AI
63 TopicsS3 Traffic Optimization with F5 BIG-IP & NetApp StorageGRID
The S3 protocol is seeing tremendous growth, often in projects involving AI where storage is a critical component, ranging from model training to inference with RAG. Model training projects usually need large, readily available datasets to keep GPUs operating efficiently. Additionally, storing sizable checkpoints—detailed snapshots of the model—is essential for these tasks. These are vital for resuming training after interruptions that could otherwise imperil weeks or months-long projects. Regardless of the AI ecosystem, S3 increasingly comes into play in some manner. For example, it is common for one tier of the storage involved, perhaps an outer tier, to be tasked with network loads to accrue knowledge sources. This data acquisition role is normally achieved today using S3 protocol transactions. Why does a F5 BIG-IP, an industry-leading ADC solution, work so well for optimizing S3 flows that are directed at a S3 storage solution such as StorageGRID? An interesting aspect of S3 is just how easily extensible it is, to a degree other protocols may not be. Take for example, routing protocols, like OSPF or BGP-4; that are governed by RFC’s controlled and published by the IETF (Internet Engineering Task Force). Unwavering compliance to RFC specifications is often non-negotiable with customers. Similarly, storage protocols are often governed by SNIA (Storage Networking Industry Association) and extensibility may not have been top of mind when standards were initially released. S3, as opposed to these examples, is proactively steered by Amazon. In fact, S3 (Simple Storage Service) was one of the earliest AWS services, launched in 2006. When referring to “S3” today, many times, the reference is normally to the set of S3 API commands that the industry has adopted in general, not specifically the storage service of AWS. Amazon’s documentation for S3, the starting point is found here, is easily digested, not clinical sets of clauses and archaic “must” or “should” directives. An entire category of user defined metadata is made available, and encourages unbounded extensibility: “User-defined metadata is metadata that you can choose to set at the time that you upload an object. This user-defined metadata is a set of name-value pairs” Why S3’s Flexibility Amplifies the Possibilities of BIG-IP and StorageGRID The extensibility baked into S3 is tailor made for the sophisticated and unique capabilities of BIG-IP. Specifically, BIG-IP ships with what has become an industry standard in Data Plane programmability: F5 iRules. For years, iRules have let IT administrators define specific, real-time actions based on the content and characteristics of network traffic. This enables them to do advanced tasks like content steering, protocol manipulation, customized persistence rules, and security policy enforcement. StorageGRID from NetApp allows a site of clustered storage nodes to use S3 protocol to both ingest content and deliver requested objects. Automatic backend synchronization allows any node to be offered up as a target by a server load balancer like BIG-IP. This allows overall storage node utilization to be optimized across the node set and scaled performance to reach the highest S3 API bandwidth levels, all while offering high availability to S3 API consumers. Should any node go off-line, or be taken out of service for maintenance, laser precise health checks from BIG-IP will remove that node from the pool used by F5, and customer S3 traffic will flow unimpeded. A previous article available here dove into the setup details and value delivered out of the box by BIG-IP for S3 clusters, such as NetApp StorageGRID. Sample BIG-IP and StorageGRID Configuration – S3 Storage QoS Steering One potential use case for BIG-IP is to expedite S3 writes such that the initial transaction is directed to the best storage node. Consider a workload that requires perhaps the latest in SSD technology, reflected by the lowest latency and highest IOPS. This will drive the S3 write (or read) towards the fastest S3 transactional completion time possible. A user can add this nuance, the need for this differentiated service level, easily as S3 metadata. The BIG-IP will make this custom field actionable, directing traffic to the backend storage node type required. As per normal StorageGRID behavior, any node can handle subsequent reads due to backend synchronization that occurs post-S3 write. Here is a sample scenario where storage nodes have been grouped into QoS levels, gold, silver and bronze to reflect the performance of the media in use. To demonstrate this use case, a lab environment was configured with three pools. This simulated a production solution