you can modify the listener by adding the profile or if one already exists, replacing it. modify gtm listener gtmlistener profiles replace-all-with { udp_gtm_dns gtm_decision_logging } Log Details Once you have all the objects configured and the DNS profile referenced in your listener, the logging should be hitting /var/log/ltm now. For this first query, the emea pool is selected, but there is no probe data for my primary load balancing method, and the none alternate method skips to the fallback, which uses the configured fallback IP to respond to the client. 2015-06-03 08:54:21 ltm1.dc.test qid 11139 from 192.168.102.1#64536: view none: query: my.example.com IN A + (192.168.102.5%0) 2015-06-03 08:54:21 ltm1.dc.test qid 11139 from 192.168.102.1#64536 [my.example.com A] [round robin selected pool (emea)] [pool member check succeeded (vip3:192.168.103.12) - pool member state is available (green)] [QoS skipped pool member (vip3:192.168.103.12) - path has unmeasured RTT] [pool member check succeeded (vip4:192.168.103.13) - pool member state is available (green)] [QoS skipped pool member (vip4:192.168.103.13) - path has unmeasured RTT] [failed to select pool member by preferred load balancing method] [Using none load balancing method] [failed to select pool member by alternate load balancing method] [selected configured fallback IP] 2015-06-03 08:54:21 ltm1.dc.test qid 11139 to 192.168.102.1#64536: [NOERROR qr,aa,rd] response: my.example.com. 30 IN A 192.168.103.99; In this second request, the emea pool is again selected, but now there is probe data, so the pool member is selected as appropriate. 2015-06-03 08:55:43 ltm1.dc.test qid 6201 from 192.168.102.1#61503: view none: query: my.example.com IN A + (192.168.102.5%0) 2015-06-03 08:55:43 ltm1.dc.test qid 6201 from 192.168.102.1#61503 [my.example.com A] [round robin selected pool (emea)] [pool member check succeeded (vip3:192.168.103.12) - pool member state is available (green)] [QoS selected pool member (vip3:192.168.103.12) - QoS score (2082756232) is higher] [pool member check succeeded (vip4:192.168.103.13) - pool member state is available (green)] [QoS skipped pool member (vip4:192.168.103.13) from two pool members with equal scores] [QoS selected pool member (vip3:192.168.103.12)] 2015-06-03 08:55:43 ltm1.dc.test qid 6201 to 192.168.102.1#61503: [NOERROR qr,aa,rd] response: my.example.com. 30 IN A 192.168.103.12; In this final request, the americas pool is selected, but there is no valid topology score for the pool members, so query is refused. 2015-06-03 08:55:53 ltm1.dc.test qid 23580 from 192.168.102.1#59437: view none: query: my.example.com IN A + (192.168.102.5%0) 2015-06-03 08:55:53 ltm1.dc.test qid 23580 from 192.168.102.1#59437 [my.example.com A] [round robin selected pool (americas)] [pool member check succeeded (vip1:192.168.103.10) - pool member state is available (green)] [QoS selected pool member (vip1:192.168.103.10) - QoS score (0) is higher] [pool member check succeeded (vip2:192.168.103.11) - pool member state is available (green)] [QoS skipped pool member (vip2:192.168.103.11) from two pool members with equal scores] [QoS selected pool member (vip1:192.168.103.10)] [topology load balancing method failed to select pool member (vip1:192.168.103.10) - topology score is 0] [failed to select pool member by preferred load balancing method] [selected configured option Return To DNS] 2015-06-03 08:55:53 ltm1.dc.test qid 23580 to 192.168.102.1#59437: [REFUSED qr,rd] response: empty Yeah, yeah, skip all that and give me the good stuff If you want to test it quickly, you can save the config below to a file (/var/tmp/gtmlogging.txt in this example) and then merge it in. Finally, modify the wideIP and listener and you’re good to go! ### ### configuration: /var/tmp/gtmlogging.txt ### sys log-config publisher gtm_decision_logging { destinations { local-syslog { } } } ltm profile dns-logging gtm_decision_logging { enable-response-logging yes include-query-id yes log-publisher gtm_decision_logging } ltm profile dns gtm_decision_logging { app-service none defaults-from dns enable-logging yes log-profile gtm_decision_logging } ### ### Merge Command ### tmsh load sys config merge file /var/tmp/gtmlogging.txt ### ### Modify wideIP and Listener ### tmsh modify gtm wideip my.example.com load-balancing-decision-log-verbosity { pool-member-selection pool-member-traversal pool-selection pool-traversal } tmsh modify gtm listener gtmlistener profiles replace-all-with { udp_gtm_dns gtm_decision_logging } tmsh save sys config2.1KViews1like3Comments