where each pool could have differing hardware vintages and performance characteristics. To understand the use of S3 metadata fields, one may look at a simple packet trace of a S3 download (GET) directed towards an StorageGRID solution. Out of the box, a few header fields will indicate that the traffic is S3. By disabling TLS, a packet analyzer on the client, Wireshark, can display the User-Agent field value as highlighted above. Often S3 traffic will originate with specific S3 graphical utilities like S3 Browser, Cyberduck, or FileZilla. The indicator of S3 is also found with the presence of common HTTP X-headers, in the example we observe x-amz-content-sha256, and x-amz-date highlighted. The guidance for adding one’s own headers is to preface the new headers with “x-amz-meta-“. In this exercise, we have chosen to include the header “x-amz-meta-object-storage-qos” as a header and have BIG-IP search out the values gold, silver, and bronze to select the appropriate storage node pool. Traffic without this header, including S3 control plane actions, will see traffic proxied by default to the bronze pool. To exercise the lab setup, we will use the “s3cmd”, a free command-line utility available for Linux and macOS, with about 60 command line options; s3cmd easily allows for header inclusions. Here is our example, which will move a 1-megabyte file using S3 into a StorageGRID hosted bucket on the “Silver” pool: s3cmd put large1megabytefile.txt s3://mybucket001/large1megabytefile.txt --host=10.150.92.75:443 --no-check-certificate --add-header="x-amz-meta-object-storage-qos:silver" BIG-IP Setup and Validation of QoS Steering The setup of a virtual server on BIG-IP is straightforward in our case. S3 traffic will be accepted on TCP port 443 of the server address, 10.150.92.75, and independent TLS sessions will face both the client and the backend storage nodes. As seen in the following BIG-IP screenshot, three pools have been defined. An iRule can be written from scratch or, alternatively, can easily be created using AI. The F5 AI Assistant, a chat interface found within the Distributed Cloud console, is extensively trained on iRules. It was used to create the following (double-click image to enlarge). Upon issuing the client’s s3cmd command to upload the 1-megabyte file with “silver” QoS requirement, we immediately observe the following traffic to the pools, having just zeroed all counters. Converting the proxied 8.4 million bits to megabytes confirms that the 1,024 KB file indeed was sent to the correct pool. Other S3 control plane interactions make up the small amount of traffic proxied to the bronze, spinning disks pool. BIG-IP and XML Tag Monitoring for Security Purposes Beyond HTTP header metadata, S3 user consoles can be harnessed to apply content tags to StorageGRID buckets and objects within buckets. In the following simple example, a bucket “bucketaugust002” has been tied to various XML user-defined tags, such as “corporate-viewer-permissions-level: restricted”. When a S3 client lists objects within a bucket tagged as restricted, it may be prudent to log this access. One approach would be iRules, but it’s not the optimal path, as the entirety of the HTTP response payload would need to be scoured for bucket listings. iRules could then apply REGEX scanning for “restricted”, as one simple example. A better approach is to use the Data Guard feature of the BIG-IP Advanced WAF module. Data Guard is built into the TMM (Traffic Management Microkernel) of BIG-IP at great optimization, whereas the TCL engine of iRules is not. Thus, iRules is fine when the exact offset of a pattern in known, and really good with request and response header manipulation, but for launching scans throughout payloads Data Guard is even better. Within AWAF, one need simply build a policy and under the “Advanced” option put in Data Guard strings of interest in a REGEX format, in our example (?:^|\W)restricted(?:$|\W), as seen below, double-click to see image in sharper detail. Although the screenshot indicates “blocking” is the enforcement mode, in our use case, alerting was only sought. As a S3Browser user explores the contents of a bucket flagged as “restricted” the following log is seen by an authorized BIG-IP administrator (double-click). Other use cases for Data Guard and S3 would include scanning of textual data objects being retrieved, specifically for the presence of fields that might be classified as PII, such as credit card numbers, US social security numbers, or any other custom value an organization is interested in. A multitude of online resources provide REGEX expressions matching the presence of any of a variety of potentially sensitive information mandated through international standards. Occurrences within retrieved data, such as data formats matching drivers’ licenses, national health care values, and passport IDs are all quickly keyed in on. The ability of Data Guard to obfuscate sensitive information, beyond blocking or alerting, is a core reason to use BIG-IP in line with your data. BIG-IP Advanced Traffic Management - Preserve Customer Performance The BIG-IP offers a myriad of safeguards and enforcement options around the issue of high-rate traffic management. The risks today include any one traffic source maliciously or inadvertently overwhelming the StorageGRID cluster with unreasonable loads. The possible protections are simply touched upon in this section, starting with some simple features, enabled per virtual server, with a few clicks. A BIG-IP deployment can be as simple as one virtual server directing all traffic to a backend cluster of StorageGRID nodes. However, just as easily, it could be another extreme: a virtual server entry reserved for one company, one department, even one specific high value client machine. In the above screenshot, one sees a few options. A virtual server may have a cap set on how many connections are permitted, normally TCP port 443-based for S3. This is a primitive but effective safeguard against denial-of-service attacks that attempt to overwhelm with bulk connection loads. As seen, an eviction policy can be enabled that closes connections that exhibit negative characteristics, like clients who become unresponsive. Lastly, it is seen that connection rate safeguards are also available and can be applied to consider source IP addresses. This can counteract singular, rogue clients in larger deployments. Another set of advanced features serve to protect the StorageGRID infrastructure in terms of clamping down on the total traffic that the BIG-IP will forward to a cluster. These features are interesting as many can apply not just at the per virtual server level, but some controls can be applied to the entirety of traffic being sent on particular VLANs or network interfaces that might interconnect to backend pools. BIG-IP’s advanced features include the aptly named Bandwidth Controllers, and are made up of two varieties: static and dynamic. Static is likely the correct choice for limiting the total bandwidth a given virtual server can direct at the backend pool of Storage Nodes. The setup is trivial, just visit the “Acceleration” tab of BIG-IP and create a static bandwidth controller of the magnitude desired. At this point, nothing further is required beyond simply choosing the policy from the virtual server advanced configuration screen. For even more agile behavior, one might choose to use a dynamic bandwidth controller. As seen below, the options now extend into individual user traffic-level metering. With ancillary BIG-IP modules like Access Policy Manager (APM) traffic can be tied back to individual authenticated users by integration with common Identity Providers (IdP) solutions like Microsoft Active Directory (AD) servers or using the SSO framework standard SAML 2.0, others exist as well. However, with LTM by itself, we can consider users as sessions consisting of source IP and source (ephemeral) TCP port pairs and can apply dynamic bandwidth controls upon this definition of a user. The following provides an example of the degree to which traffic management can be imposed by BIG-IP with dynamic controllers, including per user bandwidth. The resulting dynamic bandwidth solution can be tied to any virtual server with the following few lines of a simple iRule: when CLIENT_ACCEPTED { set mycookie [IP::remote_addr]:[TCP:: remote_port] BWC::policy attach No_user_to_exceed_5Mbps $mycookie} Summary The NetApp StorageGRID multi-node S3 compatible object storage solution fits well with a high-performance server load balancer, thus making the F5 BIG-IP a good fit. There are various features within the BIG-IP toolset that can open up a broad set of StorageGRID’s practical use cases. As documented, the ability exists for a BIG-IP iRule to isolate in upon any HTTP-level S3 header, including customized user meta-data fields. This S3 metadata now becomes actionable – the resulting options are bounded only by what can be imagined. One potential option, selecting a specific pool of Storage Nodes based upon a signaled QoS value was successfully tested. Other use cases include using the advanced WAF capabilities of BIG-IP, such as the Data Guard feature, analyzing real-time response content and alerting upon xml tags or potentially obfuscating or entirely blocking transfers with sensitive data fields. A rich set of traffic safeguards were also discussed, including per virtual server connection limits and advanced bandwidth controls. When combined with optimizations discussed in other articles, such as the OneConnect profile that can drastically suppress the number of concurrent TCP sessions handled by StorageGrid nodes, one quickly sees that the performance and security improvements attainable make the suggested architecture compelling.62Views0likes0CommentsJust Announced! Attend a lab and receive a Raspberry Pi
Have a Slice of AI from a Raspberry Pi Services such as ChatGPT have made accessing Generative AI as simple as visiting a web page. Whether at work or at home, there are advantages to channeling your user base (or family in the case of at home) through a central point where you can apply safeguards to their usage. In this lab, you will learn how to: Deliver centralized AI access through something as basic as a Raspberry Pi Learn basic methods for safeguarding AI Learn how users might circumvent basic safeguards Learn how to deploy additional services from F5 to enforce broader enterprise policies Register Here This lab takes place in an F5 virtual lab environment. Participants who complete the lab will receive a Raspberry Pi* to build the solution in their own environment. *Limited stock. Raspberry Pi is exclusive to this lab. To qualify, complete the lab and join a follow-up call with F5.867Views7likes2CommentsHow To Build An Agent With n8n And Docker - AI Step-By-Step Lab
OK, community... It’s time for another addition to our AI Step-By-Step Labs, from yours truly! I did a mini lab for installing n8n on a mac. It has been popular, but we thought it would be better as a Docker installation to fit into our lab. So I set out to do this on Docker and it was super easy. I'm not going to spoil it too much, as I'd like for you to visit the GitHub repository for our labs, but this is the flow you create: This lab walks you through installation in Docker and walks you through creation of an AI agent that proxies requests to the LLM instance you created with our first lab on installing Ollama. Please check out the repository on GitHub to get started using this powerful agentic framework in your lab, production or personal use today. Feel free to watch the video on our YouTube channel here: 232Views1like1Comment
232Views1like1CommentF5 and MinIO: AI Data Delivery for the hybrid enterprise
Introduction Modern application architectures demand solutions that not only handle exponential data growth but also enable innovation and drive business results. As AI/ML workloads take center stage in industries ranging from healthcare to finance, application designers are increasingly turning to S3-compliant object storage because of its ability to provide scalable management of unstructured data. Whether it’s for ingesting massive datasets, running iterative training models, or delivering high-throughput predictions, S3-compatible storage systems play a foundational role in supporting these advanced data pipelines. MinIO has emerged as a leader in this space, offering high-performance, S3-compatible object storage built for modern-scale applications. MinIO is designed to easily work with AI/ML workflows. It is lightweight and cloud-based, so it is a good choice for businesses that are building infrastructure to support innovation. From storing petabyte-scale datasets to providing the performance needed for real-time AI pipelines, MinIO delivers the reliability and speed required for data-intensive work. While S3-compliant storage like MinIO forms the backbone of data workflows, robust traffic management and application delivery capabilities are essential for ensuring continuous availability, secure pipelines, and performance optimization. F5 BIG-IP, with its advanced suite of traffic routing, load balancing, and security tools, complements MinIO by enabling organizations to address these challenges. Together, F5 and MinIO create a resilient, scalable architecture where applications and AI/ML systems can thrive. This solution empowers businesses to: Build secure and highly-available storage pipelines for demanding workloads. Ensure fast and reliable delivery of data, even at exascale. Simplify and optimize their infrastructure to drive innovation faster. In this article, we’ll explore how to leverage F5 BIG-IP and MinIO AIStor clusters to enable results-driven application design. Starting with an architecture overview, we’ll cover practical steps to set up BIG-IP to enhance MinIO’s functionality. Along the way, we’ll highlight how this combination supports modern AI/ML workflows and other business-critical applications. Architecture Overview To validate the solution of F5 BIG-IP and MinIO AIStor effectively, this setup incorporates a functional testing environment that simulates real-world behaviors while remaining controlled and repeatable. MinIO’s warp benchmarking tool is used for orchestrating and running tests across the architecture. The addition of benchmarking tools ensures that the functional properties of the stack (traffic management, application-layer security, and object storage performance) are thoroughly evaluated in a way that is reproducible and credible. The environment consists of: A F5 VELOS chassis with BX110 blades, running BIG-IP instances configured using F5’s AS3 extension, for traffic management and security policies using LTM (Local Traffic Manager) and ASM (Application Security Manager). A MinIO AIStor cluster consisting of four bare-metal nodes equipped with high-performance NVMe drives, bringing the environment close to real-world customer deployments. Three benchmarking nodes for orchestrating and running tests: One orchestration node directs the worker nodes with benchmark test configuration and aggregates test results. Two worker nodes run warp in client mode to simulate workloads against the MinIO cluster. Warp Benchmarking Tool The warp benchmarking tool (https://github.com/minio/warp) from MinIO is designed to simulate real-world S3 workloads while also generating measurable metrics about the testing environment. In this architecture: A central orchestration node is used to coordinate the benchmarking process. This ensures that each test is consistent and runs under comparable conditions. Two worker nodes running warp in client mode send simulated traffic to the F5 BIG-IP virtual server. These nodes act as workload generators, allowing for the simulation of read-heavy, write-heavy, or mixed object storage exercises. Warp’s distributed design enables the scaling of workload generation, ensuring that the MinIO backend is tested under real-world-like conditions. This three-node configuration ensures that benchmarking tests are distributed effectively. It also provides insights into object storage behavior, traffic management, and the impact of security enforcement in the environment. Traffic Management and Security with BIG-IP At the center of this setup is the F5 VELOS chassis, running BIG-IP instances configured to handle both traffic management (LTM) and application-layer security (ASM). The addition of ASM (Application Security Manager) ensures that the MinIO cluster is protected from malicious or malformed requests while maintaining uninterrupted service for legitimate traffic. Key functions of BIG-IP in this architecture include: Load Balancing: Avoid overloading specific MinIO nodes by using adaptive algorithms, ensuring even traffic distribution, and preventing bottlenecks and hotspots. Apply advanced load balancing methods like least connections, dynamic ratio, and least response time. These methods intelligently account for backend load and performance in real time, ensuring reliable and efficient resource utilization. SSL/TLS Termination: Terminate SSL/TLS traffic to offload encryption workloads from backend clients. Re-encryption is optionally enabled for secure communication to MinIO nodes, depending on performance and security requirements. Health Monitoring: Intelligently performs continuous monitoring of the availability and health of the backend MinIO nodes. It reroutes traffic away from unhealthy nodes as necessary and restores traffic as service is restored. Application-Layer Security: Protect the environment via Web Application Firewall (WAF) policies that block malicious traffic, including injection attacks, malformed API calls, and DDoS-style app-layer threats. BIG-IP acts as the gateway for all requests coming from S3 clients, ensuring that security, health checks, and traffic policies are all applied before requests reach the MinIO nodes. Traffic Flow Through the Full Architecture The test traffic flows through several components in this architecture, with BIG-IP and warp playing vital roles in managing and generating requests, respectively: Benchmark Orchestration: The warp orchestration node initiates tests and distributes workload configurations to the worker nodes. The warp orchestration node also aggregates test data results from the worker nodes. Warp manages benchmarking scenarios, such as read-heavy, write-heavy, or mixed traffic patterns, targeting the MinIO storage cluster. Simulated Traffic from Worker Nodes: Two worker nodes, running warp in client mode, generate S3-compatible traffic such as object PUT, GET, DELETE, or STAT requests. These requests are transmitted through the BIG-IP virtual server. The load generation simulates the kind of requests an AI/ML pipeline or data-driven application might send under production conditions. BIG-IP Processing: Requests from the worker nodes are received by BIG-IP, where they are subjected to: Traffic Control: LTM distributes the traffic among the four MinIO nodes while handling SSL termination and monitoring node health. Security Controls: ASM WAF policies inspect requests for signs of application-layer threats. Only safe, valid traffic is routed to the MinIO environment. Environment Configuration Prerequisites BIG-IP (physical or virtual) Hosts for the MinIO cluster, including configured operating systems (and scheduling systems if optionally selected) Hosts for the warp worker nodes and warp orchestration node, including configured operating systems All required networking gear to connect the BIG-IP and the nodes A copy of the AS3 template at https://github.com/f5businessdevelopment/terraform-kvm-minio/blob/main/as3manualtemplate.json A copy of the warp configuration file at https://github.com/minio/warp/blob/master/yml-samples/mixed.yml Step 1: Set up MinIO Cluster Follow MinIO’s install instructions at https://min.io/docs/minio/linux/index.html The link is for a Linux deployment but choose the deployment target that’s appropriate for your environment. Record the addresses and ports of the MinIO consoles and APIs configured in this step for use as input to the next steps. Step 2: Configure F5 BIG-IP for Traffic Management and Security Following the steps documented in https://github.com/f5businessdevelopment/terraform-kvm-minio/blob/main/MANUALAS3.md and using the template file downloaded from GitHub, create and apply an AS3 declaration to configure your BIG-IP. Step 3: Deploy and Configure MinIO Warp for Benchmarking Retrieve API Access and Secret keys Log into your MinIO Cluster and click the 'Access' icon Once in 'Access', click the 'Access Keys' button In ‘Access Keys’, click the ‘Create Access Keys’ button and follow the steps to create and record your access and secret key values. Update warp key and secret value In your warp configuration file, find the access-key and secret-key fields and update the values with those you recorded in the previous step. Update warp client addresses In your warp configuration file, find the warp-client field and update the value with the addresses of the worker nodes. Update warp s3 host address In your warp configuration file, find the host field and update the value with the address and port of the VIP listener on the BIG-IP Step 4: Verify and Monitor the Environment Start the warp on each of the worker nodes with the command warp client Once the warp clients respond that they are listening on the warp orchestrator node, start the warp benchmark test warp run test.yaml Replace test.yaml with the name of your configuration file Summary of Test Results Functional tests done in F5’s lab, using the method described above, show how the F5 + MinIO solution works and behaves. These results highlight important considerations that apply to both AI/ML pipelines and data repatriation workflows. This enables organizations to make informed design choices when deploying similar architectures. The testing goals were: Validate that BIG-IP security and traffic management policies function properly with MinIO AIStor in a simulated real-world configuration. Compare the impact of various load-balancing, security, and storage strategies to determine best practices. Test Methodology Four test configurations were executed to identify the effects of: Threads Per Worker: Testing both 1-thread and 20-thread configurations for workload generation. Multi-Part GETs and PUTs: Comparing scenarios with and without multi-part requests for better parallelization. BIG-IP Profiles: Evaluating Layer 7 (ASM-enabled security) versus Layer 4 (performance-optimized) profiles. Test Results Test Configuration Throughput Benefits 20 threads, multi-part, Layer 7 28.1 Gbps Security, High-performance reliability 20 threads, multi-part, Layer 4 81.5 Gbps High-performance reliability 1 thread, no multi-part, Layer 7 3.7 Gbps Security, Reliability 1 thread, no multi-part, Layer 4 7.8 Gbps Reliability Note: The testing results provide insights into the solution and behavior of this setup, though they are not intended as production performance benchmarks. Key Insights Multi-Part GETs and PUTs Are Critical for Throughput Optimization: Multi-part operations split objects into smaller parts for parallel processing. This allows the architecture to better utilize MinIO’s distributed storage capabilities and worker thread concurrency. Without multi-part GETs/PUTs, single-threaded configurations experienced severely reduced throughput. Recommendation: Ensure multi-part operations are enabled in applications or tools interacting with MinIO when handling large objects or high IOPS workloads. Balance Security with Performance: Layer 7 security provided by ASM is essential for sensitive data and workloads that interact with external endpoints. However, it introduces processing overhead. Layer 4 performance profiles, while lacking application-layer security features, deliver significantly higher throughput. Recommendation: Choose BIG-IP profiles based on specific workload requirements. For AI/ML data ingest and model training pipelines, consider enabling Layer 4 optimization during bulk read/write phases. For workloads requiring external access or high-security standards, deploy Layer 7 profiles. In some cases, consider horizontal scaling of load balancing and object storage tiers to add throughput capacity. Threads Per Worker Impact Throughput: Scaling up threads at the worker level significantly increased throughput in the lab environment. This demonstrates the importance of concurrency for demanding workloads. Recommendation: Optimize S3 client configurations for higher connection counts where workloads permit, particularly when performing bulk data transfers or operationally intensive reads. Example Use Cases Use Case #1: AI/ML Pipeline AI and machine learning pipelines rely heavily on storage systems that can ingest, process, and retrieve vast amounts of data quickly and securely. MinIO provides the scalability and performance needed for storage, while F5 BIG-IP ensures secure, optimized data delivery. Pipeline Workflow An enterprise running a typical AI/ML pipeline might include the following stages: Data Ingestion: Large datasets (e.g., images, logs, training corpora) are collected from various sources and stored within the MinIO cluster using PUT operations. Model Training: Data scientists iterate on AI models using the stored training datasets. These training processes generate frequent GET requests to retrieve slices of the dataset from the MinIO cluster. Model Validation and Inference: During validation, the pipeline accesses specific test data objects stored in the cluster. For deployed models, inference may require low-latency reads to make predictions in real time. How F5 and MinIO Support the Workflow This combined architecture enables the pipeline by: Ensuring Consistent Availability: BIG-IP distributes PUT and GET requests across the four nodes in the MinIO cluster using intelligent load balancing. With health monitoring, BIG-IP proactively reroutes traffic away from any node experiencing issues, preventing delays in training or inference. Optimizing Performance: NVMe-backed storage in MinIO ensures fast read and write speeds. Together with BIG-IP's traffic management, the architecture delivers reliable throughput for iterative model training and inference. Securing End-to-End Communication: ASM protects the MinIO storage APIs from malicious requests, including malformed API calls. At the same time, SSL/TLS termination secures communications between AI/ML applications and the MinIO backend. Use Case #2: Enterprise Data Repatriation Organizations increasingly seek to repatriate data from public clouds to on-premises environments. Repatriation is often driven by the need to reduce cloud storage costs, regain control over sensitive information, or improve performance by leveraging local infrastructure. This solution supports these workflows by pairing MinIO’s high-performance object storage with BIG-IP’s secure and scalable traffic management. Repatriation Workflow A typical enterprise data repatriation workflow may look like this: Bulk Data Migration: Data stored in public cloud object storage systems (e.g., AWS S3, Google Cloud Storage) is transferred to the MinIO cluster running on on-premises infrastructure using tools like MinIO Gateway or custom migration scripts. Policy Enforcement: Once migrated, BIG-IP ensures that access to the MinIO cluster is secured, with ASM enforcing WAF policies to protect sensitive data during local storage operations. Ongoing Storage Optimization: The migrated data is integrated into workflows like backup and archival, analytics, or data access for internal applications. Local NVMe drives in the MinIO cluster reduce latency compared to cloud solutions. How F5 and MinIO Support the Workflow This architecture facilitates the repatriation process by: Secure Migration: MinIO Gateway, combined with SSL/TLS termination on BIG-IP, allows data to be transferred securely from public cloud object storage services to the MinIO cluster. ASM protects endpoints from exploitation during bulk uploads. Cost Efficiency and Performance: On-premises MinIO storage eliminates expensive cloud storage costs while providing faster access to locally stored data. NVMe-backed nodes ensure that repatriated data can be rapidly retrieved for internal applications. Scalable and Secure Access: BIG-IP provides secure access control to the MinIO cluster, ensuring only authorized users or applications can use the repatriated data. Health monitoring prevents disruptions in workflows by proactively managing node unavailability. The F5 and MinIO Advantage Both use cases reflect the flexibility and power of combining F5 and MinIO: AI/ML Pipeline: Supports data-heavy applications and iterative processes through secure, high-performance storage. Data Repatriation: Empowers organizations to reduce costs while enabling seamless local storage integration. These examples provide adaptable templates for leveraging F5 and MinIO to solve problems relevant to enterprises across various industries, including finance, healthcare, agriculture, and manufacturing. Conclusion The collaboration of F5 BIG-IP and MinIO provides a high-performance, secure, and scalable architecture for modern data-driven use cases such as AI/ML pipelines and enterprise data repatriation. Testing in the lab environment validates the functionality of this solution, while highlighting opportunities for throughput optimization via configuration tuning. To bring these insights to your environment: Test multi-part configurations using tools like MinIO warp benchmark or production applications. Match BIG-IP profiles (Layer 4 or Layer 7) with the specific priorities of your workloads. Use these findings as a baseline while performing further functional or performance testing in your enterprise. The flexibility of this architecture allows organizations to push the boundaries of innovation while securing critical workloads at scale. Whether driving new AI/ML pipelines or reducing costs in repatriation workflows, the F5 + MinIO solution is well-equipped to meet the demands of modern enterprises. Further Content For more information about F5's partnership with MinIO, consider looking at the informative overview by buulam on DevCentral's YouTube channel. We also have the steps outlined in this video. 284Views2likes0Comments
284Views2likes0CommentsGetting Started With n8n For AI Automation
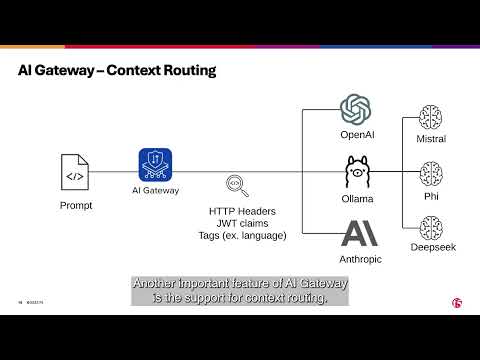
First, what is n8n? If you're not familiar with n8n yet, it's a workflow automation utility that allows us to use nodes to connect services quite easily. It's been the subject of quite a bit of Artificial Intelligence hype because it helps you construct AI Agents. I'm going to be diving more into n8n, what it can do with AI, and how to use our AI Gateway to defend against some difficult AI threats today. My hope is that you can use this in your own labs to prove out some of these things in your environment. Here's an example of how someone could use Ollama to control multiple Twitter accounts, for instance: How do you install it? Well... It’s all node, so the best way to install it in any environment is to ensure you have node version 22 (on Mac, homebrew install node@22) installed on your machine, as well as nvm (again, for mac, homebrew install nvm) and then do an npm install -g n8n. Done! Really...That simple. How much does it cost? While there is support and expanded functionality for paid subscribers, there is also a community edition that I have used here and it's free. How to license: 137Views0likes0Comments
137Views0likes0CommentsGetting Started With n8n For AI Automation
First, what is n8n? If you're not familiar with n8n yet, it's a workflow automation utility that allows us to use nodes to connect services quite easily. It's been the subject of quite a bit of Artificial Intelligence hype because it helps you construct AI Agents. I'm going to be diving more into n8n, what it can do with AI, and how to use our AI Gateway to defend against some difficult AI threats today. My hope is that you can use this in your own labs to prove out some of these things in your environment. Here's an example of how someone could use Ollama to control multiple Twitter accounts, for instance: How do you install it? Well... It’s all node, so the best way to install it in any environment is to ensure you have node version 22 (on Mac, homebrew install node@22) installed on your machine, as well as nvm (again, for mac, homebrew install nvm) and then do an npm install -g n8n. Done! Really...That simple. How much does it cost? While there is support and expanded functionality for paid subscribers, there is also a community edition that I have used here and it's free. How to license:382Views5likes0CommentsIntroducing AI Assistant for F5 Distributed Cloud, F5 NGINX One and BIG-IP
This article is an introduction to AI Assistant and shows how it improves SecOps and NetOps speed across all F5 platforms (Distributed Cloud, NGINX One and BIG-IP) , by solving the complexities around configuration, analytics, log interpretation and scripting. 475Views3likes1Comment
475Views3likes1Comment